Sci-Rho: A Multilingual Visually-Grounded Symbolic Benchmark for STEM Problems
Pith reviewed 2026-06-27 20:09 UTC · model grok-4.3
The pith
A benchmark of executable STEM problem templates reveals that vision-language models have large gaps between their average accuracy and worst-case accuracy across equivalent variations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Sci-Rho supplies 4,242 problem templates (606 per language) implemented as executable Python code that generates 42,420 total instances by varying numerical values, visual patterns, geometric shapes, color schemes, function types, and language. When 17 state-of-the-art VLMs are evaluated, worst-case accuracy (templates solved correctly on every generated variation) is substantially lower than average accuracy. Smaller models exhibit clear performance drops across languages, whereas proprietary and larger models remain robust. Step-level F1 scores display the same average-to-worst-case gap, and inspection of attention heads indicates substantial cross-lingual differences in the relative atten
What carries the argument
Executable Python code templates that generate diverse but reasoning-equivalent problem instances with attached reasoning steps and ground-truth solutions.
If this is right
- Worst-case accuracy across template variations is a stricter test of robustness than standard average accuracy.
- Language robustness in VLMs scales with model size, with smaller models showing clear degradation.
- Step-level reasoning evaluation exposes the same robustness shortfalls as final-answer accuracy.
- Attention allocation between image and text tokens varies with language, pointing to internal processing differences.
Where Pith is reading between the lines
- Training regimes could add explicit consistency losses that penalize different answers on equivalent inputs.
- The benchmark could be extended to new languages or subjects to test whether the size-based robustness pattern holds more broadly.
- Models that maintain balanced attention across languages may require architectural changes beyond scale alone.
Load-bearing premise
The many variations produced from each template all require exactly the same reasoning steps even after numbers, shapes, colors, and languages are changed.
What would settle it
A follow-up experiment in which domain experts independently verify that every generated variation from a template demands identical reasoning and the measured gap between average and worst-case accuracy disappears.
Figures
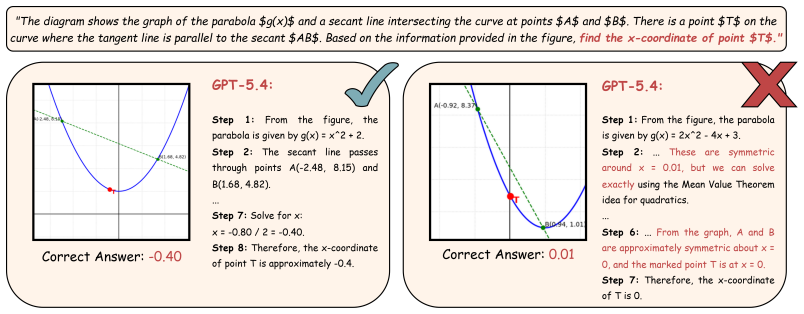
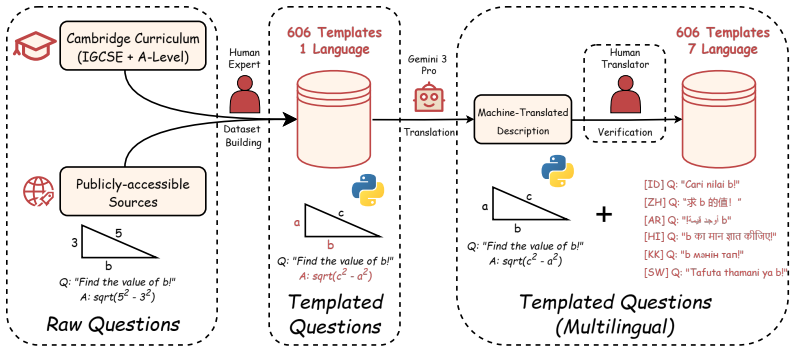
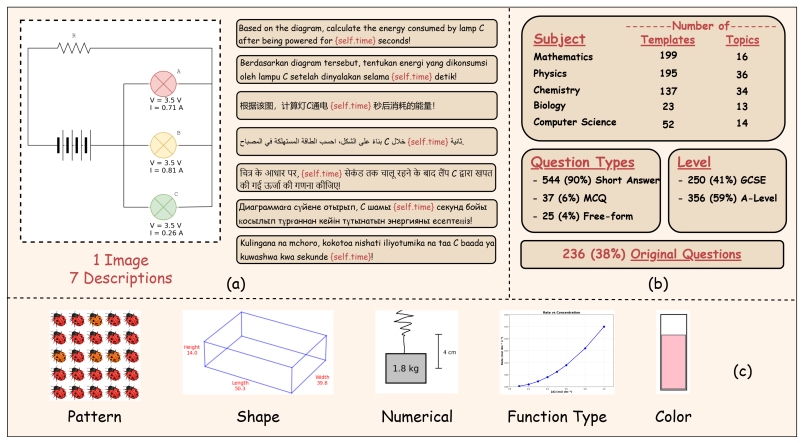
