Phantom transitions in language model fine-tuning
Pith reviewed 2026-06-29 21:52 UTC · model grok-4.3
The pith
The apparent phase transitions in language model fine-tuning on near-synonym tasks are artifacts that live only in the softmax readout.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
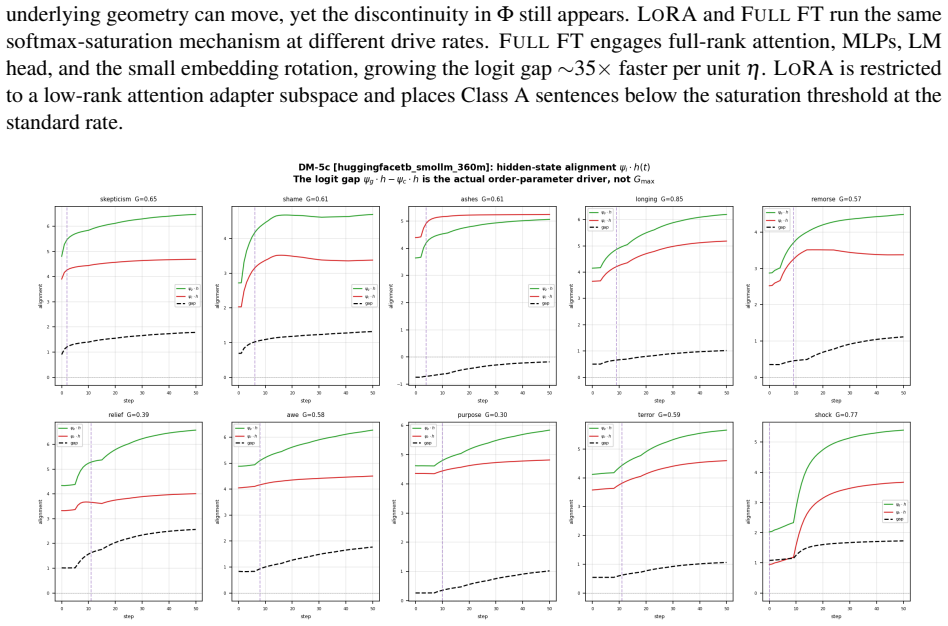
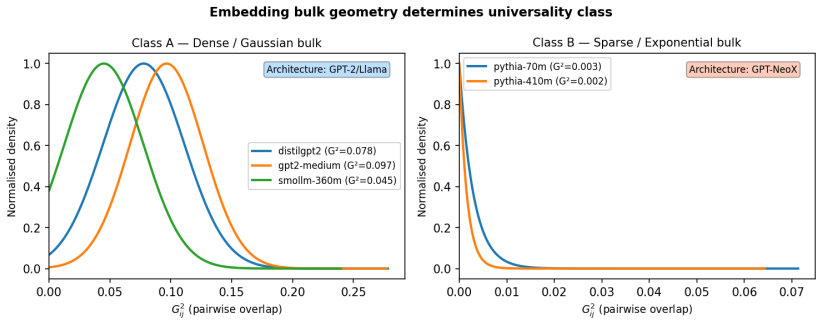
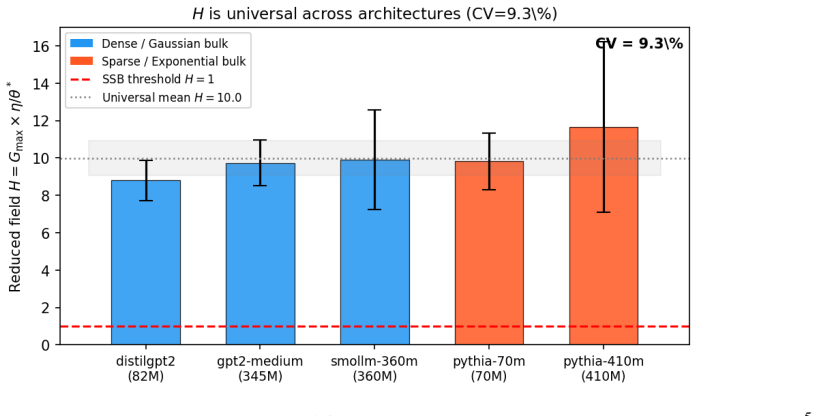
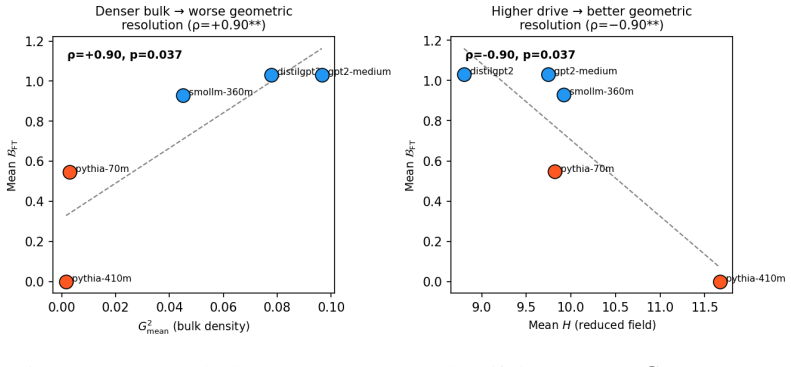
The transitions are phantoms. The spontaneous-symmetry-breaking interpretation is ruled out by direct measurement. Catapult-like jumps still appear under LoRA fine-tuning with the token embedding matrix exactly unchanged during training, where no geometric phase transition is possible. The discontinuity lives entirely in the softmax readout. A small number of dimensionless quantities organise the trajectory across architectures. One is consistent across all five under full fine-tuning. A second sorts architectures into two classes by bulk embedding distribution and predicts LoRA sufficiency. As a blind test, the framework predicts the critical learning rate of a held-out architecture to with
What carries the argument
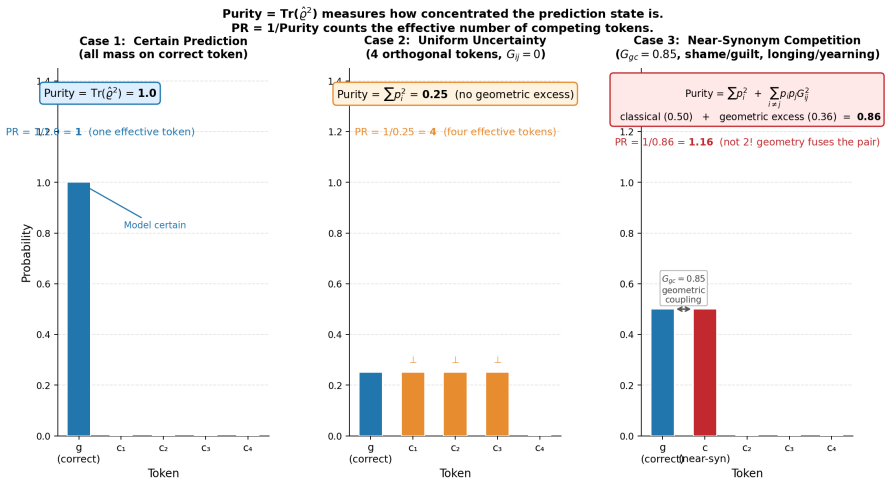
The order parameter that combines predicted distribution with pairwise embedding overlaps and decomposes additively into signal and background drag.
If this is right
- Catapult jumps persist when the embedding matrix remains exactly unchanged.
- Architectures divide into two classes by bulk embedding distribution that predicts whether LoRA alone suffices.
- One dimensionless quantity remains consistent across all tested models under full fine-tuning.
- The same framework predicts critical learning rates for unseen architectures to within 2.1 percent.
Where Pith is reading between the lines
- Monitoring the signal-to-drag ratio during training could flag impending structural failures before loss plateaus.
- Targeted adjustments to the softmax temperature or normalization might eliminate the phantom jumps without touching embeddings.
- The decomposition into signal and drag may generalize to other probability outputs where competitors compete in rank.
Load-bearing premise
The ten hand-selected near-synonym contexts represent the general near-synonym failure regime and the order parameter captures the relevant dynamics without omitting other factors.
What would settle it
Repeating the LoRA runs with fixed embeddings on a fresh set of near-synonym contexts and checking whether the order-parameter jumps disappear.
