From Rigid to Dynamic: Entropy-Guided Adaptive Inference for Long-Context LLMs
Pith reviewed 2026-06-27 16:55 UTC · model grok-4.3
The pith
Attention entropy distinguishes rigid from dynamic heads to enable adaptive compute allocation in long-context LLMs, yielding up to 2.39 times end-to-end speedup beyond 100k tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
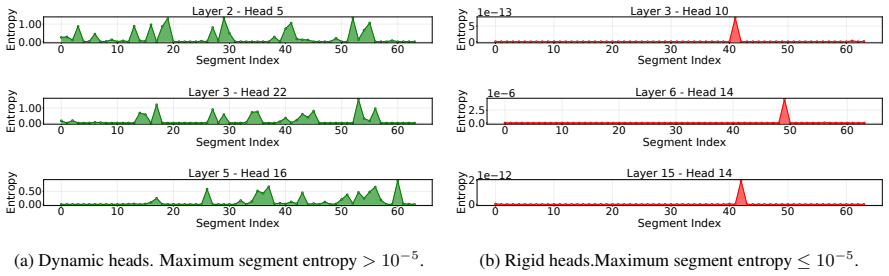
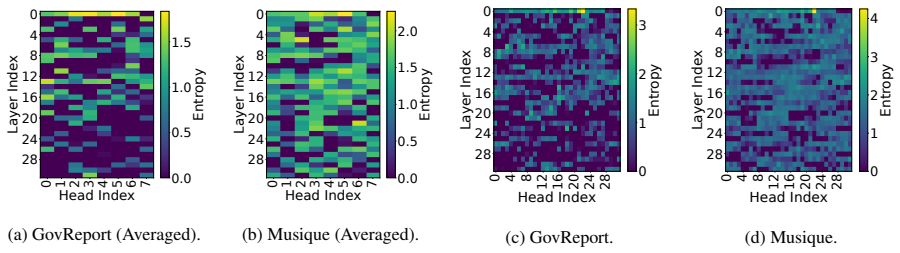
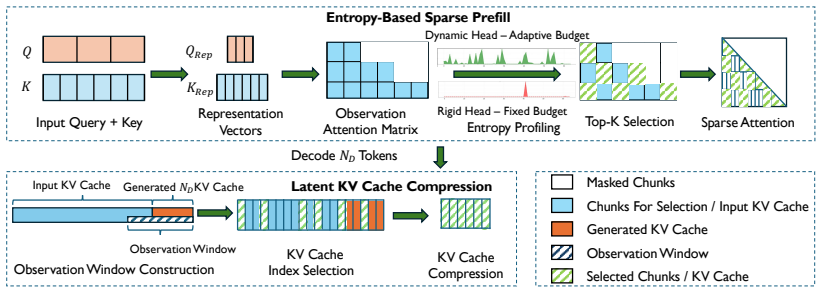
Existing sparse attention and KV cache methods use fixed patterns or uniform budgets, yet heads exhibit two entropy behaviors—rigid heads stay near zero entropy and dynamic heads fluctuate—and the mix of these behaviors is context-dependent rather than model-fixed. EntropyInfer therefore performs online entropy measurement during prefilling to allocate compute at head and segment granularity, then applies a latent KV cache compression step that incorporates tokens generated during decoding to retain the most critical entries.
What carries the argument
EntropyInfer, a training-free framework that classifies attention heads as rigid or dynamic via entropy measurement to guide per-head and per-segment compute allocation during prefilling, together with output-token-guided latent KV cache compression during decoding.
If this is right
- Compute is spent only where entropy indicates it is needed, reducing waste on rigid heads.
- KV cache compression improves by using tokens produced during generation rather than prefill tokens alone.
