Staged Factorial Screening for Budget-Constrained Micro-Pretraining
Pith reviewed 2026-07-01 08:36 UTC · model grok-4.3
The pith
Staged fractional-factorial screens identify high-penalty directions early and support bridge anchors through 24 hours on two hosts in budget-constrained micro-pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
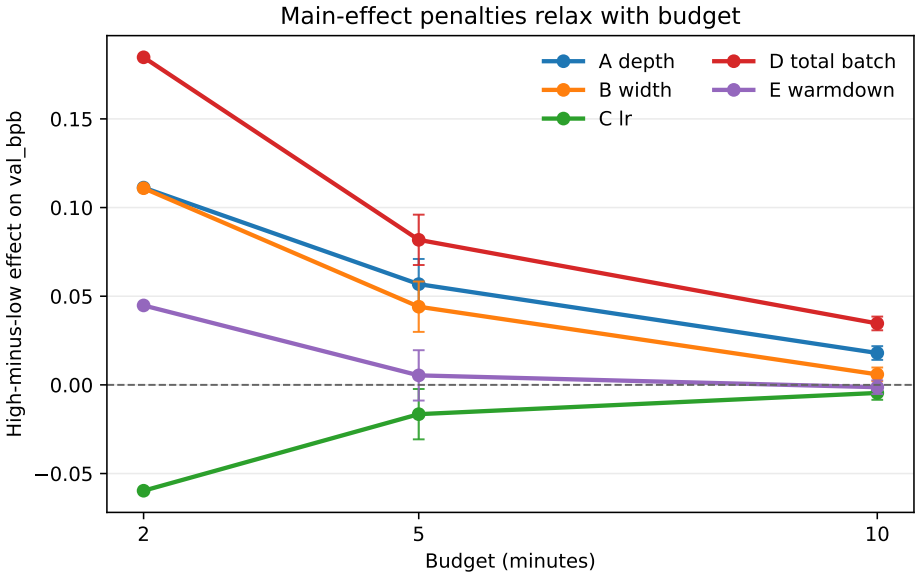
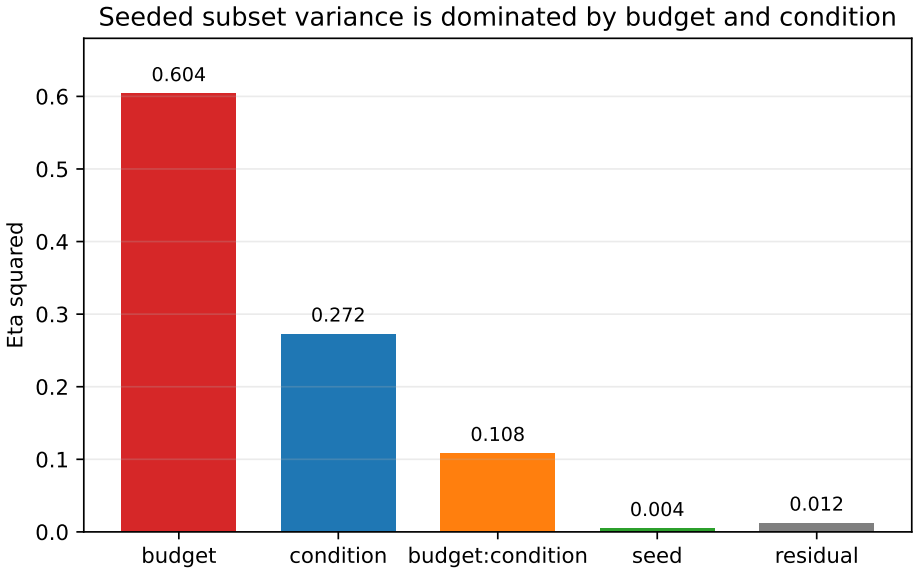
On a fixed autoresearch-derived single-GPU training loop, 613 experiments across pilot and follow-up screens at 2, 5, and 10 minutes, full 16-condition seeded reruns, targeted anchor checks, same-host baselines, a 60-minute bridge package, and bounded 12- and 24-hour three-anchor continuations on Windows A100 and Linux L40S hosts show that main penalties from total batch, depth, and width are largest at short budgets and relax as budget increases. Within the predeclared seeded full-screen families, factors D, A, B, and C retain non-zero estimates at 5 and 10 minutes after within-budget Benjamini-Hochberg correction while E does not. Random search reaches strong incumbents in the 32-condition
What carries the argument
staged fractional-factorial workflow that runs short designed screens to estimate and remove high-penalty directions before committing longer budgets to confirmation and local refinement
If this is right
- Main penalties from total batch, depth, and width are largest at short budgets and relax as budget increases.
