Can You Trust What You See? Human and AI Detection of Synthetic Legal Evidence
Pith reviewed 2026-06-28 22:53 UTC · model grok-4.3
The pith
Neither humans nor multimodal AI models can reliably tell authentic legal photos from AI-generated ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
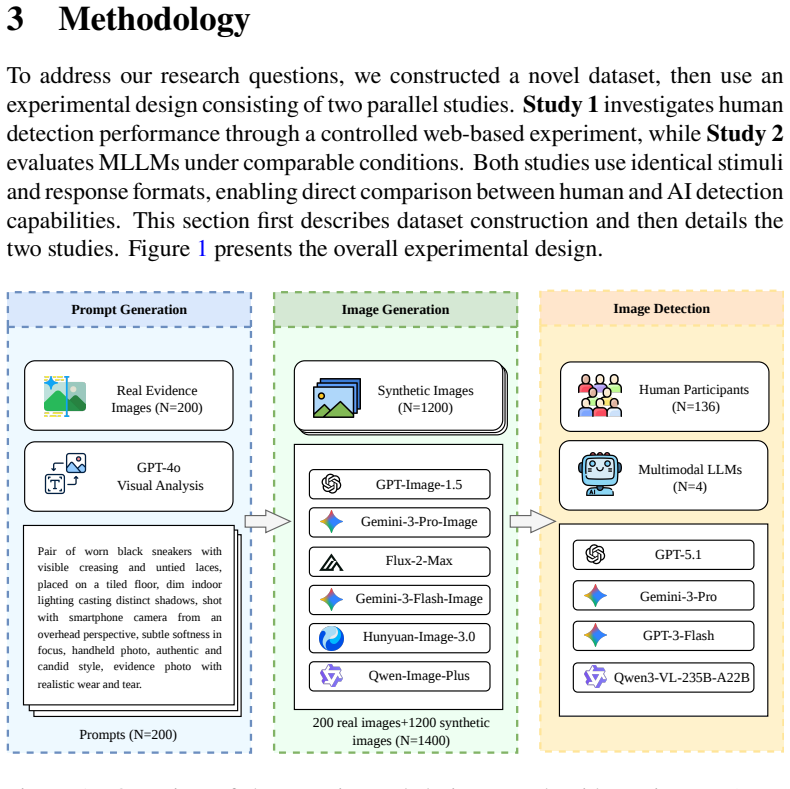
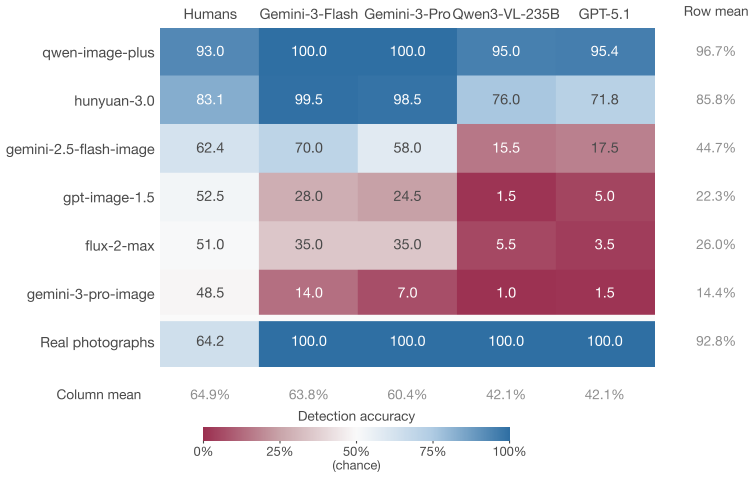
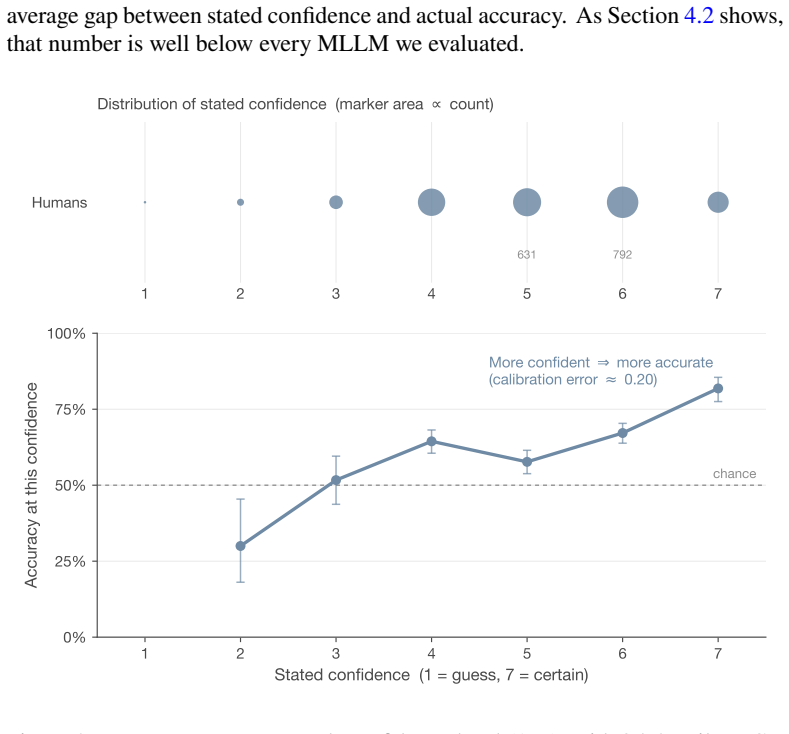
