Executable Schema Contracts: From Automatic Ingestion to Multi-Source Retrieval
Pith reviewed 2026-06-28 05:56 UTC · model grok-4.3
The pith
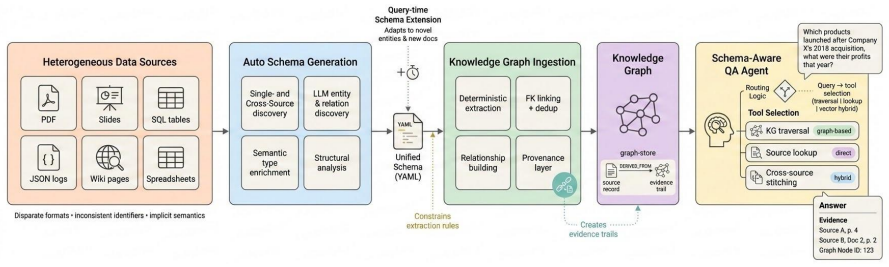
An automatically discovered executable schema acts as a shared contract for ingesting multi-source data into a knowledge graph and routing queries at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An executable schema contract derived automatically from heterogeneous sources via catalog-constrained discovery and deterministic structural analysis serves as the common interface for both building a provenance-aware knowledge graph and conditioning query-time retrieval across structured, graph, and vector tools, yielding higher accuracy than baselines that ignore structure or require manual decomposition.
What carries the argument
The executable schema contract, which encodes attested fields, keys, and hierarchy to guide both ingestion into a knowledge graph and conditional routing among retrieval tools.
If this is right
- Schema-guided construction produces a single provenance-aware knowledge graph from inconsistent input formats.
- Schema-conditioned routing lets one agent combine lookup, traversal, and vector search without task-specific training.
- Each of the three components (routing, structural intelligence, construction) contributes measurable gains when ablated.
- The full pipeline runs in zero-shot mode across four different QA benchmarks using the same underlying LLM.
Where Pith is reading between the lines
- The contract approach may generalize to enterprise settings where schemas evolve slowly and provenance is required for audit.
- A monotonic extension protocol could allow the schema to incorporate new sources without breaking existing queries.
- The same contract mechanism might be tested on scientific data collections that mix tabular measurements with textual reports.
Load-bearing premise
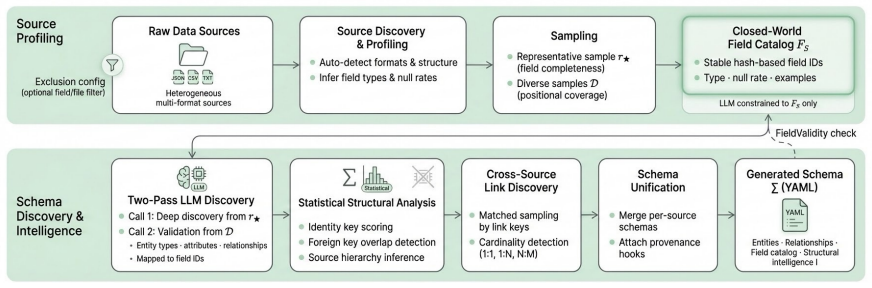
A closed-world field catalog can keep LLM schema discovery inside attested fields and deterministic structural analysis can correctly recover identity keys, foreign keys, and source hierarchy from raw data.
What would settle it
A controlled replication on a fresh multi-source corpus containing many fields absent from the catalog that shows no accuracy lift over the retrieval-only baseline under identical LLM and evaluation conditions.
