Supervised Fine-tuning with Synthetic Rationale Data Hurts Real-World Disease Prediction
Pith reviewed 2026-06-27 13:47 UTC · model grok-4.3
The pith
Training language models on synthetic rationales for disease prediction reduces accuracy compared to label-only fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
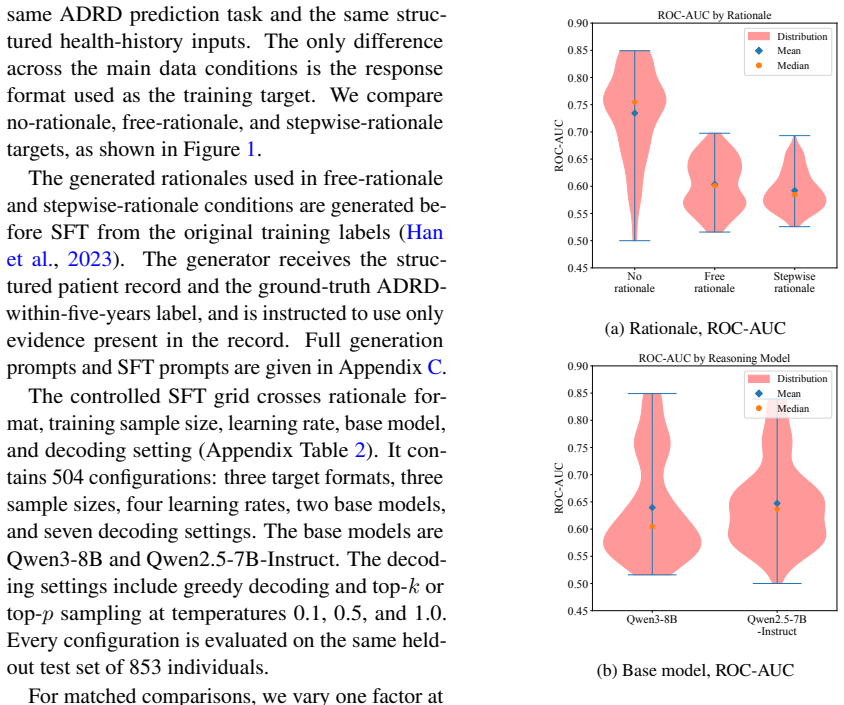
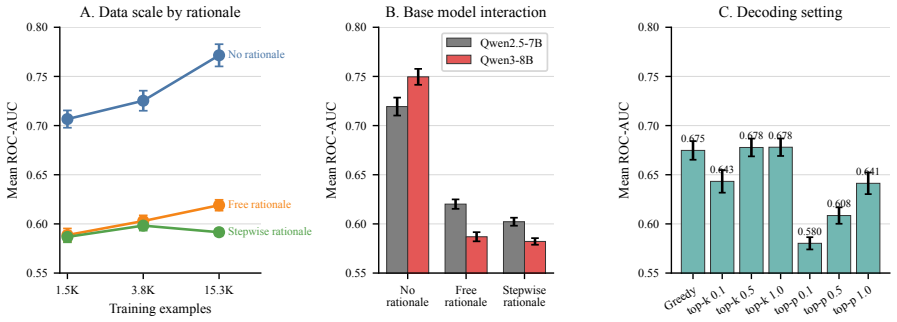
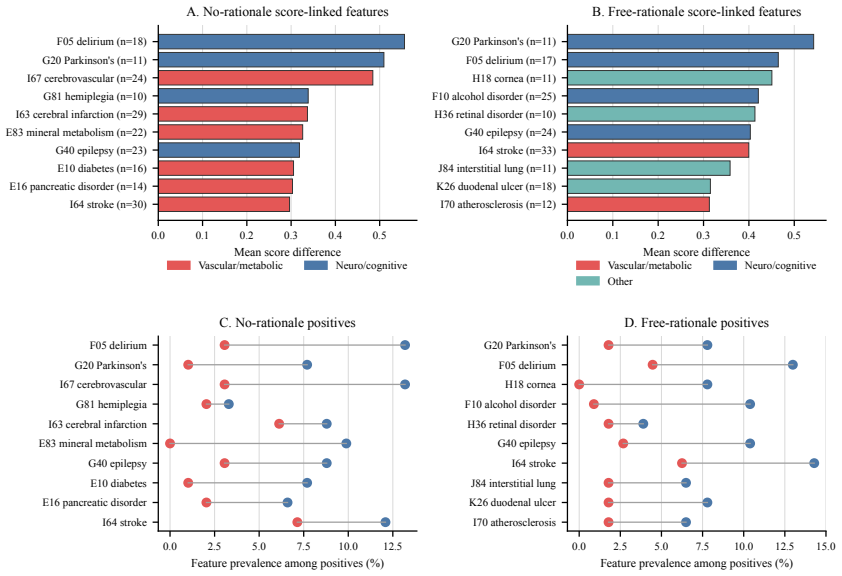
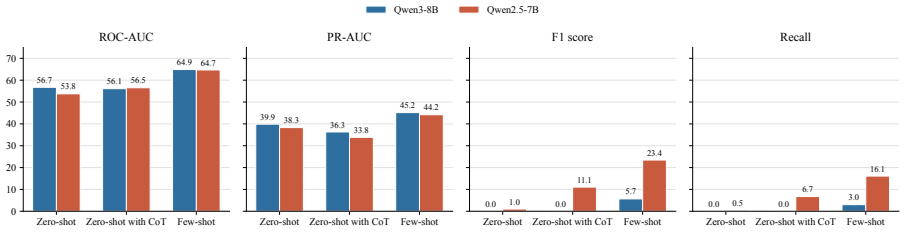
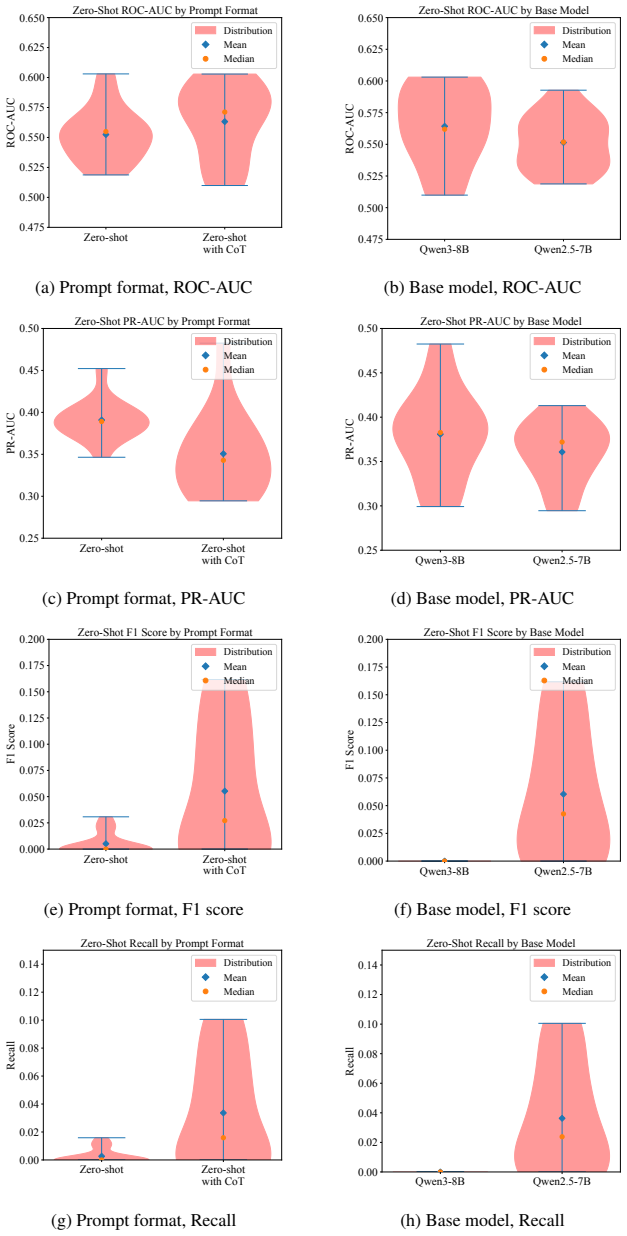
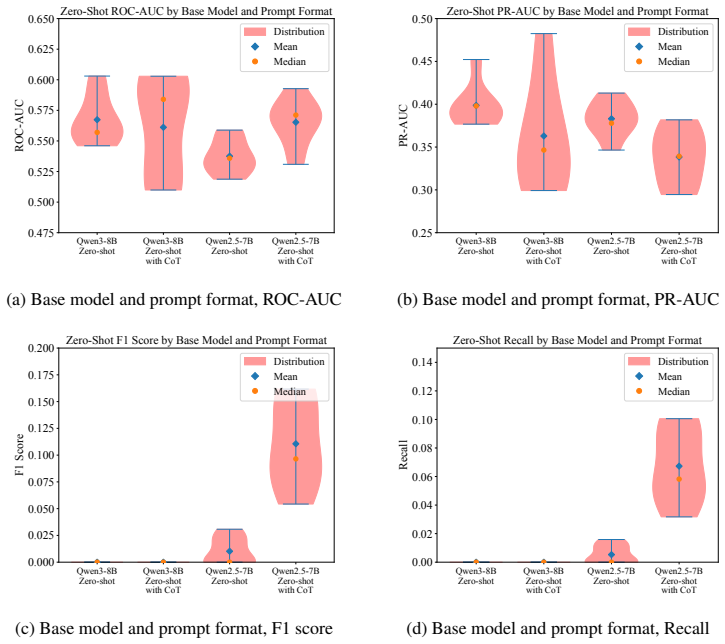
Across a controlled experiment spanning 504 configurations on ADRD prediction from health histories, rationale-based supervised fine-tuning consistently and substantially reduced prediction performance relative to label-only fine-tuning. The degradation persisted across model families and data scales and was not fixed by selecting a reasoning-oriented base model. Human experts verified that the generated rationales were medically accurate and faithfully grounded in