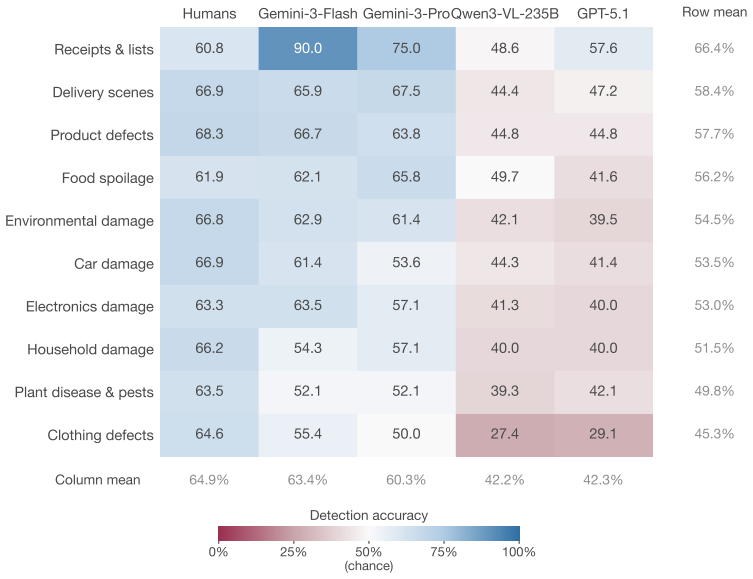
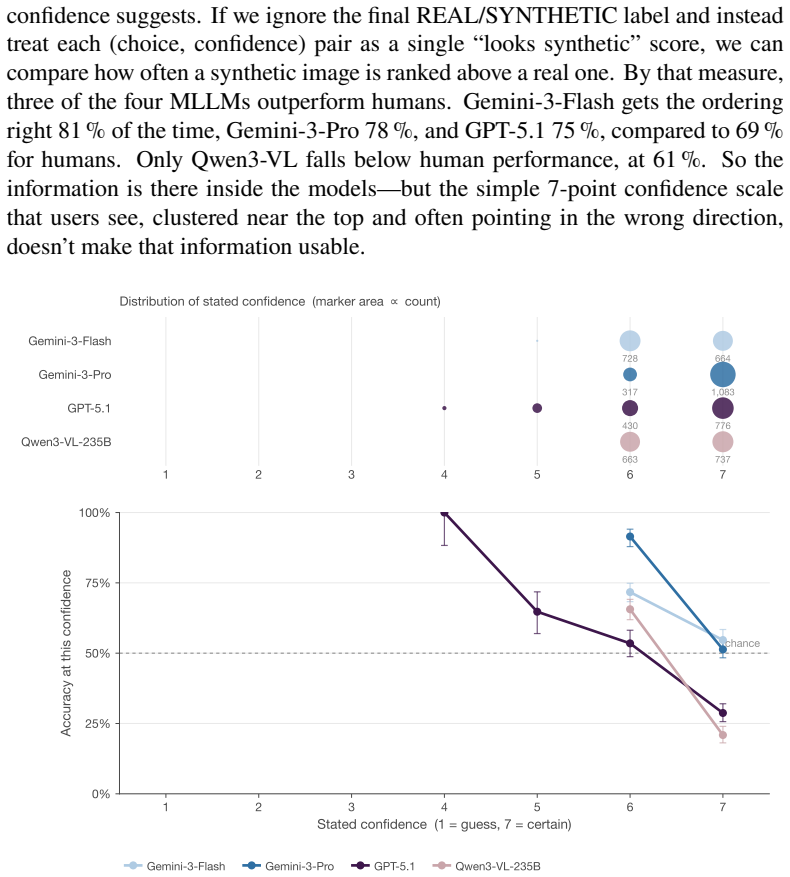
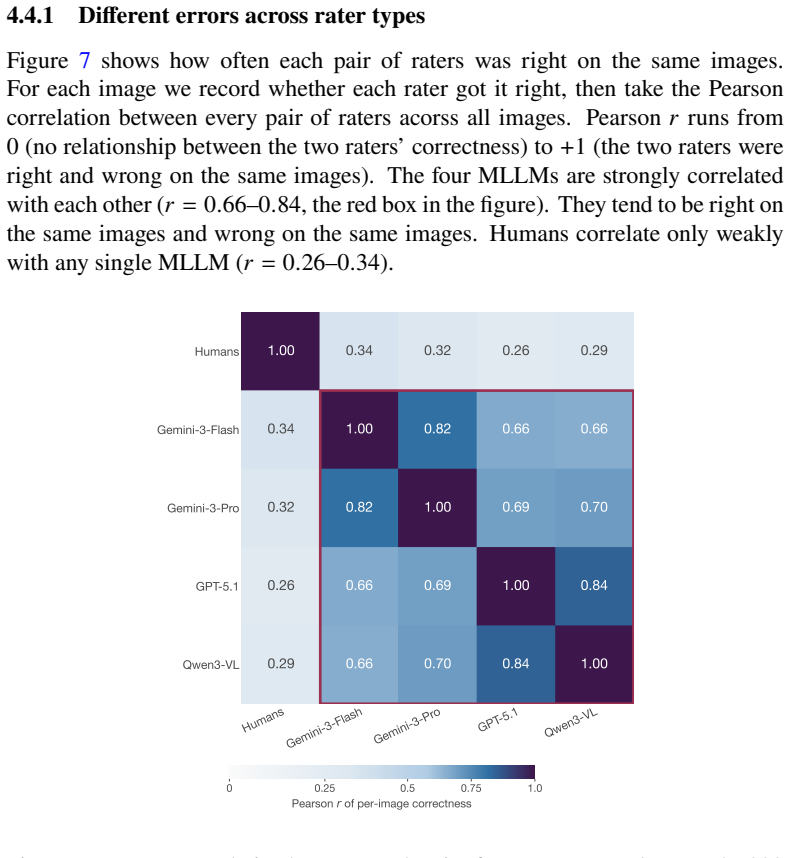
In controlled tests on the SLED-1400 dataset, lay humans achieved 64.8% accuracy distinguishing real evidentiary photographs from AI-generated counterparts, dropping to 48.5% and 51.0% on outputs from Gemini-3-Pro-Image and Flux-2-Max. Four evaluated MLLMs showed 100% specificity but only 5.9% average detection rate on the hardest generator outputs. Human and MLLM errors were largely uncorrelated.
What carries the argument
The SLED-1400 dataset of 1400 images (200 authentic paired with 1200 synthetic from six text-to-image generators in ten object-centric categories) used in identical format for human experiments and MLLM evaluations.
If this is right
- Visual evidence in legal proceedings should be treated as inherently contestable.