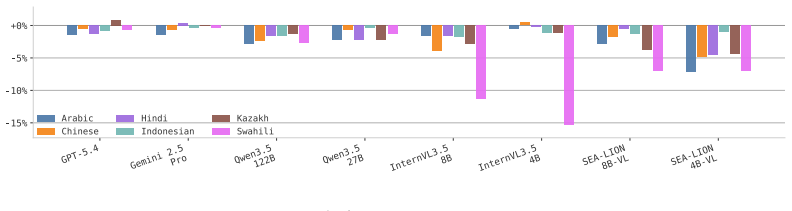
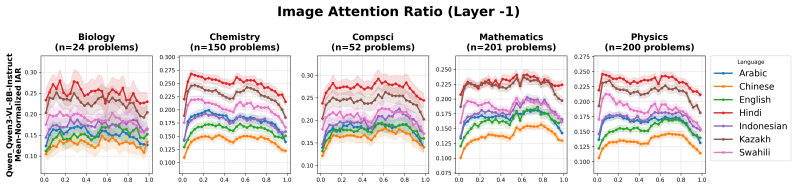

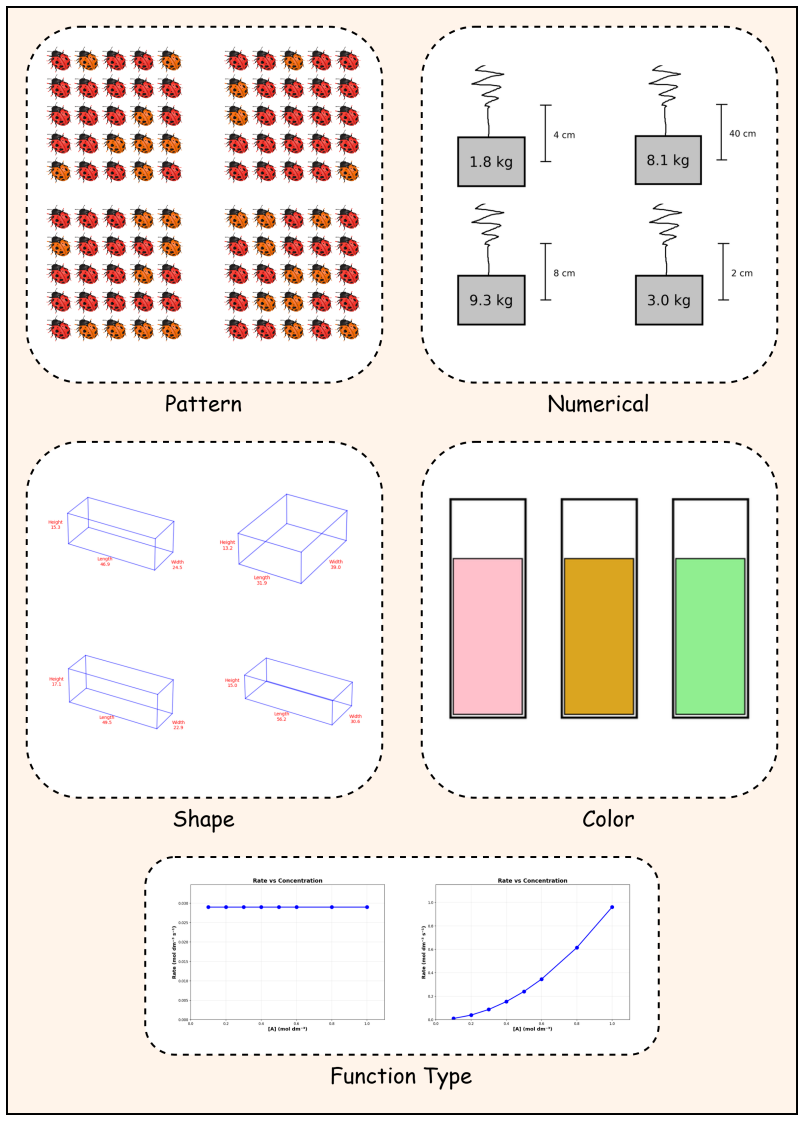
read the original abstract
Symbolic benchmarks have emerged as a key approach to assess model robustness under minor modifications to STEM-related questions. However, existing symbolic benchmarks mostly remain limited to mathematical reasoning, lack visual grounding, and are predominantly in English. In this work, we introduce Sci-Rho (Science Rhobustness), a dynamic benchmark for visually-grounded STEM problems spanning five subjects and seven languages, comprising 4,242 problem templates (606 per language) crafted by domain experts, including Olympiad medalists. Each template is implemented as executable Python code that generates diverse but equivalent problem instances by varying numerical values, visual patterns, geometric shapes, color schemes, and function types, resulting in 42,420 instances in total, each paired with reasoning steps and ground-truth solutions. We evaluated 17 state-of-the-art VLMs and discovered a noticeable gap between worst-case accuracy (defined as the proportion of problem templates that a model answers correctly across every generated variation) and average accuracy. We also discovered that smaller models show noticeable performance degradation across languages, whereas proprietary and larger models remain robust. Step-level evaluation reflects this same trend, revealing a significant gap between average F1 and worst-case F1 scores. Finally, our inspection of attention heads of a VLM reveals substantial cross-lingual variation in the relative attention allocated to image tokens compared to text tokens. Our work highlights the importance of evaluation beyond static benchmarks as a metric to measure the quality of VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sci-Rho, a dynamic benchmark for visually-grounded STEM problems across five subjects and seven languages. It comprises 4,242 expert-crafted problem templates (606 per language), each implemented as executable Python code generating 10 diverse but equivalent instances by varying numerical values, visual patterns, geometric shapes, color schemes, function types, and language, for a total of 42,420 instances with reasoning steps and ground-truth solutions. Evaluation of 17 VLMs reveals a gap between worst-case accuracy (templates solved correctly on all variations) and average accuracy, with smaller models showing language degradation while larger/proprietary models remain robust; similar gaps appear in step-level F1 scores, and attention analysis shows cross-lingual variation in image vs. text token attention.
