LIBERO-Occ: Evaluating and Improving Vision-Language-Action Models under Scene-Induced Occlusion via Viewpoint Imagination
Pith reviewed 2026-06-27 13:46 UTC · model grok-4.3
The pith
Viewpoint Imagination improves VLA robustness to occlusion by generating a complementary view from the occluded observation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
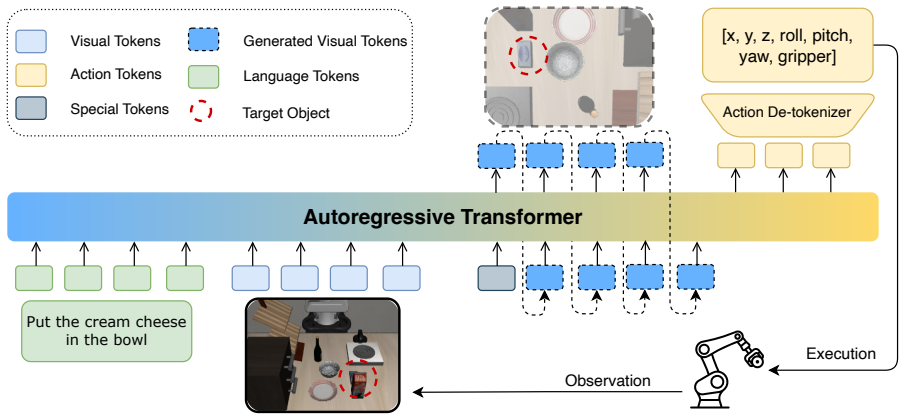
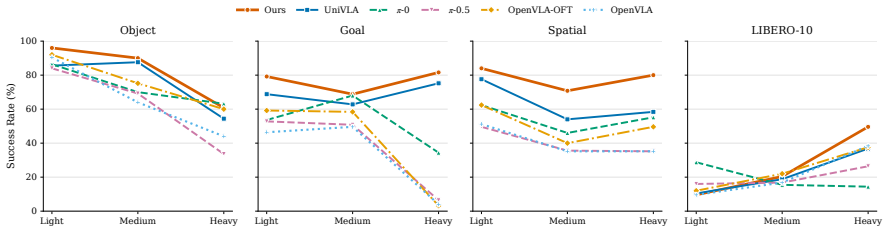
VIM generates a complementary view from an occluded primary observation and conditions action prediction on both observed and imagined evidence, improving robustness across task suites, occlusion types, and severity levels without requiring additional cameras at deployment time.
What carries the argument
Viewpoint Imagination (VIM), a module that synthesizes an imagined view to supply missing visual information for action prediction in partially observable scenes.
Load-bearing premise
The generated imagined view supplies accurate complementary information that the action predictor can reliably combine with the occluded observation rather than introducing noise or hallucinated details that hurt performance.
What would settle it
A controlled experiment in which the imagined view is replaced by random noise or a deliberately mismatched image, and VIM shows no gain or a performance drop compared with the baseline VLA.
Figures




read the original abstract
Vision-Language-Action (VLA) models achieve strong performance on standard manipulation benchmarks, but most evaluations assume that task-relevant objects are fully visible. This assumption often fails in realistic settings, where occlusion makes manipulation partially observable. In this paper, we study \textit{scene-induced occlusion} as a fundamental challenge for VLA models and introduce \textbf{LIBERO-Occ}, an occlusion-oriented extension of LIBERO. Experiments show that state-of-the-art VLAs suffer substantial performance degradation under occlusion. To address this issue, we propose \textbf{Viewpoint Imagination (VIM)}, which generates a complementary view from an occluded primary observation and conditions action prediction on both observed and imagined evidence. VIM improves robustness across task suites, occlusion types, and severity levels without requiring additional cameras at deployment time, suggesting that viewpoint imagination is an promising mechanism for perception completion in partially observable manipulation. Our benchmark and corresponding code are available at: \href{https://github.com/litsh/Libero-Occ}{https://github.com/litsh/Libero-Occ}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LIBERO-Occ, an occlusion-oriented extension of the LIBERO benchmark, and shows that state-of-the-art Vision-Language-Action (VLA) models suffer substantial performance degradation under scene-induced occlusion across task suites, occlusion types, and severity levels. It proposes Viewpoint Imagination (VIM), which generates a complementary imagined view from an occluded primary observation and conditions action prediction on both observed and imagined evidence. Experiments indicate that VIM improves robustness without requiring additional cameras at deployment time, with the benchmark and code released publicly.
Significance. If the central empirical claims hold after verification, the work is significant for highlighting and addressing partial observability in VLA models for realistic manipulation. The new benchmark and open-sourced code are concrete contributions that enable further research on occlusion robustness. The VIM approach provides a deployable mechanism for perception completion that does not rely on extra hardware.
major comments (2)
- [Section 3] Section 3: The claim that VIM improves performance by supplying accurate complementary information from the imagined view (rather than via regularization or ensemble effects) is load-bearing for the method's contribution, yet the manuscript provides no ablation replacing the imagined view with a duplicate of the occluded input or quantitative fidelity metrics on held-out visible regions. Without these controls, the reported gains across occlusion severities cannot be attributed to true perception completion.