- A workable procedural response must combine trained human review, MLLM screening, and provenance infrastructure such as C2PA Content Credentials.
- Neither humans nor MLLMs alone provide sufficient authentication for synthetic legal evidence.
Where Pith is reading between the lines
- Similar detection failures may occur in other high-stakes domains like journalism or medical imaging where authenticity matters.
- Future work could test whether combining human and MLLM judgments improves overall detection rates beyond either alone.
- Training humans on specific generator artifacts might raise accuracy above chance levels on advanced models.
Load-bearing premise
The chosen set of 200 authentic images and 136 lay web participants represent the kinds of evidence and decision-makers that appear in real civil disputes.
What would settle it
A study applying the same detection task to images actually submitted as evidence in ongoing civil cases would show whether the reported accuracy levels hold outside the controlled dataset.
Figures

read the original abstract
Visual evidence has long been treated as a reliable form of legal proof, but advances in artificial intelligence (AI) are undermining that assumption. This article asks how well humans and frontier multimodal large language models (MLLMs) can distinguish authentic evidentiary photographs from AI-generated counterparts in the object-centric scenarios typical of civil disputes. We built Synthetic Legal Evidence Detection (SLED-1400), a dataset of 200 authentic evidence images paired with 1,200 synthetic counterparts produced by six contemporary text-to-image generators across ten evidence categories. The same stimuli and response format were used in a controlled web experiment with 136 lay participants and in a standardized evaluation of four MLLMs (GPT-5.1, Gemini-3-Pro, Gemini-3-Flash, Qwen3-VL-235B). Human accuracy was 64.8% overall, and 48.5% and 51.0% on the two strongest generators (Gemini-3-Pro-Image and Flux-2-Max), indistinguishable from chance. MLLMs never misclassified an authentic image (100% specificity), but missed most synthetic outputs from the harder generators, with average MLLM detection at 5.9% on Gemini-3-Pro-Image outputs. Human and MLLM errors were largely uncorrelated, while the four MLLMs were strongly correlated with each other. Neither group is a reliable standalone authenticator. We argue that visual evidence in legal proceedings should be treated as inherently contestable, and that a workable procedural response must combine trained human review, MLLM screening, and provenance infrastructure such as C2PA Content Credentials.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the SLED-1400 dataset of 200 authentic evidentiary photographs paired with 1,200 synthetic outputs from six text-to-image generators across ten object-centric categories typical of civil disputes. It reports a controlled web experiment with 136 lay participants yielding 64.8% overall human accuracy (dropping to 48.5% and 51.0% on Gemini-3-Pro-Image and Flux-2-Max outputs, indistinguishable from chance) and a standardized evaluation of four MLLMs (GPT-5.1, Gemini-3-Pro, Gemini-3-Flash, Qwen3-VL-235B) showing 100% specificity but only 5.9% average detection on the hardest generator. Human and MLLM errors are largely uncorrelated while the MLLMs correlate strongly with each other. The authors conclude that neither humans nor MLLMs constitute reliable standalone authenticators and argue that visual legal evidence should be treated as inherently contestable, requiring combined trained review, MLLM screening, and provenance infrastructure such as C2PA.
Significance. If the empirical results hold, the work supplies concrete, falsifiable performance numbers on a purpose-built legal-evidence dataset and documents the complementary failure modes of humans and MLLMs. The new SLED-1400 stimuli and the direct head-to-head comparison constitute a useful public resource for subsequent research on detection reliability. The observation that errors are uncorrelated supplies a concrete rationale for multi-layered authentication protocols rather than reliance on any single method.
major comments (1)
- [Methods (Human Evaluation)] The experimental protocol (136 lay web participants, object-centric images presented without metadata, chain-of-custody cues, or adversarial legal framing) is described in the Methods section; because the headline claim is that neither humans nor MLLMs are reliable standalone authenticators in civil-dispute settings, the absence of any comparison to trained legal professionals or to stimuli that include additional evidentiary signals is load-bearing for the generalization from the controlled task to actual courtroom authentication.
minor comments (1)
- [MLLM Evaluation] The abstract states MLLM detection rates but does not specify the exact prompt templates or decision thresholds applied to the four models; adding these details (or a supplementary table) would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the value of the SLED-1400 dataset and the head-to-head comparison. We address the single major comment below.
read point-by-point responses
-
Referee: [Methods (Human Evaluation)] The experimental protocol (136 lay web participants, object-centric images presented without metadata, chain-of-custody cues, or adversarial legal framing) is described in the Methods section; because the headline claim is that neither humans nor MLLMs are reliable standalone authenticators in civil-dispute settings, the absence of any comparison to trained legal professionals or to stimuli that include additional evidentiary signals is load-bearing for the generalization from the controlled task to actual courtroom authentication.
