An Agency-Transferring Model-Free Policy Enhancement Technique
Pith reviewed 2026-06-27 17:10 UTC · model grok-4.3
The pith
Arbitration between a functional baseline policy and a trainable policy gradually transfers agency to produce a standalone neural network controller with explicit lower bounds on goal-reaching probability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The method arbitrates at every time step between a functional baseline policy and a trainable learning policy, initially weighting the baseline heavily and then progressively increasing the weight on the learning policy until the baseline is no longer used; under the assumption that the baseline reaches and remains in a goal set with high probability, this procedure yields a final neural-network policy whose goal-reaching probability is bounded from below by an explicit expression derived from the baseline's success rate.
What carries the argument
The arbitration mechanism that blends baseline and learning-policy actions and steadily reduces the baseline's influence until the learning policy runs alone.
If this is right
- Goal-reaching rates remain high from the first training episodes because the arbitration rule exploits the baseline's reliability.
- The final policy is a neural network that requires no baseline support at deployment time.
- Explicit lower bounds on the final policy's success probability are available once the baseline's success rate is known.
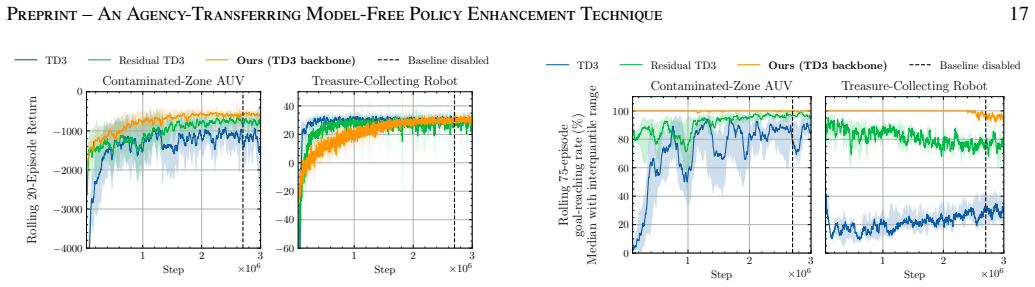
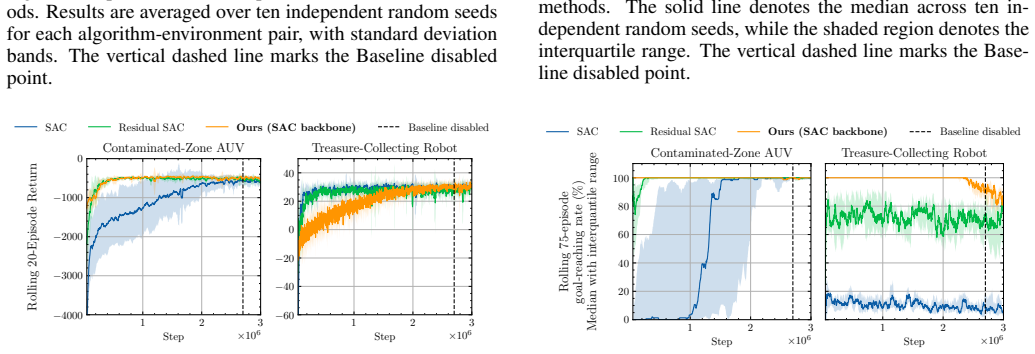
- Returns on standard continuous-control benchmarks match or exceed those of competing methods while preserving the highest goal-reaching rates among them.
- The same arbitration schedule works across multiple benchmark tasks without task-specific reward redesign.
- pith_inferences=[
Load-bearing premise
The supplied baseline policy reaches a designated goal set and stays there with high probability when run by itself.
What would settle it
Run the trained standalone neural network on the same environments and measure whether its empirical goal-reaching frequency lies below the lower bound stated in the theoretical analysis.
