Do Activation Monitors Survive Model Updates? Benchmarking, Predicting, and Repairing Activation-Monitor Staleness
Pith reviewed 2026-06-27 03:20 UTC · model grok-4.3
The pith
Fine-tuning updates make activation monitors stale while quantization updates preserve them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
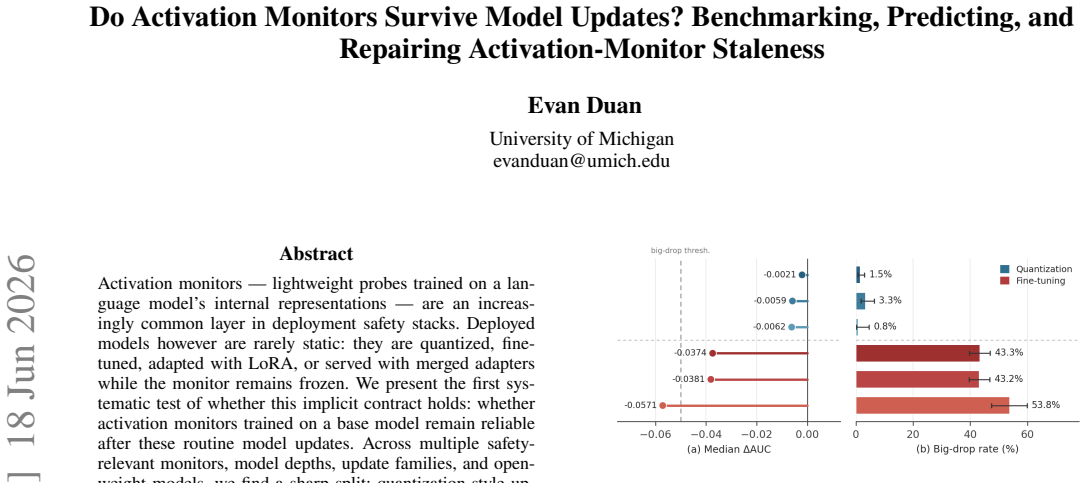
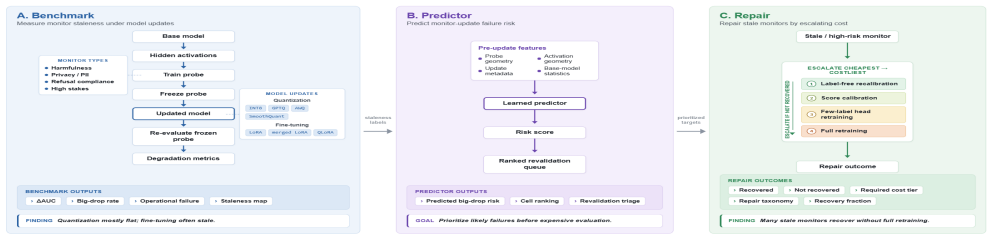
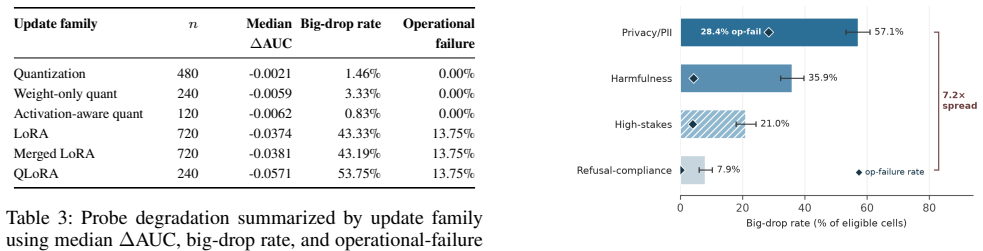
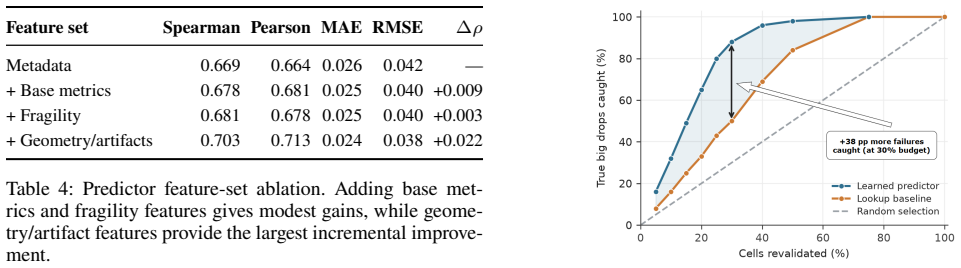
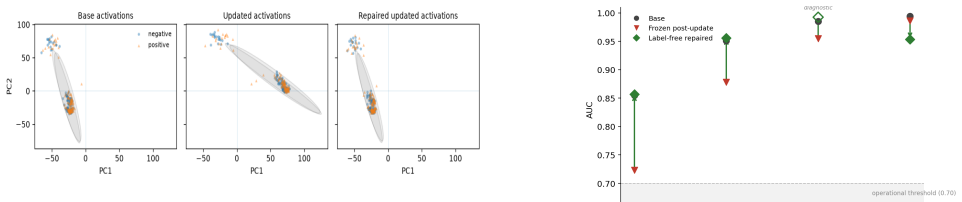
Across multiple safety-relevant monitors, model depths, update families, and open-weight models, quantization-style updates largely preserve frozen probe performance, while fine-tuning-style updates frequently make probes stale. Fragility is highly monitor-dependent, with privacy/PII probes most affected and refusal-compliance probes comparatively stable. QLoRA is especially damaging despite NF4 quantization alone being relatively benign. Degradation is predictable from pre-deployment features, and cheap label-free activation realignment repairs every repair-relevant stale cell without requiring score calibration, few-label heads, or labeled retraining.
What carries the argument
Systematic comparison of frozen activation-monitor performance before and after distinct update families (quantization versus fine-tuning), with prediction from pre-update features and label-free activation realignment as the repair mechanism.
If this is right
- Fine-tuning should trigger activation-monitor revalidation by default.
- Pre-deployment features allow triage of revalidation effort toward the monitors most likely to fail.
- Label-free activation realignment can serve as the default repair for stale monitors.
- Privacy and PII monitors warrant closer post-update scrutiny than refusal-compliance monitors.
Where Pith is reading between the lines
- Production update pipelines could embed automatic staleness checks that fire specifically on fine-tuning steps.
- The monitor-dependent fragility pattern indicates that some safety-relevant behaviors rest on more stable internal representations than others under adaptation.
- The same prediction and repair approach could be tested on continued pre-training or other update styles not covered here.
Load-bearing premise
The observed performance shifts are caused by the update categories themselves rather than other details of the experimental setup, and the tested monitors and models stand in for those used in real deployed systems.
What would settle it
