Pre-Intervention Prediction of Sparse Autoencoder Steering Side Effects
Pith reviewed 2026-06-27 19:50 UTC · model grok-4.3
The pith
Pre-steering feature statistics predict which SAE interventions steer language models more cleanly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
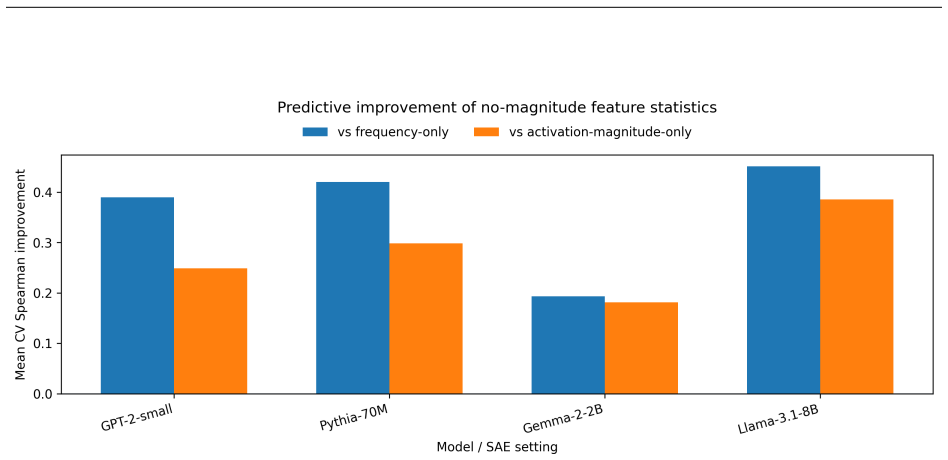
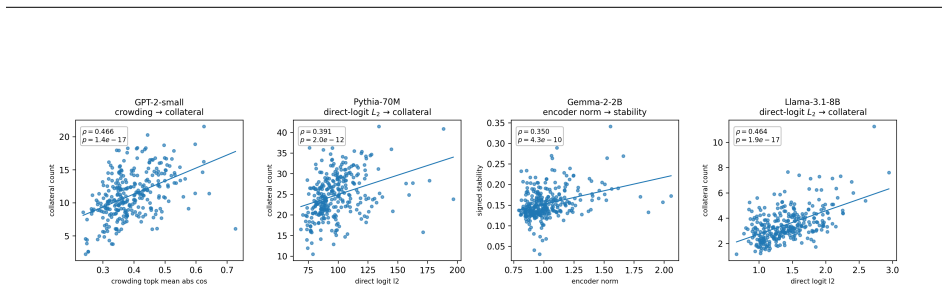
SAE steering side effects are predictable in advance from pre-intervention feature statistics including decoder geometry, activation statistics, co-activation structure, and direct-logit footprint; these predictors outperform frequency-only and activation-magnitude baselines across GPT-2-small, Pythia-70M-deduped, Gemma-2-2B, and Llama-3.1-8B with ReLU, JumpReLU, and TopK dictionaries, and ranking by predicted cleanliness selects features that steer more cleanly on fresh contexts, though the successful axis varies by model and dictionary while the signal survives residualization against magnitude confounds in most but not all cases and persists under a 32K-to-128K dictionary-width change.
What carries the argument
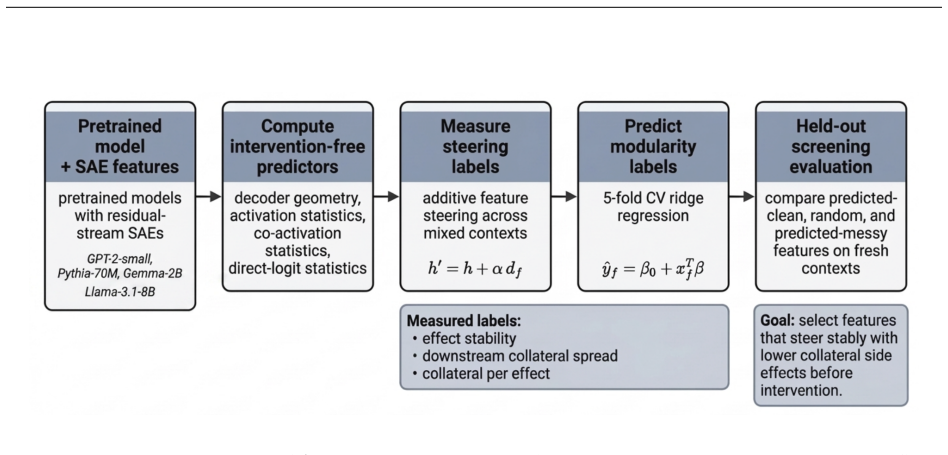
The pre-intervention screening framework that ranks features by predicted cleanliness using decoder geometry, activation statistics, co-activation structure, and direct-logit footprint computed before steering.
