Towards Long-Horizon Vessel Trajectory and Destination Forecasting with Reasoning Large Language Models
Pith reviewed 2026-06-27 18:44 UTC · model grok-4.3
The pith
RLVR post-training lets LLMs forecast 30-day vessel trajectories and destinations more accurately than baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
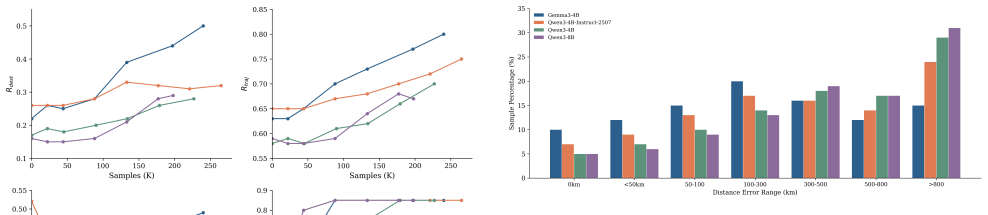
RLVR-trained LLMs substantially improve over zero-shot LLMs and representative deep learning baselines on a 60-day history to 30-day forecast AIS benchmark, especially on destination-related metrics, with 4B LLMs achieving the best overall performance through reward-compatible optimization and task-specific capacity matching.
What carries the argument
The Maritime LLM post-training framework based on Reinforcement Learning with Verifiable Reward (RLVR), which converts AIS trajectories into semantic text, enforces physical validity and destination correctness via hierarchical matching and curriculum learning.
If this is right
- RLVR alignment improves destination correctness over trajectory extrapolation alone.
- 4B parameter LLMs outperform larger 8B and 14B variants in this maritime task.
- LSTM models remain competitive deep learning baselines when fine-tuning data is limited.
- Transformer models need larger datasets for effective spatio-temporal forecasting.
Where Pith is reading between the lines
- Similar RLVR methods could apply to other domains requiring long-horizon physical trajectory prediction with semantic constraints.
- The textual representation of trajectories may allow LLMs to incorporate domain knowledge not easily encoded in coordinate-based models.
- Future work might test if the hierarchical matching reward generalizes to real-time operational data streams.
Load-bearing premise
Converting AIS trajectories into semantic textual representations enables LLMs to learn and enforce physical validity and destination correctness via the RLVR reward structure and hierarchical matching.
What would settle it
Demonstrating that RLVR-trained LLMs produce physically invalid routes or incorrect destinations on held-out 30-day forecasts at rates similar to zero-shot models would falsify the performance improvement claim.
Figures


read the original abstract
Long-horizon maritime trajectory prediction is important for shipping management, logistics planning, and maritime risk analysis, yet month-level forecasting remains insufficiently studied. Existing deep learning methods mainly focus on short- and mid-term coordinate extrapolation and often struggle to preserve route feasibility and destination correctness over extended horizons. This paper investigates joint long-horizon vessel trajectory and destination forecasting with reasoning-capable large language models, and develops a Maritime LLM post-training framework based on Reinforcement Learning with Verifiable Reward (RLVR). An AIS-based benchmark is constructed with 60-day historical trajectories and 30-day forecasting horizons, where trajectories are converted into semantic textual representations for RL prompt construction. RLVR aligns LLMs with maritime forecasting objectives by enforcing physical validity, providing early-weighted trajectory supervision, and evaluating destination correctness through hierarchical matching and curriculum learning. Experimental results show that RLVR-trained LLMs substantially improve over zero-shot LLMs and representative deep learning baselines, especially on destination-related metrics. Among the evaluated RLVR-trained variants, 4B LLMs achieve the best overall performance, suggesting that reward-compatible optimization and task-specific capacity matching are more important than simply using larger 8B or 14B LLMs. The results also show that LSTM remains a strong deep learning baseline under limited fine-tuning data, while Transformer-style spatio-temporal models typically require larger datasets and richer structured inputs. Overall, this work advances semantic, verifier-aligned maritime forecasting for operational decision support.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Maritime LLM post-training framework based on Reinforcement Learning with Verifiable Reward (RLVR) for joint long-horizon (30-day) vessel trajectory and destination forecasting from 60-day AIS histories. AIS trajectories are converted to semantic textual representations for prompting; RLVR enforces physical validity, applies early-weighted trajectory supervision, evaluates destination correctness via hierarchical matching, and uses curriculum learning. The central claim is that RLVR-trained LLMs substantially outperform zero-shot LLMs and representative deep learning baselines (especially on destination metrics), with 4B-parameter models achieving the best overall performance among evaluated variants.
Significance. If the empirical results hold after verification, the work would provide evidence that verifier-aligned RL can incorporate maritime domain constraints into LLM reasoning for long-horizon structured prediction, where traditional coordinate-extrapolation methods often fail on route feasibility. The AIS benchmark construction with extended horizons is a constructive step toward operational maritime forecasting.
major comments (2)
- [Abstract] Abstract: the claim of substantial improvements on destination metrics and a 4B-model advantage supplies no numerical results, error bars, dataset statistics, or ablation details, preventing evaluation of the data-to-claim link.
- [Methods (RLVR framework)] RLVR framework description: the physical-validity verifier (speed/turning bounds, route feasibility rules) and hierarchical destination matching are not concretely defined or exemplified; this is load-bearing for the claim that gains arise from the RLVR reward structure and LLM reasoning rather than from the richer textual input format alone.
minor comments (2)
- The manuscript should include explicit dataset statistics (number of trajectories, vessels, geographic coverage) and baseline hyperparameter settings to support reproducibility.