A fine-tuning update that leaves every tested monitor's performance unchanged on the same models and evaluation sets, or a pure quantization update that produces clear staleness.
Figures

read the original abstract
Activation monitors -- lightweight probes trained on a language model's internal representations -- are an increasingly common layer in deployment safety stacks. Deployed models however are rarely static: they are quantized, fine-tuned, adapted with LoRA, or served with merged adapters while the monitor remains frozen. We present the first systematic test of whether this implicit contract holds: whether activation monitors trained on a base model remain reliable after these routine model updates. Across multiple safety-relevant monitors, model depths, update families, and open-weight models, we find a sharp split: quantization-style updates largely preserve frozen probe performance, while fine-tuning-style updates frequently make probes stale. Fragility is highly monitor-dependent, with privacy/PII probes most affected and refusal-compliance probes comparatively stable, showing that retraining a behavior need not stale its corresponding monitor. QLoRA is especially damaging despite NF4 quantization alone being relatively benign, suggesting that quantization becomes riskier when combined with adaptation. We further show that degradation is predictable from pre-deployment features, enabling revalidation budgets to be triaged toward the monitors most likely to fail. Finally, we test repair strategies and find that cheap label-free activation realignment repairs every repair-relevant stale cell, with none requiring score calibration, few-label heads, or labeled retraining. These results suggest that fine-tuning should trigger activation-monitor revalidation by default, with prediction triaging which monitors to check first and label-free realignment as the default repair.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically benchmarks whether frozen activation monitors (lightweight probes on LLM internal activations for safety tasks) remain reliable after common model updates. Across multiple monitors, model depths, update families (quantization, fine-tuning, LoRA, merging), and open-weight models, it reports a sharp split: quantization-style updates largely preserve probe performance while fine-tuning-style updates frequently induce staleness. Fragility varies by monitor (PII/privacy probes most affected; refusal probes more stable), degradation is predictable from pre-update features, and label-free activation realignment repairs all tested stale cases without needing calibration or retraining.