If this is right
- Ranking unseen features by predicted cleanliness selects interventions that perform better on held-out contexts.
- The predictive signal survives residualization against magnitude-related confounds in GPT-2-small, Pythia-70M, and Llama-3.1-8B.
- The signal persists when dictionary width changes from 32K to 128K, though the screening payoff becomes less stable.
- The useful predictor signature and the modularity axis that transfers successfully are model- and dictionary-setting dependent.
Where Pith is reading between the lines
- Practitioners could pre-filter large SAE dictionaries to reduce the number of steering experiments that fail due to inconsistency or unintended effects.
- The model-dependent nature of the best predictors suggests that feature modularity may itself vary systematically with architecture or training details.
- Extending the same pre-steering statistics to other intervention methods, such as activation patching, could test whether the same geometry and co-activation signals apply beyond SAE steering.
Load-bearing premise
The two operationalized axes of effect stability and collateral spread capture the relevant side effects of steering, and the predictive relationships will hold for intended use cases without post-steering information.
What would settle it
In a new model or dictionary, features ranked highest by the pre-intervention predictors show no improvement in measured stability or reduced collateral spread compared with random selection on fresh contexts.
Figures

read the original abstract
Sparse autoencoder (SAE) features are increasingly used to steer language models, but feature steering is rarely clean: the same intervention can behave inconsistently across contexts and perturb unrelated features. We introduce a pre-intervention screening framework for forecasting SAE steering side effects from feature statistics computed before steering. We operationalize side effects along two axes of steering modularity, effect stability and collateral spread, and evaluate GPT-2-small, Pythia-70M-deduped, Gemma-2-2B, and Llama-3.1-8B across ReLU, JumpReLU, and TopK SAE dictionaries. Across these settings, decoder geometry, activation statistics, co-activation structure, and direct-logit footprint predict steering modularity better than frequency-only and activation-magnitude baselines. The signal is strongest in GPT-2-small, Pythia-70M, and Llama-3.1-8B, where it survives residualization against magnitude-related confounds, and weaker in Gemma-2-2B. Held-out screening shows that ranking unseen features by predicted cleanliness can select features that steer more cleanly on fresh contexts, but the successful axis varies by setting: GPT-2 improves most cleanly, Pythia improves mainly on stability, Llama mainly on collateral, and Gemma only partially. A controlled Llama Scope width comparison shows that the predictive signal persists under a 32K-to-128K dictionary-width change, although the screening payoff becomes less stable. Overall, SAE steering side effects are predictable in advance, but the useful predictor signature and transferred modularity axis are model- and dictionary-setting dependent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that pre-intervention statistics of SAE features (decoder geometry, activation statistics, co-activation structure, direct-logit footprint) predict two axes of steering modularity—effect stability and collateral spread—better than frequency/magnitude baselines across GPT-2-small, Pythia-70M-deduped, Gemma-2-2B, and Llama-3.1-8B with ReLU/JumpReLU/TopK dictionaries. It further reports that ranking unseen features by these predictions yields cleaner steering on fresh contexts (with the effective axis varying by model/dictionary) and that the signal persists under a controlled 32K-to-128K dictionary-width change on Llama.
Significance. If the empirical results hold, the work supplies a practical pre-screening method for selecting SAE features likely to produce more modular steering, reducing the need for post-hoc side-effect measurement. Strengths include the multi-model/multi-dictionary evaluation, explicit residualization controls against magnitude confounds, and held-out screening that uses only pre-steering statistics for ranking. The paper appropriately flags model- and dictionary-dependence rather than claiming universal transfer.
major comments (2)
- [residualization results] The residualization analysis (reported to survive in GPT-2-small, Pythia-70M, and Llama-3.1-8B) is load-bearing for the claim that predictors are not reducible to magnitude confounds; the manuscript should specify the exact procedure (which variables are partialled out) and report post-residualization R² or correlation values for each predictor axis.
- [held-out screening experiments] The held-out screening result—that ranking by predicted cleanliness improves modularity on fresh contexts—is central to the practical claim; the training procedure for the predictor (features used, cross-validation split, whether any context-level statistics leak) must be described with sufficient detail to confirm it remains strictly pre-intervention.
minor comments (2)
- [abstract] The abstract states that 'the successful axis varies by setting' but does not list which axis succeeds for each model; adding one sentence would improve readability without lengthening the abstract.