Figures
read the original abstract
Fine-tuning a language model on contexts whose correct completion has a near-synonym competitor often fails silently. The cross-entropy loss decreases monotonically while the correct token never overtakes the competitor in rank. We study this regime across five transformer architectures spanning two families and a fivefold parameter range, on ten hand-selected near-synonym contexts. We instrument these failures with an order parameter combining the predicted distribution and pairwise embedding overlaps. It decomposes additively into a signal, tracking the model's commitment to the correct token over its nearest competitor, and a background drag, set by how the embedding bulk leaks probability into the score. This isolates two failure modes. In kinematic failure the signal stays small. In structural failure the drag actively worsens as fine-tuning proceeds. We observe sharp catapult-like jumps in the order parameter that resemble a phase transition. A central negative result organises the paper. The transitions are phantoms. The spontaneous-symmetry-breaking interpretation is ruled out by direct measurement. Catapult-like jumps still appear under LoRA fine-tuning with the token embedding matrix exactly unchanged during training, where no geometric phase transition is possible. The discontinuity lives entirely in the softmax readout. A small number of dimensionless quantities organise the trajectory across architectures. One is consistent across all five under full fine-tuning. A second sorts architectures into two classes by bulk embedding distribution and predicts LoRA sufficiency. As a blind test, the framework predicts the critical learning rate of a held-out architecture, not used to fit any parameter, to within 2.1% of a subsequent learning-rate sweep. Findings concern the near-synonym mechanism