- Within predeclared seeded full-screen families, factors D, A, B, and C retain non-zero estimates at 5 and 10 minutes after within-budget Benjamini-Hochberg correction while E does not.
- Random search reaches strong incumbents in the 32-condition space but repeatedly in the same low-penalty region and without factor attribution.
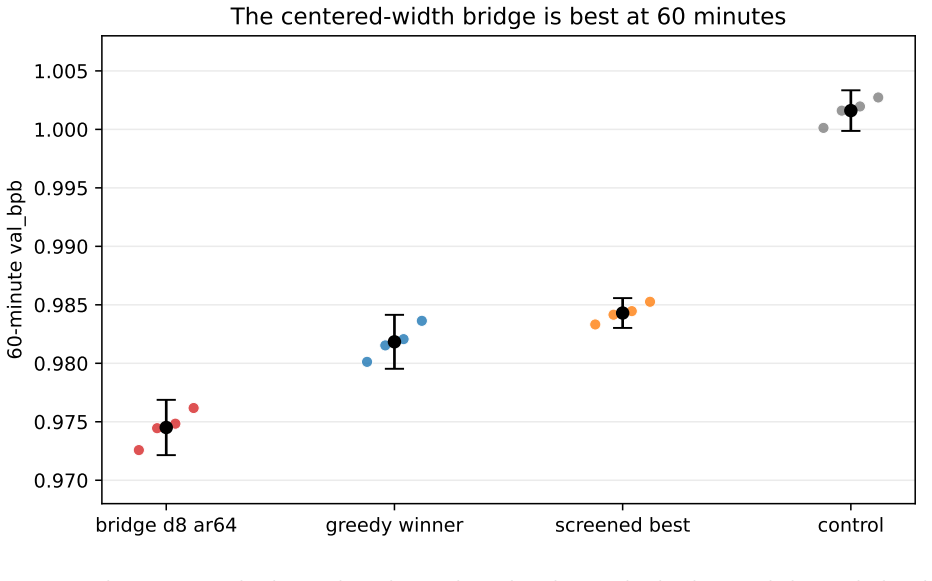
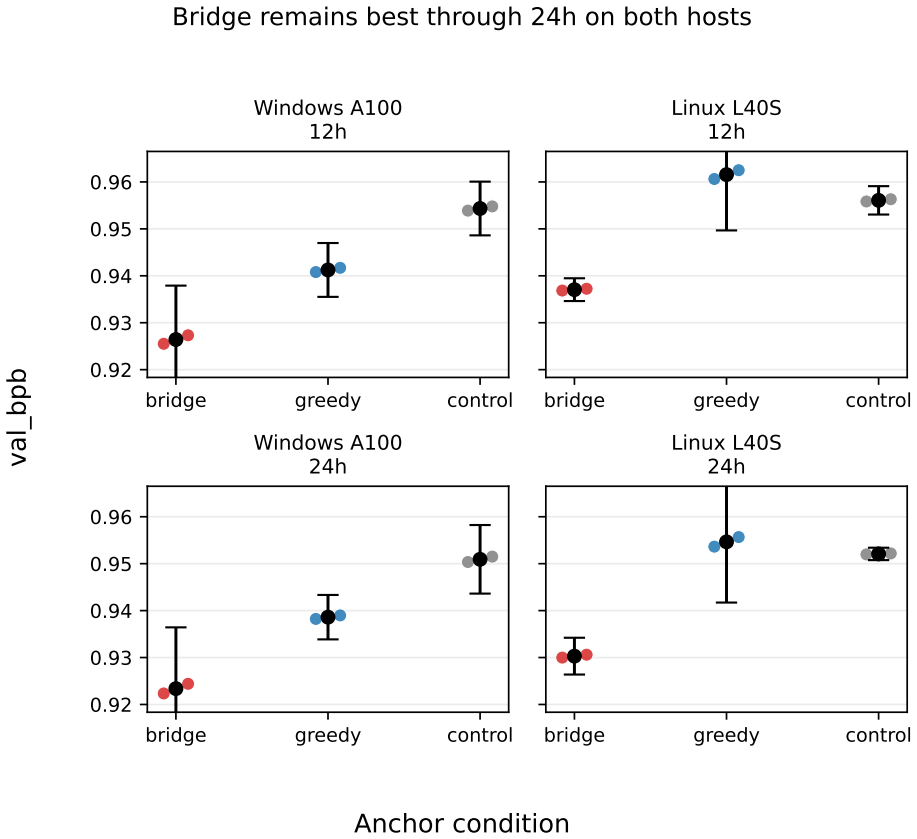
- The 60-minute bridge package has the lowest mean, and in bounded 12- and 24-hour three-anchor continuations on both hosts the bridge has the lowest sample mean while non-bridge ordering stays host-sensitive.
- The evidence supports a bridge-centered recommendation through 24 hours on two hosts, not hardware-invariant ranking or general hyperparameter-optimization superiority.
Where Pith is reading between the lines
- The observed relaxation of penalties with budget suggests that early screens could be reused across multiple model scales if the factor set is held constant.
- Host-sensitive ordering at 24 hours implies that separate short screens per hardware class may be required for stable recommendations rather than a single universal ranking.
- Because random search already locates strong points inside the low-penalty region, the added value of the factorial workflow lies mainly in the attribution step that guides later refinement.
- Extending the same staged design to include interaction terms or additional factors such as optimizer choice would test whether the current main-effects focus remains sufficient at longer budgets.
Load-bearing premise
The autoresearch-derived single-GPU training loop and predeclared factor set recover stable early effect structure that remains informative when budget increases to 60 minutes and 24 hours.
What would settle it
If 24-hour repeated runs on both hosts show any non-bridge anchor achieving a lower sample mean than the bridge anchor, or if short-screen effect estimates fail to predict the ordering observed at 60 minutes and beyond, the bridge-centered recommendation would not hold.
Figures
read the original abstract
Budget-constrained micro-pretraining often requires triaging many candidate recipes on a shared accelerator before larger search budgets are spent. We study whether a staged fractional-factorial workflow can recover stable early effect structure in this setting. On a fixed autoresearch-derived single-GPU training loop, we run 613 experiments across pilot and follow-up screens at 