OSMGraphCLIP: Learning Global Location Representations from OpenStreetMap Graphs
Pith reviewed 2026-06-27 19:47 UTC · model grok-4.3
The pith
Structured OpenStreetMap data alone supports global location embeddings that match or exceed satellite baselines on most tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
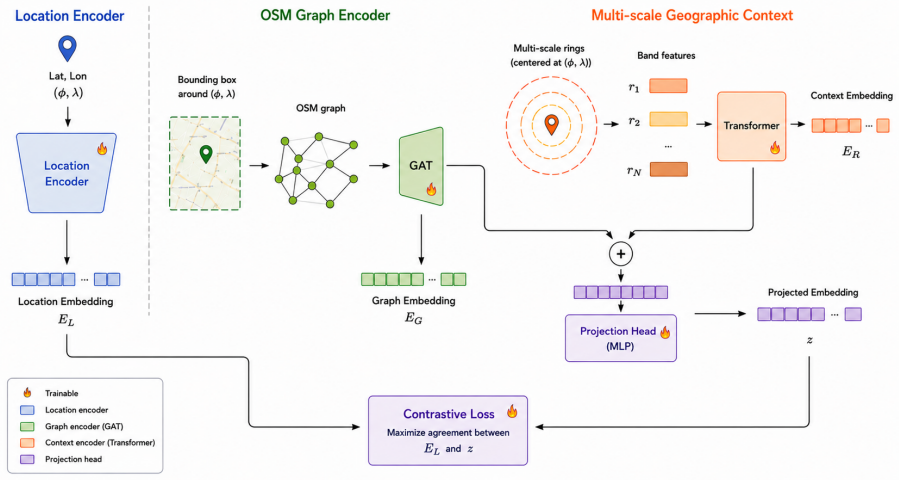
OSMGraphCLIP shows that representing geographic environments as heterogeneous graphs of typed OSM features, processed by a multi-scale graph encoder and aligned via contrastive objective to a spherical-harmonics location encoder, produces embeddings that generalize across domains and match or exceed satellite-based baselines, especially where built-environment semantics matter.
What carries the argument
