STREAM: Stochastic Riemannian Flow Matching with Anisotropic Decoder for Digital Histopathology Image Generation
Pith reviewed 2026-06-27 22:37 UTC · model grok-4.3
The pith
STREAM uses Riemannian flow matching on hypersphere patch features from vision models to generate synthetic histopathology images without conditioning collapse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
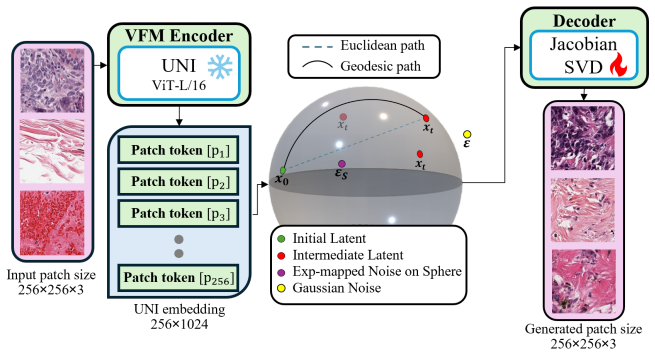
The central claim is that pretrained histopathology VFM patch-token features are l2-normalized and lie on the unit hypersphere S^{d-1} with strong angular dominance and intrinsic curvature, making them naturally suited for Riemannian formulation; STREAM therefore applies a bridge-type stochastic perturbation to establish per-token rectifiability on S^{d-1} for training a DiT in latent space together with a novel anisotropic decoder that allocates robustness to low-energy directions of the velocity-field Jacobian while preserving fidelity along its high-energy directions, yielding state-of-the-art reconstruction and generation on breast and colorectal cancer datasets.
What carries the argument
Stochastic Riemannian flow matching on unit-hypersphere patch-token features, using a bridge-type perturbation for rectifiability plus an anisotropic decoder that weights the velocity-field Jacobian by energy direction.
If this is right
- Avoids conditioning collapse by using VFM features as the latent space itself instead of as external conditioning.
- Achieves state-of-the-art reconstruction and generation performance on breast and colorectal cancer histopathology datasets.
- The stochastic perturbation establishes per-token rectifiability on the hypersphere for stable DiT training.
- The anisotropic decoder preserves high-energy fidelity while adding robustness in low-energy Jacobian directions.
Where Pith is reading between the lines
- The same hypersphere formulation may apply to other medical imaging domains where VFM patch features show comparable angular structure.
- Manifold-aware flow matching could reduce reliance on elaborate conditioning schemes across latent generative models.
- Higher diversity from this approach might improve downstream training of pathology foundation models on synthetic data.
- Direct tests on additional tissue types or non-cancer histopathology would clarify the range of the spherical assumption.
Load-bearing premise
The l2-normalized patch-token features possess strong angular dominance and intrinsic curvature that make Riemannian geometry on the hypersphere superior to Euclidean alternatives for this generation task.
What would settle it
Training the identical DiT and decoder pipeline with standard Euclidean flow matching on the same VFM features and observing whether reconstruction FID rises or sample diversity falls compared with the Riemannian version.