2, 5, and 10 minutes; full 16-condition seeded reruns at 5 and 10 minutes; targeted seeded anchor checks; same-host greedy and matched-cost random baselines; a 60-minute bridge package; and bounded Windows A100 and Linux L40S anchor continuations through 24 hours. Main penalties from total batch, depth, and width are largest at short budgets and relax as budget increases. Within the predeclared seeded full-screen families, D, A, B, and C retain non-zero estimates at 5 and 10 minutes after within-budget Benjamini-Hochberg correction, while E does not. Random search can reach strong incumbents in this 32-condition space, but repeatedly in the same low-penalty region and without factor attribution. The 60-minute bridge anchor has the lowest mean, although that package does not separate workflow refinement from the larger bridge model's capacity advantage. In bounded 12-hour and 24-hour three-anchor continuations on both hosts, the bridge has the lowest sample mean while the non-bridge ordering stays host-sensitive. We therefore present a bounded methods result: use short designed screens to identify high-penalty directions, confirm promising anchors under repeated runs, and refine locally inside the reduced space. The evidence supports a bridge-centered recommendation through 24 hours on two hosts, not hardware-invariant ranking or general hyperparameter-optimization superiority.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a staged fractional-factorial screening workflow can recover stable early effect structure for budget-constrained micro-pretraining on a fixed single-GPU autoresearch loop. Across 613 experiments (pilot/follow-up screens at 2/5/10 min, full 16-condition reruns, anchor checks, greedy/random baselines, 60-min bridge, and 12/24-hour continuations on Windows A100 and Linux L40S), main penalties from total batch, depth, and width are largest at short budgets and relax later; within predeclared seeded families, factors D/A/B/C retain non-zero estimates after within-budget BH correction while E does not. Random search reaches strong incumbents but without attribution. The 60-min bridge shows lowest mean (though confounded with capacity), and 24-hour three-anchor runs favor the bridge on both hosts while non-bridge ordering is host-sensitive. The central recommendation is therefore bounded: use short designed screens to identify high-penalty directions, confirm anchors under repetition, and refine locally in the reduced space.
