MechLens: Late Crystallization of Factual Knowledge Explains Intervention Effectiveness in Language Models
Pith reviewed 2026-06-27 20:06 UTC · model grok-4.3
The pith
Factual knowledge in language models crystallizes abruptly in the final layers rather than emerging gradually.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
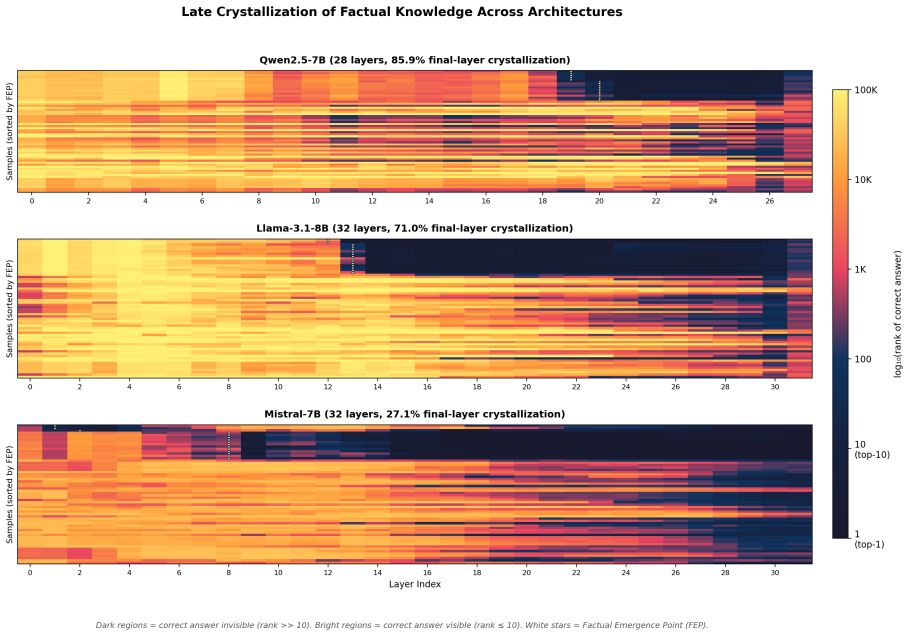
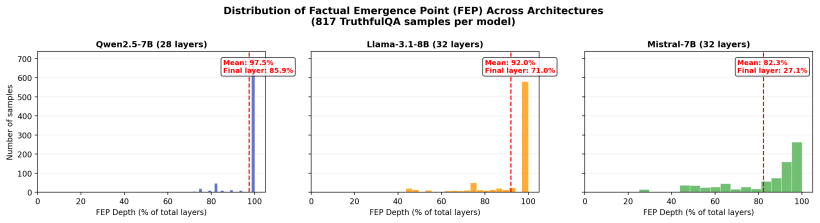
Factual knowledge does not gradually emerge across layers but crystallizes abruptly at the final layers. Across five model families, 26.8%--93.4% of correct answers never enter top-10 predictions at any intermediate layer, with late emergence (>80% depth) consistent across architectures. Tuned lens rules out probe artifacts, and the pattern is far stronger for factual questions than for sentiment classification. This leads to a crystallization-guided intervention principle where method effectiveness varies by model, plus a computability-memorization spectrum and the finding that LayerNorm scaling improves accuracy at zero added cost.
What carries the argument
Late Crystallization, the abrupt surfacing of factual knowledge in the final layers of the residual stream, which determines intervention success and is measured by when correct answers first enter top-10 predictions.
If this is right
- CAA outperforms DoLa on moderate-crystallization models such as Llama and Mistral.
- On high-crystallization models such as Qwen the performance ordering reverses.
- Scaling LayerNorm by a factor of 1.2 raises multiple-choice accuracy with no inference-time cost.
