Small Experiments, Cheaper Decisions: A Case Study in Staged Promotion for Micro-Pretraining
Pith reviewed 2026-06-27 13:18 UTC · model grok-4.3
The pith
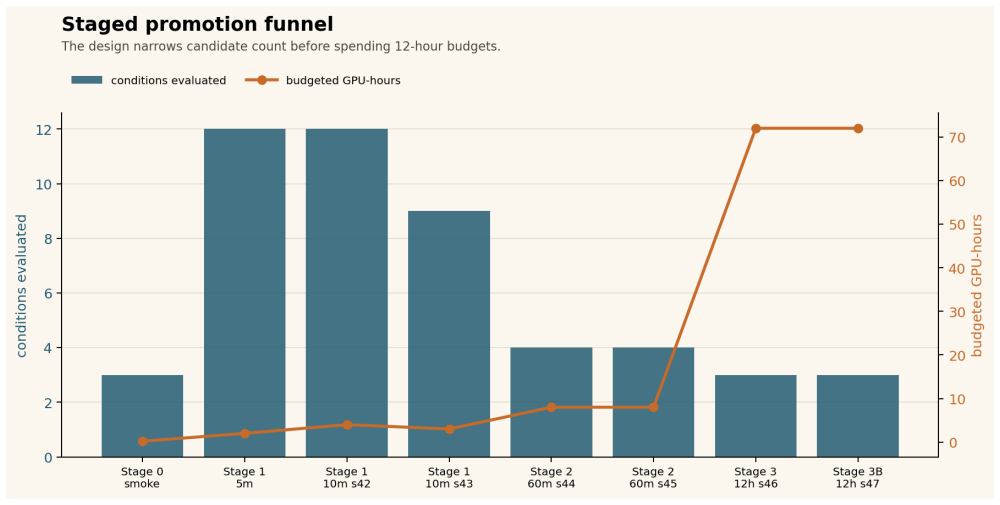
Staged promotion protocol selects top configuration using 169 GPU-hours of micro-pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
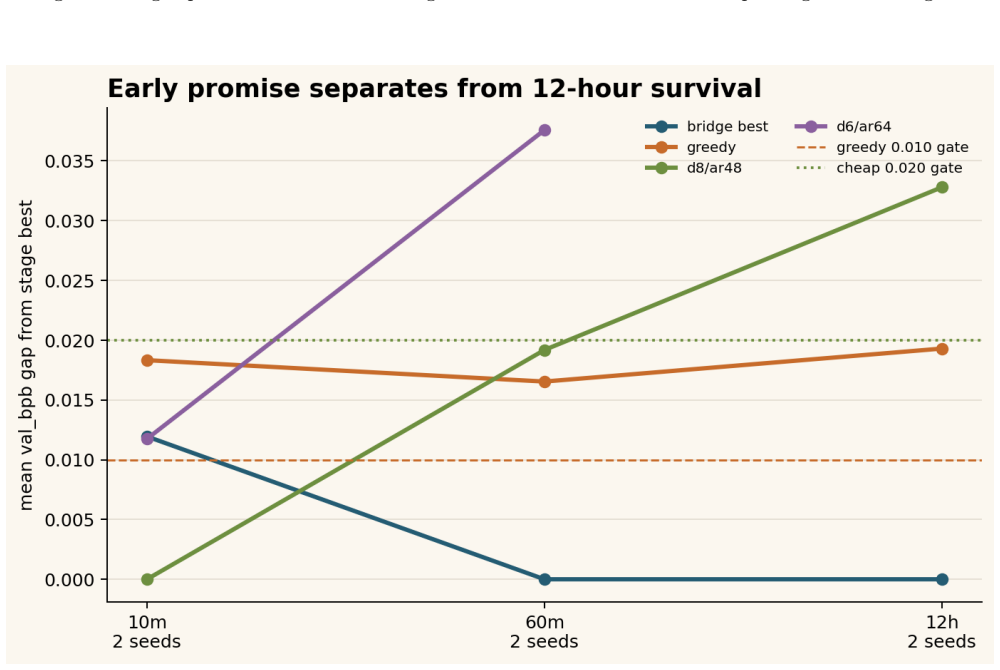
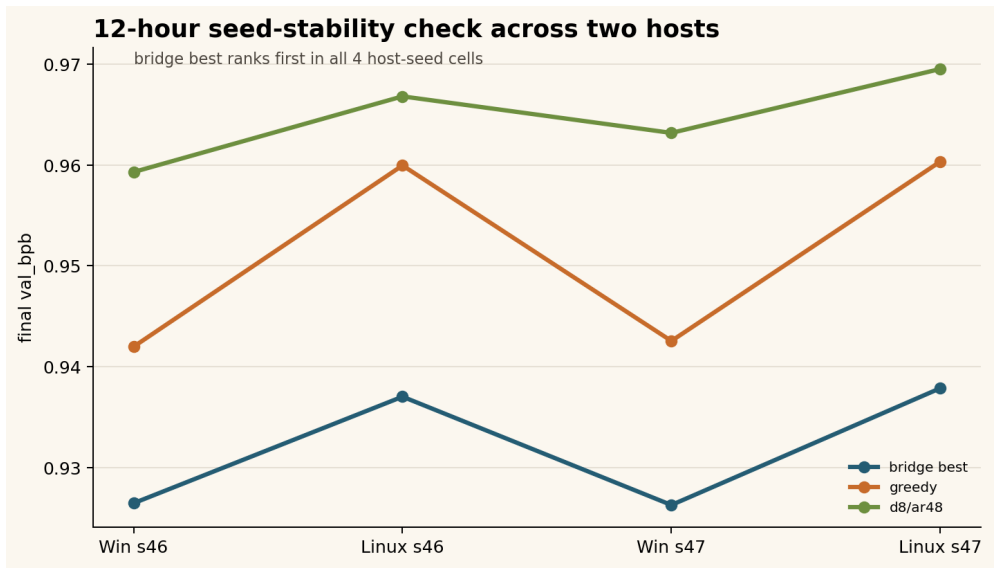
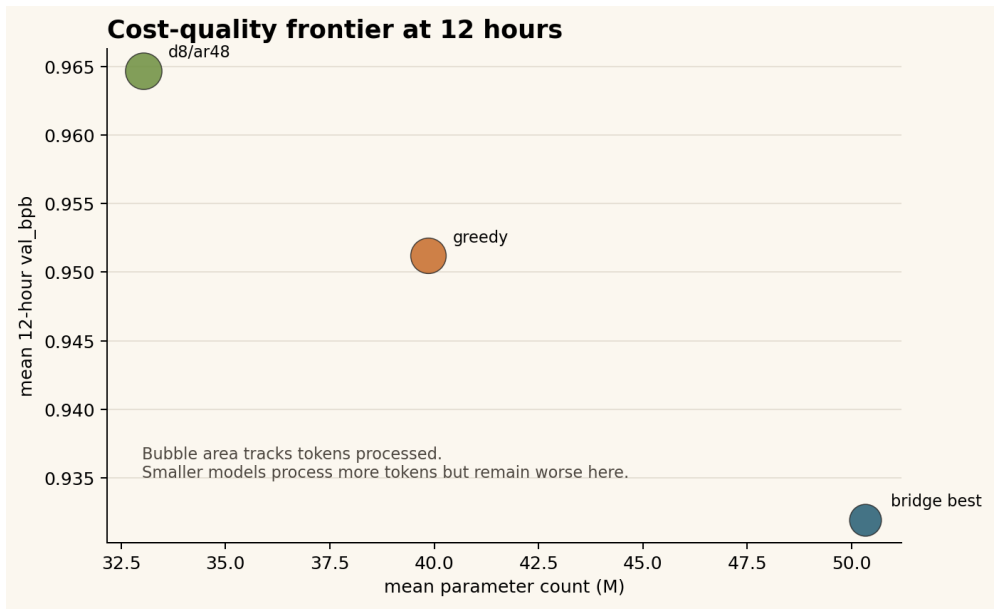
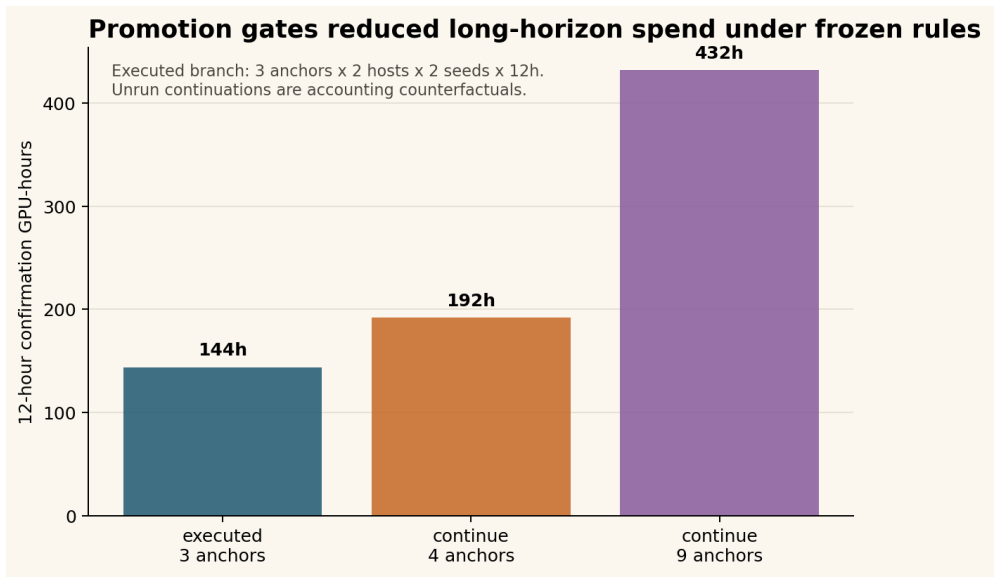
The paper establishes that a staged promotion protocol with fixed budgets and frozen rules can keep a reference configuration in the promoted set through all gates and rank it first at 12 hours across four host-seed cells in two seeds. The greedy comparator fails the 0.010 val_bpb rule and the d8/ar48 sentinel fails