Heterogeneous graphs of OSM features with multi-scale graph encoding aligned contrastively to a spherical-harmonics location encoder.
If this is right
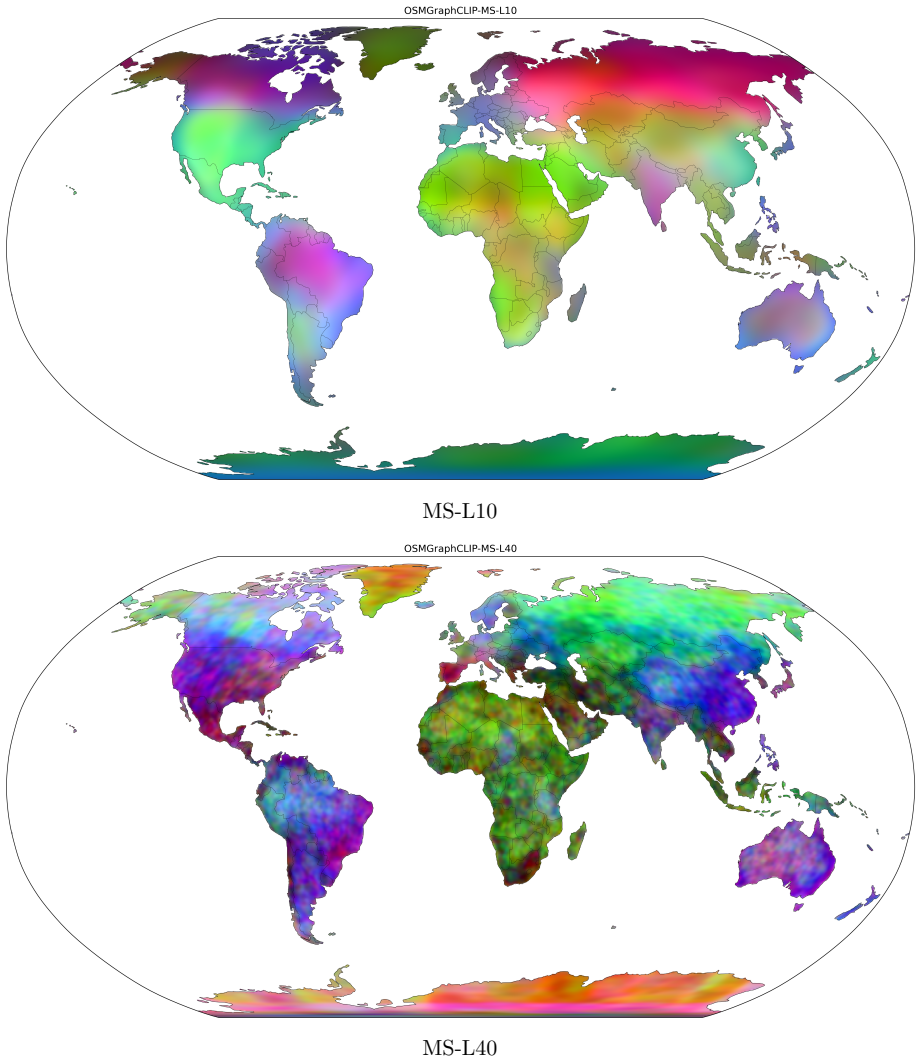
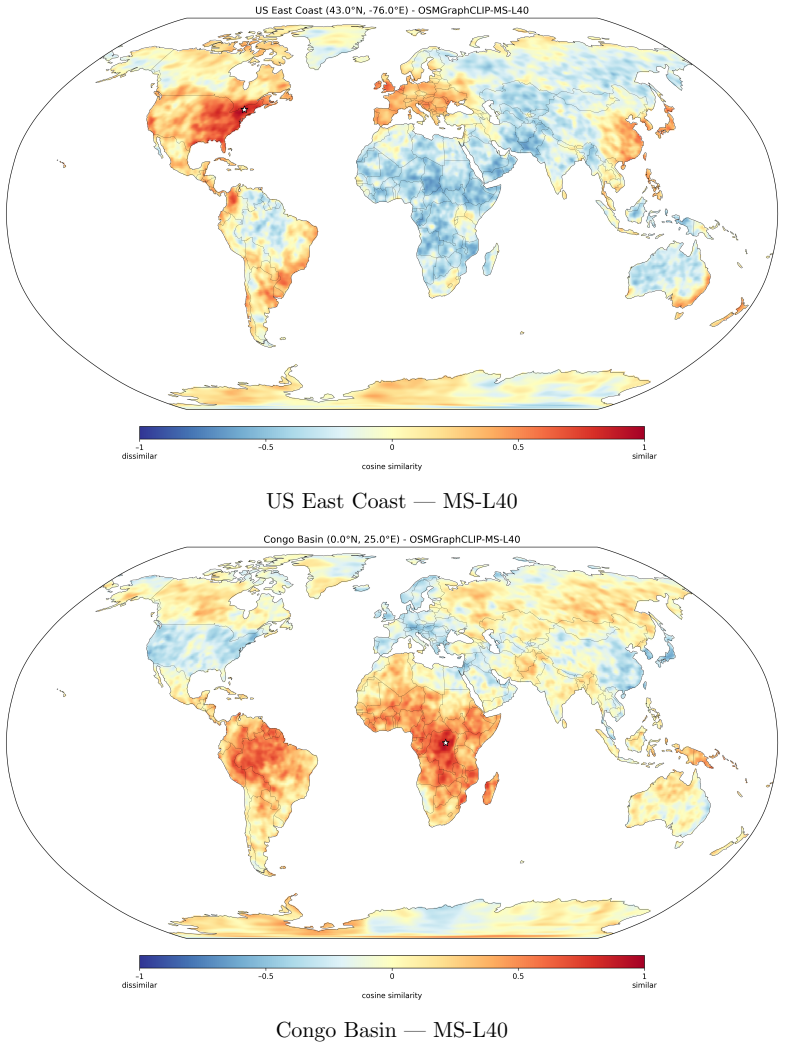
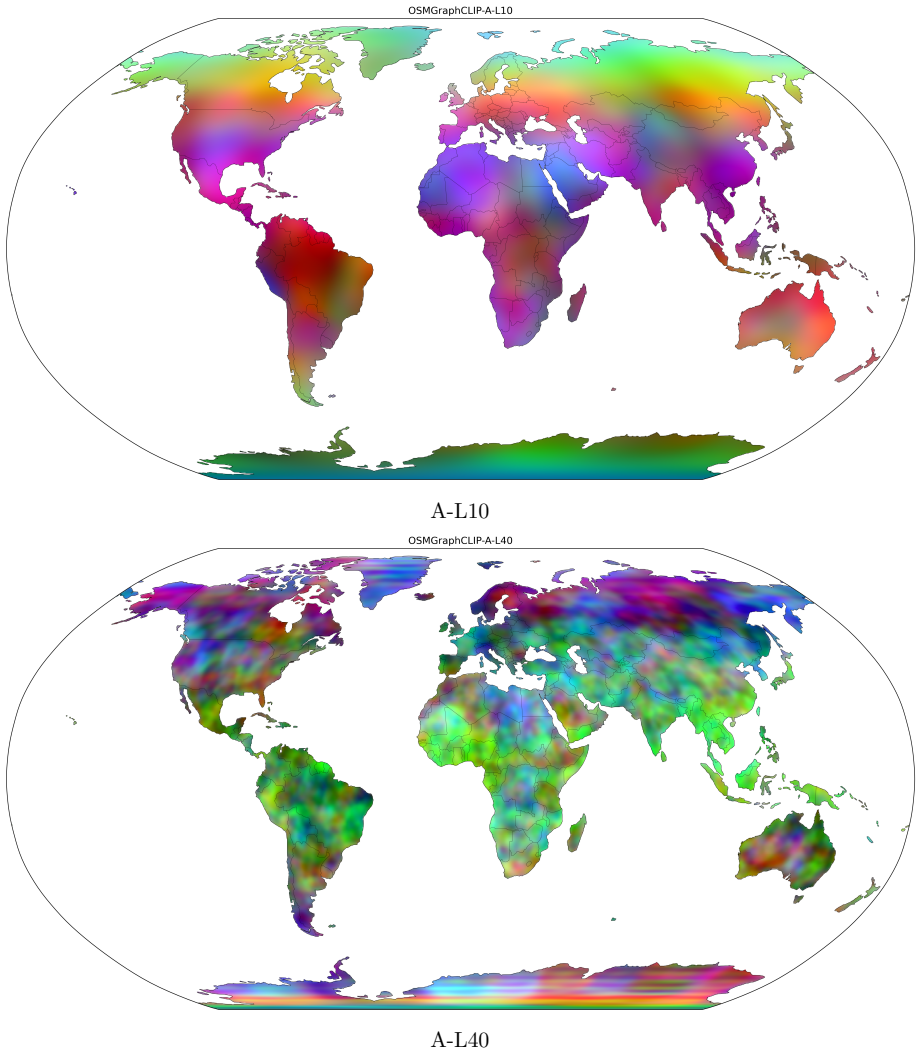
- Embeddings recover biome boundaries, urban gradients, and tropical-temperate distinctions from map topology alone.
- Advantages over satellite methods are largest on socioeconomic and public-health tasks due to explicit semantic annotation of the built environment.
- Ecological and environmental tasks remain competitive with imagery methods despite using no Earth observation data.
- The learned embeddings organize geographic space coherently without any satellite input.
Where Pith is reading between the lines
- Map-derived embeddings could lower data costs for prediction tasks that currently rely on commercial satellite sources.
- Adding temporal OSM updates might strengthen performance on forecasting tasks such as wildfire prediction.
- The same graph construction could be tested on regions with sparse OSM coverage to measure how annotation density affects downstream accuracy.
Load-bearing premise
The graph construction from OSM features plus the multi-scale encoder and contrastive objective extract semantic and topological signals that generalize to the reported downstream domains.
What would settle it
Performance on the reported benchmarks drops below satellite baselines when the contrastive alignment step is removed or when key OSM feature types such as buildings and roads are withheld from the graphs.