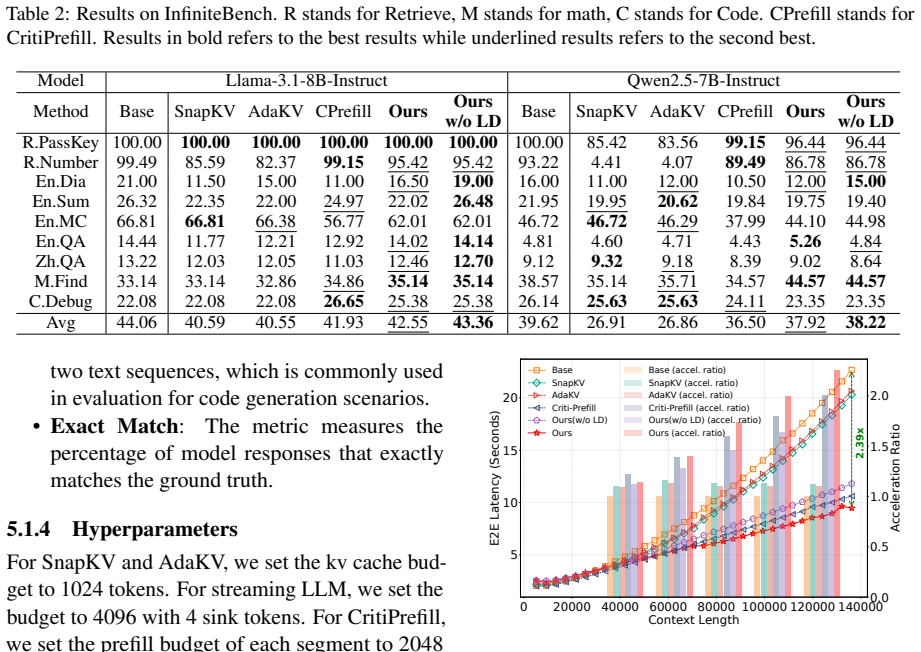
- End-to-end inference runs up to 2.39 times faster on sequences longer than 100k tokens while staying close to full-attention quality.
- The same adaptive scheme outperforms fixed-pattern baselines such as uniform sparsity across multiple model families.
Where Pith is reading between the lines
- Head entropy patterns arise from the interaction of model and input rather than being intrinsic model properties, so similar online measurement could be tested on feed-forward or other layers.
- The approach suggests that task-specific fine-tuning of entropy thresholds might further improve allocation without retraining the base model.
- Combining head-level entropy adaptation with existing token-level or layer-level pruning could compound efficiency gains on even longer contexts.
Load-bearing premise
The distribution of rigid and dynamic heads is context-dependent and cannot be predetermined offline, so online entropy measurement during prefilling is required to guide the allocation.
What would settle it
An experiment in which a fixed, offline head classification produces the same speed and quality as the online entropy measurement on the same long inputs would falsify the need for context-dependent adaptation.
Figures
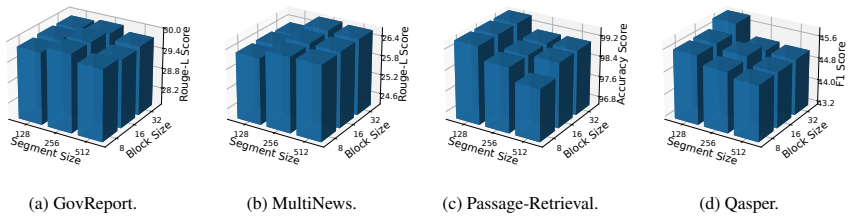

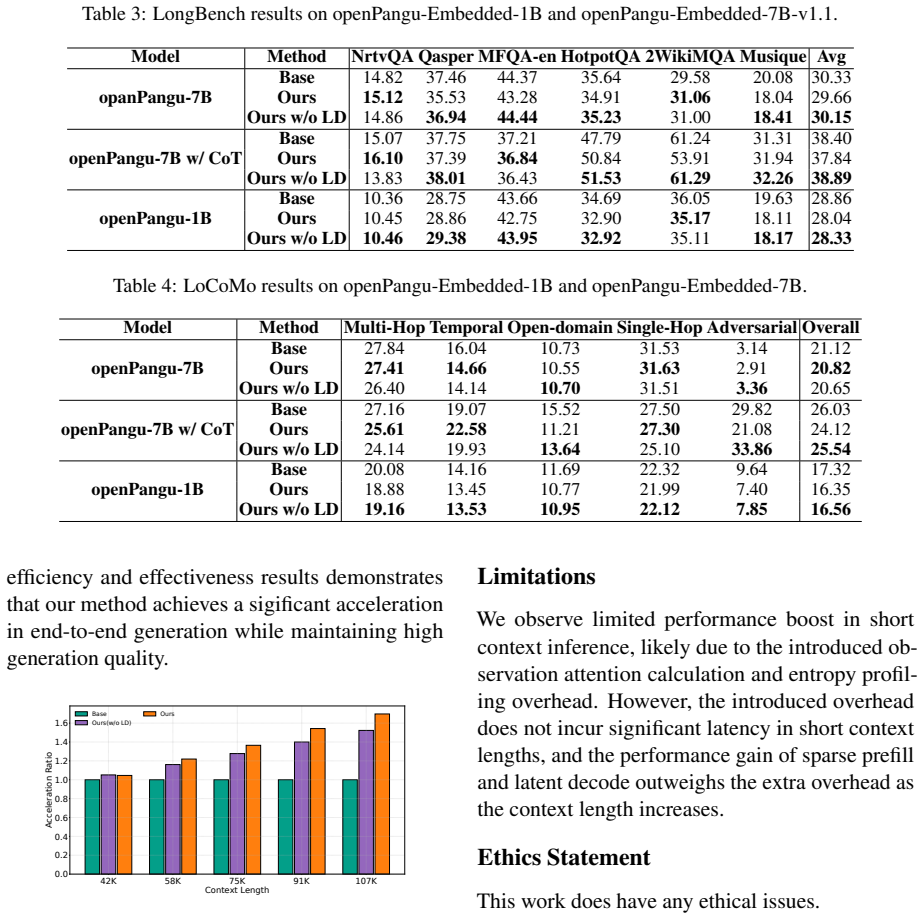
read the original abstract
Existing sparse attention and KV cache compression methods for long-context LLM inference typically apply fixed sparsity patterns or uniform budgets across all attention heads, overlooking the substantial variation in attention behavior among heads and contexts. We observe two distinct entropy patterns among attention heads: Rigid Heads, whose entropy stays near zero across input segments, and Dynamic Heads, whose entropy fluctuates significantly. Crucially, the distribution of these types is context-dependent and cannot be predetermined offline. We therefore propose EntropyInfer, a training-free framework that uses attention entropy to adaptively allocate compute at the granularity of individual heads and segments during prefilling. For decoding, we introduce a latent KV cache compression scheme that leverages generated output tokens, rather than prefill tokens alone, to identify and retain the most critical cache entries. Extensive experiments on Llama, Qwen and openPangu model series show that EntropyInfer consistently outperforms baselines including SnapKV, AdaKV, and CritiPrefill, achieving up to 2.39$\times$ end-to-end speedup beyond 100k tokens with minimal quality degradation compared to full attention. The code is released in