Significance. If the generated variations preserve semantic and reasoning equivalence, Sci-Rho would provide a valuable contribution as a multilingual, visually-grounded dynamic benchmark that moves beyond static evaluation to measure VLM robustness in STEM domains, with the reported performance gaps and attention findings offering concrete evidence of current model limitations.
major comments (2)
- [Abstract and template construction description] The central worst-case accuracy metric and cross-lingual comparisons rest on the assumption that all 10 generated instances per template are semantically, reasoning-step, and difficulty equivalent despite changes in numbers, visuals, shapes, colors, functions, and language. No section reports independent human validation, inter-rater reliability checks, or formal equivalence verification for the full set of templates and instances; this directly affects whether failures on specific variations indicate lack of robustness rather than non-equivalent test items.
- [Step-level evaluation section] The step-level evaluation and F1 score gaps are presented as reflecting the same robustness trends, but without details on how reasoning steps are extracted, aligned across variations, or scored for equivalence, it is unclear whether the reported average vs. worst-case F1 differences are load-bearing or could be artifacts of annotation or alignment choices.
minor comments (2)
- [Abstract] The abstract states '42,420 instances in total' but the per-template count (10) and template total (4,242) imply exactly that; confirm the arithmetic and any filtering in the methods section for clarity.
- [Evaluation metrics] Notation for worst-case accuracy (proportion of templates correct on every variation) should be formalized with an equation to avoid ambiguity in replication.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity on equivalence and evaluation procedures.
read point-by-point responses
-
Referee: [Abstract and template construction description] The central worst-case accuracy metric and cross-lingual comparisons rest on the assumption that all 10 generated instances per template are semantically, reasoning-step, and difficulty equivalent despite changes in numbers, visuals, shapes, colors, functions, and language. No section reports independent human validation, inter-rater reliability checks, or formal equivalence verification for the full set of templates and instances; this directly affects whether failures on specific variations indicate lack of robustness rather than non-equivalent test items.