Figures
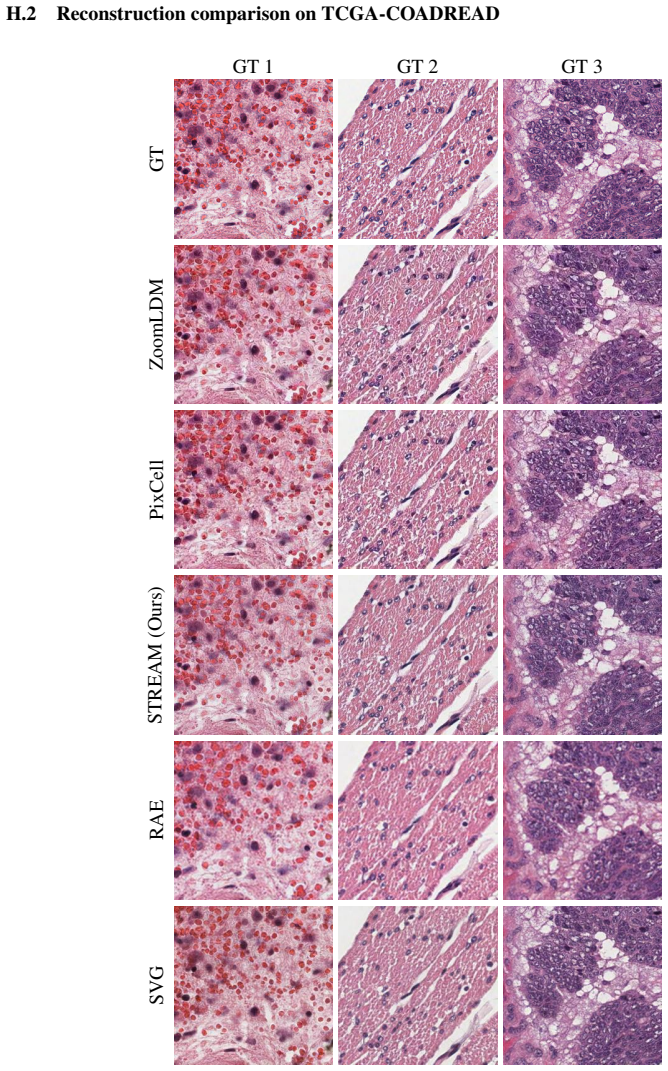
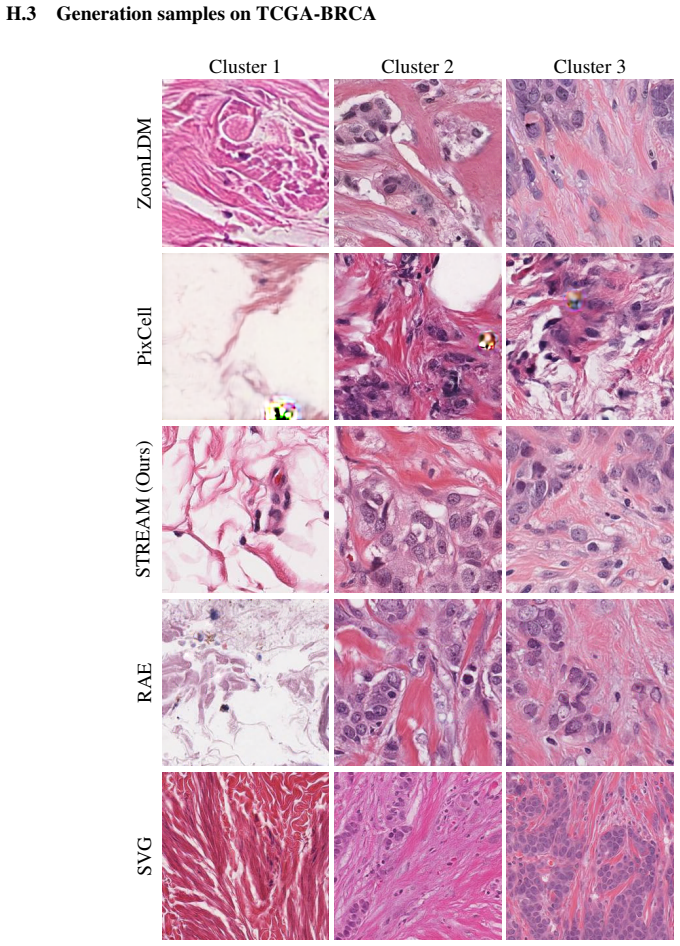
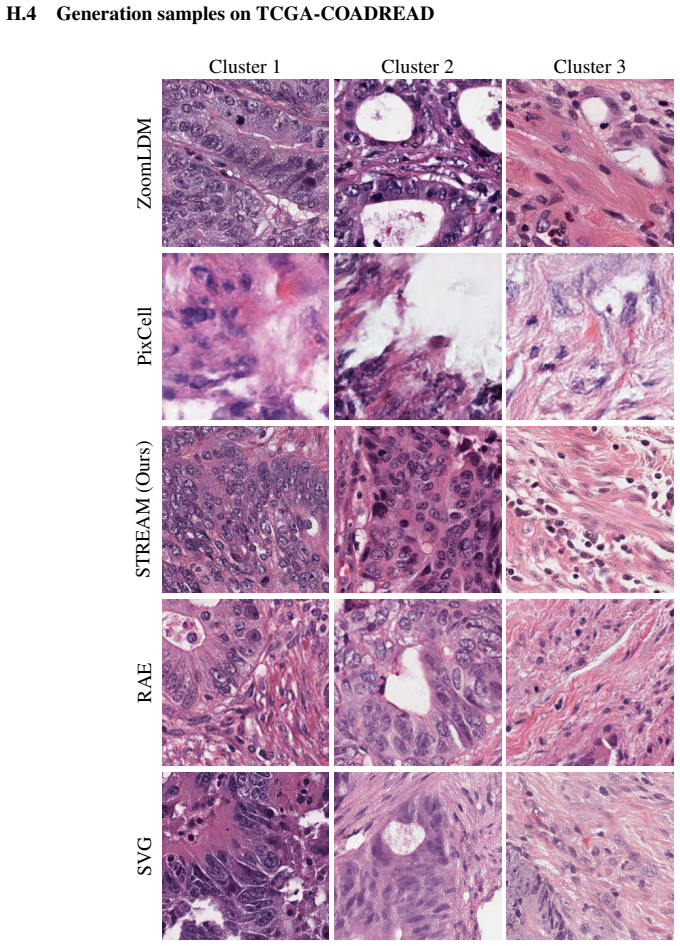
read the original abstract
Synthetic histopathology image generation addresses critical challenges in computational pathology, including patient privacy and the growing need for large-scale training data for foundation models. Latent diffusion models have dominated the image generation domain, with recent works emphasizing that the choice of latent space is critical to the quality of generated images. Existing state-of-the-art generative models in histopathology use pretrained Vision Foundation Models (VFMs) as conditioning signals, and we observe that this leads to "conditioning collapse," where the conditioning signal dominates the latent space and lowers the quality and diversity of generated samples. Therefore, we instead use pretrained histopathology VFMs as the latent space itself, leveraging their patch-token features that encode rich semantic information. We empirically show that these features are $\ell_2$-normalized and lie on the unit hypersphere $\mathcal{S}^{d-1}$ with strong angular dominance and intrinsic curvature, making them naturally suited for a Riemannian formulation. We therefore present STREAM, the first framework to apply Riemannian flow matching in the pathology domain. STREAM consists of two stages: 1) a bridge-type stochastic perturbation that establishes per-token rectifiability on $\mathcal{S}^{d-1}$ for training a Diffusion Transformer (DiT) in latent space, and 2) a novel anisotropic decoder that allocates robustness to low-energy directions of the velocity-field Jacobian while preserving fidelity along its high-energy directions. Together, STREAM achieves state-of-the-art reconstruction and generation performance on breast and colorectal cancer datasets. The code will be publicly released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes STREAM, a two-stage framework for histopathology image generation that treats ℓ_{2}-normalized patch-token features from pretrained VFMs as points on the unit hypersphere S^{d-1}. It introduces a bridge-type stochastic perturbation to enable rectifiable training of a DiT via Riemannian flow matching, paired with a novel anisotropic decoder that modulates Jacobian robustness along low- versus high-energy directions, claiming this avoids conditioning collapse and yields SOTA reconstruction and generation on breast and colorectal cancer datasets.
Significance. If the performance claims hold with proper controls, the work could meaningfully advance generative modeling in computational pathology by showing that Riemannian geometry on VFM latents can outperform conditioning-based baselines, while the public code release would aid reproducibility.
major comments (2)
- [Abstract] Abstract: the SOTA reconstruction and generation claims are unsupported by any quantitative results, error bars, baseline comparisons, dataset sizes, or metric values. This is load-bearing for the central empirical claim.