Figures





read the original abstract
Training reinforcement learning (RL) policies from scratch is costly: it requires careful reward and environment design, extensive tuning, and substantial computation. Yet many control problems already have a functional but suboptimal policy available as a baseline. This paper proposes a method for embedding such a baseline into the RL training process, simultaneously improving training efficiency relative to from-scratch methods and producing a learning policy that outperforms the baseline. At each step, the method arbitrates between the baseline policy and a trainable learning policy, initially relying strongly on the baseline policy and then progressively transferring agency to the learning policy. By the end of training, the learning policy is a standalone neural network that operates without baseline policy support. The paper formalizes what it means for the baseline policy to be functional: under this policy, the agent reaches a goal set and remains there with high probability. The proposed arbitration mechanism is designed to exploit this property during training, yielding high goal-reaching rates right from the beginning of training. A theoretical analysis provides a formal interpretation of this behavior under stated assumptions and extends it to the final baseline-free regime, where explicit lower bounds are derived for the goal-reaching probability of the standalone learning policy. Empirical results on continuous-control benchmarks show that the proposed method achieves returns that match or exceed those of competitive approaches, while maintaining the highest goal-reaching rates throughout training among the compared methods -- including in the final stage, where the learning policy operates without any baseline support.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an agency-transferring technique for RL policy enhancement. It arbitrates between a given functional baseline policy (one that reaches and stays in a goal set with high probability) and a trainable learning policy, with an agency-transfer schedule that initially favors the baseline and progressively shifts control to the learning policy. By the end of training the output is a standalone neural-network policy with no baseline support. The paper claims a theoretical analysis that extends the functional-baseline property through the arbitration mechanism to derive explicit lower bounds on the goal-reaching probability of this final policy, and reports empirical results on continuous-control benchmarks in which the method matches or exceeds competitive baselines while maintaining the highest goal-reaching rates throughout training, including in the final baseline-free stage.
Significance. If the claimed lower bounds are correctly derived and the empirical gains are reproducible, the approach would provide a practical way to bootstrap from existing functional policies, improving sample efficiency and final performance in settings where such baselines are available. The explicit conditioning on the functional-baseline assumption and the production of a truly standalone policy are potentially useful distinctions from standard imitation or residual-learning methods.
major comments (2)
- [Abstract / theoretical analysis] Abstract and theoretical-analysis section: the central claim is that explicit lower bounds on goal-reaching probability are derived for the final standalone policy by extending the functional-baseline property through the arbitration mechanism. No derivation steps, intermediate lemmas, or explicit dependence on the agency-transfer schedule appear in the abstract, and the provided manuscript excerpt does not display the relevant equations or proof outline. Because this bound is load-bearing for the paper's theoretical contribution, the absence of inspectable steps prevents verification that the extension is non-circular and holds under the stated assumptions.
- [Empirical results] Empirical-results section: the abstract states that the method achieves returns that match or exceed competitive approaches while maintaining the highest goal-reaching rates, including in the final baseline-free stage. The reader's note indicates that error bars, data-exclusion criteria, and the precise definition of the functional baseline used in each benchmark are not visible. These details are required to assess whether the reported superiority is robust or sensitive to the choice of baseline functionality.