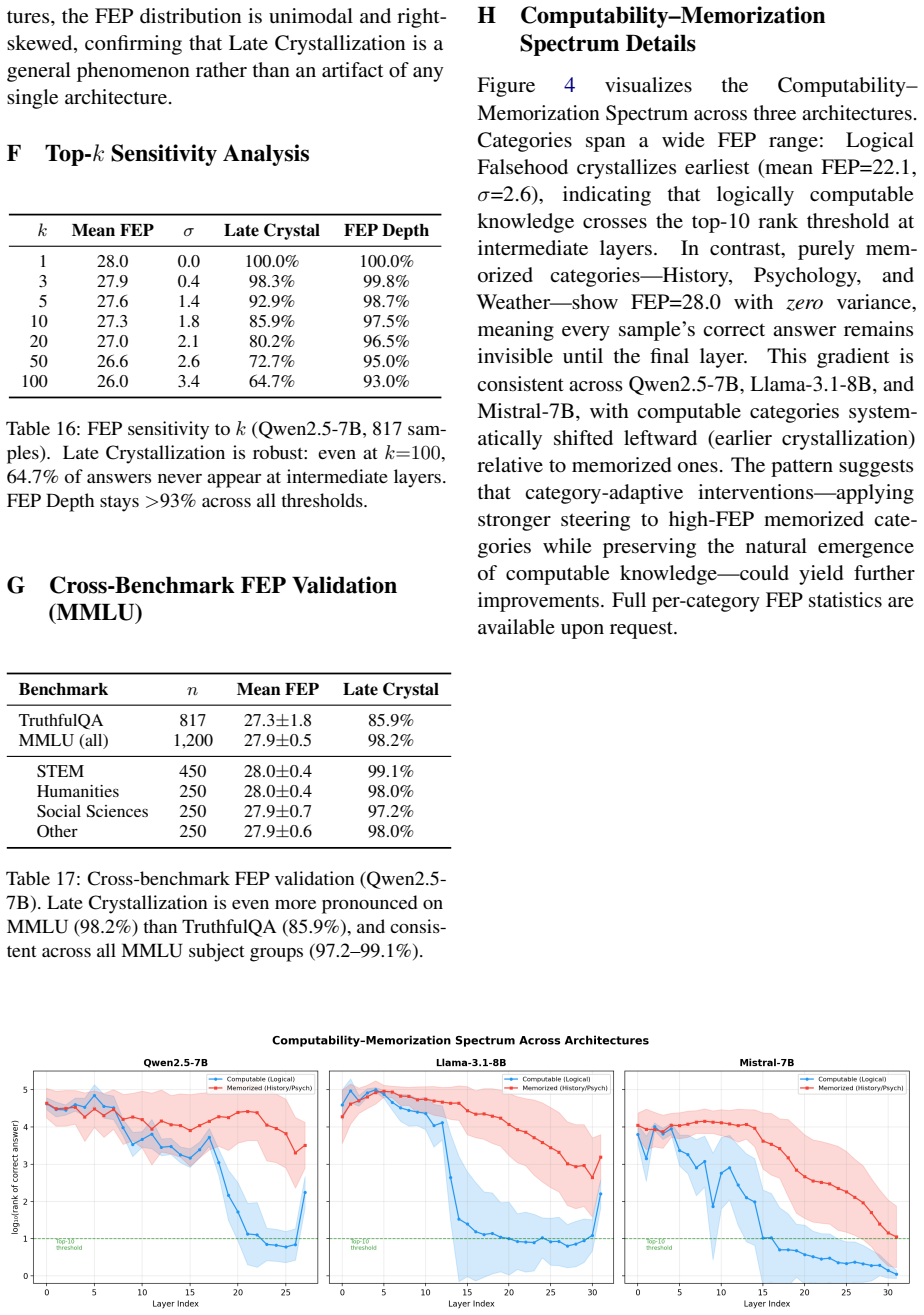
- Computable knowledge crystallizes earlier (around layer 22 in a 28-layer model) than memorized facts (layer 28).
- The late-crystallization pattern is specific to factual recall and does not appear in sentiment classification.
Where Pith is reading between the lines
- Knowledge editing techniques could gain efficiency by targeting only the layers at which crystallization occurs for each model and task.
- Training objectives might be designed to shift more knowledge toward earlier crystallization, potentially improving reliability on factual queries.
- The same measurement approach could be applied to non-text modalities to test whether crystallization timing is a general property of transformer residual streams.