- [Abstract] Abstract (paragraph on empirical observation and method description): the assertion that the observed ℓ_{2}-normalization and angular dominance make the features 'naturally suited' for a Riemannian formulation is not accompanied by an ablation or comparison isolating the manifold geometry from the bridge perturbation or anisotropic decoder; without this, the necessity of the Riemannian component over Euclidean flow matching on the same normalized tokens remains unverified.
minor comments (1)
- [Abstract] Abstract: consider specifying the exact datasets (e.g., names and splits) and metrics used to support the SOTA statement.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the abstract must be revised to include quantitative support for the SOTA claims. On the second point, we will strengthen the presentation by adding a targeted ablation that isolates the contribution of the Riemannian geometry.
read point-by-point responses
-
Referee: [Abstract] Abstract: the SOTA reconstruction and generation claims are unsupported by any quantitative results, error bars, baseline comparisons, dataset sizes, or metric values. This is load-bearing for the central empirical claim.
Authors: We agree that the abstract, as currently written, does not contain the specific metric values, error bars, baseline names, or dataset sizes needed to substantiate the SOTA claim on first reading. The full manuscript reports these quantities (FID, reconstruction MSE, diversity metrics, dataset cardinalities for the breast and colorectal cohorts, and statistical significance) in the experimental sections and tables. We will revise the abstract to incorporate the key quantitative results and error bars so that the central empirical claim is self-contained and verifiable. revision: yes
-
Referee: [Abstract] Abstract (paragraph on empirical observation and method description): the assertion that the observed ℓ₂-normalization and angular dominance make the features 'naturally suited' for a Riemannian formulation is not accompanied by an ablation or comparison isolating the manifold geometry from the bridge perturbation or anisotropic decoder; without this, the necessity of the Riemannian component over Euclidean flow matching on the same normalized tokens remains unverified.
Authors: The abstract condenses the empirical observation that VFM patch tokens are ℓ₂-normalized and exhibit angular dominance. The full manuscript motivates the Riemannian formulation from these properties and evaluates the complete STREAM pipeline against Euclidean baselines. To directly address the referee’s request for isolation, we will add an explicit ablation that trains an otherwise identical Euclidean flow-matching model on the same normalized tokens and compares it to the Riemannian version (keeping the bridge perturbation and anisotropic decoder fixed where applicable). This will be included in the revised manuscript. revision: yes
Circularity Check
No circularity; derivation self-contained via empirical observation and new components
full rationale
The paper's chain starts from an empirical observation (ℓ2-normalized VFM patch tokens on S^{d-1}) that is presented as data-driven motivation rather than a definitional input. It then introduces independent elements (bridge-type stochastic perturbation for rectifiability and anisotropic decoder for Jacobian robustness) to build the Riemannian flow matching framework. No equations reduce a claimed prediction to a fitted parameter by construction, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatz is smuggled via prior author work. The SOTA claim is tied to reported performance on external datasets, not internal redefinition. This matches the default non-circular case.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pretrained histopathology VFMs produce ℓ2-normalized patch-token features lying on the unit hypersphere S^{d-1}
- domain assumption These features exhibit strong angular dominance and intrinsic curvature making them naturally suited for Riemannian flow matching
invented entities (1)
-
Anisotropic decoder
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Albergo and Eric Vanden-Eijnden
Michael S. Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InICLR, 2023
2023
-
[2]
Diffusions hypercontractives
Dominique Bakry and Michel Émery. Diffusions hypercontractives. InSéminaire de Proba- bilités XIX. Springer, 1985
1985
-
[3]
On the Convergence and Straightness of Rectified Flow