Significance. If the results hold under proper controls, the work provides practical guidance for safety deployment: fine-tuning should trigger default revalidation, with prediction enabling triage and label-free realignment as a low-cost fix. This addresses a real gap in non-static model safety stacks and demonstrates monitor-dependent behavior plus repair feasibility. The multi-model, multi-monitor design is a strength for generalizability claims.
major comments (2)
- [Experimental Setup] Experimental Setup / Benchmarking sections: The central claim of a sharp split attributable to update category (quantization-style vs. fine-tuning-style) is load-bearing for the paper's conclusions. The manuscript must demonstrate that activation-shift magnitude, parameter delta size, or data-distribution mismatch were matched or statistically controlled across families; without this, the category label may proxy for degree of change rather than type, as the skeptic note highlights.
- [Repair Experiments] Repair Experiments section: The claim that label-free realignment repairs 'every repair-relevant stale cell' with none requiring score calibration or labeled retraining is strong and central to the practical takeaway. The paper should report the exact number of stale cells tested, the criteria for 'repair-relevant,' and any edge cases or conditions where realignment failed or required additional steps.
minor comments (2)
- [Abstract] Abstract and introduction: Clarify the precise definition of 'quantization-style' vs. 'fine-tuning-style' updates early, including whether QLoRA is treated as a hybrid and how merged adapters are categorized.
- [Prediction] Prediction section: The claim that degradation is 'predictable from pre-deployment features' would benefit from reporting the specific features used and the cross-validation procedure to allow replication.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of our experimental design and reporting. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core findings.
read point-by-point responses
-
Referee: [Experimental Setup] Experimental Setup / Benchmarking sections: The central claim of a sharp split attributable to update category (quantization-style vs. fine-tuning-style) is load-bearing for the paper's conclusions. The manuscript must demonstrate that activation-shift magnitude, parameter delta size, or data-distribution mismatch were matched or statistically controlled across families; without this, the category label may proxy for degree of change rather than type, as the skeptic note highlights.
Authors: We agree that isolating the effect of update category from magnitude of change requires explicit controls. In the revised manuscript we will add a dedicated analysis subsection that matches or statistically controls for activation-shift magnitude (via cosine distance on activations) and parameter delta size (via L2 norm of weight changes) across the quantization-style and fine-tuning-style families. We will also report data-distribution mismatch statistics where available. This will allow readers to assess whether the observed split persists after accounting for degree of change. revision: yes
-
Referee: [Repair Experiments] Repair Experiments section: The claim that label-free realignment repairs 'every repair-relevant stale cell' with none requiring score calibration or labeled retraining is strong and central to the practical takeaway. The paper should report the exact number of stale cells tested, the criteria for 'repair-relevant,' and any edge cases or conditions where realignment failed or required additional steps.
Authors: We will expand the Repair Experiments section to state the exact number of stale cells evaluated, the operational definition of 'repair-relevant' (performance drop exceeding a pre-specified threshold with statistical significance), and confirmation that label-free realignment succeeded in every case without score calibration or labeled retraining. We will also explicitly note that no edge cases requiring additional steps were observed across the tested monitors and models. revision: yes
Circularity Check
No significant circularity; purely empirical benchmarking
full rationale
The paper is an empirical benchmarking study of activation-monitor performance under model updates (quantization vs. fine-tuning families). No mathematical derivation chain, first-principles results, or 'predictions' that reduce to inputs by construction are present. The claim that degradation is 'predictable from pre-deployment features' refers to training a standard statistical model on observed experimental data to triage monitors, which is not self-definitional or fitted-input-called-prediction. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the abstract or described methods. The central split between update families rests on direct experimental measurements rather than any reduction to prior fitted quantities or self-citations. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activation monitors are trained on base model representations and remain frozen during updates.