patient-specific evidence. The same rationales improved results when supplied as inference-time demonstrations but not when used as training targets. The root cause is identified as a structural conflict between narrative plausibi
What carries the argument
The structural conflict between narrative plausibility and discriminative optimization
If this is right
- Label-only fine-tuning should be preferred over rationale-augmented training when the goal is maximum accuracy on clinical prediction tasks.
- Few-shot presentation of rationales at inference time remains a viable way to leverage explanations without incurring the training penalty.
- The negative effect on performance is not mitigated by switching to reasoning-oriented base models.
- The pattern holds across multiple model families and across different scales of training data.
- Rationale supervision introduces a training dynamic that trades narrative coherence for reduced discriminative power.
Where Pith is reading between the lines
- The same tension may appear in other prediction settings that require precise pattern detection rather than story-like justification.
- Training pipelines could separate rationale generation into a distinct stage that does not back-propagate into the main prediction parameters.
- The finding suggests testing whether the conflict reverses on tasks where narrative structure itself carries predictive value.
- Results on this specific health dataset motivate direct replication on non-health longitudinal prediction problems to isolate domain effects.
Load-bearing premise
That the observed performance drop arises from an inherent tension between narrative and discriminative objectives rather than from particulars of this dataset or training procedure.
What would settle it
An experiment on a different longitudinal clinical prediction task, such as onset of a non-neurological condition from electronic health records, in which rationale-based fine-tuning matches or exceeds label-only performance would falsify the claimed generality of the conflict.