Figures
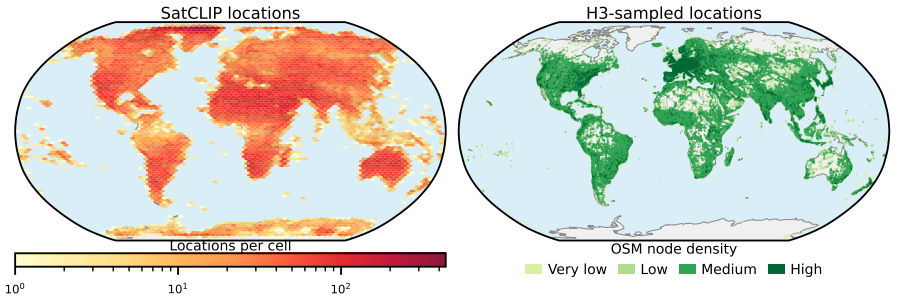
read the original abstract
We present OSMGraphCLIP, a CLIP-style geospatial representation model that learns global location embeddings from freely available OpenStreetMap (OSM) data. OSMGraphCLIP represents geographic environments as heterogeneous graphs of typed OSM features, preserving the topological and semantic relationships among roads, buildings, land-use regions, and points of interest. A multi-scale graph encoder captures both fine-grained local structure and broader landscape composition, and supervises a spherical-harmonics location encoder through a contrastive alignment objective. We evaluate OSMGraphCLIP across a diverse suite of downstream geospatial regression and classification tasks spanning climate, ecology, socioeconomic indicators, public health, land cover, biodiversity, and wildfire forecasting, and show that structured OSM data alone supports strong global location representations across domains. OSMGraphCLIP matches or exceeds satellite-based baselines on the majority of benchmarks, with the most pronounced advantage on socioeconomic and public-health tasks, where OSM's explicit semantic annotation of the built environment encodes patterns of human activity that satellite pixels can only capture indirectly. On ecological and environmental tasks, the model remains closely competitive with imagery-based methods despite using no Earth observation data. Qualitative analysis confirms that the learned embeddings organize geographic space coherently, recovering biome boundaries, urban gradients, and tropical--temperate distinctions from map topology alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OSMGraphCLIP, a CLIP-style model that constructs heterogeneous graphs from OpenStreetMap features (roads, buildings, land-use, POIs) and trains a multi-scale graph encoder to align with a spherical-harmonics location encoder via contrastive loss. It evaluates the resulting global location embeddings on downstream regression and classification tasks spanning climate, ecology, socioeconomic indicators, public health, land cover, biodiversity, and wildfire forecasting, claiming that OSMGraphCLIP matches or exceeds satellite-based baselines on the majority of benchmarks (with largest gains on socioeconomic and public-health tasks) while remaining competitive on ecological tasks despite using no imagery.
Significance. If the empirical claims are substantiated, the result would be significant: it would establish that freely available, semantically annotated vector map data can produce location representations competitive with or superior to satellite imagery for many geospatial tasks, particularly those involving human activity patterns. This has practical implications for data accessibility and cost in geospatial ML and demonstrates the value of explicit topological and semantic structure over pixel-based inputs.
major comments (2)
- [Experimental evaluation (implied §4–5)] The provided abstract and summary supply no information on dataset sizes, number of evaluation samples, baseline implementations, hyper-parameter search, or statistical testing for the reported downstream results. Without these details it is impossible to assess whether the claimed superiority on the majority of benchmarks is robust or could be explained by differences in training scale or evaluation protocol.
- [Methods and data preparation (implied §3)] The central generalization claim—that the heterogeneous graph construction plus multi-scale encoder and contrastive objective extract task-relevant signals that transfer to the reported domains—rests on the assumption that no data leakage occurs between OSM feature selection/graph construction and the downstream task labels. The manuscript must explicitly describe the train/test splits and confirm that no OSM attributes used in graph construction overlap with evaluation targets.