Reference graph
Works this paper leans on
-
[1]
2016 , eprint=
Understanding Intermediate Layers Using Linear Classifier Probes , author=. 2016 , eprint=
2016
-
[2]
Probing Classifiers: Promises, Shortcomings, and Advances
Probing Classifiers: Promises, Shortcomings, and Advances , author=. Computational Linguistics , volume=. 2022 , publisher=. doi:10.1162/coli_a_00422 , url=
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[3]
International Conference on Learning Representations , year=
Discovering Latent Knowledge in Language Models Without Supervision , author=. International Conference on Learning Representations , year=
-
[4]
Azaria, Amos and Mitchell, Tom , booktitle=. The Internal State of an. 2023 , publisher=. doi:10.18653/v1/2023.findings-emnlp.68 , url=
-
[7]
2023 , eprint=
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. 2023 , eprint=
2023
-
[8]
Proceedings of the 42nd International Conference on Machine Learning , series=
Detecting Strategic Deception with Linear Probes , author=. Proceedings of the 42nd International Conference on Machine Learning , series=. 2025 , publisher=
2025
-
[9]
Advances in Neural Information Processing Systems , year=
Refusal in Language Models Is Mediated by a Single Direction , author=. Advances in Neural Information Processing Systems , year=
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
A Holistic Approach to Undesired Content Detection in the Real World , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2023 , doi=
2023
-
[12]
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of
Han, Seungju and Rao, Kavel and Ettinger, Allyson and Jiang, Liwei and Lin, Bill Yuchen and Lambert, Nathan and Choi, Yejin and Dziri, Nouha , booktitle=. WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of. 2024 , url=
2024
-
[14]
2025 , eprint=
Constitutional Classifiers: Defending Against Universal Jailbreaks Across Thousands of Hours of Red Teaming , author=. 2025 , eprint=
2025
-
[15]
arXiv preprint arXiv:2601.04603 , year=
Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks , author=. arXiv preprint arXiv:2601.04603 , year=
-
[16]
2025 , eprint=
Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation , author=. 2025 , eprint=
2025
-
[17]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=. 2022 , url=
2022
-
[18]
2022 , url=
Dettmers, Tim and Lewis, Mike and Belkada, Younes and Zettlemoyer, Luke , booktitle=. 2022 , url=
2022
-
[19]
2023 , url=
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , booktitle=. 2023 , url=
2023
-
[20]
Proceedings of the 40th International Conference on Machine Learning , series=
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models , author=. Proceedings of the 40th International Conference on Machine Learning , series=. 2023 , publisher=
2023
-
[21]
2023 , eprint=
Shadow Alignment: The Ease of Subverting Safely-Aligned Language Models , author=. 2023 , eprint=
2023
-
[22]
International Conference on Learning Representations , year=
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To! , author=. International Conference on Learning Representations , year=
-
[23]
International Conference on Learning Representations , year=
Safety Alignment Should Be Made More Than Just a Few Tokens Deep , author=. International Conference on Learning Representations , year=
-
[24]
and Jaiswal, Ajay Kumar and Xu, Kaidi and Kailkhura, Bhavya and Hendrycks, Dan and Song, Dawn and Wang, Zhangyang and Li, Bo , booktitle=
Hong, Junyuan and Duan, Jinhao and Zhang, Chenhui and Li, Zhangheng and Xie, Chulin and Lieberman, Kelsey and Diffenderfer, James and Bartoldson, Brian R. and Jaiswal, Ajay Kumar and Xu, Kaidi and Kailkhura, Bhavya and Hendrycks, Dan and Song, Dawn and Wang, Zhangyang and Li, Bo , booktitle=. Decoding Compressed Trust: Scrutinizing the Trustworthiness of ...