- [Llama width comparison] Table or figure captions for the width-comparison experiment should explicitly note the dictionary sizes compared (32K vs 128K) and the stability of the screening payoff.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive assessment of the work. We address each major comment below and will revise the manuscript accordingly to improve methodological clarity.
read point-by-point responses
-
Referee: [residualization results] The residualization analysis (reported to survive in GPT-2-small, Pythia-70M, and Llama-3.1-8B) is load-bearing for the claim that predictors are not reducible to magnitude confounds; the manuscript should specify the exact procedure (which variables are partialled out) and report post-residualization R² or correlation values for each predictor axis.
Authors: We agree that greater specificity is required. In the revised manuscript we will detail the residualization procedure, including the exact variables partialled out (feature frequency, mean activation magnitude, and decoder vector norm), and report the post-residualization R² and correlation coefficients for each predictor axis in GPT-2-small, Pythia-70M-deduped, and Llama-3.1-8B. revision: yes
-
Referee: [held-out screening experiments] The held-out screening result—that ranking by predicted cleanliness improves modularity on fresh contexts—is central to the practical claim; the training procedure for the predictor (features used, cross-validation split, whether any context-level statistics leak) must be described with sufficient detail to confirm it remains strictly pre-intervention.
Authors: We will expand the methods section with a precise description of the predictor training procedure. This will include the input feature set, the cross-validation scheme, and explicit confirmation that only pre-intervention statistics are used, with no leakage of context-level or post-steering information, thereby verifying that the held-out screening remains strictly pre-intervention. revision: yes
Circularity Check
No significant circularity
full rationale
The paper frames its contribution as an empirical prediction task: pre-intervention feature statistics (decoder geometry, activation statistics, co-activation, direct-logit footprint) are computed independently and then tested for correlation with post-steering modularity axes (effect stability, collateral spread) on held-out features and contexts. The reported results rely on cross-model experiments, residualization controls, and screening that explicitly uses only pre-steering data for ranking. No equations, definitions, or load-bearing steps reduce any claimed prediction to the target metrics by construction, nor does any central premise rest on a self-citation chain. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Do Activation Monitors Survive Model Updates? Benchmarking, Predicting, and Repairing Activation-Monitor Staleness
Fine-tuning updates frequently stale activation monitors for language model safety while quantization does not, with degradation predictable and repairable via label-free realignment.
Reference graph
Works this paper leans on
-
[1]
Saes are good for steering–if you select the right features
Dana Arad, Aaron Mueller, and Yonatan Belinkov. Saes are good for steering–if you select the right features. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 10252– 12 10270,
2025
-
[2]
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey
https://transformer-circuits.pub/2023/monosemantic-features/index.html. Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
Pith/arXiv arXiv 2023
-
[3]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
Pith/arXiv arXiv 2021
-
[4]
Decomposing the dark matter of sparse autoencoders.arXiv preprint arXiv:2410.14670,
Joshua Engels, Logan Riggs, and Max Tegmark. Decomposing the dark matter of sparse autoencoders.arXiv preprint arXiv:2410.14670,
-
[5]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupre la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. InInternational Conference on Learning Representations, volume 2025, pp. 26721–26754,
2025
-
[7]
URLhttps://arxiv.org/abs/ 2403.08295. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783,
-
[8]
URLhttps://arxiv.org/abs/2407.21783. Zhengfu He, Wentao Shu, Xuyang Ge, Lingjie Chen, Junxuan Wang, Yunhua Zhou, Frances Liu, Qipeng Guo, Xuanjing Huang, Zuxuan Wu, et al. Llama scope: Extracting millions of features from llama-3.1-8b with sparse autoencoders.arXiv preprint arXiv:2410.20526,
-
[9]
Steering language model refusal with sparse autoencoders.arXiv preprint arXiv:2411.11296,
13 Kyle O’Brien, David Majercak, Xavier Fernandes, Richard Edgar, Blake Bullwinkel, Jingya Chen, Harsha Nori, Dean Carignan, Eric Horvitz, and Forough Poursabzi-Sangdeh. Steering language model refusal with sparse autoencoders.arXiv preprint arXiv:2411.11296,
-
[10]
Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681,
Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681,
-
[11]
URLhttps://cdn.openai.com/ better-language-models/language_models_are_unsupervised_multitask_learners.pdf. Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, János Kramár, and Neel Nanda. Jumping ahead: Improving reconstruction fidelity with jumprelu sparse au- toencoders.arXiv preprint arXiv:2407.14435,
-
[12]
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J
URLhttps: //transformer-circuits.pub/2024/scaling-monosemanticity/index.html. Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248,
Pith/arXiv arXiv 2024
-
[13]
Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to a...
-
[14]
Llama- 3.1-8B details are reported separately in Appendix F
14 A Experimental details This appendix reports the full experimental configuration for the original three non-Llama settings. Llama- 3.1-8B details are reported separately in Appendix F. Table A1 lists the model checkpoints, SAE releases, and primary/downstream hook sites. Table A2 reports the predictive-evaluation configuration, including corpus, contex...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.