Figures
read the original abstract
Real-world data spans tables, documents, and semi-structured files with implicit semantics. Querying this data requires integrating evidence across inconsistent schemas and formats, yet existing approaches either demand costly manual engineering or bypass structure entirely. We present a system that automatically discovers an executable schema from raw multi-source data and uses it as a shared contract for knowledge graph construction and query-time retrieval. A closed-world field catalog constrains LLM-based schema discovery to attested fields; deterministic structural analysis infers identity keys, foreign keys, and source hierarchy; and the resulting schema drives extraction, deduplication, and cross-source linking into a provenance-aware knowledge graph. At query time the schema -- optionally extended via a monotonic protocol -- conditions a multi-tool agent routing retrieval across structured lookup, graph traversal, and vector search, returning grounded answers with traceable citations. In controlled zero-shot comparisons using the same LLM, data, and evaluation harness, the system improves over retrieval-only and decomposition-based baselines across four QA benchmarks, with ablations showing that schema-conditioned routing, structural intelligence, and schema-guided construction each contribute to the gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a system called Executable Schema Contracts that automatically discovers an executable schema from raw multi-source heterogeneous data (tables, documents, semi-structured files). It uses a closed-world field catalog to constrain LLM-based discovery, deterministic structural analysis to infer identity keys, foreign keys, and source hierarchy, and the resulting schema to drive extraction, deduplication, and linking into a provenance-aware knowledge graph. At query time, the schema (optionally extended monotonically) conditions a multi-tool agent for routing across structured lookup, graph traversal, and vector search. The central claim is that, in controlled zero-shot comparisons with the same LLM, data, and harness, the system outperforms retrieval-only and decomposition-based baselines on four QA benchmarks, with ablations attributing gains to schema-conditioned routing, structural intelligence, and schema-guided construction.
Significance. If the empirical improvements and ablation results hold under detailed, reproducible evaluation, the work could provide a practical bridge between costly manual schema engineering and purely unstructured retrieval for real-world multi-source data integration, with added value from provenance tracking and monotonic extension.
major comments (1)
- [Abstract] Abstract: The central empirical claim of performance gains over baselines across four QA benchmarks, plus the specific contributions of the three ablated components, is asserted without any description of the benchmarks, metrics, statistical significance tests, data characteristics, baseline implementations, or controls for post-hoc choices. This absence leaves the primary result without verifiable support.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater specificity in the abstract regarding our empirical claims. We address this point below and commit to revisions that improve verifiability without altering the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim of performance gains over baselines across four QA benchmarks, plus the specific contributions of the three ablated components, is asserted without any description of the benchmarks, metrics, statistical significance tests, data characteristics, baseline implementations, or controls for post-hoc choices. This absence leaves the primary result without verifiable support.
Authors: We agree that the abstract is concise by design and therefore omits the requested experimental details, which are instead provided in full in the Experiments and Ablations sections of the manuscript (including benchmark names and characteristics, exact metrics, significance testing, baseline code and prompting details, and controls for post-hoc analysis). To directly address the concern and make the primary result more verifiable from the abstract alone, we will revise the abstract to incorporate a brief clause summarizing the four QA benchmarks, the primary metrics, and the fact that gains are supported by ablations and statistical controls. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical system for automatic schema discovery and multi-source retrieval, with claims supported by controlled zero-shot comparisons on four QA benchmarks and component ablations. No equations, derivations, or mathematical predictions appear in the abstract or described architecture. The evaluation uses external baselines and the same LLM/data harness, making results falsifiable outside any internal definitions. No self-citation load-bearing steps, fitted inputs renamed as predictions, or ansatz smuggling are present. The central claims rest on experimental outcomes rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hoprag: Multi-hop reasoning for logic-aware retrieval-augmented generation.arXiv preprint arXiv:2502.12442. Tom Mitchell, William W. Cohen, Estevam Hruschka, Partha Talukdar, Justin Betteridge, Andrew Carlson, Bhavana Dalvi, Matt Gardner, Bryan Kisiel, Jayant Krishnamurthy, Nicholas Lao, and 1 others. 2018. Never-ending learning.Communications of the ACM,...
