GHOST: Hierarchical Sub-Goal Policies for Generalizing Robot Manipulation
Pith reviewed 2026-06-27 16:08 UTC · model grok-4.3
The pith
GHOST factorizes robot manipulation into a high-level 3D sub-goal predictor from RGB-D images and a low-level controller to improve generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
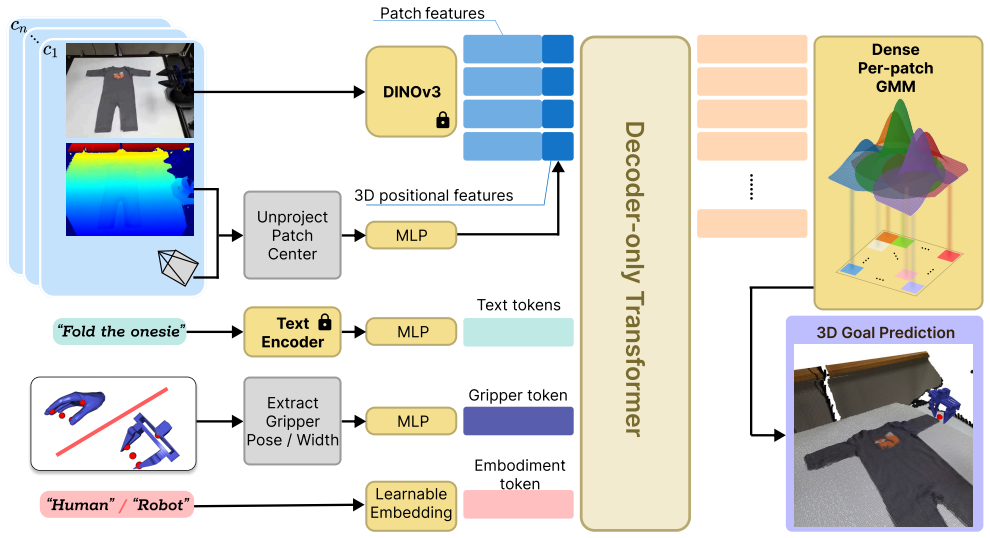
Factorizing control into a high-level policy that predicts the next sub-goal as a distribution over 3D end-effector poses from multi-view RGB-D observations and a low-level goal-conditioned controller that executes embodiment-specific actions improves performance and robustness over flat Diffusion Policies. The same interface lets the high-level policy train on human video without action retargeting because sub-goals remain largely embodiment-agnostic, so the combined system adapts to novel objects and task variations from a small number of human demonstrations.
What carries the argument
Hierarchical split into high-level sub-goal predictor (distribution over 3D poses) and low-level controller, conditioned via projected end-effector heatmaps in the image plane.
If this is right
- The hierarchical split raises success rate and robustness over a flat Diffusion Policy on the tested manipulation tasks.
- Human video can supply the high-level policy while the low-level policy stays trained only on robot demonstrations.
- The system adapts to new objects and task changes after seeing only a small number of human demonstrations.
- The spatial projection of 3D goals into image heatmaps lets image-based policies condition on those goals without additional machinery.
Where Pith is reading between the lines
- The same split could be tested on tasks where the high-level plan involves longer sequences or multiple objects.
- If sub-goal distributions prove stable across embodiments, the approach could reduce the amount of robot-specific data needed for new hardware.
- Adding a third level that predicts sequences of sub-goals might further cut the number of demonstrations required for new tasks.
Load-bearing premise
Sub-goals expressed as 3D end-effector poses are largely independent of the specific robot body so that a high-level policy trained on human video can pair with a low-level policy trained only on robot data.
What would settle it
Train a high-level policy on human video and pair it with a robot low-level policy on the same tasks; measure whether success rate drops below the rate achieved when both levels train on robot data alone.