minor comments (2)
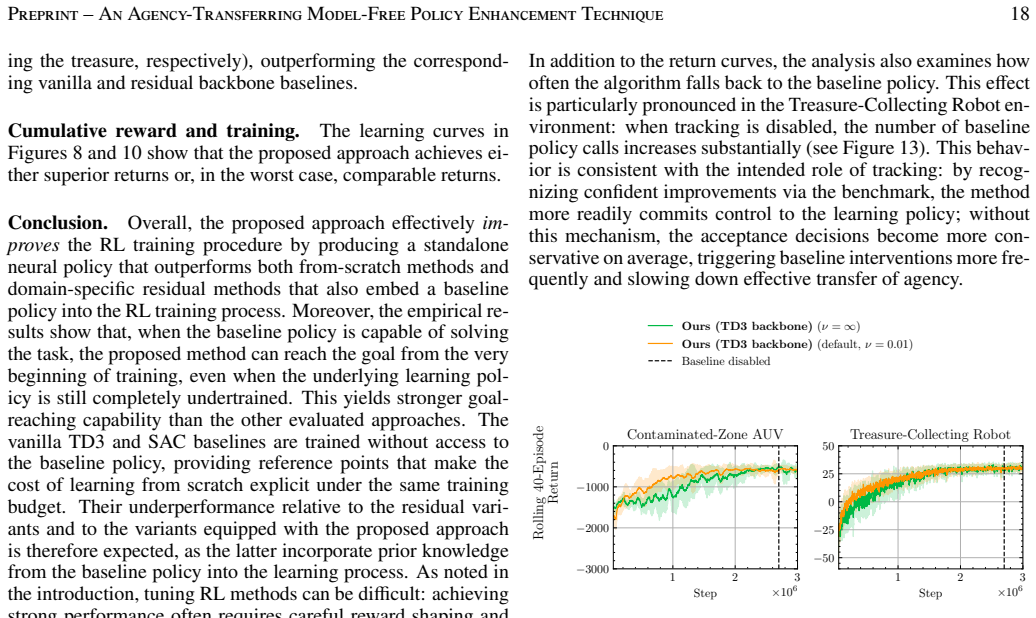
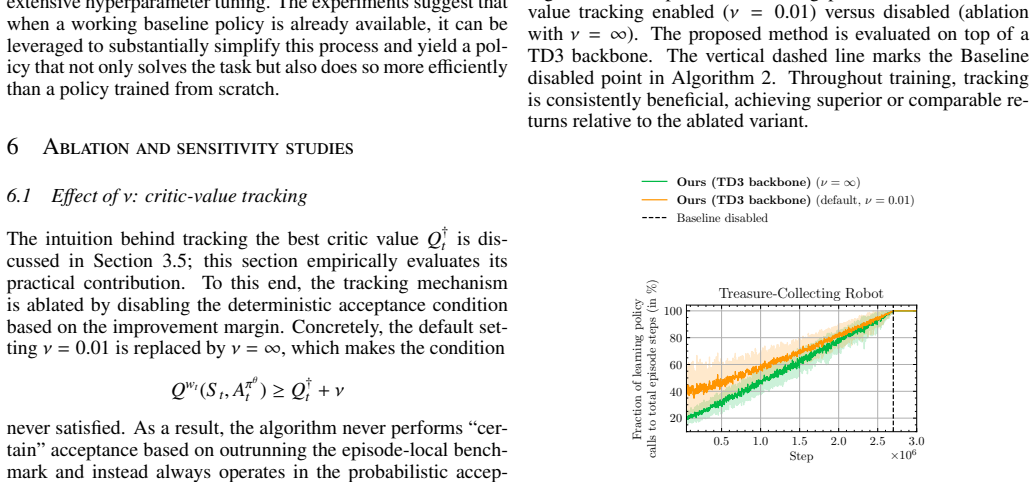
- [Method] The agency-transfer schedule is listed as a free parameter; its functional form and any hyper-parameter sensitivity analysis should be stated explicitly.
- [Formalization] Notation for the arbitration mechanism and the functional-baseline probability should be introduced once and used consistently; the current abstract description mixes informal and formal language.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our theoretical and empirical contributions. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis] Abstract and theoretical-analysis section: the central claim is that explicit lower bounds on goal-reaching probability are derived for the final standalone policy by extending the functional-baseline property through the arbitration mechanism. No derivation steps, intermediate lemmas, or explicit dependence on the agency-transfer schedule appear in the abstract, and the provided manuscript excerpt does not display the relevant equations or proof outline. Because this bound is load-bearing for the paper's theoretical contribution, the absence of inspectable steps prevents verification that the extension is non-circular and holds under the stated assumptions.
