DOME: Learning Transferable Domain Variables from Sparse Supervision for Test-Time Adaptation
Pith reviewed 2026-06-28 10:54 UTC · model grok-4.3
The pith
Explicit sample-specific domain modeling from vision-language pretraining lets basic entropy-minimization test-time adaptation outperform complex methods on image benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
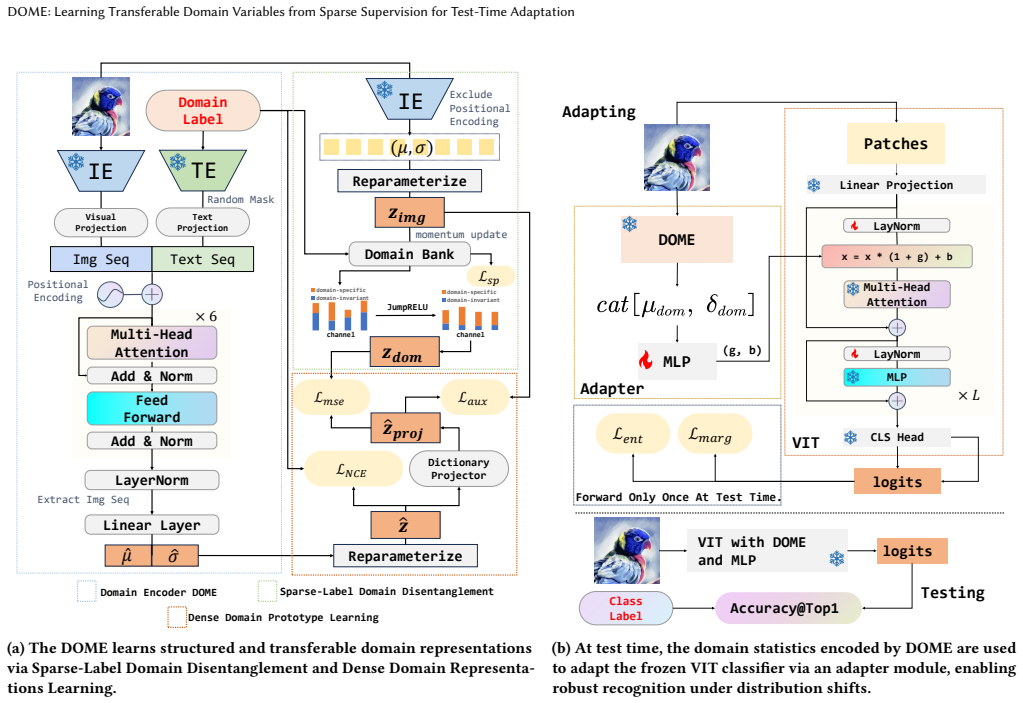
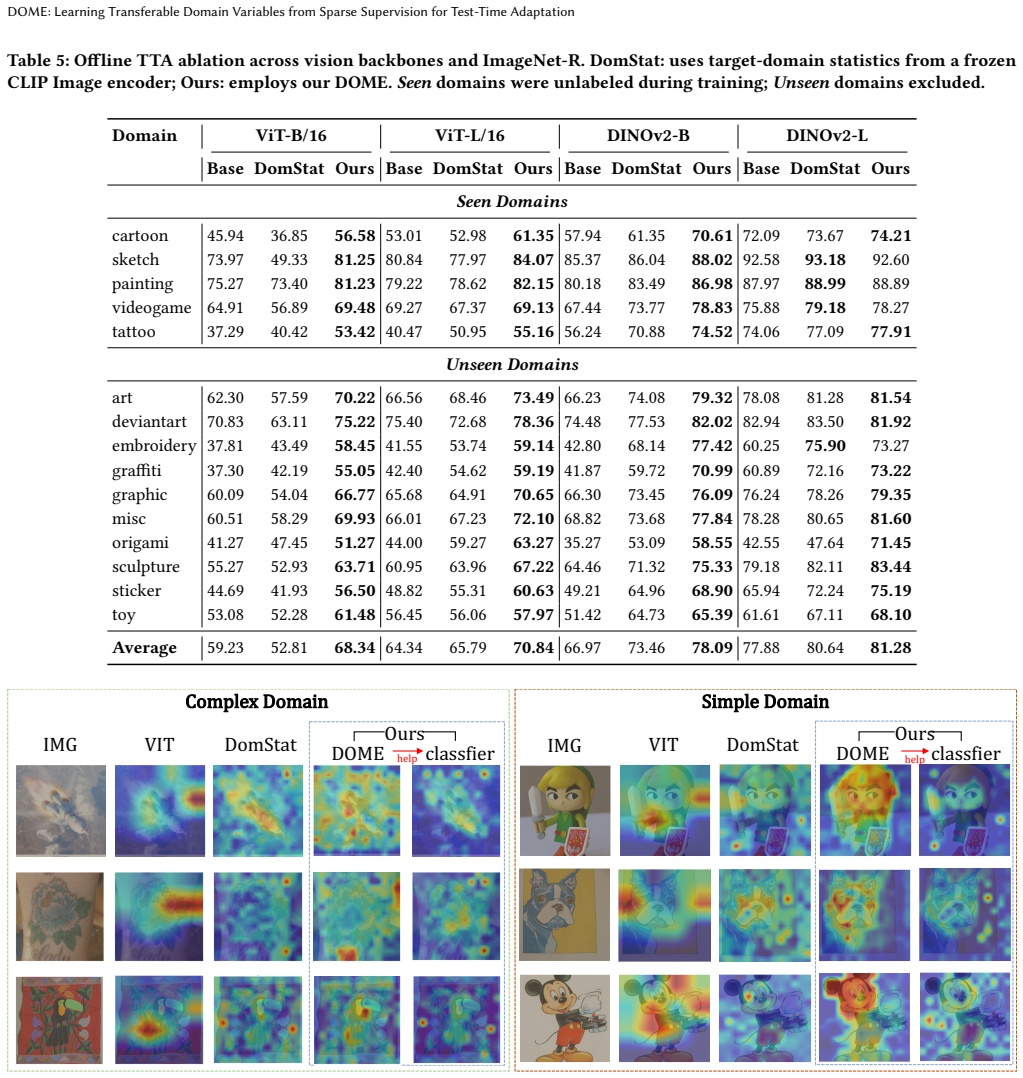
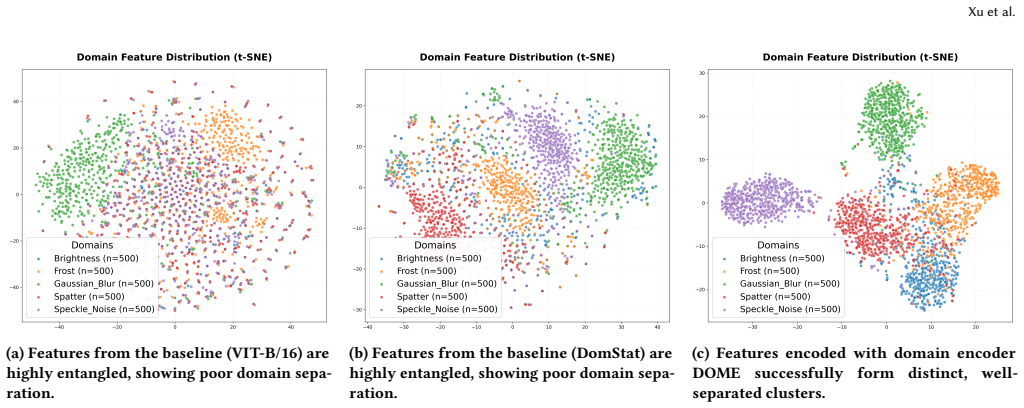
DOME learns transferable domain variables by extracting dense continuous representations via vision-language pretraining, parameterizing domains as distributional variables, and supervising them through a momentum-updated sparse domain bank; injecting these explicit cues into downstream models allows even a basic entropy-minimization test-time adaptation procedure to achieve state-of-the-art results on ImageNet-C, ImageNet-R, and ImageNet-Sketch while surpassing complex adaptation algorithms.
What carries the argument
DOME, the domain encoder that extracts dense continuous representations from vision-language pretraining, parameterizes domains as distributional variables, and maintains a momentum-updated sparse domain bank for disentangled supervision.
If this is right
- Basic entropy-minimization test-time adaptation reaches state-of-the-art accuracy on ImageNet-C, ImageNet-R, and ImageNet-Sketch once explicit domain cues are supplied.
- Robust adaptation under domain shift follows from structured domain representation rather than from elaborate adaptation algorithms.
- Domain variables extracted this way transfer across different downstream models without retraining the encoder.
- Sparse supervision via the momentum-updated bank suffices to disentangle domain information from task labels.
Where Pith is reading between the lines
- Future test-time adaptation work could shift effort from designing new adaptation rules toward building stronger domain encoders.
- The same sparse-supervision approach might apply to other modalities where pretraining already encodes shift-related factors.
