UniDexTok: A Unified Dexterous Hand Tokenizer from Real Data
Pith reviewed 2026-06-27 13:24 UTC · model grok-4.3
The pith
A 22-DoF semantic interface lets one tokenizer turn real joint states from any dexterous hand into discrete tokens that reconstruct positions to 0.18 mm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the Unified Dexterous Hand Model maps heterogeneous dexterous-hand states into a common 22-DoF semantic interface, from which UniDexTok produces discrete tokens that reconstruct joint angles and positions at 0.16 degrees and 0.18 mm mean error, cut reconstruction error by 98.98 percent and 99.03 percent relative to the recent UniHM baseline, improve target-hand accuracy when data from other embodiments is added, and achieve strong zero-shot and few-shot performance on previously unseen hands.
What carries the argument
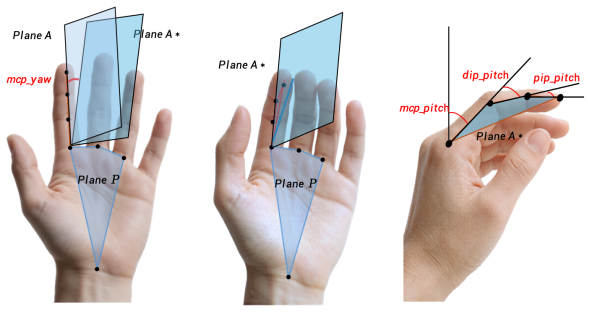
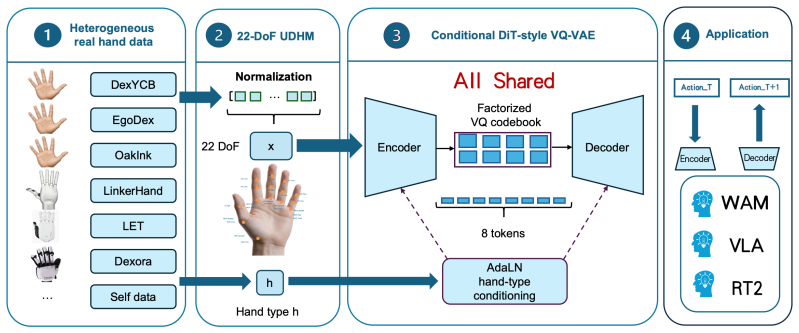
The Unified Dexterous Hand Model (UDHM), which converts varied hand kinematics into a fixed 22-DoF semantic interface that supplies standardized real joint states to the tokenizer.
If this is right
- Data collected on one hand can be mixed with data from other hands to raise reconstruction accuracy on the target hand.
- Policies or controllers trained on tokenized states can transfer across hardware without per-embodiment retargeting.
- New hand designs can be added to an existing token vocabulary with little or no additional labeled data.
- Large-scale datasets that combine many hand types become usable for joint training without custom preprocessing.
Where Pith is reading between the lines
- Tokenized hand states could serve as a common input format for vision-language-action models that must operate on varied robot hardware.
- If the 22-DoF interface proves stable, it could become a de-facto exchange format for dexterous-hand datasets across labs.
- The same tokenization approach might extend to full-body or multi-limb systems once a comparable semantic interface is defined.
Load-bearing premise
The chosen 22-DoF semantic interface captures every kinematically relevant feature of different hand designs without losing information that matters for tokenization or downstream reconstruction.
What would settle it
Reconstruction error measured on a new dexterous hand whose extra joints or non-standard kinematics lie outside the 22-DoF mapping and produce errors well above 0.18 mm.
Figures


read the original abstract
Dexterous hands are essential for fine-grained manipulation, but their hardware designs vary substantially across embodiments. Differences in kinematics, joint definitions, and degrees of freedom make it difficult to define a shared state representation compared with parallel grippers. As a result, dexterous-hand data remains fragmented and difficult to use for joint training. In this work, we propose the Unified Dexterous Hand Model (UDHM), which maps human and robot hand states into a shared 22-DoF semantic interface. Based on UDHM, we introduce UniDexTok, a retargeting-free state tokenizer that learns embodiment-conditioned discrete tokens from standardized real joint states. UniDexTok provides a unified representation for heterogeneous dexterous hands without relying on retargeting or simulation data. Compared with the recent baseline UniHM, UniDexTok reduces MPJAE from 15.63 degrees to 0.16 degrees and MPJPE from 18.51 mm to 0.18 mm, corresponding to error reductions of 98.98% and 99.03%, respectively. These results improve reconstruction from centimeter-scale to sub-millimeter accuracy. Experiments further show that data from other embodiments improves target-embodiment reconstruction accuracy, demonstrating the benefit of cross-embodiment tokenization. UniDexTok also shows strong zero-shot and few-shot reconstruction ability when new dexterous hands are introduced.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Unified Dexterous Hand Model (UDHM) to map heterogeneous human and robot hand states to a shared 22-DoF semantic interface, and introduces UniDexTok as a retargeting-free tokenizer that learns embodiment-conditioned discrete tokens directly from standardized real joint states. It claims that UniDexTok achieves 98.98% and 99.03% reductions in MPJAE and MPJPE relative to the UniHM baseline (from 15.63°/18.51 mm to 0.16°/0.18 mm), enabling cross-embodiment training benefits and strong zero-shot/few-shot reconstruction on unseen hands.