Authors: The manuscript's theoretical-analysis section contains the full derivation, including intermediate lemmas that extend the functional-baseline property via the arbitration mechanism and the explicit dependence on the agency-transfer schedule. The abstract summarizes the result at a high level, following standard conventions for length. If the excerpt reviewed omitted the relevant section, the complete manuscript includes the proof outline. To improve inspectability, we will revise the abstract to incorporate a concise outline of the key derivation steps. revision: partial
-
Referee: [Empirical results] Empirical-results section: the abstract states that the method achieves returns that match or exceed competitive approaches while maintaining the highest goal-reaching rates, including in the final baseline-free stage. The reader's note indicates that error bars, data-exclusion criteria, and the precise definition of the functional baseline used in each benchmark are not visible. These details are required to assess whether the reported superiority is robust or sensitive to the choice of baseline functionality.
Authors: The full manuscript provides error bars (standard deviation across seeds) in the result figures and tables of the empirical-results section, along with data-exclusion criteria and environment-specific definitions of the functional baseline in the experimental setup. To ensure these elements are immediately visible without reference to appendices, we will add explicit statements on error bars, exclusion rules, and baseline definitions directly in the main empirical-results section. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper states the functional baseline as an external premise and derives lower bounds on goal-reaching probability for the final standalone policy by extending that premise through the arbitration mechanism. No equations, fitted parameters, or self-citations are shown that would reduce the derived bounds to a quantity chosen from the same data or to a self-referential definition. The central theoretical step remains conditional on the stated assumptions and does not collapse by construction to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- agency-transfer schedule
axioms (1)
- domain assumption Baseline policy reaches goal set and remains there with high probability.
Reference graph
Works this paper leans on
-
[1]
Silver, T
D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, T. Lillicrap, K. Simonyan, D. Hassabis, A general reinforcement learning algorithm that masters chess, shogi, and go through self-play, Science 362 (6419) (2018) 1140–1144
2018
-
[2]
OpenAI, :, C. Berner, G. Brockman, B. Chan, V . Cheung, P. Dzbiak, C. Dennison, D. Farhi, Q. Fischer, S. Hashme, C. Hesse, R. Jozefowicz, S. Gray, C. Olsson, J. Pachocki, M. Petrov, H. P. d. O. Pinto, J. Raiman, T. Salimans, J. Schlatter, J. Schneider, S. Sidor, I. Sutskever, J. Tang, F. Wolski, S. Zhang, Dota 2 with large scale deep rein- forcement learn...
Pith/arXiv arXiv 2019
-
[3]
Vinyals, et al., Grandmaster level in StarCraft II using multi-agent reinforcement learning, Nature 575 (7782) (2019) 350–354
O. Vinyals, et al., Grandmaster level in StarCraft II using multi-agent reinforcement learning, Nature 575 (7782) (2019) 350–354
2019
-
[4]
I. Akkaya, M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, M. Plappert, G. Powell, R. Ribas, et al., Solving rubik’s cube with a robot hand, arXiv preprint arXiv:1910.07113 (2019)
Pith/arXiv arXiv 1910
-
[5]
H. Surmann, C. Jestel, R. Marchel, F. Musberg, H. El- hadj, M. Ardani, Deep reinforcement learning for real au- tonomous mobile robot navigation in indoor environments (2020).arXiv:2005.13857