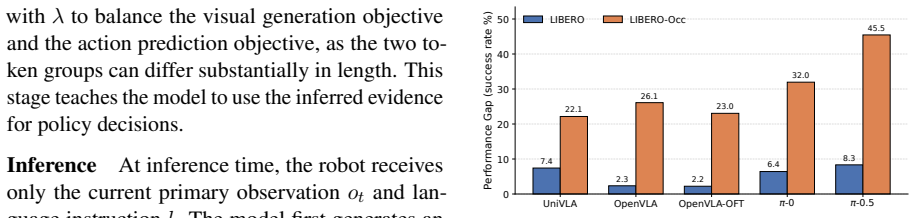
- [Experimental sections] Experimental sections: The abstract and results report degradation and improvement across suites but omit error bars, full details on the imagination module's training and quality, and per-occlusion-type breakdowns with statistical significance; these omissions make the central robustness claim only partially verifiable.
minor comments (1)
- [Abstract] The abstract states that viewpoint imagination is 'an promising mechanism'; this should be corrected to 'a promising mechanism'.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Section 3] Section 3: The claim that VIM improves performance by supplying accurate complementary information from the imagined view (rather than via regularization or ensemble effects) is load-bearing for the method's contribution, yet the manuscript provides no ablation replacing the imagined view with a duplicate of the occluded input or quantitative fidelity metrics on held-out visible regions. Without these controls, the reported gains across occlusion severities cannot be attributed to true perception completion.
Authors: We agree that the manuscript currently lacks the requested controls to isolate the contribution of the imagined view's content. An ablation replacing the imagined view with a duplicate of the occluded observation, along with quantitative fidelity metrics on held-out visible regions, would provide stronger evidence that gains arise from perception completion rather than regularization or ensembling. We will add both experiments and report the results in the revised manuscript. revision: yes
-
Referee: [Experimental sections] Experimental sections: The abstract and results report degradation and improvement across suites but omit error bars, full details on the imagination module's training and quality, and per-occlusion-type breakdowns with statistical significance; these omissions make the central robustness claim only partially verifiable.
Authors: We acknowledge that error bars, expanded training details for the imagination module, per-occlusion-type breakdowns, and statistical significance tests are absent from the current version. In revision we will add error bars to all quantitative results, include additional description and quality metrics for the imagination module, provide per-occlusion-type performance tables with significance testing, and update the abstract and results sections to reflect these additions. revision: yes
Circularity Check
No significant circularity; empirical benchmark and method evaluation
full rationale
The paper introduces LIBERO-Occ as an occlusion-extended benchmark and proposes VIM as a viewpoint imagination module that generates a complementary view to condition action prediction. No equations, derivations, or self-citations are presented that reduce any claimed result to fitted inputs or prior self-referential statements by construction. Performance gains are reported via direct experimental comparison on the benchmark across occlusion conditions, making the central claims externally falsifiable through replication rather than tautological. This is the standard case of an applied ML paper whose validity rests on empirical measurement, not on a closed mathematical chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ArXiv , year=
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success , author=. ArXiv , year=
-
[2]
Black, Kevin and Brown, Noah and Darpinian, James and Dhabalia, Karan and Driess, Danny and Esmail, Adnan and Equi, Michael Robert and Finn, Chelsea and Fusai, Niccolo and Galliker, Manuel Y. and Ghosh, Dibya and Groom, Lachy and Hausman, Karol and ichter, brian and Jakubczak, Szymon and Jones, Tim and Ke, Liyiming and LeBlanc, Devin and Levine, Sergey an...