Load-bearing premise
That the absence of a correct answer from top-10 predictions at intermediate layers means the knowledge is truly not yet present rather than stored in a form the metric does not capture.
What would settle it
Demonstrating a model family or scale in which the majority of factual answers from MMLU or similar benchmarks enter the top-10 predictions before 50% network depth would falsify the claim of consistent late crystallization.
Figures

read the original abstract
Understanding where LLMs store factual knowledge is critical for hallucination mitigation. We systematically quantify Late Crystallization: factual knowledge does not gradually emerge across layers but "crystallizes" abruptly at the final layers. Across five model families (Pythia, Gemma, Qwen2.5, Llama-3.1, Mistral; 0.5--14B), 26.8%--93.4% of correct answers never enter top-10 predictions at any intermediate layer, with late emergence (>80% depth) consistent across architectures. Cross-scale (Qwen2.5-14B) and cross-benchmark (MMLU: 98.2%) results confirm generality; tuned lens rules out probe artifacts. A sentiment-classification control (0.5% for Qwen vs. 85.9% factual; 2.0% for Mistral vs. 26.8%) confirms the phenomenon is specific to factual recall. Late Crystallization yields a crystallization-guided intervention principle: CAA outperforms DoLa on moderate-crystallization models (Llama, Mistral; p<0.001), with a directionally consistent reversal on high-crystallization Qwen (+25.4% vs. +15.5% MC1, p=0.069). LayerNorm ablation shows crystallization is intrinsic to the residual stream; LN scaling (x1.2) yields +11.8% MC1 with zero inference overhead. We further reveal a Computability-Memorization Spectrum: computable knowledge crystallizes earlier (layer 22.1/28) than memorized facts (28.0/28). We release MechLens supporting five model families.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that factual knowledge in LLMs does not emerge gradually across layers but crystallizes abruptly in the final layers. Across five model families (0.5-14B), 26.8%-93.4% of correct answers never appear in tuned-lens top-10 predictions at intermediate layers, with >80% depth emergence consistent; this is specific to factual recall (vs. sentiment control) and affects intervention choice (CAA outperforms DoLa on moderate-crystallization models). Additional claims include a computability-memorization spectrum and a LayerNorm ablation showing intrinsic residual-stream effects. MechLens is released.
Significance. If the measurement is valid, the late-crystallization finding supplies a mechanistic account of why certain interventions succeed and offers a practical editing principle (e.g., LN scaling). Cross-model and cross-benchmark consistency plus the public release of MechLens are concrete strengths that would aid reproducibility and follow-up work.
major comments (1)
- [Abstract (quantification paragraph)] Abstract (quantification paragraph) and tuned-lens results: the central claim that non-appearance in top-10 at layers <80% depth means knowledge has not yet crystallized requires that the affine tuned lens recovers the correct token whenever the relevant information is present in the residual stream. The sentiment-classification control and cross-model results address probe choice but do not test whether non-linear feature interactions or directions misaligned with the lens objective could produce an artifactual late signal. A direct test (e.g., whether the lens achieves near-ceiling recovery on a set of facts known to be present early by other probes) is needed to support the interpretation.
minor comments (1)
- [Abstract] Abstract omits dataset sizes, number of prompts, error bars, and statistical-test details for the reported percentages and p-values.
Simulated Author's Rebuttal
We thank the referee for highlighting a key assumption in our measurement approach. We address the concern regarding the tuned lens below and outline a planned revision to strengthen the supporting evidence.
read point-by-point responses
-
Referee: [Abstract (quantification paragraph)] Abstract (quantification paragraph) and tuned-lens results: the central claim that non-appearance in top-10 at layers <80% depth means knowledge has not yet crystallized requires that the affine tuned lens recovers the correct token whenever the relevant information is present in the residual stream. The sentiment-classification control and cross-model results address probe choice but do not test whether non-linear feature interactions or directions misaligned with the lens objective could produce an artifactual late signal. A direct test (e.g., whether the lens achieves near-ceiling recovery on a set of facts known to be present early by other probes) is needed to support the interpretation.