2024
-
[25]
Exploiting
Egashira, Kazuki and Vero, Mark and Staab, Robin and He, Jingxuan and Vechev, Martin , booktitle=. Exploiting. 2024 , url=
2024
-
[26]
International Conference on Learning Representations , year=
Mechanistically Analyzing the Effects of Fine-Tuning on Procedurally Defined Tasks , author=. International Conference on Learning Representations , year=
-
[27]
and Mihalcea, Rada , booktitle=
Lee, Andrew and Bai, Xiaoyan and Pres, Itamar and Wattenberg, Martin and Kummerfeld, Jonathan K. and Mihalcea, Rada , booktitle=. A Mechanistic Understanding of Alignment Algorithms: A Case Study on. 2024 , publisher=
2024
-
[28]
International Conference on Learning Representations , year=
Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity Tracking , author=. International Conference on Learning Representations , year=
-
[29]
and Wang, Yizhong and Kasai, Jungo and Hajishirzi, Hannaneh and Smith, Noah A
Liu, Leo Z. and Wang, Yizhong and Kasai, Jungo and Hajishirzi, Hannaneh and Smith, Noah A. , booktitle=. Probing Across Time: What Does. 2021 , publisher=. doi:10.18653/v1/2021.findings-emnlp.71 , url=
-
[30]
Sellam, Thibault and Yadlowsky, Steve and Wei, Jason and Saphra, Naomi and D'Amour, Alexander and Linzen, Tal and Bastings, Jasmijn and Turc, Iulia and Eisenstein, Jacob and Das, Dipanjan and Tenney, Ian and Pavlick, Ellie , year=. The. 2106.16163 , archivePrefix=
-
[31]
International Conference on Learning Representations , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. International Conference on Learning Representations , year=
-
[32]
2024 , eprint=
Interpreting Attention Layer Outputs with Sparse Autoencoders , author=. 2024 , eprint=
2024
-
[33]
Kissane, Connor and Krzyzanowski, Robert and Conmy, Arthur and Nanda, Neel , year=
-
[34]
International Conference on Learning Representations , year=
Leveraging Unlabeled Data to Predict Out-of-Distribution Performance , author=. International Conference on Learning Representations , year=
-
[35]
Advances in Neural Information Processing Systems , volume=
Agreement-on-the-Line: Predicting the Performance of Neural Networks under Distribution Shift , author=. Advances in Neural Information Processing Systems , volume=. 2022 , url=
2022
-
[36]
Ravindran, Santhosh Kumar , journal =. Adversarial. doi:10.48550/ARXIV.2507.09406 , year =
-
[37]
and Alam, Md Jahangir and Lee, Yoonpyo and Alam, Syed Bahauddin and Talukder, Sajedul , year =
Hossain, Ismail and Puppala, Saiteja and Ferdaus, J. and Alam, Md Jahangir and Lee, Yoonpyo and Alam, Syed Bahauddin and Talukder, Sajedul , year =. When
-
[38]
Shahani, Prithviraj Singh and Miandoab, Kaveh Eskandari and Scheutz, Matthias , journal =. Noise. doi:10.48550/ARXIV.2505.13500 , year =
-
[39]
Gu, Tianle and Huang, Kexin and Wang, Zongqi and Wang, Yixu and Li, Jie and Yao, Yuanqi and Yao, Yang and Yang, Yujiu and Teng, Yan and Wang, Yingchun , journal =. Probing the. doi:10.48550/ARXIV.2506.16078 , year =
-
[40]
Zheng, Chujie and Yin, Fan and Zhou, Hao and Meng, Fandong and Zhou, Jie and Chang, Kai-Wei and Huang, Minlie and Peng, Nanyun , journal =. On. doi:10.48550/ARXIV.2401.18018 , year =
-
[41]
and Poppi, Samuele and Lukas, Nils , year =
Aremu, Toluwani and Ognev, D. and Poppi, Samuele and Lukas, Nils , year =. Robust
-
[42]
Advances in Neural Information Processing Systems , volume=
Safe lora: The silver lining of reducing safety risks when finetuning large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
S afe S witch: Steering Unsafe LLM Behavior via Internal Activation Signals
Han, Peixuan and Qian, Cheng and Chen, Xiusi and Zhang, Yuji and Ji, Heng and Zhang, Denghui , booktitle =. SafeSwitch: Steering. doi:10.18653/v1/2025.findings-emnlp.366 , year =