Vansh Bansal, Saptarshi Roy, Purnamrita Sarkar, and Alessandro Rinaldo. On the Wasserstein convergence and straightness of rectified flows.arXiv preprint arXiv:2410.14949, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
A computational fluid mechanics solution to the Monge–Kantorovich mass transfer problem.Numerische Mathematik, 84(3):375–393, 2000
Jean-David Benamou and Yves Brenier. A computational fluid mechanics solution to the Monge–Kantorovich mass transfer problem.Numerische Mathematik, 84(3):375–393, 2000
2000
-
[5]
Sutherland, Michael Arbel, and Arthur Gretton
Mikołaj Bi ´nkowski, Dougal J. Sutherland, Michael Arbel, and Arthur Gretton. Demystifying MMD GANs. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[6]
Hanna, Luke Geneslaw, Allen Miraflor, Vitor Werneck Krauss Silva, Klaus J
Gabriele Campanella, Matthew G. Hanna, Luke Geneslaw, Allen Miraflor, Vitor Werneck Krauss Silva, Klaus J. Busam, Edi Brogi, Victor E. Reuter, David S. Klimstra, and Thomas J. Fuchs. Clinical-grade computational pathology using weakly supervised deep learning on whole slide images.Nature Medicine, 25:1301–1309, 2019
2019
-
[7]
Hyperspherical Autoencoder for High-Fidelity Image Reconstruction and Generation
Hun Chang, Byunghee Cha, and Jong Chul Ye. DINO-SAE: DINO spherical autoencoder for high-fidelity image reconstruction and generation.arXiv preprint arXiv:2601.22904, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Aligning visual foundation encoders to tokenizers for diffusion models
Bowei Chen, Sai Bi, Hao Tan, He Zhang, Tianyuan Zhang, Zhengqi Li, Yuanjun Xiong, Jian- ming Zhang, and Kai Zhang. Aligning visual foundation encoders to tokenizers for diffusion models. InICLR, 2026
2026
-
[9]
Masked autoencoders are effective tokenizers for diffusion models
Hao Chen, Yujin Han, Fangyi Chen, et al. Masked autoencoders are effective tokenizers for diffusion models. InICML, 2025
2025
-
[10]
Chen, Tong Ding, Ming Y
Richard J. Chen, Tong Ding, Ming Y . Lu, Drew F. K. Williamson, et al. Towards a general- purpose foundation model for computational pathology.Nature Medicine, 30(3):850–862, 2024
2024
-
[11]
Ricky T. Q. Chen and Yaron Lipman. Flow matching on general geometries. InICLR, 2024
2024
-
[12]
do Carmo.Riemannian Geometry
Manfredo P. do Carmo.Riemannian Geometry. Birkhäuser, 1992
1992
-
[13]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021
2021
-
[14]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Björn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[15]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorber, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InICML, 2024
2024
-
[16]
The Vendi score: A diversity evaluation metric for machine learning.Transactions on Machine Learning Research, 2023
Dan Friedman and Adji Bousso Dieng. The Vendi score: A diversity evaluation metric for machine learning.Transactions on Machine Learning Research, 2023
2023
-
[17]
Learned representation-guided diffusion models for large- image generation
Alexandros Graikos, Srikar Yellapragada, Minh-Quan Le, Saarthak Kapse, Prateek Prasanna, Joel Saltz, and Dimitris Samaras. Learned representation-guided diffusion models for large- image generation. InCVPR, 2024
2024
-
[18]
Nathan Halko, Per-Gunnar Martinsson, and Joel A. Tropp. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions.SIAM Review, 53(2):217–288, 2011
2011
-
[19]
On the relation between rectified flows and optimal transport.arXiv preprint arXiv:2505.19712, 2025
Johannes Hertrich, Antonin Chambolle, and Julie Delon. On the relation between rectified flows and optimal transport.arXiv preprint arXiv:2505.19712, 2025
-
[20]
GANs trained by a two time-scale update rule converge to a local Nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochre- iter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. In NeurIPS, 2017. 10
2017
-
[21]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020
2020
-
[22]
Conditional Vendi Score: Prompt-Aware Diversity Evaluation for Generative AI Models and LLMs
Mohammad Jalali, Azim Ospanov, Amin Gohari, and Farzan Farnia. Conditional vendi score: An information-theoretic approach to diversity evaluation of prompt-based generative models. arXiv preprint arXiv:2411.02817, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Mohammad Jalali, Bahar Dibaei Nia, and Farzan Farnia. Towards an explainable comparison and alignment of feature embeddings.arXiv preprint arXiv:2506.06231, 2025
-
[24]
Rethinking FID: Towards a better evaluation metric for image generation
Sadeep Jayasumana, Srikumar Ramalingam, Andreas Veit, Daniel Glasner, Ayan Chakrabarti, and Sanjiv Kumar. Rethinking FID: Towards a better evaluation metric for image generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[25]
