Ethical and Technical Limits of Deepfake Speech Datasets
Pith reviewed 2026-06-27 11:38 UTC · model grok-4.3
The pith
Most deepfake speech datasets lack demographic metadata, making fairness assessment infeasible, and share overlapping bona fide sources that undermine cross-dataset evaluations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
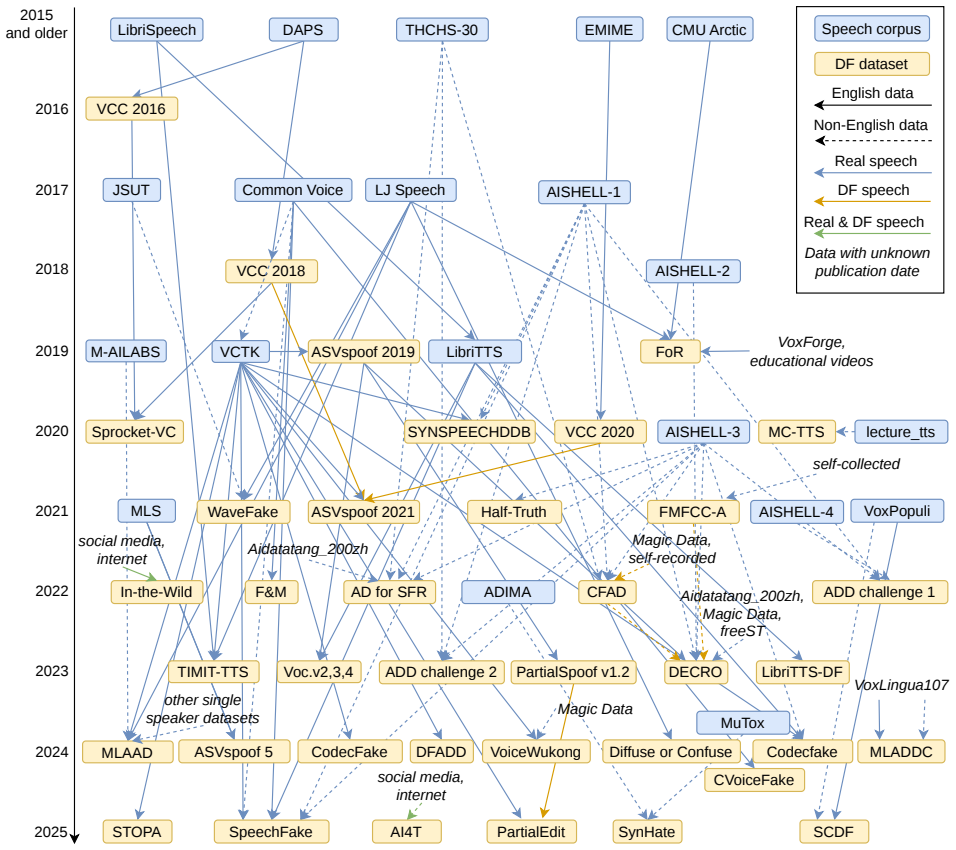
Core claim
Claims about the robustness and fairness of deepfake speech detectors are only as credible as the datasets used to train and evaluate those systems. The audit reveals two important takeaways. Firstly, fairness assessment is largely infeasible because most datasets lack demographic metadata, and only a few contain gender or language labels. This prevents any meaningful subgroup analysis and leaves other demographic attributes unaddressed. Secondly, substantial overlap in underlying bona fide source corpora across datasets can undermine cross-dataset evaluation and lead to overstated generalization claims.
What carries the argument
A systematic audit of 39 deepfake speech datasets examining accessibility, documentation, demographic and language coverage, dataset scale, and underlying bona fide speech sources.
If this is right
- Fairness of deepfake speech detectors cannot be reliably assessed with current datasets.
- Subgroup analysis across demographics such as gender or language is not possible.
- Cross-dataset evaluations may produce misleading results due to shared source material.
- Reported generalization performance of detectors is likely overstated.
Where Pith is reading between the lines
- Future dataset creators should build in demographic metadata collection from the start to support fairness work.
- Evaluation protocols may require explicit checks for source overlap to produce valid comparisons.
- The effective diversity of training material across the field is smaller than the count of published datasets suggests.
Load-bearing premise
The 39 datasets compiled for the audit represent the broader deepfake speech dataset landscape and the available documentation accurately reflects the presence or absence of demographic metadata and source overlaps.
What would settle it
Discovery of additional deepfake speech datasets that include complete demographic metadata for all speakers or an experiment demonstrating that detector performance remains consistent when trained and tested on fully non-overlapping source corpora.