arXiv 2020
-
[6]
Engstrom, A
L. Engstrom, A. Ilyas, S. Santurkar, D. Tsipras, F. Janoos, L. Rudolph, A. Madry, Implementation matters in deep rl: A case study on ppo and trpo, in: International Conference on Learning Representations, 2020. Preprint– AnAgency-TransferringModel-FreePolicyEnhancementTechnique23 URLhttps://openreview.net/forum?id= r1etN1rtPB
2020
-
[7]
Raffin, A
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, N. Dormann, Stable-baselines3: Reliable reinforcement learning implementations, Journal of Machine Learning Research 22 (268) (2021) 1–8
2021
-
[8]
Huang, R
S. Huang, R. F. J. Dossa, C. Ye, J. Braga, D. Chakraborty, K. Mehta, J. G. Ara ´ujo, Cleanrl: High-quality single- file implementations of deep reinforcement learning algo- rithms, Journal of Machine Learning Research 23 (274) (2022) 1–18
2022
-
[9]
Eimer, M
T. Eimer, M. Lindauer, R. Raileanu, Hyperparameters in reinforcement learning and how to tune them, in: Pro- ceedings of the 40th International Conference on Machine Learning (ICML), V ol. 202, PMLR, 2023, pp. 14811– 14835
2023
-
[10]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, S. Levine, Soft actor- critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor, in: Proceedings of the 35th International Conference on Machine Learning (ICML), V ol. 80 of Proceedings of Machine Learning Re- search, 2018, pp. 1861–1870
2018
-
[11]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, O. Klimov, Proximal policy optimization algorithms., CoRR abs/1707.06347 (2017). URLhttp://dblp.uni-trier.de/db/journals/ corr/corr1707.html#SchulmanWDRK17
Pith/arXiv arXiv 2017
-
[12]
Fujimoto, H
S. Fujimoto, H. van Hoof, D. Meger, Addressing func- tion approximation error in actor-critic methods, in: Pro- ceedings of the 35th International Conference on Machine Learning (ICML), V ol. 80 of Proceedings of Machine Learning Research, 2018, pp. 1587–1596
2018
-
[13]
T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, S. Levine, Residual reinforcement learning for robot control (2018).arXiv: 1812.03201. URLhttps://arxiv.org/abs/1812.03201
Pith/arXiv arXiv 2018
-
[14]
T. Silver, K. Allen, J. Tenenbaum, L. Kaelbling, Residual policy learning (2019).arXiv:1812.06298. URLhttps://arxiv.org/abs/1812.06298
Pith/arXiv arXiv 2019
-
[15]
M. Alakuijala, G. Dulac-Arnold, J. Mairal, J. Ponce, C. Schmid, Residual reinforcement learning from demon- strations (2021).arXiv:2106.08050. URLhttps://arxiv.org/abs/2106.08050
arXiv 2021
-
[16]
Z. Sheng, Z. Huang, S. Chen, Traffic expertise meets residual rl: Knowledge-informed model-based residual reinforcement learning for cav trajectory control, Com- munications in Transportation Research 4 (2024) 100142. doi:10.1016/j.commtr.2024.100142
-
[17]
Baker, I
B. Baker, I. Akkaya, P. Zhokov, J. Huizinga, J. Tang, A. Ecoffet, B. Houghton, R. Sampedro, J. Clune, Video pretraining (VPT): Learning to act by watching unlabeled online videos, in: Advances in Neural Information Pro- cessing Systems, V ol. 35, 2022
2022
-
[18]
J. Ho, S. Ermon, Generative adversarial imitation learn- ing, in: Advances in Neural Information Processing Sys- tems 29 (NeurIPS), 2016, pp. 4565–4573
2016
-
[19]
Hester, M
T. Hester, M. Vecer´ık, O. Pietquin, M. Lanctot, T. Schaul, B. Piot, D. Horgan, J. Quan, A. Sendonaris, I. Osband, G. Dulac-Arnold, J. Agapiou, J. Z. Leibo, A. Gruslys, Deep q-learning from demonstrations, in: Proceedings of the 32nd AAAI Conference on Artificial Intelligence, 2018, pp. 3223–3230
2018
-
[20]
Rajeswaran, V
A. Rajeswaran, V . Kumar, A. Gupta, G. Vezzani, J. Schul- man, E. Todorov, S. Levine, Learning complex dex- terous manipulation with deep reinforcement learning and demonstrations, in: Robotics: Science and Systems (RSS), 2018