Figures






read the original abstract
We present GHOST, a framework for learning visuomotor manipulation policies that generalize beyond the training distribution. GHOST factorizes control into (i) a high-level policy that predicts the next sub-goal as a distribution over 3D end-effector poses from multi-view RGB-D observations, and (ii) a low-level goal-conditioned controller that executes embodiment-specific actions. To condition image-based policies on 3D goals, we introduce a simple spatial interface that projects predicted goals into the image plane and represents them as end-effector heatmaps. Across a suite of manipulation tasks, this hierarchical factorization consistently improves performance and robustness compared to a flat Diffusion Policy. Further, we show that this hierarchical interface also makes it easy to incorporate human demonstrations without relying on (noisy) action retargeting. As sub-goals are largely embodiment-agnostic, we train the high-level policy on human video to specify how learned skills should be applied and composed, while keeping the low-level policy trained purely on robot data. This hierarchy enables adaptation to novel objects and task variations using a small number of human demonstrations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GHOST, a hierarchical framework for learning visuomotor manipulation policies. It factorizes the policy into a high-level component that predicts distributions over 3D end-effector poses as sub-goals from multi-view RGB-D observations and a low-level goal-conditioned controller that executes embodiment-specific actions. A spatial interface projects the 3D goals into image-plane heatmaps. The approach is shown to improve performance and robustness over flat Diffusion Policies and to facilitate the use of human demonstrations for the high-level policy while keeping the low-level policy on robot data, enabling adaptation to novel objects and task variations with few human demos.
Significance. If the empirical results hold, this work could be significant for robot learning by enabling better generalization through hierarchical factorization and easier integration of human video data without action retargeting. The spatial projection interface is a simple contribution that addresses embodiment differences between human and robot data.
major comments (2)
- [Abstract and §4 Experiments] The abstract asserts consistent improvement over Diffusion Policy but supplies no quantitative results, error bars, task details, or ablation data. The full paper must provide these (including specific tasks, metrics, and comparisons) to support the central claim of improved performance and robustness.
- [§3 Method and §4.3 Human Demonstration Experiments] The premise that sub-goals are largely embodiment-agnostic, allowing the high-level policy trained on human multi-view RGB-D video to be combined with a low-level policy trained only on robot data, lacks direct validation. A comparison of 3D end-effector pose distributions and execution success rates (with and without the human-trained high-level policy) is needed to rule out distribution shift or kinematic mismatch induced by the spatial projection interface.
minor comments (1)
- [§3.2 Spatial Interface] Clarify the precise mathematical form of the spatial interface, including how 3D poses are projected to heatmaps and any parameters involved in the projection.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §4 Experiments] The abstract asserts consistent improvement over Diffusion Policy but supplies no quantitative results, error bars, task details, or ablation data. The full paper must provide these (including specific tasks, metrics, and comparisons) to support the central claim of improved performance and robustness.
Authors: Section 4 of the manuscript already contains the requested quantitative results, including task descriptions, metrics, comparisons to Diffusion Policy baselines, error bars, and ablations. To better support the central claims in the abstract itself, we will revise the abstract to incorporate key quantitative findings from the experiments. revision: yes
-
Referee: [§3 Method and §4.3 Human Demonstration Experiments] The premise that sub-goals are largely embodiment-agnostic, allowing the high-level policy trained on human multi-view RGB-D video to be combined with a low-level policy trained only on robot data, lacks direct validation. A comparison of 3D end-effector pose distributions and execution success rates (with and without the human-trained high-level policy) is needed to rule out distribution shift or kinematic mismatch induced by the spatial projection interface.
Authors: Section 4.3 reports end-to-end task success rates demonstrating effective combination of the human-trained high-level policy with the robot low-level controller. We agree that explicit analysis of 3D pose distributions would provide stronger direct validation of the embodiment-agnostic assumption. We will add comparisons of predicted 3D sub-goal distributions (human vs. robot) and associated execution metrics in the revised version. revision: partial
Circularity Check
No circularity: empirical hierarchy claims rest on performance comparisons, not derivations or self-referential fits
full rationale
The paper describes a hierarchical policy factorization (high-level 3D sub-goal prediction from RGB-D, low-level goal-conditioned controller) and reports empirical gains over flat Diffusion Policy plus human-video transfer. No equations, fitted parameters renamed as predictions, uniqueness theorems, or ansatzes appear in the provided text. Claims are validated via task-suite experiments rather than reducing to inputs by construction. The embodiment-agnostic premise is an assumption tested empirically, not a self-definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Track2act: Predicting point tracks from internet videos enables diverse zero- shot robot manipulation.CoRR, 2024
Homanga Bharadhwaj, Roozbeh Mottaghi, Abhinav Gupta, and Shubham Tulsiani. Track2act: Predicting point tracks from internet videos enables diverse zero- shot robot manipulation.CoRR, 2024
2024
-
[2]
arXiv preprint arXiv:2410.24164, 2024
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A vision- language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[3]
Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Anthony Brohan, Noah Brown, Justice Carbajal, Yev- gen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[4]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[5]
Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping H...