kaiko.ai, Nanne Aben, Edwin D. de Jong, Ioannis Gatopoulos, Nicolas Känzig, Mikhail Karasikov, Axel Lagré, Roman Moser, Joost van Doorn, and Fei Tang. Towards large-scale training of pathology foundation models.arXiv preprint arXiv:2404.15217, 2024
-
[26]
EQ-V AE: Equivariance regularized latent space for improved generative image modeling
Theodoros Kouzelis, Ioannis Kakogeorgiou, Spyros Gidaris, and Nikos Komodakis. EQ-V AE: Equivariance regularized latent space for improved generative image modeling. InICML, 2025
2025
- [27]
-
[28]
InECCV, 2024
Minh-Quan Le, Alexandros Graikos, Srikar Yellapragada, Rajarsi Gupta, Joel Saltz, and Dim- itris Samaras.∞-Brush: Controllable large image synthesis with diffusion models in infinite dimensions. InECCV, 2024
2024
-
[29]
Lee.Introduction to Riemannian Manifolds
John M. Lee.Introduction to Riemannian Manifolds. Springer, 2nd edition, 2018
2018
-
[30]
Geometry-aware image flow matching
Junho Lee, Kwanseok Kim, and Joonseok Lee. Geometry-aware image flow matching. In International Conference on Machine Learning (ICML), 2026
2026
-
[31]
Improving the training of rectified flows
Sangyun Lee, Zinan Lin, and Giulia Fanti. Improving the training of rectified flows. In NeurIPS, 2024
2024
-
[32]
REPA-E: Unlocking V AE for end-to-end tuning with latent diffusion transformers
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. REPA-E: Unlocking V AE for end-to-end tuning with latent diffusion transformers. InICCV, 2025
2025
-
[33]
Back to Basics: Let Denoising Generative Models Denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InICLR, 2023
2023
-
[35]
Geert Litjens, Thijs Kooi, Babak Ehteshami Bejnordi, Arnaud Arindra Adiyoso Setio, Francesco Ciompi, Mohsen Ghafoorian, Jeroen A. W. M. van der Laak, Bram van Ginneken, and Clara I. Sánchez. A survey on deep learning in medical image analysis.Medical Image Analysis, 42:60–88, 2017
2017
-
[36]
Rectified Flow: A Marginal Preserving Approach to Optimal Transport
Qiang Liu. Rectified flow: A marginal preserving approach to optimal transport.arXiv preprint arXiv:2209.14577, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Improving reconstruction of representation autoencoder.arXiv preprint arXiv:2602.08620, 2026
Siyu Liu, Chujie Qin, Hubery Yin, Qixin Yan, Zheng-Peng Duan, Chen Li, Jing Lyu, Chun-Le Guo, and Chongyi Li. Improving reconstruction of representation autoencoder.arXiv preprint arXiv:2602.08620, 2026
-
[38]
Flow straight and fast: Learning to generate and transfer data with rectified flows
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flows. InICLR, 2023
2023
-
[39]
On the regularity of solutions of optimal transportation problems.Acta Mathematica, 202(2):241–283, 2009
Grégoire Loeper. On the regularity of solutions of optimal transportation problems.Acta Mathematica, 202(2):241–283, 2009
2009
-
[40]
Lu, Bowen Chen, Drew F
Ming Y . Lu, Bowen Chen, Drew F. K. Williamson, Richard J. Chen, Ivy Liang, Tong Ding, Guillaume Jaume, Igor Odintsov, Long Phi Le, Georg Gerber, Anil V . Sahai, and Faisal Mah- mood. A visual-language foundation model for computational pathology.Nature Medicine, 2024
2024
-
[41]
Albergo, Nicholas M
Nanye Ma, Mark Goldstein, Michael S. Albergo, Nicholas M. Boffi, Eric Vanden-Eijnden, and Saining Xie. SiT: Exploring flow and diffusion-based generative models with scalable interpolant transformers. InECCV, 2024. 11
2024
-
[42]
Trudinger, and Xu-Jia Wang
Xi-Nan Ma, Neil S. Trudinger, and Xu-Jia Wang. Regularity of potential functions of the optimal transportation problem.Archive for Rational Mechanics and Analysis, 177(2):151– 183, 2005
2005
-
[43]
Co-synthesis of histopathology nuclei image- label pairs using a context-conditioned joint diffusion model
Seonghui Min, Hyun-Jic Oh, and Won-Ki Jeong. Co-synthesis of histopathology nuclei image- label pairs using a context-conditioned joint diffusion model. InECCV, 2024. doi: 10.1007/ 978-3-031-72624-8_9
2024
-
[44]
Spider: A com- prehensive multi-organ supervised pathology dataset and baseline models
Dmitry Nechaev, Alexey Pchelnikov, and Ekaterina Ivanova. SPIDER: A compre- hensive multi-organ supervised pathology dataset and baseline models.arXiv preprint arXiv:2503.02876, 2025
-
[45]
DINOv2: Learning robust visual fea- tures without supervision.TMLR, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khali- dov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud As- sran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patric...