arXiv 2018
-
[2]
Wentao Wu, Hongsong Li, Haixun Wang, and Kenny Q
Stark: Benchmarking llm retrieval on tex- tual and relational knowledge bases.NeurIPS 2024 Datasets and Benchmarks Track (dataset repo / preprint). Wentao Wu, Hongsong Li, Haixun Wang, and Kenny Q. Zhu. 2012. Probase: A probabilistic taxonomy for text understanding. InProceedings of the 2012 ACM SIGMOD International Conference on Management of Data, pages...
arXiv 2024
-
[3]
Source discovery:Scan the input directory, detect file formats, and group files into logical sources
-
[4]
Profiling:For each source, enumerate observ- able fields and compute statistics (types, null rates, cardinalities)
-
[5]
Field catalog construction:Build the closed- world catalogF S with stable field identifiers
-
[6]
Sampling:Select representative sample r⋆ and diverse setD
-
[7]
Two-pass LLM discovery:Extract entities and relationships via two targeted LLM calls
-
[8]
Structural inference:Detect identity keys, foreign keys, and hierarchy using statistical methods (no LLM). Algorithm 1Source Discovery 1:procedureDISCOVERSOURCES(root) 2:S ← ∅ 3: foreach path p in RECURSIVELIST( root) do 4: ifISDIRECTORY( p)andCOUNT- FILES( p) ≥50 andSTRUCTSIM( p) ≥0.8 then 5:S ← S ∪ {CORPUSSOURCE(p)} 6:else ifISSUPPORTEDFILE(p)then 7:S ←...
-
[9]
one”; otherwise “many
Cross-source linking and unification:Dis- cover inter-source relationships and merge per- source schemas intoΣ. The remainder of this section details each stage. A.3 Source Discovery and Corpus Detection The pipeline begins by scanning the input directory to identify data sources. We support JSON, JSONL, CSV , and Excel files. A key challenge is handling ...
-
[10]
Discover link keys:Identify candidate fields that connect sources (using the foreign key detection from Section A.7)
-
[11]
Group by key value:For each source, group sampled records by their link key value
-
[12]
Find common values:Identify key values that appear in both sources
-
[13]
Load matched sets:For each common value, retrieve all records from both sources sharing that value
-
[14]
Algorithm 2 provides pseudocode for this proce- dure
Analyze matched pairs:The LLM analyzes matched record sets to discover semantic rela- tionships. Algorithm 2 provides pseudocode for this proce- dure. 13 This approach correctly handles all cardinalities: for a given key value, we retrieveallmatching records from both sources, revealing the true rela- tionship structure. A.8.2 Companion Source Detection A...
-
[15]
Source discovery:Excluded files are re- moved from the source list
-
[16]
Sampling:Excluded fields are stripped from all samples before LLM analysis. Table 5: Leakage control: excluded fields and files per dataset Dataset Type Excluded Fields/Files BLENDQA hybrid_qa_kbquestion , sub_q1, sub_q2, long_answer, short_- answer,answers. HYBRIDQA qa_evaluationquestion , question_- id, question_postag, answer-text,answer-node. TAT-QA h...
-
[17]
add type Number
Schema finalization:Entities and attributes referencing excluded fields are removed. Re- lationships with orphaned endpoints (referenc- ing removed entities) are also removed. A.10.2 Per-Dataset Leakage Control Table 5 details the fields and files excluded for each evaluation dataset to prevent ground-truth leakage. This design allows raw benchmark files ...
-
[18]
Configuration:Specify ground-truth exclu- sions for the target dataset via a Y AML mani- fest
-
[19]
Pipeline stages:The schema generation script invokes the following modules in se- quence: • Multi-source orchestrator (coordinates per-source analysis) • LLM-based dataset analyzer (two-pass entity/relationship discovery) • Structural analyzer (identity keys, for- eign keys, JSON paths) • Semantic type enricher (canonical type mapping) • Ground-truth filt...