2024
-
[6]
Amplify: Actionless motion priors for robot learning from videos
Jeremy A Collins, Lor ´and Cheng, Kunal Aneja, Albert Wilcox, Benjamin Joffe, and Animesh Garg. Amplify: Actionless motion priors for robot learning from videos. arXiv preprint arXiv:2506.14198, 2025
arXiv 2025
-
[7]
Vision transformers need registers,
Timoth ´ee Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers,
-
[8]
URL https://arxiv.org/abs/2309.16588
-
[9]
The” something something” video database for learning and evaluating visual common sense
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michal- ski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The” something something” video database for learning and evaluating visual common sense. InProceedings of the IEEE international con- ference on computer vision, pages 5842...
2017
-
[10]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jack- son Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18995– 19012, 2022
2022
-
[11]
Siddhant Haldar and Lerrel Pinto. Point policy: Unify- ing observations and actions with key points for robot manipulation.arXiv preprint arXiv:2502.20391, 2025
arXiv 2025
-
[12]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[13]
Haian Jin, Hanwen Jiang, Hao Tan, Kai Zhang, Sai Bi, Tianyuan Zhang, Fujun Luan, Noah Snavely, and Zexiang Xu. Lvsm: A large view synthesis model with minimal 3d inductive bias.arXiv preprint arXiv:2410.17242, 2024
arXiv 2024
-
[14]
Egomimic: Scaling imitation learning via egocentric video
Simar Kareer, Dhruv Patel, Ryan Punamiya, Pranay Mathur, Shuo Cheng, Chen Wang, Judy Hoffman, and Danfei Xu. Egomimic: Scaling imitation learning via egocentric video. In2025 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 13226– 13233. IEEE, 2025
2025
-
[15]
Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ash- win Balakrishna, Sudeep Dasari, Siddharth Karam- cheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[16]
Marion Lepert, Jiaying Fang, and Jeannette Bohg. Phan- tom: Training robots without robots using only human videos.arXiv preprint arXiv:2503.00779, 2025
Pith/arXiv arXiv 2025
-
[17]
Learning latent plans from play
Corey Lynch, Mohi Khansari, Ted Xiao, Vikash Kumar, Jonathan Tompson, Sergey Levine, and Pierre Sermanet. Learning latent plans from play. InConference on robot learning, pages 1113–1132. Pmlr, 2020
2020
-
[18]
Learning to generalize across long-horizon tasks from human demonstrations
Ajay Mandlekar, Danfei Xu, Roberto Mart ´ın-Mart´ın, Silvio Savarese, and Li Fei-Fei. Learning to generalize across long-horizon tasks from human demonstrations. arXiv preprint arXiv:2003.06085, 2020
arXiv 2003
-
[19]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Ab- hishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[20]
Reconstructing hands in 3d with transformers
Georgios Pavlakos, Dandan Shan, Ilija Radosavovic, Angjoo Kanazawa, David Fouhey, and Jitendra Malik. Reconstructing hands in 3d with transformers. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9826–9836, 2024
2024
-
[21]
Long-horizon visual planning with goal- conditioned hierarchical predictors.Advances in Neural Information Processing Systems, 33:17321–17333, 2020
Karl Pertsch, Oleh Rybkin, Frederik Ebert, Shenghao Zhou, Dinesh Jayaraman, Chelsea Finn, and Sergey Levine. Long-horizon visual planning with goal- conditioned hierarchical predictors.Advances in Neural Information Processing Systems, 33:17321–17333, 2020
2020
-
[22]
Wilor: End-to-end 3d hand localization and reconstruction in-the-wild
Rolandos Alexandros Potamias, Jinglei Zhang, Jiankang Deng, and Stefanos Zafeiriou. Wilor: End-to-end 3d hand localization and reconstruction in-the-wild. InProceed- ings of the Computer Vision and Pattern Recognition Conference, pages 12242–12254, 2025
2025
-
[23]
Juntao Ren, Priya Sundaresan, Dorsa Sadigh, Sanjiban Choudhury, and Jeannette Bohg. Motion tracks: A unified representation for human-robot transfer in few- shot imitation learning.arXiv preprint arXiv:2501.06994, 2025
arXiv 2025
-
[24]
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kun- chang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open- world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024
Pith/arXiv arXiv 2024
-
[25]
Javier Romero, Dimitrios Tzionas, and Michael J. Black. Embodied hands: Modeling and capturing hands and bodies together.ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 36(6), November 2017
2017
-
[26]
Oriane Sim ´eoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khali- dov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamon- jisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth ´ee Darcet, Th ´eo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Co...