Significance. If the 22-DoF interface proves complete and the quantitative gains are reproducible, the work would provide a practical route to joint training on fragmented dexterous-hand datasets and could accelerate progress on cross-embodiment transfer in manipulation. The reported sub-millimeter accuracy would constitute a substantial empirical advance over prior retargeting-based approaches.
major comments (2)
- [Abstract] Abstract: The headline error reductions (MPJAE to 0.16°, MPJPE to 0.18 mm) and all downstream claims (cross-embodiment improvement, zero-shot/few-shot) rest on the premise that the 22-DoF UDHM interface is kinematically complete and lossless for every tested embodiment. No quantitative validation (e.g., reconstruction error of original joint angles or end-effector poses before vs. after mapping) is supplied to confirm that coupled joints, embodiment-specific constraints, or non-bijective mappings are not discarded.
- [Abstract] Abstract: The MPJAE/MPJPE metrics are reported after mapping into the 22-DoF space; without an accompanying evaluation of reconstruction fidelity back to each source embodiment’s native kinematics, it is impossible to determine whether the tokenizer recovers the original hand configuration or merely a projection onto the chosen interface.
minor comments (2)
- [Abstract] Abstract: The number of distinct embodiments used for training and the exact train/test splits are not stated, making it difficult to assess the scale of the cross-embodiment experiments.
- [Abstract] Abstract: The baseline UniHM is referenced without a citation or brief description of its architecture, which would help readers situate the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the validation of the 22-DoF UDHM interface. The comments correctly identify that the abstract and current manuscript lack explicit quantitative round-trip reconstruction metrics from the standardized space back to native embodiment kinematics. We address each point below and will incorporate the requested evaluations in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline error reductions (MPJAE to 0.16°, MPJPE to 0.18 mm) and all downstream claims (cross-embodiment improvement, zero-shot/few-shot) rest on the premise that the 22-DoF UDHM interface is kinematically complete and lossless for every tested embodiment. No quantitative validation (e.g., reconstruction error of original joint angles or end-effector poses before vs. after mapping) is supplied to confirm that coupled joints, embodiment-specific constraints, or non-bijective mappings are not discarded.
Authors: We agree that the current manuscript does not provide explicit quantitative validation of reconstruction fidelity from the 22-DoF space back to each source embodiment's native joint angles or end-effector poses. Section 3.1 describes the semantic mapping rules, but additional metrics are needed to confirm preservation of coupled joints and constraints. In the revised manuscript we will add a new table (and corresponding text in Section 4) reporting per-embodiment round-trip errors (original → 22-DoF → reconstructed original) for both joint angles and fingertip positions, using the same real-data test splits. revision: yes
-
Referee: [Abstract] Abstract: The MPJAE/MPJPE metrics are reported after mapping into the 22-DoF space; without an accompanying evaluation of reconstruction fidelity back to each source embodiment’s native kinematics, it is impossible to determine whether the tokenizer recovers the original hand configuration or merely a projection onto the chosen interface.