Authors: We acknowledge that the manuscript does not report independent human validation or inter-rater reliability metrics for equivalence. Equivalence is ensured by construction: each template was authored by domain experts (including Olympiad medalists) as executable Python code that applies controlled parametric changes while preserving the fixed reasoning structure, semantic content, and difficulty level. We will add a dedicated subsection in the template construction description that details the design process, the specific variation mechanisms, and the internal consistency checks performed by the expert authors during template development. This will make the equivalence argument more explicit without claiming external validation that was not conducted. revision: yes
-
Referee: [Step-level evaluation section] The step-level evaluation and F1 score gaps are presented as reflecting the same robustness trends, but without details on how reasoning steps are extracted, aligned across variations, or scored for equivalence, it is unclear whether the reported average vs. worst-case F1 differences are load-bearing or could be artifacts of annotation or alignment choices.
Authors: Reasoning steps are generated directly by the same executable templates, so alignment across the ten variations of each template occurs by construction: every instance follows the identical sequence of symbolic steps with only the instantiated values or visual elements differing. We will expand the step-level evaluation section to explicitly describe (1) how steps are emitted from the code, (2) the template-based alignment procedure, and (3) the exact F1 computation (token-level overlap against the ground-truth step sequence). These additions will clarify that the observed average-versus-worst-case F1 gaps arise from model behavior rather than annotation or alignment artifacts. revision: yes
Circularity Check
No significant circularity; benchmark construction and empirical evaluation are self-contained.
full rationale
The paper describes expert-crafted templates implemented as Python generators to produce problem instances, followed by direct VLM evaluation on those instances. No equations, fitted parameters, predictions, or derivations are present that reduce to inputs by construction. Claims rest on measured accuracies rather than any self-referential chain or renamed result. Self-citations are absent from the provided text, and the central metrics (worst-case vs. average accuracy) are computed directly from model outputs on the generated set.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset , author=. 2024 , eprint=
2024
-
[2]
2025 , eprint=
Vision Language Models are Confused Tourists , author=. 2025 , eprint=
2025
-
[3]
2026 , eprint=
Vision Language Models are Biased , author=. 2026 , eprint=
2026
-
[4]
2026 , eprint=
FinChain: A Symbolic Benchmark for Verifiable Chain-of-Thought Financial Reasoning , author=. 2026 , eprint=
2026
-
[5]
arXiv preprint arXiv:2405.20797 , year=
Ovis: Structural embedding alignment for multimodal large language model , author=. arXiv preprint arXiv:2405.20797 , year=
-
[6]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[7]
2024 , eprint=
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models , author=. 2024 , eprint=
2024
-
[8]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[9]
2024 , eprint=
DeepSeek-VL: Towards Real-World Vision-Language Understanding , author=. 2024 , eprint=
2024
-
[10]
Introducing LLaMA 4 , year =
-
[11]
Qwen3.5: Towards Native Multimodal Agents , year =
-
[12]
Introducing Claude 4 , year =
-
[13]
2025 , eprint=
Gemini: A Family of Highly Capable Multimodal Models , author=. 2025 , eprint=
2025
-
[14]
2025 , eprint=
OpenAI GPT-5 System Card , author=. 2025 , eprint=
2025
-
[15]
2024 , eprint=
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts , author=. 2024 , eprint=
2024
-
[17]
2025 , eprint=