Pith/arXiv arXiv 2025
-
[27]
A careful examina- tion of large behavior models for multitask dexterous ma- nipulation
TRI LBM Team, Jose Barreiros, Andrew Beaulieu, Aditya Bhat, Rick Cory, Eric Cousineau, Hongkai Dai, Ching-Hsin Fang, Kunimatsu Hashimoto, Muham- mad Zubair Irshad, Masha Itkina, Naveen Kuppuswamy, Kuan-Hui Lee, Katherine Liu, Dale McConachie, Ian McMahon, Haruki Nishimura, Calder Phillips-Grafflin, Charles Richter, Paarth Shah, Krishnan Srinivasan, Blake ...
Pith/arXiv arXiv 2025
-
[28]
Chen Wang, Linxi Fan, Jiankai Sun, Ruohan Zhang, Li Fei-Fei, Danfei Xu, Yuke Zhu, and Anima Anand- kumar. Mimicplay: Long-horizon imitation learning by watching human play.arXiv preprint arXiv:2302.12422, 2023
arXiv 2023
-
[29]
Articubot: Learning universal articulated object manipulation policy via large scale simulation
Yufei Wang, Ziyu Wang, Mino Nakura, Pratik Bhowal, Chia-Liang Kuo, Yi-Ting Chen, Zackory Erickson, and David Held. Articubot: Learning universal articulated object manipulation policy via large scale simulation. arXiv preprint arXiv:2503.03045, 2025
arXiv 2025
-
[30]
Any-point trajec- tory modeling for policy learning.arXiv preprint arXiv:2401.00025, 2023
Chuan Wen, Xingyu Lin, John So, Kai Chen, Qi Dou, Yang Gao, and Pieter Abbeel. Any-point trajec- tory modeling for policy learning.arXiv preprint arXiv:2401.00025, 2023
Pith/arXiv arXiv 2023
-
[31]
Neural task programming: Learning to generalize across hierarchical tasks
Danfei Xu, Suraj Nair, Yuke Zhu, Julian Gao, Animesh Garg, Li Fei-Fei, and Silvio Savarese. Neural task programming: Learning to generalize across hierarchical tasks. In2018 IEEE international conference on robotics and automation (ICRA), pages 3795–3802. IEEE, 2018
2018
-
[32]
La- tent action pretraining from videos.arXiv preprint arXiv:2410.11758, 2024
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, et al. La- tent action pretraining from videos.arXiv preprint arXiv:2410.11758, 2024
Pith/arXiv arXiv 2024
-
[33]
Predicting 4d hand trajectory from monocular videos.arXiv preprint arXiv:2501.08329, 2025
Yufei Ye, Yao Feng, Omid Taheri, Haiwen Feng, Shub- ham Tulsiani, and Michael J Black. Predicting 4d hand trajectory from monocular videos.arXiv preprint arXiv:2501.08329, 2025
arXiv 2025
-
[34]
Sigmoid loss for language image pre- training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[35]
Universal visual decomposer: Long-horizon manipulation made easy
Zichen Zhang, Yunshuang Li, Osbert Bastani, Abhishek Gupta, Dinesh Jayaraman, Yecheng Jason Ma, and Luca Weihs. Universal visual decomposer: Long-horizon manipulation made easy. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6973–6980. IEEE, 2024
2024
-
[36]
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
-
[37]
On the continuity of rotation representations in neural networks
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representations in neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5745–5753, 2019. APPENDIXA IMPLEMENTATIONDETAILS A. High-Level Policy The high-level policy uses a decoder-only transformer op- erating on...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.