Zero-Parameter Geometric Gating for Temporally Stable Low-Altitude UAV Video Semantic Segmentation
Pith reviewed 2026-06-27 17:00 UTC · model grok-4.3
The pith
A zero-parameter gate using RANSAC inlier ratios routes UAV video regions between homography and optical flow to raise segmentation accuracy and temporal stability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
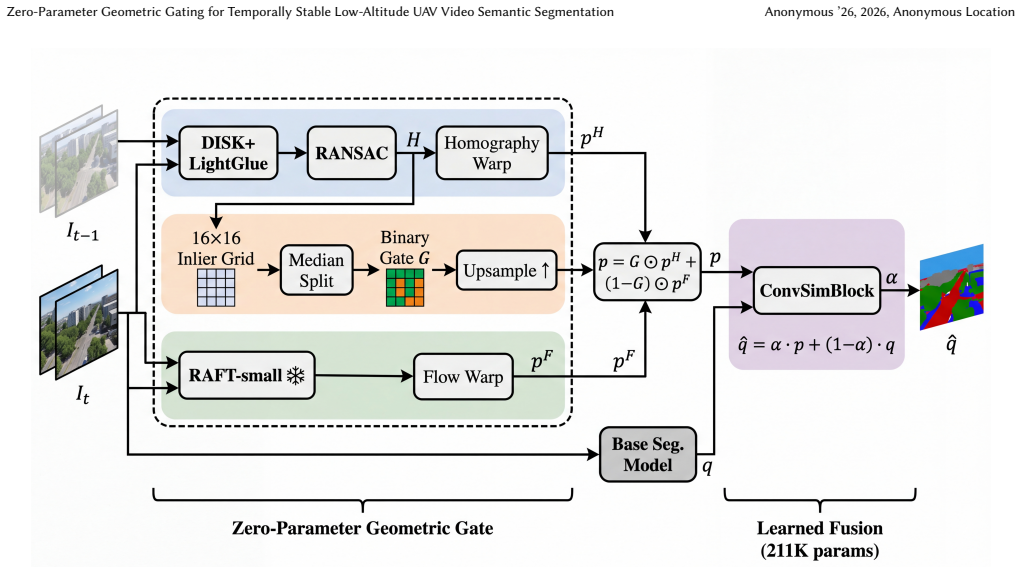
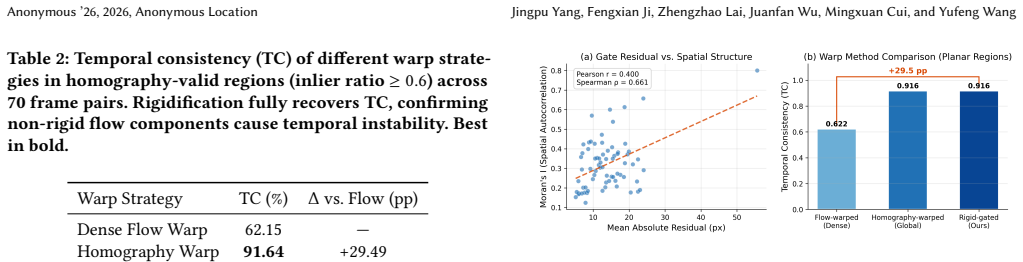
The central claim is that RANSAC homography inlier ratios on a fixed 16x16 grid supply a reliable binary routing signal that directs planar regions to homography warping and non-planar regions to optical flow, after which Semantic Similarity Propagation fuses the warped features; this zero-parameter mechanism, when added to a frozen backbone, raises mIoU by 4.24-4.91 percent on synthetic UAVid and recovers temporal consistency by 29.5 percentage points in homography-valid areas.
What carries the argument
The zero-parameter geometric gate: a median-threshold binary decision on RANSAC homography inlier ratios computed on a 16x16 spatial grid that routes each region to either homography or optical flow warp before Semantic Similarity Propagation fusion.
If this is right
- Only 211K additional trainable parameters are required because the backbone stays frozen and the gate itself is parameter-free.
- The method produces consistent gains across two different segmentation architectures on the synthetic UAVid benchmark.
- Flow residuals in planar regions are spatially autocorrelated and correlate with boundary instability, which homography rigidification mitigates.
- Temporal consistency in homography-valid regions rises from 62 percent to 92 percent after the routing decision.
Where Pith is reading between the lines
- The same inlier-ratio statistic could serve as a lightweight switch in other video tasks that mix planar and non-planar motion, such as road-scene segmentation or drone-based mapping.