Figures

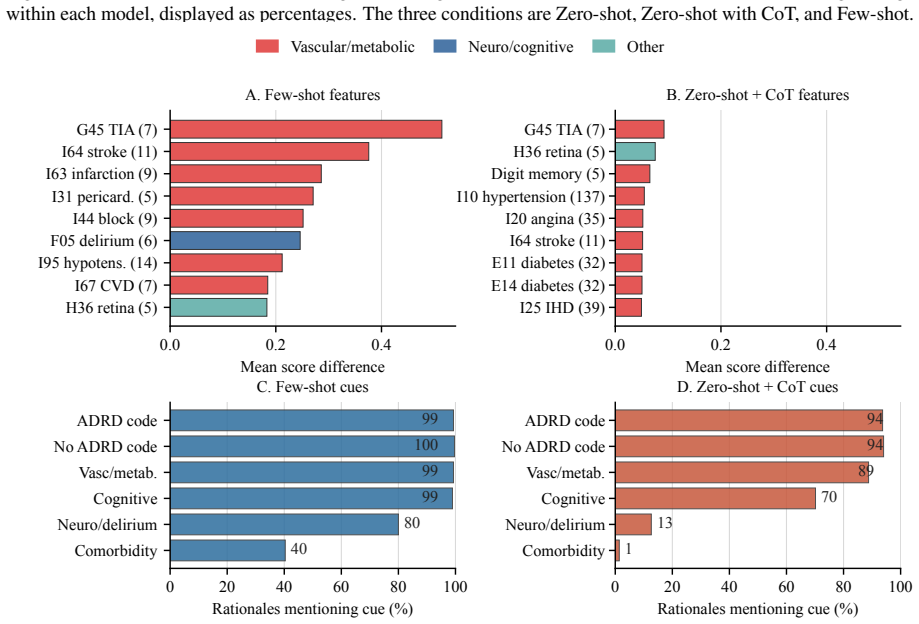
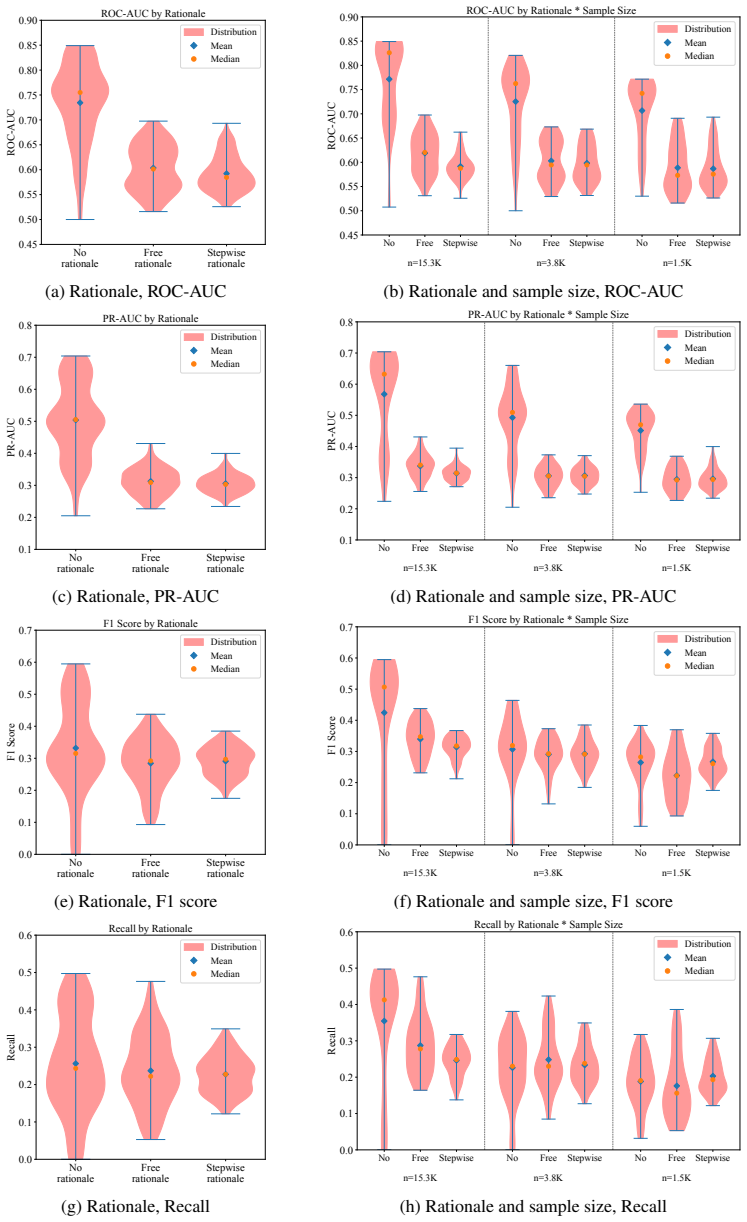
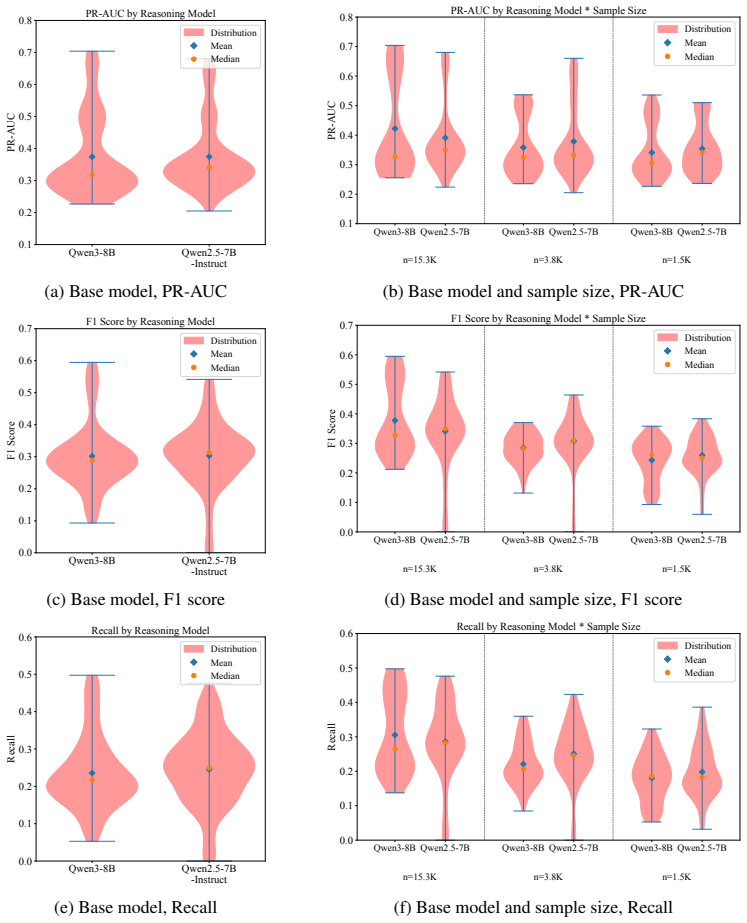
read the original abstract
Supervised fine-tuning with synthetic rationale data is widely assumed to improve language model performance on clinical prediction tasks by teaching models not just what to predict but why. We test this assumption on five-year Alzheimer's disease and related dementias (ADRD) prediction from longitudinal health histories. Across a large-scale controlled experiment of 504 configurations, we find that rationale-based SFT consistently and substantially hurts prediction performance relative to label-only fine-tuning. The degradation persists across model families and data scales, and is not resolved by using a reasoning-oriented base model. Crucially, the failure is not explained by poor rationale quality: human expert annotation confirms that the generated rationales are medically accurate and faithfully grounded in patient-specific evidence, and few-shot experiments show that the same rationales improve performance when used as inference-time demonstrations rather than training targets. We identify the root cause as a structural conflict between narrative plausibility and discriminative optimization. We hope our work paves the path toward a more precise understanding of when and how rationale-based supervision helps and when it does not, guiding the responsible development of language models for high-stakes clinical prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a large-scale empirical study (504 configurations) on five-year ADRD prediction from longitudinal health records. It finds that supervised fine-tuning on synthetic rationales consistently and substantially degrades predictive performance relative to label-only fine-tuning, across model families and data scales. Human expert review confirms the rationales are medically accurate and evidence-grounded; the same rationales improve performance in few-shot inference. The authors attribute the degradation to an inherent structural conflict between narrative plausibility and discriminative optimization, and conclude that rationale-based SFT should be used with caution in high-stakes clinical prediction.