Authors: We agree that the controlled protocol with lay participants and stimuli lacking metadata or chain-of-custody cues limits direct generalization to full courtroom authentication by trained professionals. The experiment was intentionally designed to isolate unaided visual detection performance as a baseline, which remains relevant because evidentiary photographs in civil disputes are frequently presented without reliable accompanying signals. The observed drop to chance-level accuracy on strong generators already indicates that standalone visual inspection is unreliable even under simplified conditions; this supplies evidence for the broader claim that visual legal evidence should be treated as contestable. We did not test trained legal experts because the study targets general human capabilities (analogous to jury members) rather than specialist performance, but we accept that including such a comparison would strengthen external validity. We will revise the manuscript to add an explicit Limitations subsection clarifying the scope of the human evaluation and noting that future work should examine trained professionals and stimuli with additional evidentiary signals. revision: partial
Circularity Check
Empirical study with no derivation chain or self-referential predictions
full rationale
The paper is a data-collection and evaluation study: it constructs SLED-1400 (200 authentic + 1200 synthetic images), runs controlled web experiments with 136 participants, and evaluates four MLLMs on the same stimuli. No equations, fitted parameters, predictions derived from prior fits, or uniqueness theorems appear. Central claims (human accuracy 64.8 % overall, MLLM detection 5.9 % on hardest generator) are direct empirical measurements, not reductions to inputs by construction. Self-citations, if any, are not load-bearing for the reported results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Lay participants in a web-based experiment can serve as proxies for individuals involved in civil disputes when assessing image authenticity.
- domain assumption The outputs from the six text-to-image generators represent the current state of synthetic evidence that could be presented in legal contexts.
Reference graph
Works this paper leans on
-
[1]
ACM Transactions on Multimedia Computing, Communications, and Applications , author =
Revolutionizing. ACM Transactions on Multimedia Computing, Communications, and Applications , author =. 2024 , pages =. doi:10.1145/3689641 , abstract =
-
[2]
Rutgers Computer & Technology Law Journal , author =
A. Rutgers Computer & Technology Law Journal , author =. 1992 , pages =
1992
-
[3]
Yale Journal of Law & the Humanities , author =
The image of truth:. Yale Journal of Law & the Humanities , author =. 1998 , pages =
1998
-
[4]
A. IEEE Access , author =. 2023 , keywords =. doi:10.1109/ACCESS.2023.3317083 , abstract =
-
[5]
Chalkidis, Ilias and Androutsopoulos, Ion and Aletras, Nikolaos , editor =. Neural. Proceedings of the 57th. 2019 , pages =. doi:10.18653/v1/P19-1424 , abstract =
-
[6]
Ashley, Kevin D. , month = jul, year =. Artificial. doi:10.1017/9781316761380 , abstract =
-
[7]
Artificial intelligence in legal education: a scoping review , issn =. The Law Teacher , author =. 2026 , pages =. doi:10.1080/03069400.2025.2592440 , language =
-
[8]
Vučić, Franjo , editor =. Changes in. Digital. 2023 , pages =. doi:10.1007/978-3-031-36833-2_12 , language =
-
[9]
The language of the law vs. the language of the computer: a bilingual model of legal education in the age of technology and artificial intelligence , volume =. Law, Innovation and Technology , author =. 2024 , pages =. doi:10.1080/17579961.2024.2392938 , language =
-
[10]