only and should not be extrapolated without recalibration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines silent failures during fine-tuning of language models on near-synonym contexts, where cross-entropy loss decreases but the correct token fails to overtake its competitor in rank. Across five transformer architectures (two families, fivefold parameter range) and ten hand-selected contexts, the authors introduce an order parameter that decomposes additively into a signal component (commitment to the correct token) and background drag (embedding bulk leakage). They report catapult-like jumps in this order parameter but demonstrate via LoRA fine-tuning with the token embedding matrix held exactly fixed that these are phantom transitions occurring entirely in the softmax readout, ruling out spontaneous symmetry breaking in embedding geometry. Dimensionless quantities organize trajectories across architectures, one consistent under full fine-tuning and another sorting by bulk embedding distribution to predict LoRA sufficiency; a blind test predicts the critical learning rate of a held-out architecture to within 2.1%.
Significance. If the central negative result holds, the work supplies a mechanistic account of a common fine-tuning failure mode, isolating the discontinuity to the readout and providing non-circular support through the fixed-embedding LoRA condition, cross-architecture consistency of dimensionless quantities, and successful blind prediction. These elements (multi-architecture span, direct test of the geometric hypothesis, and out-of-sample prediction) strengthen the phantom diagnosis for the measured cases and could guide targeted interventions in near-synonym regimes.
minor comments (3)