Significance. If the core empirical result holds, the work provides a clear counter-example to the common assumption that rationale supervision improves clinical prediction models. The scale of the controlled experiment, the human validation of rationale quality, and the explicit contrast with few-shot inference are notable strengths that make the negative finding credible within the tested setting. The result would usefully constrain expectations for chain-of-thought-style supervision in discriminative medical tasks and motivate more targeted investigation of when rationale data helps versus harms.
major comments (3)
- [§5 and §4.2] §5 (Discussion) and §4.2 (Ablation results): The root-cause claim of a 'structural conflict between narrative plausibility and discriminative optimization' is presented as the explanation, yet the manuscript does not report ablations that isolate this mechanism from plausible alternatives such as increased sequence length altering gradient weighting, shifted next-token loss distribution, or format-induced output bias. Without such controls, the interpretive attribution remains under-supported relative to the strength of the empirical degradation result.
- [§3 and Table 1] §3 (Experimental setup) and Table 1: The study is restricted to a single longitudinal ADRD dataset. While the 504-configuration sweep is extensive within this domain, the manuscript does not discuss or test whether the observed degradation pattern transfers to other clinical prediction tasks (e.g., shorter-horizon outcomes or tasks where narrative and discriminative objectives may align more closely). This limits the scope of the central claim.
- [§4.1] §4.1 (Main results): The performance degradation is reported as 'consistent and substantial,' but the text does not include per-configuration variance, confidence intervals, or statistical significance tests across the 504 runs. Adding these would strengthen the claim that the effect is robust rather than driven by a subset of configurations.
minor comments (2)
- [Figures 2 and 3] Figure 2 and 3: Axis labels and legend entries use inconsistent abbreviations for model families; standardize notation to match the text in §4.
- [§2] §2 (Related work): The citation to prior rationale-SFT studies in medicine could be expanded to include recent negative or null results on rationale supervision outside the clinical domain for balance.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important areas for strengthening the interpretation and scope of our findings. We address each major comment below and will incorporate revisions as noted.
read point-by-point responses
-
Referee: [§5 and §4.2] §5 (Discussion) and §4.2 (Ablation results): The root-cause claim of a 'structural conflict between narrative plausibility and discriminative optimization' is presented as the explanation, yet the manuscript does not report ablations that isolate this mechanism from plausible alternatives such as increased sequence length altering gradient weighting, shifted next-token loss distribution, or format-induced output bias. Without such controls, the interpretive attribution remains under-supported relative to the strength of the empirical degradation result.
Authors: We agree that isolating the proposed mechanism from alternatives would strengthen the interpretation. The existing few-shot experiments already provide evidence against format-induced bias, as the identical rationales improve performance when used as inference-time demonstrations rather than SFT targets. To further address sequence length and loss distribution effects, we will add controlled ablations in a revised §4.2 (e.g., padding label-only sequences to match rationale lengths and comparing loss distributions), along with expanded discussion in §5. These additions will better support the attribution while acknowledging remaining alternatives. revision: yes
-
Referee: [§3 and Table 1] §3 (Experimental setup) and Table 1: The study is restricted to a single longitudinal ADRD dataset. While the 504-configuration sweep is extensive within this domain, the manuscript does not discuss or test whether the observed degradation pattern transfers to other clinical prediction tasks (e.g., shorter-horizon outcomes or tasks where narrative and discriminative objectives may align more closely). This limits the scope of the central claim.