Shen, Bingyu and RichardWebster, Brandon and O'Toole, Alice and Bowyer, Kevin and Scheirer, Walter J. , month = dec, year =. A. 2021 16th. doi:10.1109/FG52635.2021.9667066 , urldate =
-
[11]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , author =
Enhancing. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , author =. 2025 , pages =. doi:10.1609/aies.v8i1.36529 , abstract =
-
[12]
IEEE Signal Processing Magazine , author =
More. IEEE Signal Processing Magazine , author =. 2022 , pages =. doi:10.1109/MSP.2021.3120982 , number =
-
[13]
Problematising reality: the promises and perils of synthetic media , volume =. SN Social Sciences , author =. 2020 , pages =. doi:10.1007/s43545-020-00010-8 , language =
-
[14]
Perception inception: preparing for deepfakes and the synthetic media of tomorrow , shorttitle =
Barraclough, Tom and Barnes, Curtis , month = may, year =. Perception inception: preparing for deepfakes and the synthetic media of tomorrow , shorttitle =
-
[15]
Frontiers in Artificial Intelligence , author =
What you see is not what you get anymore: a mixed-methods approach on human perception of. Frontiers in Artificial Intelligence , author =. 2025 , pages =. doi:10.3389/frai.2025.1707336 , abstract =
-
[16]
The state of
Labajová, Lucia , year =. The state of
-
[17]
Frank, Joel and Herbert, Franziska and Ricker, Jonas and Schönherr, Lea and Eisenhofer, Thorsten and Fischer, Asja and Dürmuth, Markus and Holz, Thorsten , month = may, year =. A. 2024. doi:10.1109/SP54263.2024.00159 , urldate =
-
[18]
Dianey and Rojas-Velazquez, David and Gorelova, Aleksandra V
Rueda-Arango, Y. Dianey and Rojas-Velazquez, David and Gorelova, Aleksandra V. and Lopez-Rincon, Alejandro , month = sep, year =. Exploring. 2024. doi:10.1109/ISTAS61960.2024.10732054 , urldate =
-
[19]
Seeing is not always believing: benchmarking human and model perception of
Lu, Zeyu and Huang, Di and Bai, Lei and Qu, Jingjing and Wu, Chengyue and Liu, Xihui and Ouyang, Wanli , month = dec, year =. Seeing is not always believing: benchmarking human and model perception of. Proceedings of the 37th
-
[20]
Vision-. IEEE Transactions on Pattern Analysis and Machine Intelligence , author =. 2024 , pages =. doi:10.1109/TPAMI.2024.3369699 , number =
-
[21]
Journal of Imaging , author =. 2023 , pages =. doi:10.3390/jimaging9100199 , abstract =
-
[22]
and Jain, Ishan and Wang, Oliver and Zhang, Richard , year =
Epstein, David C. and Jain, Ishan and Wang, Oliver and Zhang, Richard , year =. Online
-
[23]
Cozzolino, Davide and Poggi, Giovanni and Nießner, Matthias and Verdoliva, Luisa , editor =. Zero-. Computer. 2025 , pages =. doi:10.1007/978-3-031-72649-1_4 , language =
-
[24]
Performance. IEEE Access , author =. 2024 , pages =. doi:10.1109/ACCESS.2024.3394250 , urldate =
-
[25]
Computer Science Review , author =
Methods and trends in detecting. Computer Science Review , author =. 2026 , pages =. doi:10.1016/j.cosrev.2026.100908 , language =
-
[26]
Raising the
Cozzolino, Davide and Poggi, Giovanni and Corvi, Riccardo and Nießner, Matthias and Verdoliva, Luisa , year =. Raising the
-
[27]
Houston Law Review , author =
Navigating the. Houston Law Review , author =. 2025 , pages =
2025
-
[28]
Hungarian Journal of Legal Studies , author =
Large language models and their possible uses in law , volume =. Hungarian Journal of Legal Studies , author =. 2024 , pages =. doi:10.1556/2052.2023.00475 , abstract =
-
[29]
Bhambhoria, Rohan and Dahan, Samuel and Li, Jonathan and Zhu, Xiaodan , editor =. Evaluating. Compliance for. 2026 , pages =. doi:10.1007/978-3-032-12795-2_5 , language =
-
[30]
Loyola of Los Angeles Law Review , author =
Generative. Loyola of Los Angeles Law Review , author =. 2025 , pages =
2025
-
[31]