- If domain cues prove this decisive, evaluation protocols could add explicit checks for how well representations separate domain from content.
Load-bearing premise
Vision-language pretraining produces representations that accurately reflect the multidimensional, sample-specific domain shifts in the test data, and the sparse domain bank supplies supervision without adding its own distribution shift or selection bias.
What would settle it
An ablation that removes the domain cues supplied by DOME and shows the basic entropy-minimization strategy falling below the performance of complex test-time adaptation methods on the same ImageNet variants.
Figures

read the original abstract
Test-time adaptation (TTA) aims to align a model to shifting test domains using only unlabeled streaming data. Most existing methods implicitly infer a single global domain distribution, ignoring the multidimensional and sample-specific nature of real-world domain shifts, leading to fragile adaptation. We propose DOME, an effective domain encoder that explicitly models each sample's domain in a zero-shot manner. DOME leverages vision-language pretraining to extract dense, continuous representations, parameterizes domains as distributional variables, and introduces a momentum-updated sparse domain bank for disentangled supervision. By injecting these explicit domain cues into downstream models, even a basic entropy-minimization TTA strategy achieves state-of-the-art performance across ImageNet-C, ImageNet-R, and ImageNet-Sketch, outperforming complex TTA approaches. Our results demonstrate that robust adaptation stems not from intricate adaptation algorithms, but from explicit, structured domain representation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DOME, a domain encoder for test-time adaptation (TTA) that explicitly models each sample's domain in a zero-shot manner. It leverages vision-language pretraining to extract dense continuous representations, parameterizes domains as distributional variables, and introduces a momentum-updated sparse domain bank for disentangled supervision. The central claim is that injecting these explicit domain cues into downstream models allows even a basic entropy-minimization TTA strategy to achieve state-of-the-art performance on ImageNet-C, ImageNet-R, and ImageNet-Sketch, outperforming complex TTA approaches. The paper concludes that robust adaptation stems from explicit, structured domain representation rather than intricate adaptation algorithms.
Significance. If the empirical results hold, the work would be significant for the TTA literature by shifting emphasis from increasingly complex adaptation algorithms toward better explicit domain modeling. It demonstrates a practical use of vision-language pretraining for sample-specific domain variables and introduces the sparse domain bank as a mechanism for disentangled supervision. This could encourage future methods to prioritize structured domain cues over algorithmic sophistication on standard corruption and style-shift benchmarks.
major comments (1)
- [Abstract] Abstract: The central empirical claim—that DOME enables basic entropy-minimization TTA to outperform complex methods on ImageNet-C, ImageNet-R, and ImageNet-Sketch—is stated without any accompanying experimental details, tables, figures, error bars, or ablation studies in the manuscript. This absence makes it impossible to verify the outperformance or assess whether the sparse domain bank introduces its own distribution shift.
minor comments (1)
- [Abstract] The abstract introduces 'distributional domain variables' and 'sparse domain bank' without a brief inline definition or reference to the section where they are formalized, which reduces immediate clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the review and the positive evaluation of the work's potential significance. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim—that DOME enables basic entropy-minimization TTA to outperform complex methods on ImageNet-C, ImageNet-R, and ImageNet-Sketch—is stated without any accompanying experimental details, tables, figures, error bars, or ablation studies in the manuscript. This absence makes it impossible to verify the outperformance or assess whether the sparse domain bank introduces its own distribution shift.
Authors: Abstracts are concise summaries by design and do not contain tables, figures, or detailed results; those appear in the body of the manuscript. Section 4 presents the main results on ImageNet-C, ImageNet-R, and ImageNet-Sketch, including direct comparisons showing that entropy minimization augmented by DOME outperforms prior complex TTA methods, with error bars and multiple runs. Section 5 contains ablations on the sparse domain bank, demonstrating that the momentum-updated bank provides disentangled supervision without introducing measurable distribution shift or performance degradation. The manuscript therefore supplies the requested verification material. revision: no
Circularity Check
No significant circularity
full rationale
The paper is an empirical proposal for a domain encoder (DOME) that extracts representations via vision-language pretraining, parameterizes domains as distributional variables, and uses a momentum-updated sparse bank for supervision. Performance claims rest on benchmark experiments (ImageNet-C/R/Sketch) showing that explicit domain cues improve basic entropy-minimization TTA. No mathematical derivation chain exists; no equations reduce predictions to fitted inputs by construction, no self-definitional loops, and no load-bearing self-citations or imported uniqueness theorems are present in the provided text. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vision-language pretraining yields dense continuous representations that encode sample-specific domain shifts.