- [Abstract / Experiments] The abstract and methods should explicitly state the selection criteria or sampling procedure for the ten near-synonym contexts to support reproducibility and allow readers to assess representativeness of the failure regime.
- [Order parameter section] The order parameter is described as combining predicted distribution and pairwise embedding overlaps; formalizing its exact definition (including any normalization or weighting) with an equation in the main text would improve clarity.
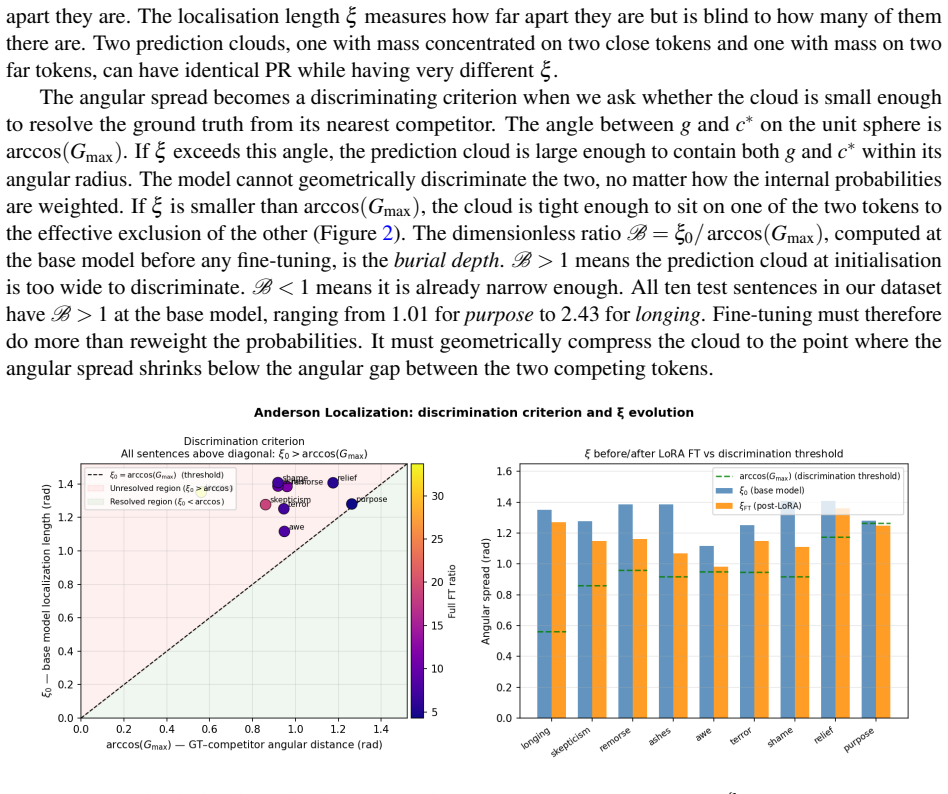
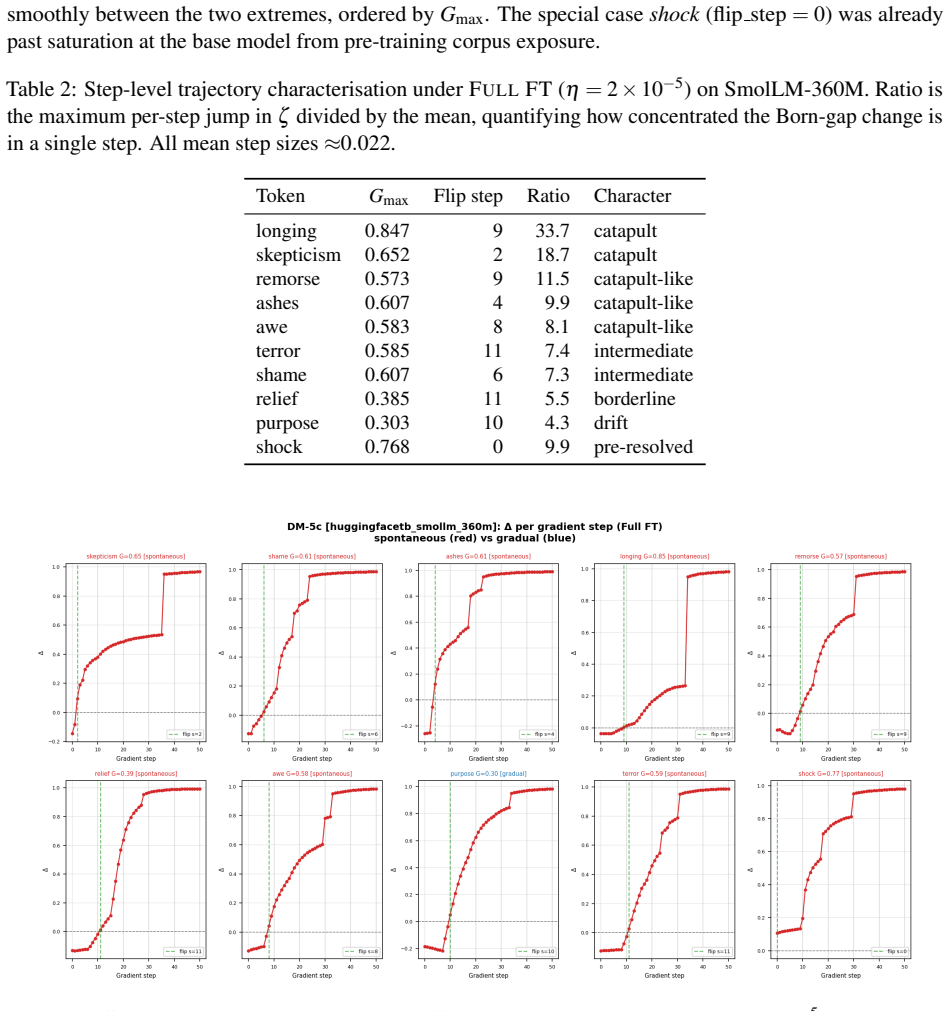
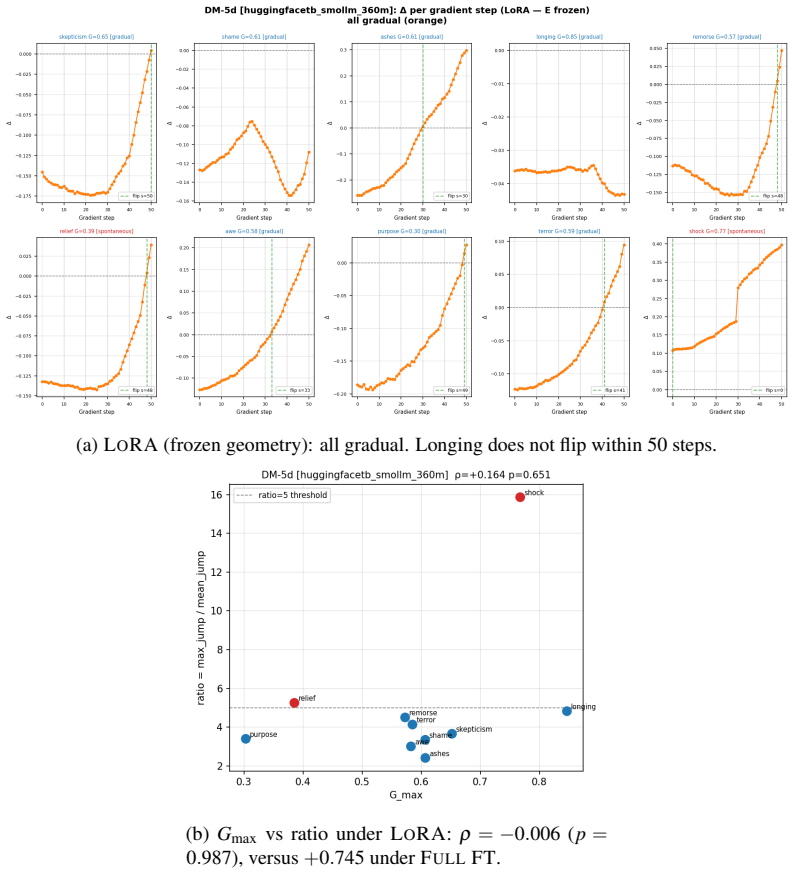
- [Results figures] Figures reporting the order parameter trajectories and learning-rate sweeps should include explicit discussion of error bars, exclusion criteria, and statistical significance of the observed jumps.
Simulated Author's Rebuttal
We thank the referee for their careful summary of the work and for the positive recommendation to accept. The report correctly identifies the central negative result (phantom transitions confined to the softmax readout) and the supporting elements (fixed-embedding LoRA controls, cross-architecture dimensionless quantities, and blind prediction). No major comments were raised that require response or revision.
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on direct experimental measurements (LoRA runs with token embeddings held exactly fixed, ruling out geometric phase transitions) and a blind prediction of critical learning rate on a held-out architecture (accurate to 2.1% with no fitting to that model). The order parameter, its signal/background decomposition, and the reported dimensionless quantities are constructed from observable quantities and shown consistent across architectures without reducing to the target results by definition or by self-citation chains. No load-bearing step equates a prediction to its own fitted input or imports uniqueness from prior author work.