-
[20]
Output:Executable schema in YAML for- mat
-
[21]
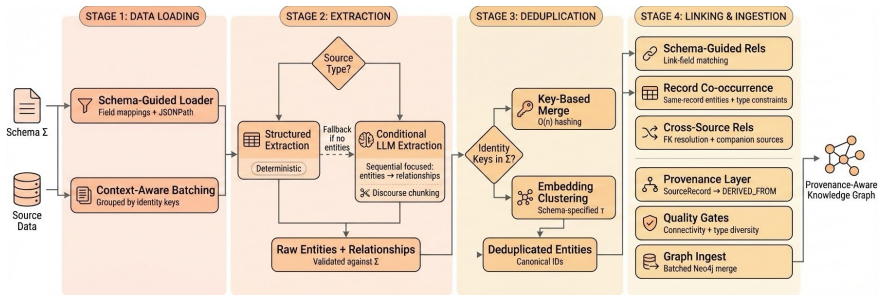
Key parameters:Sample size per source (default: 50), LLM model (GPT-4.1), field catalog enumeration (automatic), corpus file threshold (50), structural similarity threshold (0.8) B KG Ingestion Pipeline: Technical Details This appendix provides implementation details for the schema-guided KG ingestion pipeline described in Section 3.3. Given a schema Σ an...
-
[22]
Source ordering:Determine processing or- der from schema hierarchy (parents before children)
-
[23]
Entity extraction:Apply multi-strategy ex- traction per source
-
[24]
Deduplication:Merge duplicate entities via identity keys and clustering
-
[25]
Relationship extraction:Build edges using three parallel strategies plus cross-source FK resolution
-
[26]
sub_source1[*]
Neo4j ingestion:Write nodes and edges with provenance tracking. B.2 Source Ordering When the schema defines hierarchical relationships between sources (e.g., parent entities referenced by child passages), we process parent sources first to ensure foreign key targets exist before children reference them. Source hierarchy is inferred during schema generatio...
-
[27]
Section headers (HTML markers such as <h1>/<h2>, or markdown headings)
-
[28]
Discourse boundaries (speaker turns, para- graph breaks)
-
[29]
This reduces total LLM calls by avoiding a separate relationship extraction pass
Sliding window (fallback) Algorithm 4Identity Key Deduplication 1: procedureDEDUPLICATE- BYKEY(E,key_field) 2:G←GROUPBY(E, λe: e.attributes[key_field]) 3:E ′ ← ∅ 4:for(key,group)∈Gdo 5:if|group|>1then 6:e merged ← MERGEENTITIES(group) 7:else 8:e merged ←group[0] 9:end if 10:E ′ ←E ′ ∪ {emerged} 11:end for 12:returnE ′ 13:end procedure Co-extraction.During...
-
[30]
Embed:Convert each entity to text and com- pute sentence embeddings (all-MiniLM-L6- v2, 384-d)
-
[31]
Cluster:Apply agglomerative clustering with distance threshold 0.15 (i.e., similarity ≥ 0.85). 17
-
[32]
Merge:For each cluster with >1 entity, merge into a canonical form preserving all source references. B.4.3 ID Mapping Deduplication produces a mapping from temporary IDs to canonical IDs: id_map:temp_id→canonical_id This mapping is applied to all relationship end- points before Neo4j ingestion, and duplicate rela- tionships are removed. B.5 Three-Strategy...
-
[33]
All entities have at least one DERIVED_FROM edge to aSourceRecord. 18
-
[34]
SourceRecord nodes preserve original field values for traceability (e.g., entity_id, record_id)
-
[35]
Revenue” is covered by schema-derived “FinancialMetric
Answer citations can be traced back to specific source records via graph traversal. The provenance layer enables answer grounding: when the QA agent returns an answer, it can cite the specific source records that supplied the supporting evidence via theDERIVED_FROM relationship chain. B.7 Quality Validation and Dataset Preparation B.7.1 Quality Metrics Be...