https://github.com/SHA-4096/EntropyInfer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EntropyInfer, a training-free method for efficient long-context LLM inference. It observes that attention heads exhibit either low-entropy 'rigid' or high-fluctuating 'dynamic' patterns, with the rigid/dynamic assignment being context-dependent and thus requiring online entropy measurement during prefilling to adaptively allocate compute per head and segment. For decoding it adds a latent KV-cache compression scheme that incorporates generated tokens. Experiments on Llama, Qwen and openPangu series report consistent outperformance over SnapKV, AdaKV and CritiPrefill, with up to 2.39× end-to-end speedup beyond 100 k tokens and minimal quality degradation; code is released.
Significance. If the necessity of online entropy-driven adaptation is confirmed and the speed/quality results replicate under full experimental controls, the work would offer a practical, training-free route to head- and segment-level sparsity that exploits observed entropy heterogeneity. The public code release strengthens reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim that rigid/dynamic head distributions 'cannot be predetermined offline' and therefore require online entropy measurement during prefilling is load-bearing, yet no ablation is reported that fixes head types from average entropy on a held-out context set and compares end-to-end speedup/quality against the online version. If static allocation matches performance within noise, the adaptive mechanism is not justified.
- [Abstract] Abstract: performance claims (speedup, quality degradation) are stated without any description of the entropy thresholds, exact per-head/segment allocation rules, number of runs, or statistical significance tests, preventing verification that the reported gains are supported by the data.
minor comments (1)
- [Abstract] The abstract mentions 'latent KV cache compression' but provides no equation or algorithmic sketch of how generated tokens are used to select retained entries.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript to incorporate the requested clarifications and ablation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that rigid/dynamic head distributions 'cannot be predetermined offline' and therefore require online entropy measurement during prefilling is load-bearing, yet no ablation is reported that fixes head types from average entropy on a held-out context set and compares end-to-end speedup/quality against the online version. If static allocation matches performance within noise, the adaptive mechanism is not justified.