Figures
read the original abstract
Claims about the robustness and fairness of deepfake speech detectors are only as credible as the datasets used to train and evaluate those systems. We present a dataset-level audit of the deepfake speech landscape. We compile and analyze 39 deepfake speech datasets, examining key attributes including accessibility, documentation, demographic and language coverage, dataset scale, and the underlying bona fide speech sources. Our audit reveals two important takeaways. Firstly, fairness assessment is largely infeasible because most datasets lack demographic metadata, and only a few contain gender or language labels. This prevents any meaningful subgroup analysis and leaves other demographic attributes unaddressed. Secondly, we identify substantial overlap in underlying bona fide source corpora across datasets, which can undermine cross-dataset evaluation and lead to overstated generalization claims.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a dataset-level audit of 39 deepfake speech datasets, examining attributes including accessibility, documentation, demographic and language coverage, scale, and underlying bona fide speech sources. It concludes that fairness assessment is largely infeasible because most datasets lack demographic metadata (with only a few containing gender or language labels), preventing subgroup analysis, and that substantial overlap exists in the bona fide source corpora across datasets, which can undermine cross-dataset evaluation and lead to overstated generalization claims.
Significance. If the audit's sampling is representative, the findings identify concrete barriers to ethical evaluation and reliable benchmarking in deepfake speech detection. By cataloging metadata gaps and source overlaps, the work supplies a practical reference that could inform dataset curation standards and evaluation protocols in the field.
major comments (1)
- [Dataset compilation / audit methodology] The section describing the compilation of the 39 datasets provides no explicit search protocol, inclusion/exclusion criteria, or completeness argument. This is load-bearing for both central claims: without it, the assertion that fairness assessment is 'largely infeasible' for 'most datasets' and that source overlaps are 'substantial' across 'the deepfake speech landscape' cannot be distinguished from possible sampling bias (e.g., under-representation of newer or non-English corpora with richer metadata).
minor comments (2)
- [Results / tables] A summary table listing all 39 datasets with columns for accessibility, demographic labels present, and identified source corpora would improve readability and allow readers to verify the overlap and metadata claims directly.
- [Abstract] The abstract states that 'only a few contain gender or language labels' but does not quantify 'few' or 'most'; adding counts or percentages in the abstract would strengthen the headline claims without lengthening the text.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and recommendation. The single major comment identifies a genuine gap in our methodology description. We will revise the manuscript to address it directly.
read point-by-point responses
-
Referee: [Dataset compilation / audit methodology] The section describing the compilation of the 39 datasets provides no explicit search protocol, inclusion/exclusion criteria, or completeness argument. This is load-bearing for both central claims: without it, the assertion that fairness assessment is 'largely infeasible' for 'most datasets' and that source overlaps are 'substantial' across 'the deepfake speech landscape' cannot be distinguished from possible sampling bias (e.g., under-representation of newer or non-English corpora with richer metadata).
Authors: We agree that the absence of an explicit search protocol, inclusion/exclusion criteria, and completeness argument is a limitation that weakens the generalizability claims. In the revised manuscript we will insert a new subsection (likely 3.1) that specifies: (1) the search strategy (keywords, databases including Google Scholar, arXiv, Hugging Face Datasets, Zenodo, and major surveys up to December 2023); (2) inclusion criteria (publicly released deepfake speech datasets containing both bona fide and spoofed utterances, with at least one published paper); (3) exclusion criteria (non-speech audio, private datasets, or those without any accompanying paper); and (4) a completeness argument based on cross-referencing against the most-cited surveys and repositories at the time of collection. We will also note the cutoff date and discuss the possibility of newer datasets with richer metadata. This revision will allow readers to evaluate sampling bias while preserving the audit's core observations on the 39 datasets we examined. revision: yes
Circularity Check
No circularity: purely empirical survey with no derivations or fitted quantities
full rationale
This is a descriptive audit paper that compiles 39 datasets and reports direct observations on metadata presence, source overlaps, and documentation quality. There are no equations, parameters, predictions, uniqueness theorems, or ansatzes. All claims reduce to the authors' manual examination of the listed datasets rather than to any self-referential construction or prior fitted result. The sampling assumption noted by the skeptic is a scope limitation, not a circular reduction of a derivation to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction The misuse of synthetic speech poses a growing challenge for speaker verification, digital forensics, and media authentica- tion [1, 2, 3]. Employing a deepfake speech detector is a core defense mechanism [4, 5], but moving toward real-world us- age shifts focus from accuracy alone to robustness, fairness, and transparency. In high-stakes set...
-
[2]
Background Current work on deepfake speech datasets focuses on model benchmarking [7, 8] or high-level dataset overviews [11], typ- ically reporting basic properties such as size, year, and some- times a short description, with limited attention to dataset au- ditability and representativeness (e.g., demographic metadata or data sources). In parallel, the...