minor comments (1)
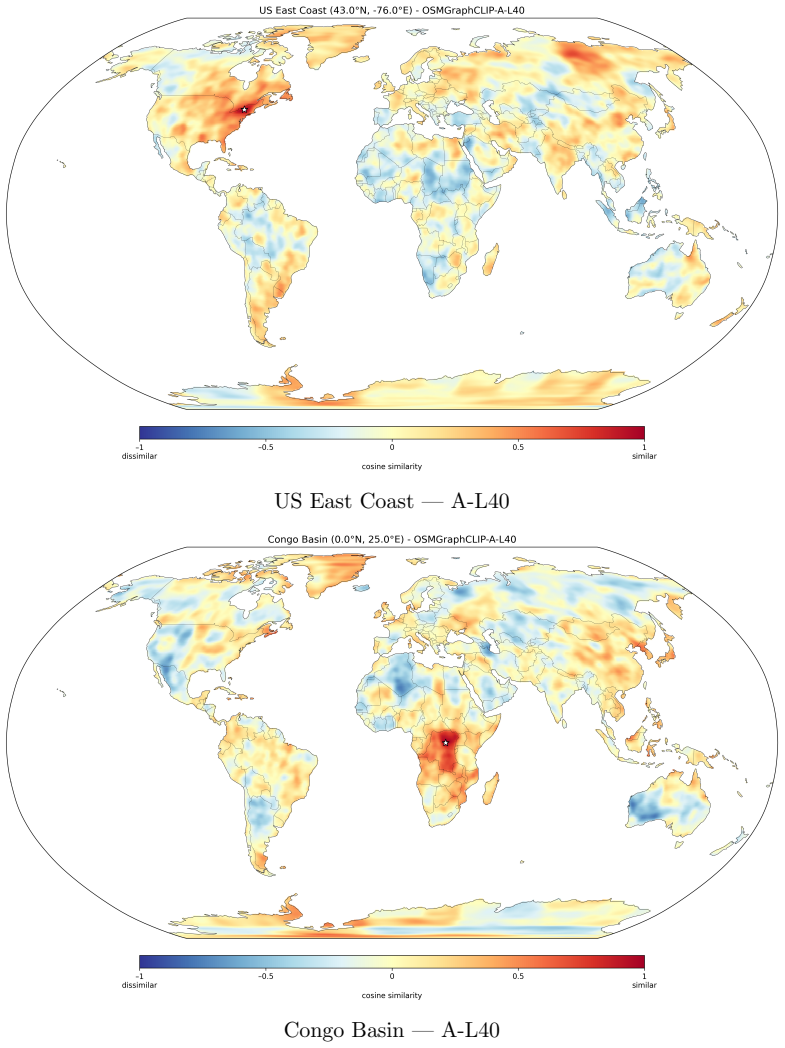
- [Abstract] The abstract refers to 'qualitative analysis' confirming coherent organization of geographic space but provides no description of the visualization or analysis method.
Simulated Author's Rebuttal
We are grateful to the referee for their thoughtful review and valuable suggestions for improving the clarity and rigor of our manuscript. We address the two major comments point-by-point below. Both points can be addressed through revisions that enhance experimental details and methodological transparency without altering the core contributions.
read point-by-point responses
-
Referee: [Experimental evaluation (implied §4–5)] The provided abstract and summary supply no information on dataset sizes, number of evaluation samples, baseline implementations, hyper-parameter search, or statistical testing for the reported downstream results. Without these details it is impossible to assess whether the claimed superiority on the majority of benchmarks is robust or could be explained by differences in training scale or evaluation protocol.
Authors: We agree that greater detail on these aspects is necessary for assessing robustness. Although the full manuscript describes the evaluation datasets and tasks in Sections 4–5, we will add a new subsection (or expanded table) in the experimental evaluation section that explicitly reports dataset sizes, number of evaluation samples per task, baseline implementation details (including any re-implementations or public code used), the hyperparameter search procedure, and statistical testing (e.g., standard deviations across runs or significance tests). This will allow direct evaluation of whether performance differences are robust. revision: yes
-
Referee: [Methods and data preparation (implied §3)] The central generalization claim—that the heterogeneous graph construction plus multi-scale encoder and contrastive objective extract task-relevant signals that transfer to the reported domains—rests on the assumption that no data leakage occurs between OSM feature selection/graph construction and the downstream task labels. The manuscript must explicitly describe the train/test splits and confirm that no OSM attributes used in graph construction overlap with evaluation targets.