-
[44]
Das, Amitava and Borah, Abhilekh and Jain, Vinija and Chadha, Aman , journal =. AlignGuard-. doi:10.48550/ARXIV.2508.02079 , year =
-
[45]
Yeo, Wei Jie and Prakash, Nirmalendu and Neo, Clement and Lee, Roy Ka-Wei and Cambria, Erik and Satapathy, Ranjan , journal =. Understanding. doi:10.48550/ARXIV.2505.23556 , year =
-
[46]
Agnihotri, Shashank and Jakubassa, Jonas and Dey, Priyam and Goyal, Sachin and Schiele, Bernt and Radhakrishnan, Venkatesh Babu and Keuper, Margret , journal =. A. doi:10.48550/ARXIV.2510.02768 , year =
-
[47]
McGuinness, Max and Serrano, Alex and Bailey, Luke and Emmons, Scott , journal =. Neural. doi:10.48550/ARXIV.2512.11949 , year =
-
[48]
RefusalGuard: Geometry-
Asif, Sadia and Amiri, Mohammad Mohammadi , year =. RefusalGuard: Geometry-
-
[49]
Watch the Weights: Unsupervised monitoring and control of fine-tuned LLMs
Zhong, Ziqian and Raghunathan, Aditi , journal =. Watch the. doi:10.48550/ARXIV.2508.00161 , year =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.00161
-
[50]
2025 , title =
Wu, Chengcan and Zhang, Zhixin and Wei, Zeming and Zhang, Yihao and Sun, Meng , journal =. 2025 , title =
2025
-
[51]
ASGuard: Activation-Scaling Guard to Mitigate Targeted Jailbreaking Attack
Park, Yein and Park, Jungwoo and Kang, Jaewoo , journal =. ASGuard: Activation-. doi:10.48550/ARXIV.2509.25843 , year =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.25843
-
[52]
Du, Yanrui and Fan, Fenglei and Zhao, Sendong and Cao, Jiawei and Lin, Qika and He, Kai and Liu, Ting and Qin, Bing and Feng, Mengling , journal =. Anchoring. doi:10.48550/ARXIV.2509.06795 , year =
-
[53]
Behrouzi, Sasha and Wu, Lichao and Rostami, Mohamadreza and Sadeghi, Ahmad-Reza , journal =. NeST: Neuron. doi:10.48550/ARXIV.2602.16835 , year =
-
[54]
Sanyal, Debdeep and Ray, Manodeep and Mandal, Murari , journal =. AntiDote: Bi-level. doi:10.48550/ARXIV.2509.08000 , year =
-
[55]
Li, Shen and Yao, Liuyi and Zhang, Lan and Li, Yaliang , journal =. Safety. doi:10.48550/ARXIV.2408.17003 , year =
-
[56]
Chang, Edward Y. and Chang, Ethan Y. , journal =. Inverse-. doi:10.48550/ARXIV.2510.08648 , year =
-
[57]
2025 , title =
Han, Bing and Zhao, Feifei and Zhao, Dongcheng and Shen, Guobin and Wu, Ping and Shi, Yu and Zeng, Yi , journal =. 2025 , title =
2025
-
[58]
Qi, Weiwei and Wu, Zefeng and Zheng, Tianhang and Zhang, Zikang and Jia, Xiaojun and Qin, Zhan and Ren, Kui , year =. Towards
-
[59]
2026 , eprint=
Perplexity Can Miss SAE Feature Damage Under Quantization , author=. 2026 , eprint=
2026
-
[60]
2026 , eprint=
Pre-Intervention Prediction of Sparse Autoencoder Steering Side Effects , author=. 2026 , eprint=
2026
-
[64]
PIIBench: A Unified Multi-Source Benchmark Corpus for PII Detection , author=
-
[65]
2023 , eprint=
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers , author=. 2023 , eprint=
2023
-
[66]
Proceedings of machine learning and systems , volume=
Awq: Activation-aware weight quantization for on-device llm compression and acceleration , author=. Proceedings of machine learning and systems , volume=
-
[69]
Computer Science Review , volume=
Locate, steer, and improve: A practical survey of actionable mechanistic interpretability in large language models , author=. Computer Science Review , volume=. 2026 , publisher=
2026
-
[70]
Alain, G.; and Bengio, Y. 2016. Understanding Intermediate Layers Using Linear Classifier Probes. arXiv:1610.01644
Pith/arXiv arXiv 2016
-
[71]
Arditi, A.; Obeso, O.; Syed, A.; Paleka, D.; Panickssery, N.; Gurnee, W.; and Nanda, N. 2024. Refusal in Language Models Is Mediated by a Single Direction. In Advances in Neural Information Processing Systems
2024
-
[72]