the 0.020 mean-gap rule. The full protocol records 169.2 training GPU-hours, with the 12-hour branch using 144 GPU-hours, compared to 432 GPU-hours for continuing all nine 10-minute candidates.
What carries the argument
Staged factorial screening with five fixed budgets (2 min, 5 min, 10 min, 60 min, 12 h) and frozen promotion thresholds applied across heterogeneous hosts.
If this is right
- The bridge condition ranks first in all four 60-minute host-seed cells and again in the 12-hour package.
- The protocol spends 169.2 GPU-hours total versus 432 for full continuation of 10-minute candidates.
- Rankings at 5- and 10-minute stages vary by host, treated as promotion evidence rather than stable curves.
- The 60-minute replicated gate retains the reference while discarding some candidates.
Where Pith is reading between the lines
- Similar staging could be applied to other pretraining scales to test whether the same thresholds remain effective.
- The approach might generalize to screening in other machine learning experiment pipelines where full runs are expensive.
- Future work could vary the stage budgets to measure sensitivity of the final selection to the chosen gates.
Load-bearing premise
The set of twelve prior-screened configurations contains every setup that could have performed better at the 12-hour scale, so early elimination does not discard superior options.
What would settle it
Training one of the nine skipped 10-minute candidates for 12 hours and observing a lower validation bits-per-byte than the promoted bridge condition would show that the protocol missed a better configuration.