- domain assumption A momentum-updated sparse domain bank can provide disentangled supervision without introducing new biases.
invented entities (2)
-
Distributional domain variables
no independent evidence
-
Sparse domain bank
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shai Ben-David, John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jennifer Wortman Vaughan. 2010. A theory of learning from different domains.Machine learning79, 1 (2010), 151–175. DOME: Learning Transferable Domain Variables from Sparse Supervision for Test-Time Adaptation
2010
-
[2]
Dian Chen, Dequan Wang, Trevor Darrell, and Sayna Ebrahimi. 2022. Contrastive test-time adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 295–305
2022
-
[3]
Yang Chen, Yu Wang, Yingwei Pan, Ting Yao, Xinmei Tian, and Tao Mei. 2021. A style and semantic memory mechanism for domain generalization. InProceedings of the IEEE/CVF International Conference on Computer Vision. 9164–9173
2021
-
[4]
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus En- zweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. 2016. The cityscapes dataset for semantic urban scene understanding. InProceedings of the IEEE conference on computer vision and pattern recognition. 3213–3223
2016
-
[5]
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey
-
[6]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse autoencoders find highly interpretable features in language models. arXiv preprint arXiv:2309.08600(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Alexey Dosovitskiy. 2020. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario March, and Victor Lempitsky. 2016. Domain-adversarial training of neural networks.Journal of machine learning research17, 59 (2016), 1–35
2016
-
[9]
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. 2024. Scaling and evaluating sparse autoencoders.arXiv preprint arXiv:2406.04093(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Taesik Gong, Jongheon Jeong, Taewon Kim, Yewon Kim, Jinwoo Shin, and Sung- Ju Lee. 2022. Note: Robust continual test-time adaptation against temporal correlation.Advances in Neural Information Processing Systems35 (2022), 27253– 27266
2022
-
[11]
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. 2021. The many faces of robustness: A critical analysis of out-of-distribution generalization. InProceedings of the IEEE/CVF international conference on computer vision. 8340– 8349
2021
-
[12]
Dan Hendrycks and Thomas Dietterich. 2019. Benchmarking neural net- work robustness to common corruptions and perturbations.arXiv preprint arXiv:1903.12261(2019). Includes ImageNet-C
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[13]
Xiaowei Hu, Chi-Wing Fu, Lei Zhu, and Pheng-Ann Heng. 2019. Depth- attentional features for single-image rain removal. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition. 8022–8031
2019
-
[14]
Xun Huang and Serge Belongie. 2017. Arbitrary style transfer in real-time with adaptive instance normalization. InProceedings of the IEEE international conference on computer vision. 1501–1510
2017
-
[15]
Yongcheng Jing, Yezhou Yang, Zunlei Feng, Jingwen Ye, Yizhou Yu, and Mingli Song. 2019. Neural style transfer: A review.IEEE transactions on visualization and computer graphics26, 11 (2019), 3365–3385
2019
- [16]
-
[17]
Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M Hospedales. 2017. Deeper, broader and artier domain generalization. InProceedings of the IEEE international conference on computer vision. 5542–5550
2017
-
[18]
Wei-Hong Li, Xialei Liu, and Hakan Bilen. 2021. Universal representation learning from multiple domains for few-shot classification. InProceedings of the IEEE/CVF international conference on computer vision. 9526–9535
2021
-
[19]
Xianfeng Li, Weijie Chen, Di Xie, Shicai Yang, Peng Yuan, Shiliang Pu, and Yueting Zhuang. 2021. A free lunch for unsupervised domain adaptive object detection without source data. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 8474–8481
2021
-
[20]
Ya Li, Mingming Gong, Xinmei Tian, Tongliang Liu, and Dacheng Tao. 2018. Domain generalization via conditional invariant representations. InProceedings of the AAAI conference on artificial intelligence, Vol. 32
2018
-
[21]
Jian Liang, Ran He, and Tieniu Tan. 2025. A comprehensive survey on test-time adaptation under distribution shifts.International Journal of Computer Vision 133, 1 (2025), 31–64
2025
-
[22]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. InEuropean conference on computer vision. Springer, 740–755
2014
-
[23]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[24]
Mingsheng Long, Zhangjie Cao, Jianmin Wang, and Michael I Jordan. 2018. Conditional adversarial domain adaptation.Advances in neural information processing systems31 (2018)
2018
-
[25]
Jing Ma. 2024. Improved self-training for test-time adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 23701– 23710