SeePhys: Does Seeing Help Thinking? -- Benchmarking Vision-Based Physics Reasoning , author=. 2025 , eprint=
2025
-
[18]
2025 , eprint=
PHYBench: Holistic Evaluation of Physical Perception and Reasoning in Large Language Models , author=. 2025 , eprint=
2025
-
[19]
2025 , eprint=
PhysReason: A Comprehensive Benchmark towards Physics-Based Reasoning , author=. 2025 , eprint=
2025
-
[20]
2022 , eprint=
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , author=. 2022 , eprint=
2022
-
[21]
2025 , eprint=
SciVerse: Unveiling the Knowledge Comprehension and Visual Reasoning of LMMs on Multi-modal Scientific Problems , author=. 2025 , eprint=
2025
-
[22]
2024 , eprint=
Large Language Models Are Not Robust Multiple Choice Selectors , author=. 2024 , eprint=
2024
-
[23]
2026 , eprint=
EngTrace: A Symbolic Benchmark for Verifiable Process Supervision of Engineering Reasoning , author=. 2026 , eprint=
2026
-
[24]
2024 , eprint=
Fool Your (Vision and) Language Model With Embarrassingly Simple Permutations , author=. 2024 , eprint=
2024
-
[25]
2025 , eprint=
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models , author=. 2025 , eprint=
2025
-
[26]
2025 , eprint=
DynaMath: A Dynamic Visual Benchmark for Evaluating Mathematical Reasoning Robustness of Vision Language Models , author=. 2025 , eprint=
2025
-
[27]
2025 , eprint=
VGRP-Bench: Visual Grid Reasoning Puzzle Benchmark for Large Vision-Language Models , author=. 2025 , eprint=
2025
-
[28]
2025 , eprint=
AgroBench: Vision-Language Model Benchmark in Agriculture , author=. 2025 , eprint=
2025
-
[31]
2024 , eprint=
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. 2024 , eprint=
2024
-
[32]
2024 , eprint=
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites , author=. 2024 , eprint=
2024
-
[33]
2024 , eprint=
Improved Baselines with Visual Instruction Tuning , author=. 2024 , eprint=
2024
-
[34]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[35]
Gemini 2.5 Pro Model Card , year =
-
[36]
Gemini 2.5 Flash Model Card , year =
-
[37]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[38]
2025 , eprint=
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency , author=. 2025 , eprint=
2025
-
[39]
2026 , eprint=
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding , author=. 2026 , eprint=
2026
-
[40]
SEA-LION v4 Model Documentation , year =
-
[41]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[42]
2026 , eprint=
ChartAttack: Testing the Vulnerability of LLMs to Malicious Prompting in Chart Generation , author=. 2026 , eprint=
2026
-
[43]
2026 , eprint=
Is this chart lying to me? Automating the detection of misleading visualizations , author=. 2026 , eprint=
2026
-
[44]
2025 , eprint=
True Multimodal In-Context Learning Needs Attention to the Visual Context , author=. 2025 , eprint=
2025
-
[45]
2025 , eprint=
Words or Vision: Do Vision-Language Models Have Blind Faith in Text? , author=. 2025 , eprint=
2025
-
[46]
2025 , eprint=
Refusal Falls off a Cliff: How Safety Alignment Fails in Reasoning? , author=. 2025 , eprint=
2025
-
[47]
2025 , eprint=
MLLMs are Deeply Affected by Modality Bias , author=. 2025 , eprint=
2025
-
[48]
Sea-lion v4 model documentation
AI Singapore . Sea-lion v4 model documentation. https://docs.sea-lion.ai/models/sea-lion-v4, 2026. Accessed: 2026-04-26
2026
-
[49]
Qwen3-vl technical report, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
Pith/arXiv arXiv 2025
-
[50]
True multimodal in-context learning needs attention to the visual context, 2025
Shuo Chen, Jianzhe Liu, Zhen Han, Yan Xia, Daniel Cremers, Philip Torr, Volker Tresp, and Jindong Gu. True multimodal in-context learning needs attention to the visual context, 2025. URL https://arxiv.org/abs/2507.15807
arXiv 2025
-
[51]
Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, Vincent Shao, Yue Yang, Weikai Huang, Ziqi Gao, Taira Anderson, Jianrui Zhang, Jitesh Jain, George Stoica, Winson Han, Ali Farhadi, and Ranjay Krishna. Molmo2: Open weights and data for vision-language m...