Authors: We agree that explicit confirmation of no data leakage is essential. OSM feature selection relies exclusively on standard, globally available map elements (roads, buildings, land use, POIs) chosen without reference to any downstream task labels. All downstream tasks use independent public datasets whose train/test splits are followed exactly as defined by their original sources. We will revise Section 3 to include (i) explicit descriptions of the train/test splits employed for each downstream task and (ii) a clear statement confirming that no OSM attributes were selected or filtered on the basis of evaluation targets. revision: yes
Circularity Check
No significant circularity
full rationale
The provided abstract and description outline a standard contrastive learning pipeline (heterogeneous OSM graph construction, multi-scale graph encoder, spherical-harmonics location encoder, contrastive alignment) evaluated on downstream tasks. No equations, fitted parameters, or self-citations are shown that would reduce any reported performance metric to a quantity defined by the same inputs or by construction. The central claim rests on empirical generalization across domains rather than any self-referential derivation step, rendering the argument self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mohit Agarwal, Mimi Sun, Chaitanya Kamath, Arbaaz Muslim, Prithul Sarker, Joy- deep Paul, Hector Yee, Marcin Sieniek, Kim Jablonski, Yael Mayer, et al. General geospatial inference with a population dynamics foundation model.arXiv preprint arXiv:2411.07207, 2024
Pith/arXiv arXiv 2024
-
[2]
GAIR Authors. GAIR: Aligning satellite, street view, and location embeddings via contrastive learning.arXiv preprint arXiv:2503.16683, 2025
Pith/arXiv arXiv 2025
-
[3]
H3-MOSAIC: Combining OSM semantics and satellite imagery on spatial grids.International Journal of Health Geographics, 2025
H3-MOSAIC Authors. H3-MOSAIC: Combining OSM semantics and satellite imagery on spatial grids.International Journal of Health Geographics, 2025
2025
-
[4]
Lubian Bai, Xiuyuan Zhang, Siqi Zhang, Zepeng Zhang, Haoyu Wang, Wei Qin, and Shihong Du. Geolink: Empowering remote sensing foundation model with open- streetmap data.arXiv preprint arXiv:2509.26016, 2025
arXiv 2025
-
[5]
H3: Uber’s hexagonal hierarchical spatial index
Isaac Brodsky. H3: Uber’s hexagonal hierarchical spatial index. Uber Engineering Blog, 2018. URLhttps://eng.uber.com/h3/. Accessed 2026
2018
-
[6]
Christopher F Brown, Michal R Kazmierski, Valerie J Pasquarella, William J Ruck- lidge, Masha Samsikova, Chenhui Zhang, Evan Shelhamer, Estefania Lahera, Olivia Wiles, Simon Ilyushchenko, et al. Alphaearth foundations: An embedding field model for accurate and efficient global mapping from sparse label data.arXiv preprint arXiv:2507.22291, 2025
Pith/arXiv arXiv 2025
-
[7]
PLACES: Local data for better health, ZCTA data (GIS-friendly format), 2023 release
Centers for Disease Control and Prevention. PLACES: Local data for better health, ZCTA data (GIS-friendly format), 2023 release. Data.CDC.gov, 2023. URLhttps://data.cdc.gov/500-Cities-Places/ PLACES-ZCTA-Data-GIS-Friendly-Format-2023-release/c7b2-4ecy/about_ data. Accessed 2026
2023
-
[8]
Kai Norman Clasen, Leonard Hackel, Tom Burgert, Gencer Sumbul, Beg¨ um Demir, and Volker Markl. reBEN: Refined BigEarthNet dataset for remote sensing image analysis.arXiv preprint arXiv:2407.03653, 2024
arXiv 2024
-
[9]
A small set of formal topological relationships suitable for end-user interaction
Eliseo Clementini, Paolino Di Felice, and Peter Van Oosterom. A small set of formal topological relationships suitable for end-user interaction. InInternational symposium on spatial databases, pages 277–295. Springer, 1993
1993
-
[10]
A formal approach to imprecise and incomplete geographical objects.Computers, Envi- ronment and Urban Systems, 22(5):395–408, 1998
Jo˜ ao Paulo de Almeida, Jonathan Raper, Gilberto Camara, and Thomas Cova. A formal approach to imprecise and incomplete geographical objects.Computers, Envi- ronment and Urban Systems, 22(5):395–408, 1998
1998
-
[11]
An 22 ecoregion-based approach to protecting half the terrestrial realm.BioScience, 67(6): 534–545, 2017
Eric Dinerstein, David Olson, Anup Joshi, Carly Vynne, Neil D Burgess, Eric Wikra- manayake, Nathan Hahn, Suzanne Palminteri, Prashant Hedao, Reed Noss, et al. An 22 ecoregion-based approach to protecting half the terrestrial realm.BioScience, 67(6): 534–545, 2017
2017
-
[12]
Geovex: Geospatial vectors with hexagonal con- volutional autoencoders
Daniele Donghi and Anne Morvan. Geovex: Geospatial vectors with hexagonal con- volutional autoencoders. InProceedings of the 6th ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery, pages 3–13, 2023
2023
-
[13]
A global dataset of air temperature derived from satellite remote sensing and weather stations.Scientific Data, 5(1):180246, 2018
Jake Hooker, Gregory Duveiller, and Alessandro Cescatti. A global dataset of air temperature derived from satellite remote sensing and weather stations.Scientific Data, 5(1):180246, 2018
2018
-
[14]