Authors: The referee is correct that MPJAE/MPJPE are computed after mapping. To clarify whether UniDexTok recovers the original configuration rather than a projection, the revision will include the round-trip reconstruction evaluation described above. This will be reported both for the tokenizer outputs and for the UDHM mapping itself, allowing readers to separate interface loss from tokenization error. revision: yes
Circularity Check
No circularity: empirical tokenizer results on defined interface
full rationale
The paper defines UDHM as a mapping to a fixed 22-DoF semantic interface and trains UniDexTok to produce discrete tokens from real joint states already standardized by that mapping. Reported MPJAE/MPJPE reductions are empirical comparisons against the UniHM baseline on the same standardized representation; no derivation, equation, or self-citation reduces the claimed accuracy or cross-embodiment gains to a tautology or fitted input renamed as prediction. The 22-DoF choice is an explicit modeling decision whose completeness is an assumption, not a self-referential step inside the derivation chain.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Unified Dexterous Hand Model (UDHM)
no independent evidence
-
UniDexTok
no independent evidence
Reference graph
Works this paper leans on
-
[1]
X. Long, Q. Zhao, K. Zhang, Z. Zhang, D. Wang, Y . Liu, Z. Shu, Y . Lu, S. Wang, X. Wei, W. Li, W. Yin, Y . Yao, J. Pan, Q. Shen, R. Yang, X. Cao, and Q. Dai. A survey: Learning embodied intelligence from physical simulators and world models, 2025
2025
-
[2]
Gupta, S
A. Gupta, S. Savarese, S. Ganguli, and L. Fei-Fei. Embodied intelligence via learning and evolution.Nature Communications, 12:5734, 2021
2021
-
[3]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InProceedings of the 7th Conference on Robot Learning (CoRL), 2023
2023
-
[4]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Fos- ter, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. InProceed- ings of the 8th Conference on Robot Learning (CoRL), 2024
2024
-
[5]
Grover, A
S. Grover, A. Gopalkrishnan, B. Ai, H. I. Christensen, H. Su, and X. Li. Enhancing general- ization in vision–language–action models by preserving pretrained representations, 2025
2025
-
[6]
Jiang, Y
G. Jiang, Y . Liang, J. Ye, J.-Y . Huang, C. Jing, R. Duan, P. Abbeel, X. Wang, and X. Zou. Cross-hand latent representation for vision-language-action models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[7]
R. Wen, G. Chen, Z. Cui, M. Du, Y . Gou, Z. Han, L. Huang, M. Lei, Y . Li, Z. Li, W. Liu, Y . Liu, X. Ma, H. Niu, Y . Ouyang, Z. Ren, H. Shi, W. Xu, H. Zhang, J. Zhang, X. Zhang, L. Zheng, W. Zhong, Y . Zhou, Z. Zhu, and H. Li. Gr-dexter technical report.arXiv preprint arXiv:2512.24210, 2025
arXiv 2025
-
[8]
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, D. Zhao, et al. Worldvla: Towards autoregressive action world model, 2025
2025
-
[9]
A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, H. Li, J. Li, J. Lv, J. Liu, M. Cao, P. Li, Q. Deng, W. Mei, X. Wang, X. Chen, X. Zhou, Y . Wang, Y . Chang, Y . Li, Y . Zhou, Y . Ye, Z. Liu, and Z. Zhu. Gigaworld-policy: An efficient action-centered world–action model, 2026
2026
-
[10]
B. Kim, T. Kim, J. Lee, and H. Joo. Dexterous world models, 2025
2025
-
[11]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, and J. Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning. In International Conference on Learning Representations (ICLR), 2026
2026
-
[12]
R. G. Goswami, A. Bar, D. Fan, T.-Y . Yang, G. Zhou, P. Krishnamurthy, M. Rabbat, F. Khor- rami, and Y . LeCun. World models for learning dexterous hand-object interactions from human videos, 2026
2026
-
[13]
Pertsch, K
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models. InRobotics: Science and Systems (RSS), 2025
2025
-
[14]
Billard and D
A. Billard and D. Kragic. Trends and challenges in robot manipulation.Science, 364(6446), 2019
2019
-
[15]
K. Shaw, A. Agarwal, and D. Pathak. LEAP hand: Low-cost, efficient, and anthropomorphic hand for robot learning. InRobotics: Science and Systems (RSS), 2023. 11
2023
-
[16]
Huang, D
Y . Huang, D. Fan, H. Duan, D. Yan, W. Qi, J. Sun, Q. Liu, and P. Wang. Human-like dexterous manipulation for anthropomorphic five-fingered hands: A review.Biomimetic Intelligence and Robotics, 5:100212, 2025
2025
-
[17]
L. Yang, K. Li, X. Zhan, F. Wu, A. Xu, L. Liu, and C. Lu. Oakink: A large-scale knowledge repository for understanding hand-object interaction. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[18]
Hoque, P
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang. Egodex: Learning dexter- ous manipulation from large-scale egocentric video. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[19]