Authors: We agree that the absence of this ablation leaves the central claim insufficiently supported. Our Section 3.1 observations show context-dependent variation in head classifications, but without a direct comparison to a static baseline derived from held-out averages we cannot quantify the performance gap. We will add the requested ablation (static assignment from held-out entropy averages versus online per-context measurement) to the revised manuscript, reporting end-to-end speedup and quality metrics on the same benchmarks. This will either substantiate the need for online adaptation or allow us to adjust our claims accordingly. revision: yes
-
Referee: [Abstract] Abstract: performance claims (speedup, quality degradation) are stated without any description of the entropy thresholds, exact per-head/segment allocation rules, number of runs, or statistical significance tests, preventing verification that the reported gains are supported by the data.
Authors: The abstract is space-constrained, but the full manuscript details the entropy threshold (Section 3.2), per-head/segment allocation logic (Algorithm 1 and Section 3.3), and experimental protocol. We will revise the abstract to include the key threshold value, a brief statement of the allocation rules, the number of runs (five independent runs with mean and standard deviation), and note that paired t-tests were used for significance where appropriate. This will make the performance claims verifiable from the abstract alone. revision: yes
Circularity Check
No significant circularity; derivation relies on runtime measurement and external experiments
full rationale
The paper's core method computes attention entropy at runtime during prefilling to classify rigid vs. dynamic heads and allocate compute accordingly. This is a direct measurement, not a fitted parameter renamed as a prediction or a self-referential definition. The claim that head-type distributions are context-dependent is presented as an empirical observation, with end-to-end speedups validated against independent baselines (SnapKV, AdaKV, CritiPrefill) on Llama/Qwen/openPangu models. No equations reduce by construction to inputs, no self-citation chains are load-bearing for the central result, and no ansatz or uniqueness theorem is smuggled in. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention entropy can be computed at runtime and reliably distinguishes rigid from dynamic heads in a context-dependent way
Reference graph
Works this paper leans on
-
[1]
Bai, Yushi and Lv, Xin and Zhang, Jiajie and Lyu, Hongchang and Tang, Jiankai and Huang, Zhidian and Du, Zhengxiao and Liu, Xiao and Zeng, Aohan and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi , editor =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1:. doi:10.18653/v1/2024.acl-long.172 , abstract =
-
[2]
Transactions on Machine Learning Research , year=
A survey on large language model acceleration based on kv cache management , author=. Transactions on Machine Learning Research , year=
-
[3]
doi:ccccccccccccccccccccccccccccc , urldate =
Bai, Yushi and Lv, Xin and Zhang, Jiajie and Lyu, Hongchang and Tang, Jiankai and Huang, Zhidian and Du, Zhengxiao and Liu, Xiao and Zeng, Aohan and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi , year = 2024, month = jun, number =. doi:ccccccccccccccccccccccccccccc , urldate =. arXiv , langid =:2308.14508 , primaryclass =
Pith/arXiv arXiv 2024
-
[4]
and Cohan, Arman , year = 2020, journal =
Beltagy, Iz and Peters, Matthew E. and Cohan, Arman , year = 2020, journal =. Longformer:. 2004.05150 , archiveprefix =
Pith/arXiv arXiv 2020
-
[5]
Longformer:
Beltagy, Iz and Peters, Matthew E and Cohan, Arman , langid =. Longformer:
-
[6]
Chen, Hanting and Wang, Yasheng and Han, Kai and Li, Dong and Li, Lin and Bi, Zhenni and Li, Jinpeng and Wang, Haoyu and Mi, Fei and Zhu, Mingjian and Wang, Bin and Song, Kaikai and Fu, Yifei and He, Xu and Luo, Yu and Zhu, Chong and He, Quan and Wu, Xueyu and He, Wei and Hu, Hailin and Tang, Yehui and Tao, Dacheng and Chen, Xinghao and Wang, Yunhe , year...