Journal of Banking Regulation , author =
Legal implications of automated suspicious transaction monitoring: enhancing integrity of. Journal of Banking Regulation , author =. 2024 , pages =. doi:10.1057/s41261-024-00233-2 , abstract =
-
[32]
Global Times , file =
Chinese court detects. Global Times , file =
-
[33]
IEEE Access , author =. 2023 , pages =. doi:10.1109/ACCESS.2023.3324403 , urldate =
-
[34]
Frontiers in Big Data , author =
Audio deepfakes:. Frontiers in Big Data , author =. 2023 , pages =. doi:10.3389/fdata.2022.1001063 , abstract =
-
[35]
Audio. IEEE Access , author =. 2023 , pages =. doi:10.1109/ACCESS.2023.3333866 , urldate =
-
[36]
Manipulating faces for identity theft via morphing and deepfake:
Agarwal, Akshay and Ratha, Nalini , editor =. Manipulating faces for identity theft via morphing and deepfake:. Deep. 2023 , keywords =. doi:https://doi.org/10.1016/bs.host.2022.12.003 , abstract =
-
[37]
Brooklyn Journal of International Law , author =
Deep. Brooklyn Journal of International Law , author =. 2023 , pages =
2023
-
[38]
Social Media + Society , author =
Deepfakes and. Social Media + Society , author =. 2020 , pages =. doi:10.1177/2056305120903408 , abstract =
-
[39]
The Eurasia Proceedings of Science Technology Engineering and Mathematics , author =
Impact of. The Eurasia Proceedings of Science Technology Engineering and Mathematics , author =. 2023 , pages =. doi:10.55549/epstem.1371792 , abstract =
-
[40]
Journal of Intellectual Property Law & Practice , author =
Regulating deep fakes: legal and ethical considerations , volume =. Journal of Intellectual Property Law & Practice , author =. 2020 , pages =. doi:10.1093/jiplp/jpz167 , language =
-
[41]
Journal of Intellectual Property Law & Practice , author =
Do deepfakes pose a golden opportunity?. Journal of Intellectual Property Law & Practice , author =. 2020 , pages =. doi:10.1093/jiplp/jpz139 , language =
-
[42]
Trauma, Violence, & Abuse , author =
Legal. Trauma, Violence, & Abuse , author =. 2024 , pages =. doi:10.1177/15248380221143772 , abstract =
-
[43]
Journal of Tort Law , author =
Deepfake. Journal of Tort Law , author =. 2025 , pages =. doi:10.1515/jtl-2025-0032 , abstract =
-
[44]
Crime, Law and Social Change , author =
Regulating deepfakes between. Crime, Law and Social Change , author =. 2025 , pages =. doi:10.1007/s10611-024-10197-z , language =
-
[45]
Flynn, Asher and Clough, Jonathan and Cooke, Talani , editor =. Disrupting and. The. 2021 , pages =. doi:10.1007/978-3-030-83734-1_29 , language =
-
[46]
Montasari, Reza , year =. Cyberspace,. doi:10.1007/978-3-031-50454-9 , language =
-
[47]
IEEE Transactions on Technology and Society , author =
Beyond. IEEE Transactions on Technology and Society , author =. 2024 , pages =. doi:10.1109/TTS.2024.3427816 , number =
-
[48]
Jasserand, Catherine , month = sep, year =. Deceptive. 2024. doi:10.1109/BIOSIG61931.2024.10786729 , urldate =
-
[49]
International Review of Law, Computers & Technology , author =
Generative. International Review of Law, Computers & Technology , author =. 2024 , pages =. doi:10.1080/13600869.2024.2324540 , language =
-
[50]
AI & Society , author =. 2026 , pages =. doi:10.1007/s00146-025-02755-3 , language =
-
[51]
Face/off: "
Gerstner, Erik , year =. Face/off: ". Defense Counsel Journal , publisher =
-
[52]
Richmond Journal of Law & Technology , author =
Out of. Richmond Journal of Law & Technology , author =. 2021 , pages =
2021
-
[53]
Northwestern University Law Review , author =
Deepfake. Northwestern University Law Review , author =. 2021 , pages =
2021
-
[54]
Mitchell Hamline Law Review , author =
A. Mitchell Hamline Law Review , author =. 2022 , pages =
2022
-
[55]
Virginia Law Review Online , author =