Figures
read the original abstract
Short pretraining runs can reduce experimental cost, but they can also over-promote configurations that only look strong at tiny budgets. We study an auditable staged-promotion protocol for a fixed micro-pretraining runner on two heterogeneous host blocks: Windows A100 and Linux L40S. Starting from twelve prior-screened configurations, we use staged budgets of 2 minutes, 5 minutes, 10 minutes, 60 minutes, and 12 hours, with frozen promotion rules before expensive continuations. The early screens are intentionally treated as unstable: the 5- and 10-minute rankings are host-sensitive, and the eventual 12-hour top-ranked condition is not the mean-best condition at the replicated 10-minute gate. Because seed ranges differ across stages, these changes are operational promotion evidence, not within-seed curves. A replicated 60-minute gate keeps the Staged Factorial Screening bridge reference in the promoted set, where it ranks first in all four 60-minute host-seed cells. In the final 12-hour confirmation package, the bridge condition ranks first in all four host-seed cells across two seeds; the greedy comparator does not meet the frozen 0.010 val_bpb near-equivalence rule; and the cheaper d8/ar48 (depth-8, aspect-48) sentinel does not meet the frozen 0.020 mean-gap rule. The executed 12-hour branch spends 144 GPU-hours, and the full staged protocol records 169.2 training GPU-hours including screening stages. Continuing all four 60-minute candidates would spend 192 GPU-hours, while continuing all nine replicated 10-minute candidates would spend 432 GPU-hours. The latter numbers are accounting counterfactuals for unrun continuations, not evidence that skipped candidates could not have overtaken the reference. The result is a bounded cost-allocation finding, not a claim of global optimality, capacity-normalized superiority, or superiority over adaptive hyperparameter optimization methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a staged promotion protocol with budgets of 2/5/10/60 minutes and 12 hours, using frozen promotion rules (0.010 val_bpb near-equivalence and 0.020 mean-gap), allows for auditable decisions from twelve prior-screened configurations in micro-pretraining. It demonstrates that the bridge condition ranks first at the 12-hour stage across all host-seed cells, with total compute of 169.2 GPU-hours, providing cost savings compared to counterfactual full continuations, while qualifying the result as a bounded cost-allocation finding rather than general optimality.
Significance. If the thresholds are indeed frozen and the screening set sufficient, this case study illustrates a practical method for reducing experimental costs in pretraining configuration selection with explicit accounting of compute usage and clear limitations on the scope of claims. The use of multiple hosts and seeds, along with acknowledgment of ranking instability at early stages, adds to the operational evidence presented.
major comments (2)
- [Abstract] Abstract: The central claim that the protocol yields auditable promotion decisions from the twelve prior-screened configurations without post-hoc adjustment requires that the initial set is exhaustive and that the promotion thresholds were fixed independently of outcomes; the manuscript provides no details on the screening process or when the 0.010/0.020 rules were determined relative to data collection, which is load-bearing for the auditable property.
- [Abstract] Abstract: The 12-hour result states that the bridge condition ranks first in all four host-seed cells across two seeds and that the greedy comparator fails the frozen rule, but without reported per-cell values, variance estimates, or explicit confirmation that the rules were applied identically to all candidates, the stability claim is difficult to verify from the given numbers alone.
minor comments (1)
- [Abstract] Abstract: The counterfactual costs (192 GPU-hours for four 60-minute candidates, 432 for nine 10-minute candidates) are correctly labeled as accounting exercises rather than evidence of superiority, but a short clarification on how the sets of four and nine were determined from the twelve would improve transparency.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. The two major comments correctly identify areas where additional transparency would strengthen the verifiability of the auditable-protocol claim. We address each point below and will incorporate the requested details in a revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the protocol yields auditable promotion decisions from the twelve prior-screened configurations without post-hoc adjustment requires that the initial set is exhaustive and that the promotion thresholds were fixed independently of outcomes; the manuscript provides no details on the screening process or when the 0.010/0.020 rules were determined relative to data collection, which is load-bearing for the auditable property.
Authors: We agree that the current text does not explicitly document the provenance of the twelve configurations or the timing of threshold selection. The 0.010 val_bpb near-equivalence and 0.020 mean-gap rules were fixed in advance of the staged-budget experiments on the basis of an earlier, separate pilot study whose data are not part of the reported twelve-configuration set. The screening phase itself was an independent exploratory run performed before any of the staged budgets were executed. We will revise the abstract and add a short methods paragraph stating these facts, thereby making the “frozen before expensive continuations” claim directly verifiable from the manuscript. revision: yes
-
Referee: [Abstract] Abstract: The 12-hour result states that the bridge condition ranks first in all four host-seed cells across two seeds and that the greedy comparator fails the frozen rule, but without reported per-cell values, variance estimates, or explicit confirmation that the rules were applied identically to all candidates, the stability claim is difficult to verify from the given numbers alone.