2024
-
[46]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[47]
Nonparametric regression estimation on closed Riemannian manifolds.Jour- nal of Nonparametric Statistics, 18(1):57–67, 2006
Bruno Pelletier. Nonparametric regression estimation on closed Riemannian manifolds.Jour- nal of Nonparametric Statistics, 18(1):57–67, 2006
2006
-
[48]
Image tokenizer needs post-training.arXiv preprint arXiv:2509.12474, 2025
Kai Qiu, Xiang Li, Hao Chen, Jason Kuen, Xiaohao Xu, Jiuxiang Gu, Yinyi Luo, Bhiksha Raj, Zhe Lin, and Marios Savvides. Image tokenizer needs post-training.arXiv preprint arXiv:2509.12474, 2025
-
[49]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
2022
-
[50]
Latent diffusion model without variational autoencoder.arXiv preprint arXiv:2510.15301, 2025
Minglei Shi, Haolin Wang, Wenzhao Zheng, Ziyang Yuan, Xiaoshi Wu, Xintao Wang, Pengfei Wan, Jie Zhou, and Jiwen Lu. Latent diffusion model without variational autoencoder.arXiv preprint arXiv:2510.15301, 2025
-
[51]
RecTok: Reconstruction distillation along rectified flow
Qingyu Shi, Size Wu, Jinbin Bai, Kaidong Yu, Yujing Wang, Yunhai Tong, Xiangtai Li, and Xuelong Li. RecTok: Reconstruction distillation along rectified flow. InCVPR, 2026
2026
-
[52]
Oriane Simeoni et al. DINOv3.arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Hao Tang, Chenwei Xie, Xiaoyi Bao, Tingyu Weng, Pandeng Li, Yun Zheng, and Liwei Wang. UniLiP: Adapting clip for unified multimodal understanding, generation and editing.arXiv preprint arXiv:2507.23278, 2025
-
[54]
The Cancer Genome Atlas Network. Comprehensive molecular characterization of human colon and rectal cancer.Nature, 487(7407):330–337, 2012. doi: 10.1038/nature11252
-
[55]
Comprehensive molecular portraits of human breast tumours.Nature, 490:61–70, 2012
The Cancer Genome Atlas Network. Comprehensive molecular portraits of human breast tumours.Nature, 490:61–70, 2012
2012
-
[56]
von Renesse and Karl-Theodor Sturm
Max-K. von Renesse and Karl-Theodor Sturm. Transport inequalities, gradient estimates, en- tropy and Ricci curvature.Communications on Pure and Applied Mathematics, 58(7):923–940, 2005
2005
-
[57]
Self-improving generative foundation model for synthetic medical image generation and clinical applications.Nature Medicine, 31 (2):609–617, 2025
Jinzhuo Wang, Kai Wang, Yunfang Yu, Yuxing Lu, et al. Self-improving generative foundation model for synthetic medical image generation and clinical applications.Nature Medicine, 31 (2):609–617, 2025
2025
-
[58]
Diffuse and Disperse: Im- age Generation with Representation Regularization, 2025
Runqian Wang and Kaiming He. Diffuse and disperse: Image generation with representation regularization.arXiv preprint arXiv:2506.09027, 2025
-
[59]
Olguin, Jeffrey J
Jinxi Xiang, Xiyue Wang, Xiaoming Zhang, Yinghua Xi, Feyisope Eweje, Yuchen Chen, Yuan- feng Li, Colin Bergstrom, Matthew Gopaulchan, Ted Kim, Kun-Hsing Yu, Sierra Willens, Francesca M. Olguin, Jeffrey J. Nirschl, Joel Neal, Maximilian Diehn, Sen Yang, and Ruijiang Li. A vision-language foundation model for precision oncology.Nature, 638(8051):769–778, 2025
2025
-
[60]