Y .-W. Chao, W. Yang, Y . Xiang, P. Molchanov, A. Handa, J. Tremblay, Y . S. Narang, K. Van Wyk, U. Iqbal, S. Birchfield, J. Kautz, and D. Fox. Dexycb: A benchmark for cap- turing hand grasping of objects. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[20]
Zhang, J
Z. Zhang, J. Liu, Y . Shi, and J. Wang. Unihm: Unified dexterous hand manipulation with vision language model. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[21]
Zhang, Q
G. Zhang, Q. Xu, H. Zhang, J. Ma, L. He, Y . Bao, Z. Ping, Z. Yuan, C. Lu, C. Yuan, T. Liang, X. Tian, M. Shao, F. Zhang, M. Ding, Y . Gao, H. Zhao, H. Zhao, and H. Xu. Unidex: A robot foundation suite for universal dexterous hand control from egocentric human videos. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[22]
L. Zha, A. J. Hancock, M. Zhang, T. Yin, Y . Huang, D. Shah, A. Z. Ren, and A. Majumdar. Lap: Language-action pre-training enables zero-shot cross-embodiment transfer. InRobotics: Science and Systems (RSS), 2026
2026
-
[23]
P. Li, Y . Wu, Z. Xi, W. Li, Y . Huang, Z. Zhang, Y . Chen, J. Wang, S.-C. Zhu, T. Liu, and S. Huang. Controlvla: Few-shot object-centric adaptation for pre-trained vision-language- action models. InConference on Robot Learning (CoRL), 2025
2025
-
[24]
Let: A large-scale dexterous hand dataset with tactile and force feedback
Leju Robotics. Let: A large-scale dexterous hand dataset with tactile and force feedback. https://www.modelscope.cn/datasets/lejurobot/LET-Base-Dataset, 2026. Ac- cessed: 2026-06-10
2026
-
[25]
Zhang, J
Z. Zhang, J. Pang, Z. Yang, K. Li, M. Liao, S. Zhang, G. Chi, J. Guo, H.-a. Gao, M. Shi, D. Ge, Y . Mu, J. Gu, R. Chen, H. Dong, H. Xu, L. Yi, Y . Zhu, H. Zhao, P. Wang, S. Zhang, G. Yao, J. Chen, H. Li, and H. Zhao. Dexora: Open-source vla for high-dof bimanual dexterity. In IEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[26]
Linkerhand-open-world-dataset.https://www.modelscope.cn/datasets/ Linkerbot/Linkerhand-Open-World-Dataset, 2026
Linkerbot. Linkerhand-open-world-dataset.https://www.modelscope.cn/datasets/ Linkerbot/Linkerhand-Open-World-Dataset, 2026. Accessed: 2026-06-10
2026
-
[27]
K. Li, P. Li, T. Liu, Y . Li, and S. Huang. Maniptrans: Efficient dexterous bimanual manipula- tion transfer via residual learning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[28]
C. Xin, M. Yu, Y . Jiang, Z. Zhang, and X. Li. Analyzing key objectives in human-to-robot retargeting for dexterous manipulation.IEEE Robotics and Automation Practice, 2025
2025
-
[29]
Romero, D
J. Romero, D. Tzionas, and M. J. Black. Embodied hands: Modeling and capturing hands and bodies together.ACM Transactions on Graphics (Proc. SIGGRAPH Asia), 36(6), 2017
2017
-
[30]
R. Wang, J. Zhang, J. Chen, Y . Xu, P. Li, T. Liu, and H. Wang. Dexgraspnet: A large-scale robotic dexterous grasp dataset for general objects based on simulation. InIEEE International Conference on Robotics and Automation (ICRA), 2023. 12
2023
-
[31]
R. Zhao, S. Xu, R. Jin, Y . Deng, Y . Tai, K. Jia, and G. Liu. Sim2real vla: Zero-shot generaliza- tion of synthesized skills to realistic manipulation. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[32]
Z. Zeng, F. Ding, H. Yang, X. Li, and Y . Liao. Dexsim2real: Foundation model-guided sim- to-real transfer for generalizable dexterous manipulation, 2026
2026
-
[33]
Hsieh, W.-H
E. Hsieh, W.-H. Hsieh, Y .-J. Wang, T. Lin, J. Malik, K. Sreenath, and H. Qi. Learning dexterous manipulation skills from imperfect simulations. InIEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[34]
M. Zhu, Y . Zhu, J. Li, J. Wen, Z. Xu, N. Liu, R. Cheng, C. Shen, Y . Peng, F. Feng, and J. Tang. Scaling diffusion policy in transformer to 1 billion parameters for robotic manipulation. In IEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[35]
M. Song, X. Deng, Z. Zhou, J. Wei, W. Guan, and L. Nie. A survey on diffusion policy for robotic manipulation: Taxonomy, analysis, and future directions.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
2025
-
[36]
H. Guo, H. Wang, H. Bai, Z. Li, and L. Tao. Learning with less: Optimizing tactile sensor configurations for dexterous manipulation.arXiv preprint arXiv:2409.20473, 2025
Pith/arXiv arXiv 2025
-
[37]
Bauer, E
E. Bauer, E. Nava, and R. K. Katzschmann. Latent action diffusion for cross-embodiment manipulation. InIEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[38]
H. Yuan, B. Zhou, Y . Fu, and Z. Lu. Cross-embodiment dexterous grasping with reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[39]
Zhang, H
J. Zhang, H. Liu, D. Li, X. Yu, H. Geng, Y . Ding, J. Chen, and H. Wang. Dexgraspnet 2.0: Learning generative dexterous grasping in large-scale synthetic cluttered scenes. InConference on Robot Learning (CoRL), 2024
2024
-
[40]
van den Oord, O
A. van den Oord, O. Vinyals, and K. Kavukcuoglu. Neural discrete representation learning. In Advances in Neural Information Processing Systems (NeurIPS), 2017. 13
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.