- Notation for the hierarchical matching and curriculum schedule could be clarified with a small example or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of substantial improvements on destination metrics and a 4B-model advantage supplies no numerical results, error bars, dataset statistics, or ablation details, preventing evaluation of the data-to-claim link.
Authors: We agree that the abstract would be strengthened by including key numerical results. In the revised manuscript we will add specific destination metric values, note error bars or variance where computed, include dataset statistics, and reference ablation outcomes to better support the claims. revision: yes
-
Referee: [Methods (RLVR framework)] RLVR framework description: the physical-validity verifier (speed/turning bounds, route feasibility rules) and hierarchical destination matching are not concretely defined or exemplified; this is load-bearing for the claim that gains arise from the RLVR reward structure and LLM reasoning rather than from the richer textual input format alone.
Authors: We acknowledge that the current Methods section lacks explicit definitions and examples. We will expand it to specify the exact speed and turning bounds, route feasibility rules, and provide concrete examples for the physical-validity verifier. We will also detail the hierarchical destination matching criteria with examples. These additions will clarify the contribution of the RLVR reward components. revision: yes
Circularity Check
No circularity; empirical results measured against external baselines with no self-defining reductions.
full rationale
The paper reports experimental outcomes from training LLMs via RLVR on a constructed AIS benchmark and comparing performance to zero-shot LLMs and DL baselines (LSTM, Transformer-style models). No equations, fitted parameters, or self-citations are presented that reduce the claimed improvements (especially on destination metrics) or the 4B model superiority to quantities defined by the method itself. The RLVR components (physical validity enforcement, hierarchical matching, curriculum) are described as alignment mechanisms whose effectiveness is evaluated externally rather than presupposed by construction. This matches the default case of a non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[2]
Deep learning models for vessel’s eta prediction: bulk ports perspective,
S. El Mekkaoui, L. Benabbou, and A. Berrado, “Deep learning models for vessel’s eta prediction: bulk ports perspective,”Flexible Services and Manufacturing Journal, vol. 35, no. 1, pp. 5–28, 2023
2023
-
[3]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[4]
Advancements in deep learning techniques for time series forecast- ing in maritime applications: a comprehensive review,
M. Wang, X. Guo, Y . She, Y . Zhou, M. Liang, and Z. S. Chen, “Advancements in deep learning techniques for time series forecast- ing in maritime applications: a comprehensive review,”Information, vol. 15, no. 8, p. 507, 2024
2024
-
[5]
Informer: Beyond efficient transformer for long sequence time-series forecasting,
H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li, H. Xiong, and W. Zhang, “Informer: Beyond efficient transformer for long sequence time-series forecasting,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 12, 2021, pp. 11 106–11 115
2021
-
[6]
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting,
H. Wu, J. Xu, J. Wang, and M. Long, “Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting,” inAdvances in Neural Information Processing Systems, vol. 34, 2021, pp. 22 419–22 430
2021
-
[7]
A time series is worth 64 words: Long-term forecasting with transformers,
Y . Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam, “A time series is worth 64 words: Long-term forecasting with transformers,” 2023
2023
-
[9]
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
M. Jin, S. Wang, L. Ma, Z. Chu, J. Y . Zhang, X. Shi, P.-Y . Chen, Y . Liang, Y .-F. Li, S. Panet al., “Time-llm: Time series fore- casting by reprogramming large language models,”arXiv preprint arXiv:2310.01728, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Urbangpt: Spatio-temporal large language models,
Z. Li, L. Xia, J. Tang, Y . Xu, L. Shi, L. Xia, D. Yin, and C. Huang, “Urbangpt: Spatio-temporal large language models,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 5351–5362
2024
-
[11]
Time Series Forecasting as Reasoning: A Slow-Thinking Approach with Reinforced LLMs
Y . Luo, Y . Zhou, M. Cheng, J. Wang, D. Wang, T. Pan, and J. Zhang, “Time series forecasting as reasoning: A slow-thinking approach with reinforced llms,”arXiv preprint arXiv:2506.10630, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
H. Park, J. Jung, M. Seo, H. Choi, D. Cho, S. Park, and D.-G. Choi, “Ais-llm: A unified framework for maritime trajectory prediction, anomaly detection, and collision risk assessment with explainable forecasting,”arXiv preprint arXiv:2508.07668, 2025
-
[13]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y . Li, Y . Wu, and D. Guo, “Deepseekmath: Pushing the limits of mathematical rea- soning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Llama-3.1-tulu-3-8b-sft,
Allen Institute for AI, “Llama-3.1-tulu-3-8b-sft,” Hugging Face model repository, 2024
2024
-
[15]
arXiv preprint arXiv:2507.11851 , year=
M. Samragh, A. Kundu, D. Harrison, K. Nishu, D. Naik, M. Cho, and M. Farajtabar, “Your llm knows the future: Uncovering its multi- token prediction potential,”arXiv preprint arXiv:2507.11851, 2025
-
[16]
Spatial- temporal large language model for traffic prediction,
C. Liu, S. Yang, Q. Xu, Z. Li, C. Long, Z. Li, and R. Zhao, “Spatial- temporal large language model for traffic prediction,” in2024 25th IEEE International Conference on Mobile Data Management (MDM). IEEE, 2024, pp. 31–40
2024
-
[17]
St-llm+: Graph enhanced spatio-temporal large language models for traffic prediction,
C. Liu, K. H. Hettige, Q. Xu, C. Long, S. Xiang, G. Cong, Z. Li, and R. Zhao, “St-llm+: Graph enhanced spatio-temporal large language models for traffic prediction,”IEEE Transactions on Knowledge and Data Engineering, 2025. 6
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.