Authors: We agree that the interpretation of late crystallization rests on the tuned lens being able to recover the correct token when relevant information is present in the residual stream. The tuned lens is an affine map trained to reconstruct the final-layer vocabulary distribution from each intermediate residual stream, which is the established method for this type of analysis. The sentiment-classification control (0.5–2.0% late emergence vs. 26.8–85.9% for facts) and cross-model/cross-scale consistency reduce the chance of a lens-specific artifact, as any systematic misalignment would be expected to appear across tasks. Nevertheless, we acknowledge that this does not directly rule out non-linear interactions or misaligned directions. We will add a direct validation in the revision: on a subset of facts, we will train an alternative linear probe on early-layer activations using ground-truth labels and compare its recovery rate to the tuned lens, reporting whether the lens achieves near-ceiling performance on facts independently shown to be present early. revision: yes
Circularity Check
No circularity: claims rest on direct empirical counts of top-10 emergence
full rationale
The paper quantifies late crystallization via direct layer-wise counts of whether correct answers enter the top-10 under tuned-lens decoding, with no equations, fitted parameters, or self-citations that reduce the reported percentages or intervention comparisons to the inputs by construction. The tuned-lens usage is presented as an external control for probe choice rather than a self-referential definition, and the crystallization-guided intervention results are compared against independently measured crystallization depths rather than being forced by them. This is a standard empirical measurement pipeline with no load-bearing self-definition or renaming of known results.
Axiom & Free-Parameter Ledger
free parameters (2)
- top-10 prediction threshold
- >80% depth cutoff
axioms (1)
- domain assumption Tuned lens suffices to rule out probe artifacts
Reference graph
Works this paper leans on
-
[1]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle=. Locating and Editing Factual Associations in
-
[2]
International Conference on Learning Representations , year=
Mass-Editing Memory in a Transformer , author=. International Conference on Learning Representations , year=
-
[3]
Proceedings of EMNLP , year=
Transformer Feed-Forward Layers Are Key-Value Memories , author=. Proceedings of EMNLP , year=
-
[4]
Proceedings of EMNLP , year=
Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space , author=. Proceedings of EMNLP , year=
-
[5]
Proceedings of EMNLP , year=
Dissecting Recall of Factual Associations in Auto-Regressive Language Models , author=. Proceedings of EMNLP , year=
-
[6]
AI Alignment Forum , year=
Fact Finding: Attempting to Reverse-Engineer Factual Recall on the Neuron Level , author=. AI Alignment Forum , year=
-
[7]
Transformer Circuits Thread , year=
Circuit Tracing: Revealing Computational Graphs in Language Models , author=. Transformer Circuits Thread , year=
-
[8]
2022 , howpublished=
TransformerLens , author=. 2022 , howpublished=
2022
-
[9]
LessWrong , year=
Interpreting GPT: the logit lens , author=. LessWrong , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Eliciting Latent Predictions from Transformers with the Tuned Lens , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Wang, Zhenyu , journal=
-
[12]
Advances in Neural Information Processing Systems , volume=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Chuang, Yung-Sung and Xie, Yujia and Luo, Hongyin and Kim, Yoon and Glass, James and He, Pengcheng , booktitle=
-
[14]
Steering Language Models With Activation Engineering
Activation Addition: Steering Language Models Without Optimization , author=. arXiv preprint arXiv:2308.10248 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Representation Engineering: A Top-Down Approach to
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and others , journal=. Representation Engineering: A Top-Down Approach to
-
[16]
Zhang, Yifan and others , booktitle=
-
[17]
International Conference on Learning Representations , year=
Discovering Latent Knowledge in Language Models Without Supervision , author=. International Conference on Learning Representations , year=
-
[18]
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions , author=. arXiv preprint arXiv:2311.05232 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
ACM Computing Surveys , volume=
Survey of Hallucination in Natural Language Generation , author=. ACM Computing Surveys , volume=
-
[20]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[21]
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P and others , journal=. Judging
-
[22]
International Conference on Machine Learning , year=
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling , author=. International Conference on Machine Learning , year=
-
[23]
Gemma: Open Models Based on Gemini Research and Technology
Gemma: Open Models Based on Gemini Research and Technology , author=. arXiv preprint arXiv:2403.08295 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
The Llama 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and de Las Casas, Diego and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and others , journal=. Mistral
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.