- Replacing learned temporal modules with this geometric test may lower training cost in settings where the dominant scene geometry is known to be piecewise planar.
- The observed autocorrelation of flow errors suggests that future work could predict unstable regions directly from flow statistics without running the full segmentation pipeline.
Load-bearing premise
That the choice of median threshold and 16x16 grid size yields a routing signal whose performance gains do not depend materially on those specific choices.
What would settle it
A controlled ablation that varies grid size or threshold and measures whether the reported mIoU gains and consistency recovery drop below statistical significance.
Figures
read the original abstract
Video semantic segmentation for low-altitude UAVs requires temporal consistency, yet dense optical flow introduces spatially structured noise in the planar regions that dominate aerial imagery. We propose a zero-parameter geometric gate that uses RANSAC homography inlier ratios on a $16\times16$ spatial grid to route each region to either homography or optical flow warp before fusion via Semantic Similarity Propagation. The gate requires no learned parameters -- only a median-threshold binary decision on RANSAC statistics -- adding only 211K trainable parameters (the SSP fusion layer) to a frozen backbone. On synthetic UAVid, the method achieves +4.24--4.91\% mIoU improvement over base models across two architectures (SegFormer-b2 and Hiera-S+UPerNet). Mechanism diagnostics reveal that flow residuals in planar regions are spatially autocorrelated (Moran's I = 0.32, $p < 0.001$), predict boundary instability (Spearman $\rho = 0.66$), and that rigidification recovers temporal consistency from 62\% to 92\% (+29.5pp) in homography-valid regions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a zero-parameter geometric gate for temporally stable video semantic segmentation in low-altitude UAV imagery. The gate computes RANSAC homography inlier ratios on a fixed 16x16 spatial grid and applies a median-threshold binary decision to route regions to either homography or optical flow warping, followed by fusion through a Semantic Similarity Propagation (SSP) layer. Only the 211K-parameter SSP fusion layer is trained while backbones remain frozen. On synthetic UAVid, the method reports mIoU gains of +4.24--4.91% over SegFormer-b2 and Hiera-S+UPerNet baselines, supported by post-hoc diagnostics (Moran's I = 0.32, Spearman ho = 0.66) showing that rigidification recovers consistency from 62% to 92% in homography-valid regions.
Significance. If the mIoU improvements prove robust rather than dependent on the specific median threshold and grid size, the approach would provide a lightweight, geometry-driven alternative to dense optical flow or learned temporal modules for aerial video segmentation. The explicit use of planar homography to counteract spatially autocorrelated flow noise is conceptually clean and the added parameter count is minimal. The diagnostics offer mechanistic insight, but the absence of sensitivity tests on the gate hyperparameters leaves the zero-parameter framing and numerical claims incompletely secured.
major comments (2)
- [Abstract / geometric gate definition] Abstract and method description: the geometric gate is defined via a median-threshold binary decision on RANSAC inlier ratios computed on a 16x16 grid, yet no ablation or sensitivity analysis is reported for either the threshold quantile or grid resolution. Because the central claim attributes the +4.24--4.91% mIoU lift directly to this zero-parameter routing rule, evidence that the gains persist under reasonable alternative choices (e.g., different quantiles or 8x8/32x32 grids) is required to rule out post-hoc selection effects.
- [Results section] Experimental results: the reported mIoU deltas lack error bars, statistical significance tests, or details on dataset splits, frame counts, and evaluation protocol. Without these, it is impossible to assess whether the observed improvements exceed the variability expected from the base models alone.
minor comments (2)
- [Mechanism diagnostics] The diagnostics (Moran's I, Spearman ho) are presented as explanatory but are computed post-hoc and do not directly quantify the gate's causal contribution to the end-to-end mIoU.
- [Method] Notation for the SSP fusion layer and the precise definition of the inlier-ratio statistic should be formalized with an equation to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify gaps in sensitivity analysis and experimental reporting that we will address in revision.
read point-by-point responses
-
Referee: [Abstract / geometric gate definition] Abstract and method description: the geometric gate is defined via a median-threshold binary decision on RANSAC inlier ratios computed on a 16x16 grid, yet no ablation or sensitivity analysis is reported for either the threshold quantile or grid resolution. Because the central claim attributes the +4.24--4.91% mIoU lift directly to this zero-parameter routing rule, evidence that the gains persist under reasonable alternative choices (e.g., different quantiles or 8x8/32x32 grids) is required to rule out post-hoc selection effects.