2018
-
[21]
Garc ´ıa, F
J. Garc ´ıa, F. Fern´andez, A comprehensive survey on safe reinforcement learning, Journal of Machine Learning Research 16 (42) (2015) 1437–1480. URLhttps://jmlr.org/papers/v16/garcia15a. html
2015
-
[22]
Achiam, D
J. Achiam, D. Held, A. Tamar, P. Abbeel, Constrained pol- icy optimization, in: Proceedings of the 34th International Conference on Machine Learning (ICML), 2017, pp. 22– 31
2017
-
[23]
Y . Chow, O. Nachum, E. Duenez-Guzman, M. Ghavamzadeh, A lyapunov-based approach to safe reinforcement learning, in: Advances in Neural Information Processing Systems (NeurIPS), V ol. 31, 2018, pp. 8092–8101.arXiv:1805.07708, doi:10.48550/arXiv.1805.07708. URLhttps://papers.nips.cc/ paper_files/paper/2018/hash/ 4fe5149039b52765bde64beb9f674940-Abstract. html
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1805.07708 2018
-
[24]
Alshiekh, R
M. Alshiekh, R. Bloem, R. Ehlers, B. K ¨onighofer, S. Niekum, U. Topcu, Safe reinforcement learning via shielding, in: Proceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI), 2018, pp. 2669–2678
2018
-
[25]
A. D. Ames, X. Xu, J. W. Grizzle, P. Tabuada, Control barrier function based quadratic programs for safety critical systems, IEEE Transactions on Automatic Con- trol 62 (8) (2017) 3861–3876.arXiv:1609.06408, doi:10.1109/TAC.2016.2638961. URLhttps://doi.org/10.1109/TAC.2016. 2638961
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/tac.2016.2638961 2017
-
[26]
D. Liberzon, Switching in Systems and Control, Sys- tems & Control: Foundations & Applications, Birkh¨auser Boston, 2003.doi:10.1007/978-1-4612-0017-8. URLhttps://link.springer.com/book/10.1007/ 978-1-4612-0017-8
-
[27]
M. S. Branicky, Multiple lyapunov functions and other analysis tools for switched and hybrid systems, IEEE Transactions on Automatic Control 43 (4) (1998) 475– 482.doi:10.1109/9.664150. URLhttps://doi.org/10.1109/9.664150
-
[28]
H. Bharadhwaj, A. Kumar, N. Rhinehart, S. Levine, F. Shkurti, A. Garg, Conservative safety critics for exploration, in: International Conference on Learning Representations (ICLR), 2021.arXiv:2010.14497, doi:10.48550/arXiv.2010.14497. URLhttps://openreview.net/forum?id= iaO86DUuKi Preprint– AnAgency-TransferringModel-FreePolicyEnhancementTechnique24
-
[29]
G. Dalal, K. Dvijotham, M. Vecerik, T. Hester, C. Padu- raru, Y . Tassa, Safe exploration in continuous action spaces, CoRR abs/1801.08757 (2018).doi:10.48550/ arXiv.1801.08757. URLhttps://arxiv.org/abs/1801.08757
Pith/arXiv arXiv 2018
-
[30]
A. S. Morse, Supervisory control of families of linear set- point controllers—part i: Exact matching, IEEE Transac- tions on Automatic Control 41 (10) (1996) 1413–1431. doi:10.1109/9.539424. URLhttps://doi.org/10.1109/9.539424
-
[31]
A. S. Morse, Supervisory control of families of linear set- point controllers—part ii: Robustness, IEEE Transactions on Automatic Control 42 (11) (1997) 1500–1515.doi: 10.1109/9.649687. URLhttps://doi.org/10.1109/9.649687
-
[32]
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, D. Wierstra, Continuous control with deep reinforcement learning, in: Proceedings of the 4th International Conference on Learning Representations (ICLR), 2016, arXiv:1509.02971
Pith/arXiv arXiv 2016
-
[33]
H. K. Khalil, Nonlinear Systems, 3rd Edition, Prentice Hall, 2002
2002
-
[34]
E. D. Sontag, Comments on integral variants of ISS, Sys- tems and Control Letters 34 (1-2) (1998) 93–100.doi: 10.1016/S0167-6911(98)00007-1
-
[35]
Billingsley, Probability and Measure, 3rd Edition, John Wiley & Sons, 1995
P. Billingsley, Probability and Measure, 3rd Edition, John Wiley & Sons, 1995
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.