Authors: We acknowledge this limitation on generalizability. In the revision, we will expand the discussion in §3 to justify the choice of five-year ADRD prediction as a canonical high-stakes task where narrative plausibility can conflict with discriminative needs, and add an explicit limitations paragraph noting that transfer to other tasks (such as shorter-horizon outcomes) is an important direction for future work. This will appropriately scope the central claim without overgeneralization. revision: yes
-
Referee: [§4.1] §4.1 (Main results): The performance degradation is reported as 'consistent and substantial,' but the text does not include per-configuration variance, confidence intervals, or statistical significance tests across the 504 runs. Adding these would strengthen the claim that the effect is robust rather than driven by a subset of configurations.
Authors: We agree that statistical characterization would strengthen the robustness claim. In the revised manuscript, we will augment §4.1 (and associated tables/figures) with per-configuration standard deviations, bootstrap confidence intervals on the performance deltas, and paired statistical tests (e.g., Wilcoxon signed-rank) across the 504 configurations to demonstrate that the degradation is consistent and statistically significant rather than driven by outliers. revision: yes
Circularity Check
No circularity: purely empirical experimental study
full rationale
The paper is a controlled empirical study reporting performance comparisons across 504 SFT configurations on longitudinal health data. No derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the text. Claims rest directly on measured degradation, human rationale validation, and few-shot controls rather than any chain that reduces outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2212.07919 , year=
Roscoe: A suite of metrics for scoring step-by-step reasoning , author=. arXiv preprint arXiv:2212.07919 , year=
-
[2]
arXiv preprint arXiv:2304.10703 , year=
Receval: Evaluating reasoning chains via correctness and informativeness , author=. arXiv preprint arXiv:2304.10703 , year=
-
[3]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
Socreval: Large language models with the socratic method for reference-free reasoning evaluation , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[4]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
Assessing LLM Reasoning Steps via Principal Knowledge Grounding , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
2025
-
[5]
Journal of Mathematical Psychology , volume=
The area above the ordinal dominance graph and the area below the receiver operating characteristic graph , author=. Journal of Mathematical Psychology , volume=. 1975 , doi=
1975
-
[6]
The meaning and use of the area under a receiver operating characteristic (
Hanley, James A and McNeil, Barbara J , journal=. The meaning and use of the area under a receiver operating characteristic (. 1982 , doi=
1982
-
[7]
An introduction to
Fawcett, Tom , journal=. An introduction to. 2006 , doi=
2006
-
[8]
1979 , isbn=
Information Retrieval , author=. 1979 , isbn=
1979
-
[9]
The relationship between precision-recall and
Davis, Jesse and Goadrich, Mark , booktitle=. The relationship between precision-recall and. 2006 , doi=
2006
-
[10]
The precision-recall plot is more informative than the
Saito, Takaya and Rehmsmeier, Marc , journal=. The precision-recall plot is more informative than the. 2015 , doi=
2015
-
[11]
Biometrics , volume=
Comparing the areas under two or more correlated receiver operating characteristic curves: A nonparametric approach , author=. Biometrics , volume=. 1988 , doi=
1988
-
[12]
1993 , isbn=
An Introduction to the Bootstrap , author=. 1993 , isbn=
1993
-
[13]
Scandinavian Journal of Statistics , volume=
A simple sequentially rejective multiple test procedure , author=. Scandinavian Journal of Statistics , volume=. 1979 , url=
1979
-
[14]
Journal of the Royal Statistical Society: Series B (Methodological) , volume=
Controlling the false discovery rate: A practical and powerful approach to multiple testing , author=. Journal of the Royal Statistical Society: Series B (Methodological) , volume=. 1995 , doi=
1995
-
[15]
arXiv preprint arXiv:2404.05221 , year=