Significance. If the bounded empirical findings hold, the work supplies a practical, statistically controlled method for triaging candidate recipes under tight accelerator budgets before committing larger resources. Strengths include the explicit framing as a methods result tied to a fixed training loop and predeclared factors, the use of repeated anchor runs and within-budget multiple-testing correction, and direct probing of effect stability via the 60-min bridge and 24-hour continuations. It does not claim hardware-invariant rankings or general HPO superiority.
minor comments (3)
- [Abstract, §3] Abstract and §3: the exact definitions and level settings for the five predeclared factors (A–E) are referenced but not enumerated in the provided text; a concise table or appendix listing them would improve reproducibility.
- [§4, Table 2] §4 and Table 2: the precise implementation of the within-budget Benjamini-Hochberg correction (e.g., how p-values are pooled across the 5- and 10-minute screens) is described at high level; an explicit formula or pseudocode step would clarify whether the reported non-zero estimates for D/A/B/C survive the exact procedure used.
- [Figure 3, §5.2] Figure 3 and §5.2: the 24-hour continuation plots show host-sensitive ordering for non-bridge anchors, but axis scaling and error-bar conventions differ slightly between hosts; uniform formatting would aid direct visual comparison.
Simulated Author's Rebuttal
We thank the referee for the clear summary of the manuscript, the positive assessment of its scope and limitations, and the recommendation for minor revision. No specific major comments are enumerated in the report.
Circularity Check
No significant circularity; empirical results self-contained
full rationale
The manuscript reports results from a fixed experimental loop of 613 runs using predeclared factors, short screens, BH correction, repeated anchors, and bounded continuations. No equations, derivations, or predictions appear; all claims reduce to direct sample means and within-budget corrections on the observed data. No self-citations are load-bearing for the central bounded-methods recommendation. The work is self-contained against the described training loop and does not invoke fitted parameters renamed as predictions or uniqueness theorems.
Axiom & Free-Parameter Ledger
free parameters (1)
- Factor levels for A, B, C, D, E
axioms (2)
- domain assumption Fractional factorial design recovers stable early effect structure in autoregressive pretraining loops
- standard math Benjamini-Hochberg correction controls false discoveries within predeclared seeded families
Forward citations
Cited by 1 Pith paper
-
Small Experiments, Cheaper Decisions: A Case Study in Staged Promotion for Micro-Pretraining
Case study applies frozen staged budgets and promotion rules to twelve micro-pretraining configurations, identifying a top bridge condition at 12 hours with 169 GPU-hours total versus higher counterfactual costs.
Reference graph
Works this paper leans on
-
[1]
GitHub repository
Andrej Karpathy.autoresearch. GitHub repository. Available at:https://github.com/ karpathy/autoresearch
-
[2]
SkyPilot documentation.Parallel autoresearch. Available at:https://docs.skypilot.co/ en/latest/examples/agents/autoresearch.html [3]Predictable Scale: Part I, Step Law -- Optimal Hyperparameter Scaling Law in Large Lan- guage Model Pretraining. arXiv:2503.04715.https://arxiv.org/abs/2503.04715 [4]Principled Architecture-aware Scaling of Hyperparameters. a...