-
[36]
Prerequisites:Generated executable schema (from Section A)
-
[37]
Pipeline stages:The ingestion driver invokes the following modules: • Pipeline orchestrator (batching, paral- lelism, progress tracking) • Multi-strategy entity extractor (struc- tured + conditional LLM extraction) • Two-stage entity deduplicator (identity- key + embedding-based) • Three-strategy relationship extractor (FK links, type patterns, LLM) • Cro...
-
[38]
Configuration:Neo4j connection via envi- ronment variables or a local settings file
-
[39]
Key parameters:Batch size (default: 100), max workers (default: 8), chunk size (8,000 chars), overlap (500 chars), similarity thresh- old (0.85), embedding model ( all-MiniLM- L6-v2)
-
[40]
C Schema Extension: Technical Details This appendix provides implementation details for the schema extension system described in Sec- tion 3.4
Output:Neo4j graph with provenance edges (DERIVED_FROM). C Schema Extension: Technical Details This appendix provides implementation details for the schema extension system described in Sec- tion 3.4. C.1 Architecture Overview The extension system comprises two complemen- tary components with different analysis depths:
-
[41]
SchemaExtender(persistent): Permanently extends the schema when new documents ar- rive. Runs the full analysis pipeline – two- pass LLM discovery, structural analysis (iden- tity keys, foreign keys, JSON paths), and semantic type enrichment – identical to ini- tial schema generation (Section A), ensuring methodological consistency and quality par- ity
-
[42]
sovereign state
QueryDrivenSchemaExtender(query- scoped): Extends the schema in-memory for a specific query with automatic revert. Uses a single LLM call to analyze query requirements and propose candidate entity types with confidence scores, trading analysis depth for speed ( ∼8× faster than persistent extension). C.2 Sufficiency Analysis Before invoking expensive deep ...
-
[43]
Two-pass LLM discovery:Deep + valida- tion passes to extract entities and relationships from the new data
-
[44]
Semantic enrichment:Detect additional en- tity types from data values (not field names alone). Algorithm 7Schema Diff Computation 1:procedureCOMPUTEDIFF(analysis,Σ) 2:diff← {new_entities: [],new_attrs: {},new_rels: []} 3:E existing ←GETENTITIES(Σ) 4:fore∈analysis.entitiesdo 5:ife.type/∈E existing then 6:diff.new_entities.APPEND(e) 7:else 8:A new ←e.attrs\...
-
[45]
2026-01-26T14:30:00Z
Structural analysis:Detect identity keys, for- eign keys, and JSON paths – all without LLM involvement. This produces a complete intelligence package methodologically identical to the initial schema. Query-scoped extension uses a lighter single-call analysis (Section C.6). C.4 Diff-Based Merge We compute a schema diff to identify additions without modifyi...
2026
-
[46]
current”, “latest
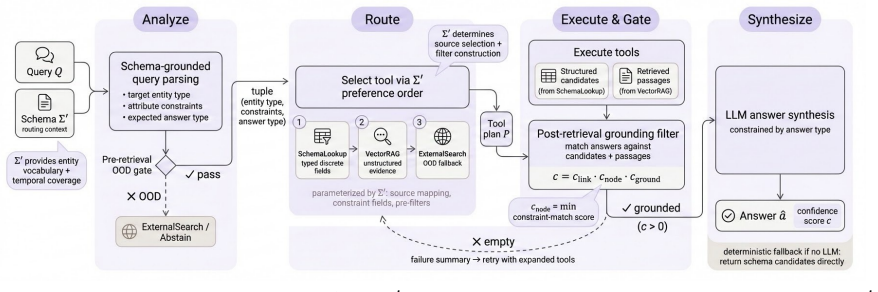
Temporal OOD: keywords indicating real- time information needs (“current”, “latest”, “today”) or year references beyondΣ′’s tem- poral range
-
[47]
If either check fires, the query is flagged OOD and routed directly to EXTERNALSEARCH
Entity OOD: extracted entity mentions (e.g., tickers) that do not appear in Σ′’s known- value dictionaries. If either check fires, the query is flagged OOD and routed directly to EXTERNALSEARCH. Post-retrieval (Stage 2).After tool execution, the agent checks:
-
[48]
Retrieval confidence: if the maximum sim- ilarity score across retrieved passages falls below a threshold (default 0.3), the result is flagged as low-confidence
-
[49]
I cannot determine
Answer grounding: if the generated answer contains uncertainty phrases (e.g., “I cannot determine”), the result is flagged. Flagged queries trigger a fallback to EXTER- NALSEARCHand confidence is discounted. D.4 Routing Policy Routing isschema-driven: the agent prefers deter- ministic structure when the schema exposes typed, discrete-valued fields. The po...