-
[7]
doi:10.48550/arXiv.2510.22556 , urldate =
Chen, Jinhan and Liu, Jianchun and Xu, Hongli and Gao, Xianjun and Wang, Shilong , year = 2025, month = oct, number =. doi:10.48550/arXiv.2510.22556 , urldate =. arXiv , keywords =:2510.22556 , primaryclass =
-
[8]
Proceedings of the 36th International Conference on Neural Information Processing Systems , author =
-
[9]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R. doi:10.48550/arXiv.2205.14135 , urldate =. arXiv , langid =:2205.14135 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.14135
-
[10]
The Thirty-Ninth Annual Conference on Neural Information Processing Systems , author =
Ada-. The Thirty-Ninth Annual Conference on Neural Information Processing Systems , author =
-
[11]
International Conference on Learning Representations , author =
Model Tells You What to Discard:. International Conference on Learning Representations , author =
-
[12]
Ge, Suyu and Zhang, Yunan and Liu, Liyuan and Zhang, Minjia and Han, Jiawei and Gao, Jianfeng , year = 2024, month = jan, number =. Model. arXiv , langid =:2310.01801 , primaryclass =
Pith/arXiv arXiv 2024
-
[13]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and. The. doi:10.48550/arXiv.2407.21783 , urldate =. arXiv , keywords =:2407.21783 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[14]
Proceedings of the 38th International Conference on Neural Information Processing Systems , author =
-
[15]
and Shao, Yakun Sophia and Keutzer, Kurt and Gholami, Amir , year = 2025, month = may, number =
Hooper, Coleman and Kim, Sehoon and Mohammadzadeh, Hiva and Mahoney, Michael W. and Shao, Yakun Sophia and Keutzer, Kurt and Gholami, Amir , year = 2025, month = may, number =. doi:10.48550/arXiv.2401.18079 , urldate =. arXiv , keywords =:2401.18079 , primaryclass =
-
[16]
and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili , urldate =
Jiang, Huiqiang and Li, Yucheng and Zhang, Chengruidong and Wu, Qianhui and Luo, Xufang and Ahn, Surin and Han, Zhenhua and Abdi, Amir H. and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili , year = 2024, month = oct, number =. doi:10.48550/arXiv.2407.02490 , urldate =. arXiv , langid =:2407.02490 , primaryclass =
-
[17]
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and de las Casas, Diego and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and Lavaud, L. Mistral. doi:10.48550/arXiv.2310.06825 , urldate =. arXiv , keywords =:2310.06825 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825
-
[18]
Entropy-Guided
Kim, Heekyum and Jung, Yuchul , year = 2025, month = jul, journal =. Entropy-Guided. doi:None , abstract =
2025
-
[19]
Entropy-
Kim, Heekyum and Jung, Yuchul , abstract =. Entropy-
-
[20]
The Thirteenth International Conference on Learning Representations , author =
-
[21]
Lai, Xunhao and Lu, Jianqiao and Luo, Yao and Ma, Yiyuan and Zhou, Xun , year = 2025, abstract =
2025
-
[22]
doi:10.48550/arXiv.2507.13681 , urldate =
Li, Haoyang and Xu, Zhanchao and Li, Yiming and Chen, Xuejia and Li, Darian and Tian, Anxin and Xiao, Qingfa and Deng, Cheng and Wang, Jun and Li, Qing and Chen, Lei and Yuan, Mingxuan , year = 2025, month = jul, number =. doi:10.48550/arXiv.2507.13681 , urldate =. arXiv , langid =:2507.13681 , primaryclass =
-
[23]
Li, Mo and Zhang, Songyang and Zhang, Taolin and Duan, Haodong and Liu, Yunxin and Chen, Kai , year = 2025, journal =
2025
-
[24]
doi:10.48550/arXiv.2407.11963 , urldate =
Li, Mo and Zhang, Songyang and Liu, Yunxin and Chen, Kai , year = 2024, month = jul, number =. doi:10.48550/arXiv.2407.11963 , urldate =. arXiv , keywords =:2407.11963 , primaryclass =
-
[25]
arXiv , langid =:2404.14469 , primaryclass =