2025
-
[3]
ArXiv , year=
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models , author=. ArXiv , year=
-
[4]
ArXiv , year=
LIBERO-PRO: Towards Robust and Fair Evaluation of Vision-Language-Action Models Beyond Memorization , author=. ArXiv , year=
-
[5]
ArXiv , year=
On Robustness of Vision-Language-Action Model against Multi-Modal Perturbations , author=. ArXiv , year=
-
[6]
ArXiv , year=
LIBERO-X: Robustness Litmus for Vision-Language-Action Models , author=. ArXiv , year=
-
[7]
2026 , url=
LIBERO-Para: A Diagnostic Benchmark and Metrics for Paraphrase Robustness in VLA Models , author=. 2026 , url=
2026
-
[8]
2022 International Conference on Robotics and Automation (ICRA) , year=
Unseen Object Amodal Instance Segmentation via Hierarchical Occlusion Modeling , author=. 2022 International Conference on Robotics and Automation (ICRA) , year=
2022
-
[9]
International Symposium of Robotics Research , year=
Safe, Occlusion-Aware Manipulation for Online Object Reconstruction in Confined Spaces , author=. International Symposium of Robotics Research , year=
-
[10]
ArXiv , year=
Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks , author=. ArXiv , year=
-
[11]
2026 , url=
TacVLA: Contact-Aware Tactile Fusion for Robust Vision-Language-Action Manipulation , author=. 2026 , url=
2026
-
[12]
2019 International Conference on Robotics and Automation (ICRA) , year=
Online Planning for Target Object Search in Clutter under Partial Observability , author=. 2019 International Conference on Robotics and Automation (ICRA) , year=
2019
-
[13]
Robotics Auton
Hierarchical POMDP planning for object manipulation in clutter , author=. Robotics Auton. Syst. , year=
-
[14]
2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , year=
Occlusion-Aware Search for Object Retrieval in Clutter , author=. 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , year=
2021
-
[15]
IEEE Robotics and Automation Letters , year=
Active-Perceptive Language-Oriented Grasp Policy for Heavily Cluttered Scenes , author=. IEEE Robotics and Automation Letters , year=
-
[16]
Conference on Robot Learning , year=
View-Invariant Policy Learning via Zero-Shot Novel View Synthesis , author=. Conference on Robot Learning , year=
-
[17]
ArXiv , year=
VLA-LPAF: Lightweight Perspective-Adaptive Fusion for Vision-Language-Action to Enable More Unconstrained Robotic Manipulation , author=. ArXiv , year=
-
[18]
ArXiv , year=
Imagination at Inference: Synthesizing In-Hand Views for Robust Visuomotor Policy Inference , author=. ArXiv , year=
-
[19]
ArXiv , year=
ActiveVLA: Injecting Active Perception into Vision-Language-Action Models for Precise 3D Robotic Manipulation , author=. ArXiv , year=
-
[20]
2026 , url=
SaPaVe: Towards Active Perception and Manipulation in Vision-Language-Action Models for Robotics , author=. 2026 , url=
2026
-
[21]
ArXiv , year=
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning , author=. ArXiv , year=
-
[22]
ArXiv , year=
Unified Vision-Language-Action Model , author=. ArXiv , year=
-
[23]
2024 , eprint=
Emu3: Next-Token Prediction is All You Need , author=. 2024 , eprint=
2024
-
[24]
2025 , eprint=
WorldVLA: Towards Autoregressive Action World Model , author=. 2025 , eprint=
2025
-
[25]
arXiv preprint arXiv:2212.06817 , year=
Rt-1: Robotics transformer for real-world control at scale , author=. arXiv preprint arXiv:2212.06817 , year=
-
[26]
Conference on Robot Learning , pages=
Rt-2: Vision-language-action models transfer web knowledge to robotic control , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[27]
arXiv preprint arXiv:2303.03378 , year=
Palm-e: An embodied multimodal language model , author=. arXiv preprint arXiv:2303.03378 , year=
-
[28]
arXiv preprint arXiv:2405.12213 , year=
Octo: An open-source generalist robot policy , author=. arXiv preprint arXiv:2405.12213 , year=
-
[29]
IEEE Robotics and Automation Letters , volume=
Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks , author=. IEEE Robotics and Automation Letters , volume=. 2022 , publisher=
2022
-
[30]
arXiv preprint arXiv:2503.02881 , year=
Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation , author=. arXiv preprint arXiv:2503.02881 , year=
-
[31]
arXiv preprint arXiv:2512.21970 , year=
StereoVLA: Enhancing Vision-Language-Action Models with Stereo Vision , author=. arXiv preprint arXiv:2512.21970 , year=
-
[32]
IEEE Robotics and Automation Letters , year=
Observe then act: Asynchronous active vision-action model for robotic manipulation , author=. IEEE Robotics and Automation Letters , year=
-
[33]
Gearing up and accelerating cross-fertilization between academic and industrial robotics research in Europe: Technology transfer experiments from the ECHORD project , pages=
Active recognition and manipulation for mobile robot bin picking , author=. Gearing up and accelerating cross-fertilization between academic and industrial robotics research in Europe: Technology transfer experiments from the ECHORD project , pages=. 2014 , publisher=
2014
-
[34]
arXiv preprint arXiv:2404.12377 , year=
Robodreamer: Learning compositional world models for robot imagination , author=. arXiv preprint arXiv:2404.12377 , year=
-
[35]
International Conference on Learning Representations , volume=
Dream to manipulate: Compositional world models empowering robot imitation learning with imagination , author=. International Conference on Learning Representations , volume=
-
[36]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[37]
Conference on Robot Learning , pages=
Bridgedata v2: A dataset for robot learning at scale , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[38]
Openvla: An open-source vision-language-action model, 2024 , author=. URL https://arxiv. org/abs/2406.09246 , volume=
Pith/arXiv arXiv 2024
-
[39]
arXiv preprint arXiv:2410.24164 , year=
_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. arXiv preprint arXiv:2410.24164 , year=
-
[40]
arXiv preprint arXiv:2501.09747 , year=
Fast: Efficient action tokenization for vision-language-action models , author=. arXiv preprint arXiv:2501.09747 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.