-
[50]
the FIELD CATALOG (authoritative list of fields), and
-
[51]
DO NOT invent fields, entities, or relationships that are not evidenced in the samples
the SAMPLE DATA provided (may include multiple samples). DO NOT invent fields, entities, or relationships that are not evidenced in the samples. PRIORITIZE COMPLETENESS: model ALL entity types and relationships across all samples provided. Dataset:{description} Source Format:{format} (JSON / CSV / Parquet / Text / Hybrid) Total Records:{num_records} FIELD...
-
[52]
INSTANCE-BASED: same specific instance appears multiple times (e.g., same person, organization, identifier)
-
[53]
CONCEPTUAL / CATEGORICAL: different instances of the same concept type (e.g., FinancialMetric, Product, TimePeriod). For each entity provide: name, description, anchor (primary key or natural key), attributes (field_id, name, type_guess), extraction method (field|nested_field|pattern|llm), examples, and confidence in [0,1]. Include a SourceRecord entity f...
-
[54]
Preserve existing schema by default
-
[55]
Add NEW entities for any distinct uncaptured concepts
-
[56]
Add NEW relationships for any clear connections
-
[57]
Add NEW attributes for existing entities if found
-
[58]
Note issues but do not remove existing elements. FIELD CATALOG (authoritative): {catalog_summary} EXISTING SCHEMA (authoritative; must be preserved): Entities: {entity_summary} Relationships: {relationship_summary} Temporal: {temporal_info} ADDITIONAL SAMPLES (only for gap finding): {samples_str} WHAT TO LOOK FOR: Step 1 – Check field catalog for uncovere...
-
[59]
Identify entity types mentioned or implied
-
[60]
Determine if any are MISSING from existing entities
-
[61]
Identify any relationships needed that are MISSING
-
[62]
needs_extension
For each missing item, provide: - Type name - Confidence (0.0–1.0) - Reason why needed - Example instances from the query - Attributes to track Return JSON: { "needs_extension": true/false, "required_entities": [ {"type": "...", "confidence": 0.95, "reason": "...", "examples": [...], "attributes": [...]} ], "required_relationships": [ {"type": "...", "sou...
-
[63]
Parse the schema to identify relevant entity types, relationships, and field semantics
-
[64]
current”, “latest
Check for OOD signals: temporal keywords (“current”, “latest”), entity mentions absent from schema. If OOD, route directly to ExternalSearch
-
[65]
Select tools based on query type: - Typed, discrete-valued constraints→ SchemaLookup - Descriptive / unstructured evidence→ VectorRAG - Multi-hop or relationship queries→ GraphTraverse - Out-of-distribution→ExternalSearch
-
[66]
OUTPUT: {tool_calls} 27 F Adapted GraphRAG Baseline Adapted GraphRAG baseline
Generate tool calls with schema-derived parameters. OUTPUT: {tool_calls} 27 F Adapted GraphRAG Baseline Adapted GraphRAG baseline. GraphRAG (Edge et al., 2024) builds community- summarized graphs over text corpora and retrieves via community reports, targeting homogeneous text summarization rather than multi-source schema-guided QA. Applying it to our set...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.