Li, Yuhong and Huang, Yingbing and Yang, Bowen and Venkitesh, Bharat and Locatelli, Acyr and Ye, Hanchen and Cai, Tianle and Lewis, Patrick and Chen, Deming , year = 2024, month = jun, number =. arXiv , langid =:2404.14469 , primaryclass =
Pith/arXiv arXiv 2024
-
[26]
Liu, Zirui and Yuan, Jiayi and Jin, Hongye and Zhong, Shaochen and Xu, Zhaozhuo and Braverman, Vladimir and Chen, Beidi and Hu, Xia , year = 2024, journal =. 2402.02750 , archiveprefix =
Pith/arXiv arXiv 2024
-
[27]
doi:10.13140/RG.2.2.28167.37282 , urldate =
Liu, Zirui and Yuan, Jiayi and Jin, Hongye and Zhong, Shaochen and Xu, Zhaozhuo and Braverman, Vladimir and Chen, Beidi and Hu, Xia , year = 2023, eprint =. doi:10.13140/RG.2.2.28167.37282 , urldate =
-
[28]
Audiocomposer: Towards fine-grained audio generation with natural language descriptions,
Lv, Junlin and Feng, Yuan and Xie, Xike and Jia, Xin and Peng, Qirong and Xie, Guiming , year = 2025, pages =. doi:10.1109/ICASSP49660.2025.10887916 , keywords =
-
[29]
doi:10.48550/arXiv.2409.12490 , urldate =
Lv, Junlin and Feng, Yuan and Xie, Xike and Jia, Xin and Peng, Qirong and Xie, Guiming , year = 2024, month = sep, number =. doi:10.48550/arXiv.2409.12490 , urldate =. arXiv , langid =:2409.12490 , primaryclass =
-
[30]
OpenAI and Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and Aleman, Florencia Leoni and Almeida, Diogo and Altenschmidt, Janko and Altman, Sam and Anadkat, Shyamal and Avila, Red and Babuschkin, Igor and Balaji, Suchir and Balcom, Valerie and Baltescu, Paul and Bao, Haiming and Bavarian, Mohammad and Belgum, Jeff a...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774
-
[31]
Qwen and Yang, An and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Li, Chengyuan and Liu, Dayiheng and Huang, Fei and Wei, Haoran and Lin, Huan and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jianxin and Yang, Jiaxi and Zhou, Jingren and Lin, Junyang and Dang, Kai and Lu, Keming and Bao, Keqin and Yang, Ke...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2025
-
[32]
Shannon, C. E. , year = 1948, month = jul, journal =. A. doi:10.1002/j.1538-7305.1948.tb01338.x , urldate =
-
[33]
Proceedings of the 40th International Conference on Machine Learning , author =
-
[34]
Sheng, Ying and Zheng, Lianmin and Yuan, Binhang and Li, Zhuohan and Ryabinin, Max and Fu, Daniel Y. and Xie, Zhiqiang and Chen, Beidi and Barrett, Clark and Gonzalez, Joseph E. and Liang, Percy and R. doi:10.48550/arXiv.2303.06865 , urldate =. arXiv , keywords =:2303.06865 , primaryclass =
-
[35]
Svyatkovskiy, Alexey and Deng, Shao Kun and Fu, Shengyu and Sundaresan, Neel , year = 2020, month = nov, pages =. Proceedings of the 28th. doi:10.1145/3368089.3417058 , urldate =
-
[36]
doi:10.48550/arXiv.2407.15891 , abstract =
Tang, Hanlin and Lin, Yang and Lin, Jing and Han, Qingsen and Hong, Shikuan and Yao, Yiwu and Wang, Gongyi , year = 2024, month = jul, number =. doi:10.48550/arXiv.2407.15891 , urldate =. arXiv , keywords =:2407.15891 , primaryclass =
-
[37]
and Kaiser,
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Attention Is All You Need , booktitle =
-
[38]
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia , year = 2023, month = aug, number =. Attention. doi:10.48550/arXiv.1706.03762 , urldate =. arXiv , langid =:1706.03762 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762 2023
-
[39]
Wang, Zheng and Jin, Boxiao and Yu, Zhongzhi and Zhang, Minjia , year = 2024, month = jul, number =. Model. doi:10.48550/arXiv.2407.08454 , urldate =. arXiv , keywords =:2407.08454 , primaryclass =
-
[40]
Transactions on Machine Learning Research , issn =
Emergent Abilities of Large Language Models , author =. Transactions on Machine Learning Research , issn =
-
[41]
Emergent Abilities of Large Language Models