Deepfakes,. Virginia Law Review Online , author =
-
[56]
Hastings Law Journal , author =
Deepfakes on. Hastings Law Journal , author =. 2023 , pages =
2023
-
[57]
2026 , file =
Tampa Bay 28 , author =. 2026 , file =
2026
-
[58]
Judges say they're not ready
AI-generated evidence is showing up in court. Judges say they're not ready. , url =. NBC News , author =. 2025 , day =
2025
-
[59]
Delfino, Rebecca , year =. The. Ohio State Law Journal , publisher =
-
[60]
Deeply dehumanizing, degrading, and violating:
Pascale, Emily , year =. Deeply dehumanizing, degrading, and violating:. Syracuse Law Review , publisher =
-
[61]
California Western International Law Journal , author =
A. California Western International Law Journal , author =. 2024 , pages =
2024
-
[62]
The Business, Entrepreneurship & Tax Law Review , author =
Synthetic. The Business, Entrepreneurship & Tax Law Review , author =. 2024 , pages =
2024
-
[63]
Science and Technology Law Review , author =
Judicial. Science and Technology Law Review , author =. 2025 , pages =. doi:10.52214/stlr.v26i2.13890 , abstract =
-
[64]
, year =
Murray, Michael D. , year =. Visual. SMU Science and Technology Law Review , publisher =
-
[65]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
A style-based generator architecture for generative adversarial networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[66]
arXiv preprint arXiv:2204.06125 , year=
Hierarchical text-conditional image generation with clip latents , author=. arXiv preprint arXiv:2204.06125 , year=
-
[67]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[68]
arXiv preprint arXiv:2006.07397 , year=
The deepfake detection challenge (dfdc) dataset , author=. arXiv preprint arXiv:2006.07397 , year=
Pith/arXiv arXiv 2006
-
[69]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Faceforensics++: Learning to detect manipulated facial images , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[70]
arXiv preprint arXiv:2509.09495 , year=
OpenFake: An Open Dataset and Platform Toward Real-World Deepfake Detection , author=. arXiv preprint arXiv:2509.09495 , year=
-
[71]
arXiv preprint arXiv:2412.15260 , year=
Analyzing Images of Legal Documents: Toward Multi-Modal LLMs for Access to Justice , author=. arXiv preprint arXiv:2412.15260 , year=
-
[72]
arXiv preprint arXiv:2511.13772 , year=
Can LLMs Create Legally Relevant Summaries and Analyses of Videos? , author=. arXiv preprint arXiv:2511.13772 , year=
-
[73]
Qiang, Chenhui and Wei, Zhaoyang and Han, Xumeng and Wang, Zipeng and Li, Siyao and Lan, Xiangyuan and Jiao, Jianbin and Han, Zhenjun , month = oct, year =. Proceedings of the 33rd. doi:10.1145/3746027.3758208 , language =
-
[74]
Forensic Science International: Digital Investigation , volume=
Digital forensics in law enforcement: A case study of LLM-driven evidence analysis , author=. Forensic Science International: Digital Investigation , volume=. 2025 , publisher=
2025
-
[75]
Forty-first International Conference on Machine Learning , year=
Chatbot arena: An open platform for evaluating llms by human preference , author=. Forty-first International Conference on Machine Learning , year=
-
[76]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[77]
parallax , volume=
Visual images in the courtroom: A historical perspective , author=. parallax , volume=. 2008 , publisher=
2008
-
[78]
China Daily , url =
Li, Hongyang , title =. China Daily , url =. 2025 , month = dec, date =
2025
-
[79]
California Law Review , volume=
Deep fakes: A looming challenge for privacy, democracy, and national security , author=. California Law Review , volume=
-
[80]
AI4AJ@ ICAIL , pages=
Chatgpt as an artificial lawyer? , author=. AI4AJ@ ICAIL , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.