Axiom & Free-Parameter Ledger
free parameters (1)
- dimensionless quantities organizing trajectory
axioms (1)
- domain assumption The order parameter decomposes additively into signal (commitment to correct token) and background drag (embedding bulk leakage)
invented entities (3)
-
order parameter
no independent evidence
-
signal component
no independent evidence
-
background drag component
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Luke Zettlemoyer, and Sonal Gupta. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Proceedings of ACL, 2021
2021
-
[2]
Absence of diffusion in certain random lattices
Philip W Anderson. Absence of diffusion in certain random lattices. Physical Review, 109 0 (5): 0 1492, 1958
1958
-
[3]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O'Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397--2430, 2023
2023
-
[4]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33: 0 1877--1901, 2020
1901
-
[5]
Isotropy in the contextual embedding space: Clusters and functional roles
Xingyu Cai, Jiaji Dong, Pratik Rohatgi, and Kenneth W Church. Isotropy in the contextual embedding space: Clusters and functional roles. In International Conference on Learning Representations, 2021
2021
-
[6]
A statistical physics of language model reasoning
Jack David Carson and Amir Reisizadeh. A statistical physics of language model reasoning. arXiv preprint arXiv:2506.04374, 2025
-
[7]
Mathematical foundations for a compositional distributional model of meaning
Bob Coecke, Mehrnoosh Sadrzadeh, and Stephen Clark. Mathematical foundations for a compositional distributional model of meaning. Linguistic Analysis, 36: 0 345--384, 2010
2010
-
[8]
QLoRA : Efficient finetuning of quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA : Efficient finetuning of quantized LLMs . Advances in Neural Information Processing Systems, 36, 2023
2023
-
[9]
BERT : Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT : Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT, pages 4171--4186, 2019
2019
-
[10]
arXiv preprint arXiv:2002.06305 , year=
Jesse Dodge, Gabriel Ilharco, Roy Schwartz, Ali Farhadi, Hannaneh Hajishirzi, and Noah Smith. Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping. arXiv preprint arXiv:2002.06305, 2020
-
[11]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, et al. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
How contextual are contextualized word representations? comparing the geometry of BERT , ELMo , and GPT-2 embeddings
Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of BERT , ELMo , and GPT-2 embeddings. In Proceedings of EMNLP-IJCNLP, pages 55--65, 2019
2019
-
[13]
Representation degeneration problem in training natural language generation models
Jun Gao, Di He, Xu Tan, Tao Qin, Liwei Wang, and Tie-Yan Liu. Representation degeneration problem in training natural language generation models. In International Conference on Learning Representations, 2019
2019
-
[14]
Parameter-efficient transfer learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP . In International Conference on Machine Learning, pages 2790--2799, 2019
2019
-
[15]
LoRA : Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA : Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[16]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 55 0 (12): 0 1--38, 2023
2023
-
[17]
Fine-tuning can distort pretrained features and underperform out-of-distribution
Ananya Kumar, Aditi Raghunathan, Robbie Jones, Tengyu Ma, and Percy Liang. Fine-tuning can distort pretrained features and underperform out-of-distribution. In International Conference on Learning Representations, 2022
2022
-
[18]
A path towards autonomous machine intelligence
Yann LeCun. A path towards autonomous machine intelligence. OpenReview, 2022. Version 0.9.2
2022
-
[19]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. In Proceedings of EMNLP, pages 3045--3059, 2021
2021
-
[20]
On the large learning rate dynamics of SGD
Aitor Lewkowycz, Yasaman Bahri, Ethan Dyer, Jascha Sohl-Dickstein, and Guy Gur-Ari. On the large learning rate dynamics of SGD . arXiv preprint arXiv:2006.10265, 2020
-
[21]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of ACL-IJCNLP, pages 4582--4597, 2021
2021
-
[22]
On faithfulness and factuality in abstractive summarization
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. On faithfulness and factuality in abstractive summarization. In Proceedings of ACL, pages 1906--1919, 2020
1906
-
[23]
On the stability of fine-tuning BERT : Misconceptions, explanations, and strong baselines
Marius Mosbach, Maksym Andriushchenko, and Dietrich Klakow. On the stability of fine-tuning BERT : Misconceptions, explanations, and strong baselines. In International Conference on Learning Representations, 2021
2021
-
[24]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. In International Conference on Learning Representations, 2023
2023
-
[25]
Quantum Computation and Quantum Information
Michael A Nielsen and Isaac L Chuang. Quantum Computation and Quantum Information. Cambridge University Press, 2000
2000
-
[26]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35: 0 27730--27744, 2022
2022
-
[27]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets. arXiv preprint arXiv:2201.02177, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Using the output embedding to improve language models
Ofir Press and Lior Wolf. Using the output embedding to improve language models. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, pages 157--163, 2017
2017
-
[29]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Blog, 1 0 (8): 0 9, 2019
2019
-
[30]
RoFormer : Enhanced transformer with rotary position embedding
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer : Enhanced transformer with rotary position embedding. Neurocomputing, 568: 0 127063, 2024
2024
-
[31]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA : Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[33]
Emergent abilities of large language models
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Miculivicius, et al. Emergent abilities of large language models. Transactions on Machine Learning Research, 2022
2022
-
[34]
End-to-end quantum-like language models with application to question answering
Peng Zhang, Jiabin Niu, Zhan Su, Benyou Wang, Leyu Ma, and Dawei Song. End-to-end quantum-like language models with application to question answering. In Proceedings of AAAI, volume 32, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.