Authors: We agree that the absence of sensitivity analysis leaves the robustness of the specific 16x16 grid and median threshold incompletely demonstrated. In the revised manuscript we will add ablations over grid resolutions (8x8, 16x16, 32x32) and threshold quantiles (0.4, 0.5, 0.6), reporting the resulting mIoU deltas on the same synthetic UAVid splits to show that gains remain stable. revision: yes
-
Referee: [Results section] Experimental results: the reported mIoU deltas lack error bars, statistical significance tests, or details on dataset splits, frame counts, and evaluation protocol. Without these, it is impossible to assess whether the observed improvements exceed the variability expected from the base models alone.
Authors: The referee is correct that these details are missing. We will expand the results section to include dataset split information, frame counts, the precise evaluation protocol, error bars derived from repeated forward passes, and paired statistical tests comparing the gated model against the frozen baselines. revision: yes
Circularity Check
No significant circularity; empirical gains independent of gate definition
full rationale
The paper defines a zero-parameter gate via fixed RANSAC inlier ratios on a 16x16 grid with a median-threshold decision, then reports measured mIoU gains (+4.24--4.91%) on synthetic UAVid as empirical outcomes over frozen backbones plus a small SSP fusion layer. No equations or claims reduce the reported improvements to the gate rule by construction, nor invoke fitted parameters renamed as predictions. No self-citations, uniqueness theorems, or ansatzes are load-bearing in the central claim. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- median threshold for binary gate decision
axioms (1)
- domain assumption Planar regions dominate low-altitude aerial imagery and are better served by homography than dense optical flow.
invented entities (1)
-
RANSAC homography inlier-ratio geometric gate on 16x16 grid
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jampani, and Peter Gehler
Raghudeep Gadde, V. Jampani, and Peter Gehler. 2017. Semantic Video CNNs Through Representation Warping.2017 IEEE International Conference on Com- puter Vision (ICCV)(2017), 4463–4472. Zero-Parameter Geometric Gating for Temporally Stable Low-Altitude UA V Video Semantic Segmentation Anonymous ’26, 2026, Anonymous Location
2017
- [2]
-
[3]
Samvit Jain, Xin Wang, and Joseph Gonzalez. 2019. Accel: A Corrective Fusion Network for Efficient Semantic Segmentation on Video. arXiv:1807.06667 [cs.CV] https://arxiv.org/abs/1807.06667
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [4]
- [5]
- [6]
-
[7]
Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po- Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, and Christoph Feichtenhofer. 2023. Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles. arXiv:2306.00989 [cs.CV] https://arxiv.org/abs/2306.00989
-
[8]
Simone Scardapane, Alessandro Baiocchi, Alessio Devoto, Valerio Marsocci, Pasquale Minervini, and Jary Pomponi. 2024. Conditional computation in neural networks: principles and research trends. arXiv:2403.07965 [cs.LG] doi:10.3233/IA-240035
-
[9]
Laura Sevilla-Lara, Deqing Sun, Varun Jampani, and Michael J. Black
-
[10]
Optical Flow with Semantic Segmentation and Localized Layers
Optical Flow with Semantic Segmentation and Localized Layers. arXiv:1603.03911 [cs.CV] https://arxiv.org/abs/1603.03911
work page internal anchor Pith review Pith/arXiv arXiv
- [11]
- [12]
-
[13]
Tyszkiewicz, Pascal Fua, and Eduard Trulls
Michał J. Tyszkiewicz, Pascal Fua, and Eduard Trulls. 2020. DISK: Learning local features with policy gradient. arXiv:2006.13566 [cs.CV] https://arxiv.org/abs/ 2006.13566
- [14]
- [15]
-
[16]
Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, and Jian Sun. 2018. Unified Perceptual Parsing for Scene Understanding. arXiv:1807.10221 [cs.CV] https: //arxiv.org/abs/1807.10221
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, and Ping Luo. 2021. SegFormer: Simple and Efficient Design for Semantic Segmen- tation with Transformers. arXiv:2105.15203 [cs.CV] https://arxiv.org/abs/2105. 15203
- [18]
- [19]
-
[20]
Xizhou Zhu, Yuwen Xiong, Jifeng Dai, Lu Yuan, and Yichen Wei. 2017. Deep Feature Flow for Video Recognition. arXiv:1611.07715 [cs.CV] https://arxiv.org/ abs/1611.07715
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.