Residual correlation in graph neural network regression
Junteng Jia and Austin R Benson. Residual correlation in graph neural network regression. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 588–598, 2020
2020
-
[15]
Satclip: Global, general-purpose location embeddings with satellite im- agery
Konstantin Klemmer, Esther Rolf, Caleb Robinson, Lester Mackey, and Marc Rußwurm. Satclip: Global, general-purpose location embeddings with satellite im- agery. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 4347–4355, 2025
2025
-
[16]
Mesogeos: A multi-purpose dataset for data-driven wildfire modeling in the mediter- ranean
Spyros Kondylatos, Ioannis Prapas, Gustau Camps-Valls, and Ioannis Papoutsis. Mesogeos: A multi-purpose dataset for data-driven wildfire modeling in the mediter- ranean. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URLhttps://openreview.net/forum?id= VH1vxapUTs
2023
-
[17]
Highway2vec: Representing OpenStreetMap microregions with respect to their road network characteristics
Kacper Le´ sniara and Piotr Szyma´ nski. Highway2vec: Representing OpenStreetMap microregions with respect to their road network characteristics. InProceedings of the 5th ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery, pages 18–29, 2022
2022
-
[18]
Enriching location representation with detailed semantic information
Junyuan Liu, Xinglei Wang, Tao Cheng, and Stephen Law. Enriching location representation with detailed semantic information. In12th International Confer- ence on Geographic Information Science (GIScience 2025), volume 352 ofLeib- niz International Proceedings in Informatics (LIPIcs), pages 3:1–3:7, 2025. doi: 10.4230/LIPIcs.GIScience.2025.3
-
[19]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[20]
Presence-only geographical priors for fine-grained image classification
Oisin Mac Aodha, Elijah Cole, and Pietro Perona. Presence-only geographical priors for fine-grained image classification. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9596–9606, 2019
2019
-
[21]
Multi- scale representation learning for spatial feature distributions using grid cells
Gengchen Mai, Krzysztof Janowicz, Bo Yan, Rui Zhu, Ling Cai, and Ni Lao. Multi- scale representation learning for spatial feature distributions using grid cells. InIn- ternational Conference on Learning Representations, 2020. 23
2020
-
[22]
Gengchen Mai, Yao Xuan, Ni Lao, Jinmeng He, Chris Cundy, Weiming Zhao, Song Gao, and Stefano Ermon. Sphere2vec: A general-purpose location representation learning over a spherical surface for large-scale geospatial predictions.ISPRS Journal of Photogrammetry and Remote Sensing, 202:439–462, 2023
2023
-
[23]
OpenStreetMap: The free wiki world map
OpenStreetMap Contributors. OpenStreetMap: The free wiki world map. https://www.openstreetmap.org, 2004
2004
-
[24]
Semiparametric maximum likelihood estimates of spatial dependence.Geographical Analysis, 35(1):76–90, 2003
R Kelley Pace and Ronald P Barry. Semiparametric maximum likelihood estimates of spatial dependence.Geographical Analysis, 35(1):76–90, 2003
2003
-
[25]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Woon Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763. PMLR, 2021
2021
-
[26]
Sentence-BERT: Sentence embeddings using Siamese BERT-Networks.arXiv preprint arXiv:1908.10084, 2019
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT-Networks.arXiv preprint arXiv:1908.10084, 2019
Pith/arXiv arXiv 1908
-
[27]
A generalizable and accessible approach to machine learning with global satellite imagery.Nature Communications, 12(1):4392, 2021
Esther Rolf, Jonathan Proctor, Tamma Carleton, Ian Bolliger, Vaishaal Shankar, Miyabi Ishihara, Benjamin Recht, and Solomon Hsiang. A generalizable and accessible approach to machine learning with global satellite imagery.Nature Communications, 12(1):4392, 2021
2021
-
[28]
Geographic location encoding with spherical harmonics and sinusoidal representation networks
Marc Rußwurm, Konstantin Klemmer, Esther Rolf, Robin Zbinden, and Devis Tuia. Geographic location encoding with spherical harmonics and sinusoidal representation networks. InInternational Conference on Learning Representations, 2024
2024
-
[29]
Gt-loc: Unifying when and where in images through a joint embedding space
David G Shatwell, Ishan Rajendrakumar Dave, Sirnam Swetha, and Mubarak Shah. Gt-loc: Unifying when and where in images through a joint embedding space. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1–11, 2025
2025
-
[30]
Implicit neural representations with periodic activation functions
Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions. InAd- vances in Neural Information Processing Systems, volume 33, pages 7462–7473, 2020
2020
-
[31]
Satbird: a dataset for bird species distribu- tion modeling using remote sensing and citizen science data
M´ elisande Teng, Amna Elmustafa, Benjamin Akera, Yoshua Bengio, Hager Radi, Hugo Larochelle, and David Rolnick. Satbird: a dataset for bird species distribu- tion modeling using remote sensing and citizen science data. In A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Infor- mation Processing Systems, volu...