Wei, Jason and Tay, Yi and Bommasani, Rishi and Raffel, Colin and Zoph, Barret and Borgeaud, Sebastian and Yogatama, Dani and Bosma, Maarten and Zhou, Denny and Metzler, Donald and Chi, Ed H. and Hashimoto, Tatsunori and Vinyals, Oriol and Liang, Percy and Dean, Jeff and Fedus, William , year = 2022, month = oct, number =. Emergent. doi:10.48550/arXiv.220...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2206.07682 2022
-
[42]
The Fourteenth International Conference on Learning Representations , author =
-
[43]
doi:10.48550/arXiv.2510.11292 , urldate =
Wu, Wenbo and Si, Qingyi and Pan, Xiurui and Wang, Ye and Zhang, Jie , year = 2025, month = oct, number =. doi:10.48550/arXiv.2510.11292 , urldate =. arXiv , keywords =:2510.11292 , primaryclass =
-
[44]
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Xiao, Guangxuan and Tang, Jiaming and Zuo, Jingwei and Guo, Junxian and Yang, Shang and Tang, Haotian and Fu, Yao and Han, Song , year = 2024, month = oct, number =. doi:10.48550/arXiv.2410.10819 , urldate =. arXiv , keywords =:2410.10819 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.10819 2024
-
[45]
Efficient Streaming Language Models with Attention Sinks , booktitle =
Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike , editor =. Efficient Streaming Language Models with Attention Sinks , booktitle =
-
[46]
Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike , year = 2024, month = apr, number =. Efficient. arXiv , langid =:2309.17453 , primaryclass =
Pith/arXiv arXiv 2024
-
[47]
Xiong, Jing and Shen, Jianghan and Ye, Fanghua and Tao, Chaofan and Wan, Zhongwei and Lu, Jianqiao and Wu, Xun and Zheng, Chuanyang and Guo, Zhijiang and Yang, Min and Kong, Lingpeng and Wong, Ngai , editor =. Proceedings of the 2025. doi:10.18653/v1/2025.emnlp-main.209 , urldate =
-
[48]
https://doi.org/10.18653/v1/2024.findings-acl.195
Yang, Dongjie and Han, Xiaodong and Gao, Yan and Hu, Yao and Zhang, Shilin and Zhao, Hai , editor =. Findings of the Association for Computational Linguistics:. doi:10.18653/v1/2024.findings-acl.195 , abstract =
-
[49]
arXiv , langid =:2405.12532 , primaryclass =
Yang, Dongjie and Han, XiaoDong and Gao, Yan and Hu, Yao and Zhang, Shilin and Zhao, Hai , year = 2024, month = jun, number =. arXiv , langid =:2405.12532 , primaryclass =
arXiv 2024
-
[50]
Big Bird:
Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon, Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others , year = 2020, journal =. Big Bird:
2020
-
[51]
Zaheer, Manzil and Guruganesh, Guru and Dubey, Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon, Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and Ahmed, Amr , abstract =. Big
-
[52]
doi: 10.18653/v1/2024.acl-long.814
Zhang, Xinrong and Chen, Yingfa and Hu, Shengding and Xu, Zihang and Chen, Junhao and Hao, Moo and Han, Xu and Thai, Zhen and Wang, Shuo and Liu, Zhiyuan and Sun, Maosong , year = 2024, pages =. Proceedings of the 62nd. doi:10.18653/v1/2024.acl-long.814 , urldate =
-
[53]
Proceedings of the 37th International Conference on Neural Information Processing Systems , author =
-
[54]
Zhang, Zhenyu and Sheng, Ying and Zhou, Tianyi and Chen, Tianlong and Zheng, Lianmin and Cai, Ruisi and Song, Zhao and Tian, Yuandong and R. H\ \_2\. arXiv , langid =:2306.14048 , primaryclass =
-
[55]
doi:10.48550/arXiv.2511.11907 , urldate =
Zhang, Huawei and Xia, Chunwei and Wang, Zheng , year = 2025, month = dec, number =. doi:10.48550/arXiv.2511.11907 , urldate =. arXiv , keywords =:2511.11907 , primaryclass =
-
[56]
arXiv preprint arXiv:2402.17753 , year=
Evaluating very long-term conversational memory of llm agents , author=. arXiv preprint arXiv:2402.17753 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.