Conghao Xiong, Zhengrui Guo, Zhe Xu, Yifei Zhang, Raymond Kai-yu Tong, Si Yong Yeo, Hao Chen, Joseph J. Y . Sung, and Irwin King. Exploiting low-dimensional manifold of features for few-shot whole slide image classification. InICLR, 2026. 12
2026
-
[61]
A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):181–188, 2024
Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, Sheng Zhang, et al. A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):181–188, 2024
2024
-
[62]
TopoCellGen: Generating histopathology cell topology with a diffusion model
Meilong Xu, Saumya Gupta, Xiaoling Hu, Chen Li, Shahira Abousamra, Dimitris Samaras, Prateek Prasanna, and Chao Chen. TopoCellGen: Generating histopathology cell topology with a diffusion model. InCVPR, 2025
2025
-
[63]
Latent denoising makes good visual tokenizers.arXiv preprint arXiv:2507.15856, 2025
Jiawei Yang, Tianhong Li, Lijie Fan, Yonglong Tian, and Yue Wang. Latent denoising makes good visual tokenizers.arXiv preprint arXiv:2507.15856, 2025
-
[64]
Reconstruction vs
Jingfeng Yao, Bin Yang, and Xinggang Wang. Reconstruction vs. generation: Taming opti- mization dilemma in latent diffusion models. InCVPR, 2025
2025
-
[65]
PathLDM: Text conditioned latent diffusion model for histopathology
Srikar Yellapragada, Alexandros Graikos, Prateek Prasanna, Tahsin Kurc, Joel Saltz, and Dim- itris Samaras. PathLDM: Text conditioned latent diffusion model for histopathology. In IEEE/CVF Winter Conf. Appl. Comput. Vis., 2024
2024
-
[66]
Knudsen, Tahsin Kurc, Rajarsi R
Srikar Yellapragada, Alexandros Graikos, Zilinghan Li, Kostas Triaridis, Varun Belagali, Tarak Nath Nandi, Karen Bai, Beatrice S. Knudsen, Tahsin Kurc, Rajarsi R. Gupta, Prateek Prasanna, Ravi K. Madduri, Joel Saltz, and Dimitris Samaras. PixCell: A generative founda- tion model for digital histopathology images.arXiv preprint arXiv:2506.05127, 2025
-
[67]
Representation alignment for generation: Training diffusion transformers is easier than you think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think. InICLR, 2025
2025
-
[68]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InCVPR, 2018
2018
-
[69]
Vision foundation models as effective visual tokenizers for autore- gressive image generation
Anlin Zheng, Xin Wen, Xuanyang Zhang, Chuofan Ma, Tiancai Wang, Gang Yu, Xiangyu Zhang, and Xiaojuan Qi. Vision foundation models as effective visual tokenizers for autore- gressive image generation. InNeurIPS, 2025
2025
-
[70]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders.arXiv preprint arXiv:2510.11690, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Stabilize the latent space for image autoregressive modeling: A unified perspective
Yongxin Zhu, Bocheng Li, Hang Zhang, Xin Li, Linli Xu, and Lidong Bing. Stabilize the latent space for image autoregressive modeling: A unified perspective. InNeurIPS, 2024
2024
-
[72]
Virchow2:Scalingself-supervisedmixedmagnification models in pathology
Eric Zimmermann, Eugene V orontsov, Julian Viret, Adam Casson, Michal Zelechowski, George Shaikovski, Neil Tenenholtz, James Hall, David Klimstra, Razik Yousfi, Thomas Fuchs, Nicolo Fusi, Siqi Liu, and Kristen Severson. Virchow2: Scaling self-supervised mixed magnification models in pathology.arXiv preprint arXiv:2408.00738, 2024. 13 A Mathematical Prelim...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.