-
[32]
URLhttps://proceedings.neurips.cc/paper_files/paper/2023/file/ ef7653bbc4655305efb89a32362e332a-Paper-Datasets_and_Benchmarks.pdf. 24
2023
-
[33]
The iNaturalist species classifi- cation and detection dataset
Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and Serge Belongie. The iNaturalist species classifi- cation and detection dataset. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8769–8778, 2018
2018
-
[34]
Graph attention networks
Petar Veliˇ ckovi´ c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Li` o, and Yoshua Bengio. Graph attention networks. InInternational Conference on Learn- ing Representations, 2018
2018
-
[35]
Order matters: Sequence to sequence for sets
Oriol Vinyals, Samy Bengio, and Manjunath Kudlur. Order matters: Sequence to sequence for sets. InInternational Conference on Learning Representations, 2016
2016
-
[36]
Geoclip: Clip-inspired alignment between locations and images for effective worldwide geo- localization.Advances in Neural Information Processing Systems, 36:8690–8701, 2023
Vicente Vivanco Cepeda, Gaurav Kumar Nayak, and Mubarak Shah. Geoclip: Clip-inspired alignment between locations and images for effective worldwide geo- localization.Advances in Neural Information Processing Systems, 36:8690–8701, 2023
2023
-
[37]
Satellite maneuver detection and estimation with radar survey observations,
Xinglei Wang, Tao Cheng, Stephen Law, Zichao Zeng, Lu Yin, and Junyuan Liu. Multi-modal contrastive learning of urban space representations from POI data. Computers, Environment and Urban Systems, 118:102299, 2025. doi: 10.1016/j. compenvurbsys.2025.102299
work page doi:10.1016/j 2025
-
[38]
Yi Wang, Zhitong Xiong, Chenying Liu, Adam J. Stewart, Thomas Dujardin, Niko- laos Ioannis Bountos, Angelos Zavras, Franziska Gerken, Ioannis Papoutsis, Laura Leal-Taix´ e, and Xiao Xiang Zhu. Towards a unified copernicus foundation model for earth vision, 2025. URLhttps://arxiv.org/abs/2503.11849
arXiv 2025
-
[39]
MoRA: Mobility as the backbone for geospatial representation learning at scale
Ya Wen, Jixuan Cai, Qiyao Ma, Linyan Li, Xinhua Chen, Chris Webster, and Yulun Zhou. MoRA: Mobility as the backbone for geospatial representation learning at scale. arXiv preprint arXiv:2506.01297, 2025
arXiv 2025
-
[40]
Hex2vec: Context-aware embedding H3 hexagons with OpenStreetMap tags
Szymon Wo´ zniak and Piotr Szyma´ nski. Hex2vec: Context-aware embedding H3 hexagons with OpenStreetMap tags. InProceedings of the 4th ACM SIGSPATIAL In- ternational Workshop on AI for Geographic Knowledge Discovery, pages 61–71, 2021
2021
-
[41]
Urbanclip: Learning text-enhanced urban region profiling with contrastive language-image pretraining from the web
Yibo Yan, Haomin Wen, Siru Zhong, Wei Chen, Haodong Chen, Qingsong Wen, Roger Zimmermann, and Yuxuan Liang. Urbanclip: Learning text-enhanced urban region profiling with contrastive language-image pretraining from the web. InProceedings of the ACM Web Conference 2024, WWW ’24, page 4006–4017, New York, NY, USA,
2024
-
[42]
Proceedings of the ACM Web Conference 2024 , series =
Association for Computing Machinery. ISBN 9798400701719. doi: 10.1145/ 3589334.3645378. URLhttps://doi.org/10.1145/3589334.3645378. 25 A Appendix A.1 Evaluation Protocol Details A.1.1 Dataset Overview Unless otherwise specified, we use official benchmark splits and preprocessing protocols. For California Housing we use the standardscikit-learnimplementati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.