Llm reasoners: New evaluation, library, and analysis of step-by-step reasoning with large language models , author=. arXiv preprint arXiv:2404.05221 , year=
-
[16]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[17]
On the impact of fine-tuning on chain-of-thought reasoning , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[18]
Nature Reviews Neurology , year=
UK Biobank at 20—a growing, global resource for dementia research , author=. Nature Reviews Neurology , year=
-
[19]
Nature Reviews Neurology , volume=
A global view of the genetic basis of Alzheimer disease , author=. Nature Reviews Neurology , volume=. 2023 , doi=
2023
-
[20]
European Heart Journal , volume=
Modifiable cardiovascular risk factors and genetics for targeted prevention of dementia , author=. European Heart Journal , volume=. 2023 , doi=
2023
-
[21]
Nature , volume=
Learning the natural history of human disease with generative transformers , author=. Nature , volume=. 2025 , doi=
2025
-
[22]
PLOS Medicine , volume=
UK Biobank: An open access resource for identifying the causes of a wide range of complex diseases of middle and old age , author=. PLOS Medicine , volume=. 2015 , doi=
2015
-
[23]
and Tejada-Vera, Betzaida , title =
Kramarow, Ellen A. and Tejada-Vera, Betzaida , title =. 2024 , howpublished =. doi:10.15620/cdc/165795 , url =
-
[24]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[25]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[26]
International Conference on Learning Representations , volume=
Let's verify step by step , author=. International Conference on Learning Representations , volume=
-
[27]
arXiv preprint arXiv:2211.12588 , year=
Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks , author=. arXiv preprint arXiv:2211.12588 , year=
-
[28]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[29]
arXiv preprint arXiv:2203.11171 , year=
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
-
[30]
Nature , volume=
The UK Biobank resource with deep phenotyping and genomic data , author=. Nature , volume=. 2018 , publisher=
2018
-
[31]
Proceedings of the AAAI conference on artificial intelligence , volume=
Large language models are clinical reasoners: Reasoning-aware diagnosis framework with prompt-generated rationales , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[32]
Niu, Shuai and Ma, Jing and Lin, Hongzhan and Bai, Liang and Wang, Zhihua and Xu, Yida and Song, Yunya and Yang, Xian. Knowledge-Augmented Multimodal Clinical Rationale Generation for Disease Diagnosis with Small Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.1...
-
[33]
International Conference on Learning Representations , volume=
Reasoning-enhanced healthcare predictions with knowledge graph community retrieval , author=. International Conference on Learning Representations , volume=
-
[34]
Song, Hoyun and Lee, Huije and Shin, Jisu and Cho, Sukmin and Ko, Changgeon and Park, Jong C. Does Rationale Quality Matter? Enhancing Mental Disorder Detection via Selective Reasoning Distillation. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1119
-
[35]
arXiv preprint arXiv:2512.20074 , year=
Reason2Decide: Rationale-Driven Multi-Task Learning , author=. arXiv preprint arXiv:2512.20074 , year=
-
[36]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Reasonmed: A 370k multi-agent generated dataset for advancing medical reasoning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[37]
arXiv preprint arXiv:2605.01474 , year=
ReMedi: Reasoner for Medical Clinical Prediction , author=. arXiv preprint arXiv:2605.01474 , year=
-
[38]
medRxiv , pages=
Large-language-model-based 10-year risk prediction of cardiovascular disease: insight from the UK biobank data , author=. medRxiv , pages=. 2023 , publisher=
2023
-
[39]
NPJ digital medicine , volume=
Small language models learn enhanced reasoning skills from medical textbooks , author=. NPJ digital medicine , volume=. 2025 , publisher=
2025
-
[40]
arXiv preprint arXiv:2501.09213 , year=
FinemedLM-o1: Enhancing medical knowledge reasoning ability of LLM from supervised fine-tuning to test-time training , author=. arXiv preprint arXiv:2501.09213 , year=
-
[41]
arXiv preprint arXiv:2412.18925 , year=
Huatuogpt-o1, towards medical complex reasoning with llms , author=. arXiv preprint arXiv:2412.18925 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.