Pith/arXiv arXiv 2026
-
[52]
Words or vision: Do vision-language models have blind faith in text?, 2025
Ailin Deng, Tri Cao, Zhirui Chen, and Bryan Hooi. Words or vision: Do vision-language models have blind faith in text?, 2025. URL https://arxiv.org/abs/2503.02199
arXiv 2025
-
[53]
Gemini 2.5 flash model card
Google DeepMind . Gemini 2.5 flash model card. https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-2-5-Flash-Model-Card.pdf, 2025 a . Accessed: 2026-04-26
2025
-
[54]
Gemini 2.5 pro model card
Google DeepMind . Gemini 2.5 pro model card. https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-2-5-Pro-Model-Card.pdf, 2025 b . Accessed: 2026-04-26
2025
-
[55]
Engtrace: A symbolic benchmark for verifiable process supervision of engineering reasoning, 2026
Ayesha Gull, Muhammad Usman Safder, Rania Elbadry, Fan Zhang, Veselin Stoyanov, Preslav Nakov, and Zhuohan Xie. Engtrace: A symbolic benchmark for verifiable process supervision of engineering reasoning, 2026. URL https://arxiv.org/abs/2511.01650
Pith/arXiv arXiv 2026
-
[56]
Ziyu Guo, Ray Zhang, Hao Chen, Jialin Gao, Dongzhi Jiang, Jiaze Wang, and Pheng-Ann Heng. Sciverse: Unveiling the knowledge comprehension and visual reasoning of lmms on multi-modal scientific problems, 2025. URL https://arxiv.org/abs/2503.10627
arXiv 2025
-
[57]
Vision language models are confused tourists, 2025
Patrick Amadeus Irawan, Ikhlasul Akmal Hanif, Muhammad Dehan Al Kautsar, Genta Indra Winata, Fajri Koto, and Alham Fikri Aji. Vision language models are confused tourists, 2025. URL https://arxiv.org/abs/2511.17004
arXiv 2025
-
[58]
Learn to explain: Multimodal reasoning via thought chains for science question answering, 2022
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering, 2022. URL https://arxiv.org/abs/2209.09513
arXiv 2022
-
[59]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts, 2024
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts, 2024. URL https://arxiv.org/abs/2310.02255
Pith/arXiv arXiv 2024
-
[60]
Introducing llama 4, 2025
Meta AI . Introducing llama 4, 2025. URL https://ai.meta.com/llama/. Accessed: 2026-04-16
2025
-
[61]
Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models, 2025
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models, 2025. URL https://arxiv.org/abs/2410.05229
Pith/arXiv arXiv 2025
-
[62]
Benchmarking Vision Language Models for Cultural Understanding
Shravan Nayak, Kanishk Jain, Rabiul Awal, Siva Reddy, Sjoerd Van Steenkiste, Lisa Anne Hendricks, Karolina Stanczak, and Aishwarya Agrawal. Benchmarking vision language models for cultural understanding. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pa...
-
[63]
Jean De Dieu Nyandwi, Yueqi Song, Simran Khanuja, and Graham Neubig. Grounding multilingual multimodal LLM s with cultural knowledge. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 24198--24242, Suzhou, China, November...
-
[64]
Phybench: Holistic evaluation of physical perception and reasoning in large language models, 2025
Shi Qiu, Shaoyang Guo, Zhuo-Yang Song, Yunbo Sun, Zeyu Cai, Jiashen Wei, Tianyu Luo, Yixuan Yin, Haoxu Zhang, Yi Hu, Chenyang Wang, Chencheng Tang, Haoling Chang, Qi Liu, Ziheng Zhou, Tianyu Zhang, Jingtian Zhang, Zhangyi Liu, Minghao Li, Yuku Zhang, Boxuan Jing, Xianqi Yin, Yutong Ren, Zizhuo Fu, Jiaming Ji, Weike Wang, Xudong Tian, Anqi Lv, Laifu Man, J...
arXiv 2025
-
[65]
Vgrp-bench: Visual grid reasoning puzzle benchmark for large vision-language models, 2025
Yufan Ren, Konstantinos Tertikas, Shalini Maiti, Junlin Han, Tong Zhang, Sabine Süsstrunk, and Filippos Kokkinos. Vgrp-bench: Visual grid reasoning puzzle benchmark for large vision-language models, 2025. URL https://arxiv.org/abs/2503.23064
arXiv 2025
-
[66]
Agrobench: Vision-language model benchmark in agriculture, 2025
Risa Shinoda, Nakamasa Inoue, Hirokatsu Kataoka, Masaki Onishi, and Yoshitaka Ushiku. Agrobench: Vision-language model benchmark in agriculture, 2025. URL https://arxiv.org/abs/2507.20519
arXiv 2025
-
[67]
Openai gpt-5 system card, 2025
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexandra Barr, Alexandre Kirchmeyer, Ale...
Pith/arXiv arXiv 2025
-
[68]
Kai Sun, Yushi Bai, Ji Qi, Lei Hou, and Juanzi Li. MM - MATH : Advancing multimodal math evaluation with process evaluation and fine-grained classification. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Findings of the Association for Computational Linguistics: EMNLP 2024, pages 1358--1375, Miami, Florida, USA, November 2024. Association ...