Authors: The manuscript asserts uniform ranking but does not tabulate the per-cell val_bpb and mean-gap numbers that underlie the claim. We will add an appendix table listing the four host-seed cells at the 12-hour stage, together with the exact numerical outcomes for the bridge condition, the greedy comparator, and the d8/ar48 sentinel. This will allow readers to confirm that the frozen 0.010/0.020 thresholds were applied identically. Because each stage used distinct seed ranges, within-cell variance is not defined in the design; we will note this limitation explicitly rather than report a variance estimate. revision: yes
Circularity Check
No circularity: direct empirical measurements from frozen staged protocol
full rationale
The paper reports results from an executed staged-promotion protocol with explicitly frozen rules (0.010 val_bpb near-equivalence, 0.020 mean-gap) applied to twelve prior-screened configurations across fixed budgets. All central claims are direct measurements of GPU-hours, rankings, and rule outcomes from the runs themselves; no equations, fitted parameters renamed as predictions, or self-citation chains appear in the derivation. The text explicitly frames the outcome as a bounded cost-allocation finding rather than optimality or general derivation, rendering the chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- promotion thresholds =
0.010 and 0.020
- stage budgets =
2min/5min/10min/60min/12h
axioms (1)
- domain assumption Short pretraining runs provide usable ranking signal despite host sensitivity and instability
Reference graph
Works this paper leans on
-
[1]
Staged Factorial Screening for Budget-Constrained Micro-Pretraining
Felipe Chavarro Polania. Staged Factorial Screening for Budget-Constrained Micro-Pretraining. arXiv:2606.05186, 2026.https://arxiv.org/abs/2606.05186
Pith/arXiv arXiv 2026
-
[2]
Hyperband: A NovelBandit-BasedApproachtoHyperparameterOptimization
Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. Hyperband: A NovelBandit-BasedApproachtoHyperparameterOptimization. JournalofMachineLearningResearch, 18(185):1- 52, 2018.https://jmlr.org/papers/v18/16-558.html
2018
-
[3]
A System for Massively Parallel Hyperparameter Tuning
Liam Li, Kevin Jamieson, Afshin Rostamizadeh, Ekaterina Gonina, Jonathan Ben-tzur, Moritz Hardt, Benjamin Recht, and Ameet Talwalkar. A System for Massively Parallel Hyperparameter Tuning. Proceedings of Machine Learning and Systems, 2020.https://proceedings.mlsys.org/paper_files/paper/2020/hash/ a06f20b349c6cf09a6b171c71b88bbfc-Abstract.html
2020
-
[4]
BOHB: Robust and Efficient Hyperparameter Optimization at Scale
Stefan Falkner, Aaron Klein, and Frank Hutter. BOHB: Robust and Efficient Hyperparameter Optimization at Scale. Proceedings of the 35th International Conference on Machine Learning, PMLR 80:1437-1446, 2018. https://proceedings.mlr.press/v80/falkner18a.html
2018
-
[5]
Jesse Dodge, Suchin Gururangan, Dallas Card, Roy Schwartz, and Noah A. Smith. Show Your Work: Improved Reporting of Experimental Results. Proceedings of EMNLP-IJCNLP, pages 2185-2194, 2019.https: //aclanthology.org/D19-1224/
2019
-
[6]
Hwang, Luca Soldaini, Akshita Bhagia, Jiacheng Liu, Dirk Groeneveld, Oyvind Tafjord, Noah A
Ian Magnusson, Nguyen Tai, Ben Bogin, David Heineman, Jena D. Hwang, Luca Soldaini, Akshita Bhagia, Jiacheng Liu, Dirk Groeneveld, Oyvind Tafjord, Noah A. Smith, Pang Wei Koh, and Jesse Dodge. DataDecide: 13 How to Predict Best Pretraining Data with Small Experiments. arXiv:2504.11393, 2025.https://arxiv.org/ abs/2504.11393
arXiv 2025
-
[7]
Fantastic Pretraining Optimizers and Where to Find Them
Kaiyue Wen, David Hall, Tengyu Ma, and Percy Liang. Fantastic Pretraining Optimizers and Where to Find Them. arXiv:2509.02046, 2025.https://arxiv.org/abs/2509.02046 14
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.