Azaria, A.; and Mitchell, T. 2023. The Internal State of an LLM Knows When It's Lying. In Findings of the Association for Computational Linguistics: EMNLP 2023, 967--976. Association for Computational Linguistics
2023
-
[73]
Baek, C.; Jiang, Y.; Raghunathan, A.; and Kolter, J. Z. 2022. Agreement-on-the-Line: Predicting the Performance of Neural Networks under Distribution Shift. In Advances in Neural Information Processing Systems, volume 35, 19274--19289
2022
-
[74]
Belinkov, Y. 2022. Probing Classifiers: Promises, Shortcomings, and Advances. Computational Linguistics, 48(1): 207--219
2022
-
[75]
Burns, C.; Ye, H.; Klein, D.; and Steinhardt, J. 2023. Discovering Latent Knowledge in Language Models Without Supervision. In International Conference on Learning Representations
2023
-
[76]
Cunningham, H.; Ewart, A.; Riggs, L.; Huben, R.; and Sharkey, L. 2024. Sparse Autoencoders Find Highly Interpretable Features in Language Models. In International Conference on Learning Representations
2024
-
[77]
Das, S.; and Fioretto, F. 2026. NeuroFilter: Privacy Guardrails for Conversational LLM Agents. arXiv preprint arXiv:2601.14660
arXiv 2026
-
[78]
Dettmers, T.; Lewis, M.; Belkada, Y.; and Zettlemoyer, L. 2022. LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale. In Advances in Neural Information Processing Systems, volume 35, 30318--30332
2022
-
[79]
Dettmers, T.; Pagnoni, A.; Holtzman, A.; and Zettlemoyer, L. 2023. QLoRA : Efficient Finetuning of Quantized LLM s. In Advances in Neural Information Processing Systems, volume 36
2023
-
[80]
Du, Y.; Fan, F.; Zhao, S.; Cao, J.; Lin, Q.; He, K.; Liu, T.; Qin, B.; and Feng, M. 2025. Anchoring Refusal Direction : Mitigating Safety Risks in Tuning via Projection Constraint . arXiv.org
2025
-
[81]
Duan, E. 2026 a . Perplexity Can Miss SAE Feature Damage Under Quantization. arXiv:2606.03002
Pith/arXiv arXiv 2026
-
[82]
Duan, E. 2026 b . Pre-Intervention Prediction of Sparse Autoencoder Steering Side Effects. arXiv:2606.08365
Pith/arXiv arXiv 2026
-
[83]
Egashira, K.; Vero, M.; Staab, R.; He, J.; and Vechev, M. 2024. Exploiting LLM Quantization. In Advances in Neural Information Processing Systems
2024
-
[84]
Frantar, E.; Ashkboos, S.; Hoefler, T.; and Alistarh, D. 2023. GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers. arXiv:2210.17323
Pith/arXiv arXiv 2023
-
[85]
C.; Neyshabur, B.; and Sedghi, H
Garg, S.; Balakrishnan, S.; Lipton, Z. C.; Neyshabur, B.; and Sedghi, H. 2022. Leveraging Unlabeled Data to Predict Out-of-Distribution Performance. In International Conference on Learning Representations
2022
-
[86]
Goldowsky-Dill, N.; Chughtai, B.; Heimersheim, S.; and Hobbhahn, M. 2025. Detecting Strategic Deception with Linear Probes. In Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research. PMLR
2025
-
[87]
Han, P.; Qian, C.; Chen, X.; Zhang, Y.; Ji, H.; and Zhang, D. 2025. SafeSwitch: Steering Unsafe LLM Behavior via Internal Activation Signals . In Findings of the Association for Computational Linguistics : EMNLP 2025 , 6936--6955. Association for Computational Linguistics
2025
-
[88]
Y.; Lambert, N.; Choi, Y.; and Dziri, N
Han, S.; Rao, K.; Ettinger, A.; Jiang, L.; Lin, B. Y.; Lambert, N.; Choi, Y.; and Dziri, N. 2024. WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLM s. In Advances in Neural Information Processing Systems
2024
-
[89]
R.; Jaiswal, A
Hong, J.; Duan, J.; Zhang, C.; Li, Z.; Xie, C.; Lieberman, K.; Diffenderfer, J.; Bartoldson, B. R.; Jaiswal, A. K.; Xu, K.; Kailkhura, B.; Hendrycks, D.; Song, D.; Wang, Z.; and Li, B. 2024. Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLM s Under Compression. In Proceedings of the 41st International Conference on Machine Learn...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.