-
[69]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
Pith/arXiv arXiv 2025
-
[70]
Vision language models are biased, 2026
An Vo, Khai-Nguyen Nguyen, Mohammad Reza Taesiri, Vy Tuong Dang, Anh Totti Nguyen, and Daeyoung Kim. Vision language models are biased, 2026. URL https://arxiv.org/abs/2505.23941
Pith/arXiv arXiv 2026
-
[71]
Measuring multimodal mathematical reasoning with math-vision dataset, 2024
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset, 2024. URL https://arxiv.org/abs/2402.14804
Pith/arXiv arXiv 2024
-
[72]
Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency, 2025
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, Guanzhou Chen, Zichen Ding, Changyao Tian, Zhenyu Wu, Jingjing Xie, Zehao Li, Bowen Yang, Yuchen Duan, Xuehui Wang, Zhi Hou,...
Pith/arXiv arXiv 2025
-
[73]
Seephys: Does seeing help thinking? -- benchmarking vision-based physics reasoning, 2025
Kun Xiang, Heng Li, Terry Jingchen Zhang, Yinya Huang, Zirong Liu, Peixin Qu, Jixi He, Jiaqi Chen, Yu-Jie Yuan, Jianhua Han, Hang Xu, Hanhui Li, Mrinmaya Sachan, and Xiaodan Liang. Seephys: Does seeing help thinking? -- benchmarking vision-based physics reasoning, 2025. URL https://arxiv.org/abs/2505.19099
arXiv 2025
-
[74]
Finchain: A symbolic benchmark for verifiable chain-of-thought financial reasoning, 2026
Zhuohan Xie, Daniil Orel, Rushil Thareja, Dhruv Sahnan, Hachem Madmoun, Fan Zhang, Debopriyo Banerjee, Georgi Georgiev, Xueqing Peng, Lingfei Qian, Jimin Huang, Jinyan Su, Aaryamonvikram Singh, Rui Xing, Rania Elbadry, Chen Xu, Haonan Li, Fajri Koto, Ivan Koychev, Tanmoy Chakraborty, Yuxia Wang, Salem Lahlou, Veselin Stoyanov, Sophia Ananiadou, and Presla...
Pith/arXiv arXiv 2026
-
[75]
Refusal falls off a cliff: How safety alignment fails in reasoning?, 2025
Qingyu Yin, Chak Tou Leong, Linyi Yang, Wenxuan Huang, Wenjie Li, Xiting Wang, Jaehong Yoon, YunXing, XingYu, and Jinjin Gu. Refusal falls off a cliff: How safety alignment fails in reasoning?, 2025. URL https://arxiv.org/abs/2510.06036
arXiv 2025
-
[76]
Physreason: A comprehensive benchmark towards physics-based reasoning, 2025
Xinyu Zhang, Yuxuan Dong, Yanrui Wu, Jiaxing Huang, Chengyou Jia, Basura Fernando, Mike Zheng Shou, Lingling Zhang, and Jun Liu. Physreason: A comprehensive benchmark towards physics-based reasoning, 2025. URL https://arxiv.org/abs/2502.12054
arXiv 2025
-
[77]
Large language models are not robust multiple choice selectors, 2024
Chujie Zheng, Hao Zhou, Fandong Meng, Jie Zhou, and Minlie Huang. Large language models are not robust multiple choice selectors, 2024. URL https://arxiv.org/abs/2309.03882
arXiv 2024
-
[78]
Mllms are deeply affected by modality bias, 2025
Xu Zheng, Chenfei Liao, Yuqian Fu, Kaiyu Lei, Yuanhuiyi Lyu, Lutao Jiang, Bin Ren, Jialei Chen, Jiawen Wang, Chengxin Li, Linfeng Zhang, Danda Pani Paudel, Xuanjing Huang, Yu-Gang Jiang, Nicu Sebe, Dacheng Tao, Luc Van Gool, and Xuming Hu. Mllms are deeply affected by modality bias, 2025. URL https://arxiv.org/abs/2505.18657
arXiv 2025
-
[79]
Fool your (vision and) language model with embarrassingly simple permutations, 2024
Yongshuo Zong, Tingyang Yu, Ruchika Chavhan, Bingchen Zhao, and Timothy Hospedales. Fool your (vision and) language model with embarrassingly simple permutations, 2024. URL https://arxiv.org/abs/2310.01651
arXiv 2024
-
[80]
Chengke Zou, Xingang Guo, Rui Yang, Junyu Zhang, Bin Hu, and Huan Zhang. Dynamath: A dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models, 2025. URL https://arxiv.org/abs/2411.00836
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.