2024
-
[26]
Alireza Makhzani and Brendan Frey. 2013. K-sparse autoencoders.arXiv preprint arXiv:1312.5663(2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[27]
Xiaofeng Mao, Yuefeng Chen, Yao Zhu, Da Chen, Hang Su, Rong Zhang, and Hui Xue. 2023. Coco-o: A benchmark for object detectors under natural distribution shifts. InProceedings of the IEEE/CVF International Conference on Computer Vision. 6339–6350
2023
-
[28]
Muhammad Jehanzeb Mirza, Pol Jané Soneira, Wei Lin, Mateusz Kozinski, Horst Possegger, and Horst Bischof. 2023. Actmad: Activation matching to align distributions for test-time-training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24152–24161
2023
-
[29]
Hyeonseob Nam and Hyo-Eun Kim. 2018. Batch-instance normalization for adaptively style-invariant neural networks.Advances in Neural Information Processing Systems31 (2018)
2018
-
[30]
Andrew Ng et al. 2011. Sparse autoencoder.CS294A Lecture notes72, 2011 (2011), 1–19
2011
-
[31]
Shuaicheng Niu, Chunyan Miao, Guohao Chen, Pengcheng Wu, and Peilin Zhao
- [32]
-
[33]
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Yaofo Chen, Shijian Zheng, Peilin Zhao, and Mingkui Tan. 2022. Efficient test-time model adaptation without forgetting. InInternational conference on machine learning. PMLR, 16888–16905
2022
- [34]
-
[35]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El- Nouby, et al. 2023. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, and Bo Wang
-
[37]
InProceedings of the IEEE/CVF international conference on computer vision
Moment matching for multi-source domain adaptation. InProceedings of the IEEE/CVF international conference on computer vision. 1406–1415
-
[38]
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. 2018. Film: Visual reasoning with a general conditioning layer. In Proceedings of the AAAI conference on artificial intelligence, Vol. 32
2018
-
[39]
Leonardo Petrini, Francesco Cagnetta, Eric Vanden-Eijnden, and Matthieu Wyart
-
[40]
Learning sparse features can lead to overfitting in neural networks.Ad- vances in Neural Information Processing Systems35 (2022), 9403–9416
2022
-
[41]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[42]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
-
[43]
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, János Kramár, and Neel Nanda. 2024. Jumping ahead: Improv- ing reconstruction fidelity with jumprelu sparse autoencoders.arXiv preprint arXiv:2407.14435(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Stephan R Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun. 2016. Playing for data: Ground truth from computer games. InEuropean conference on computer vision. Springer, 102–118
2016
-
[45]
Christos Sakaridis, Dengxin Dai, and Luc Van Gool. 2018. Semantic foggy scene understanding with synthetic data.International Journal of Computer Vision126, 9 (2018), 973–992
2018
-
[46]
Christos Sakaridis, Dengxin Dai, and Luc Van Gool. 2021. ACDC: The adverse conditions dataset with correspondences for semantic driving scene understand- ing. InProceedings of the IEEE/CVF international conference on computer vision. 10765–10775
2021
-
[47]
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedan- tam, Devi Parikh, and Dhruv Batra. 2017. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE inter- national conference on computer vision. 618–626
2017
-
[48]
Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. 2016. Instance normaliza- tion: The missing ingredient for fast stylization.arXiv preprint arXiv:1607.08022 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[49]
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. 2020. Tent: Fully test-time adaptation by entropy minimization.arXiv preprint arXiv:2006.10726(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[50]
Haohan Wang, Songwei Ge, Zachary Lipton, and Eric P Xing. 2019. Learning robust global representations by penalizing local predictive power.Advances in neural information processing systems32 (2019)
2019
-
[51]
Qin Wang, Olga Fink, Luc Van Gool, and Dengxin Dai. 2022. Continual test-time domain adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7201–7211
2022
-
[52]
Ross Wightman. 2019. PyTorch Image Models. https://github.com/rwightman/ pytorch-image-models. doi:10.5281/zenodo.4414861
- [53]
-
[54]
Longhui Yuan, Binhui Xie, and Shuang Li. 2023. Robust test-time adaptation in dynamic scenarios. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15922–15932
2023
-
[55]
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. 2022. Condi- tional prompt learning for vision-language models. InProceedings of the IEEE/CVF Xu et al. conference on computer vision and pattern recognition. 16816–16825. [51] Kaiyang Zhou, Yongxin Yang, Yu Qiao, and Tao Xiang. 2021. Domain generaliza- tion with mixstyle.arXiv preprint arXiv:21...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.