-
[3]
Journal of Machine Learning Research, 13(10):281-305, 2012.https://jmlr.org/beta/papers/ v13/bergstra12a.html
James Bergstra and Yoshua Bengio.Random Search for Hyper-Parameter Optimization. Journal of Machine Learning Research, 13(10):281-305, 2012.https://jmlr.org/beta/papers/ v13/bergstra12a.html
2012
-
[4]
Hoos, and Kevin Leyton-Brown.An Efficient Approach for As- sessing Hyperparameter Importance
Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown.An Efficient Approach for As- sessing Hyperparameter Importance. Proceedings of the 31st International Conference on Machine Learning, PMLR 32, 2014.https://proceedings.mlr.press/v32/hutter14.html
2014
-
[5]
Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization
Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization. Journal of Machine Learning Research, 18(185):1-52, 2018.https://jmlr.org/beta/papers/v18/16-558.html
2018
-
[6]
Proceedings of the 35th International Conference on Machine Learning, PMLR 80, 2018.https://proceedings.mlr.press/v80/falkner18a.html
Stefan Falkner, Aaron Klein, and Frank Hutter.BOHB: Robust and Efficient Hyperparam- eter Optimization at Scale. Proceedings of the 35th International Conference on Machine Learning, PMLR 80, 2018.https://proceedings.mlr.press/v80/falkner18a.html
2018
-
[7]
Adams.Practical Bayesian Optimization of Machine Learning Algorithms
Jasper Snoek, Hugo Larochelle, and Ryan P. Adams.Practical Bayesian Optimization of Machine Learning Algorithms. Advances in Neural Information Processing Systems 25, 2012. https://proceedings.neurips.cc/paper/2012/hash/05311655a15b75fab86956663e1819cd-Abstract. html
-
[8]
Montgomery.Design and Analysis of Experiments
Douglas C. Montgomery.Design and Analysis of Experiments. Wiley, 10th edition, 2019
2019
-
[9]
George E. P. Box, J. Stuart Hunter, and William G. Hunter.Statistics for Experimenters: Design, Innovation, and Discovery. Wiley, 2nd edition, 2005. 22
2005
-
[10]
C. F. Jeff Wu and Michael Hamada.Experiments: Planning, Analysis, and Optimization. Wiley, 2nd edition, 2009
2009
-
[11]
George E. P. Box and K. B. Wilson.On the Experimental Attainment of Optimum Condi- tions. Journal of the Royal Statistical Society, Series B, 13(1):1-45, 1951
1951
-
[12]
Myers, Douglas C
Raymond H. Myers, Douglas C. Montgomery, and Christine M. Anderson-Cook.Response Surface Methodology: Process and Product Optimization Using Designed Experiments. Wiley, 4th edition, 2016
2016
-
[13]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Population Based Training of Neural Networks
Max Jaderberg, Valentin Dalibard, Simon Osindero, Wojciech M. Czarnecki, Jeff Donahue, Ali Razavi, Oriol Vinyals, Tim Green, Iain Dunning, Karen Simonyan, Chrisantha Fernando, and Koray Kavukcuoglu.Population Based Training of Neural Networks. arXiv:1711.09846, 2017. https://arxiv.org/abs/1711.09846
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
arXiv:1810.05934, 2018.https://arxiv.org/abs/1810.05934
Liam Li, Kevin Jamieson, Afshin Rostamizadeh, Ekaterina Gonina, Moritz Hardt, Ben- jamin Recht, and Ameet Talwalkar.A System for Massively Parallel Hyperparameter Tuning. arXiv:1810.05934, 2018.https://arxiv.org/abs/1810.05934
-
[16]
Cyclical Learning Rates for Training Neural Networks
Leslie N. Smith.Cyclical Learning Rates for Training Neural Networks. IEEE Winter Conference on Applications of Computer Vision, 2017. arXiv:1506.01186.https://arxiv.org/ abs/1506.01186
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates
Leslie N. Smith and Nicholay Topin.Super-Convergence: Very Fast Training of Neu- ral Networks Using Large Learning Rates. Proceedings of SPIE 11006, Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications, 2019. arXiv:1708.07120.https: //arxiv.org/abs/1708.07120
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[18]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin.Attention Is All You Need. arXiv:1706.03762, 2017. https://arxiv.org/abs/1706.03762 23
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.