-
[3]
Audit of Existing Deepfake Speech Datasets This section audits existing deepfake speech datasets to eval- uate whether available resources are suitable for fairness eval- uation and cross-dataset generalization testing. Our contribu- 1Interactive browser of the dataset table and provenance map: https://security-fit.github.io/deepfake_speech_ datasets_app/...
Pith/arXiv arXiv 2026
-
[4]
The exam- ined datasets list more than 100 distinct tools and architectures (both open-source and commercial), indicating significant di- versity
Synthesizers:A diverse range of synthesizers is arguably the most critical factor for effectively training detectors to ad- dress real-world scenarios, particularly since utterances gener- ated by novel methods may evade detection [53, 54]. The exam- ined datasets list more than 100 distinct tools and architectures (both open-source and commercial), indic...
-
[5]
Deepfake datasets draw from a wide range of sources, typically established speech corpora and seldom from social media; purely self-recorded data is rare
(Bona fide) speech sources:The origin of the bona fide speech plays a crucial role in assessing the generalization abil- ity of deepfake speech detectors. Deepfake datasets draw from a wide range of sources, typically established speech corpora and seldom from social media; purely self-recorded data is rare. Importantly, many datasets are derived from ove...
2019
-
[6]
Without adequate demographic data, ensuring the effectiveness of detection solutions across diverse groups becomes unattain- able
Demographics:Demographic metadata is essential for analyzing and mitigating bias in deepfake speech detection. Without adequate demographic data, ensuring the effectiveness of detection solutions across diverse groups becomes unattain- able. The existing datasets currently do not sufficiently incorpo- rate this essential information. Only some datasets pr...
-
[7]
Only a handful are bilin- gual [8, 30]
Language:Most deepfake speech datasets are monolin- gual, mostly English and Chinese. Only a handful are bilin- gual [8, 30]. Multilingual datasets have recently emerged, in- cluding MLAAD [9], AI4T [48], SynHate [49], SCDF [10] and SpeechFake [52]. These datasets are also trying to provide bal- anced language subsets. Prior results indicate that detector...
-
[8]
Small datasets are unlikely to be suitable for DNN-based training; prior work suggests that fewer than 80,000 samples can be insufficient in some settings [4]
Size:Dataset scale affects the feasibility of training modern detectors. Small datasets are unlikely to be suitable for DNN-based training; prior work suggests that fewer than 80,000 samples can be insufficient in some settings [4]. How- ever, the sample count alone is not informative without adequate diversity in speakers and synthesis methods
-
[9]
Older datasets may under-represent current attacks, leading to evaluations that do not reflect state-of-the-art deepfakes
Publication year:Because speech synthesis quality evolves rapidly, staying up to date with this trend is crucial. Older datasets may under-represent current attacks, leading to evaluations that do not reflect state-of-the-art deepfakes
-
[10]
Even when acces- sible, restrictive or unclear licenses can still limit reproducibil- ity and practical deployment
Availability:Access and licensing remain practical bar- riers: 15% (6/39) of datasets are restricted, and some are described as public but are not obtainable via the provided links [49] or are only partially released [51]. Even when acces- sible, restrictive or unclear licenses can still limit reproducibil- ity and practical deployment
-
[11]
Findings & Discussion Our dataset audit uncovered major shortcomings of the cur- rently available deepfake speech datasets. Most issues originate from missing metadata, undisclosed synthesis details, insuffi- cient gender and language coverage, outdated synthesis tools, and licensing or access constraints. Only 19/39 (49%) datasets report speaker counts a...
-
[12]
Our analysis shows that missing demographic and lan- guage metadata makes fairness and bias evaluation infeasible with the resources currently available
Conclusion This paper presented a dataset-level audit of 39 deepfake speech datasets and mapped overlap in underlying bona fide source cor- pora. Our analysis shows that missing demographic and lan- guage metadata makes fairness and bias evaluation infeasible with the resources currently available. Additionally, we identi- fied substantial overlap between...
-
[13]
Acknowledgments This work was supported by the Brno University of Technology internal project FIT-S-26-9011, and the Ministry of Education, Youth and Sports of the Czech Republic through the e-INFRA CZ project (ID: 90254)
-
[14]
The authors reviewed and edited the output as needed and take full respon- sibility for the publication’s content
Generative AI Use Disclosure During the preparation of this work, the authors used Generative AI Models (specifically Google Gemini, ChatGPT, and Gram- marly) for language editing and text refinement. The authors reviewed and edited the output as needed and take full respon- sibility for the publication’s content
-
[15]
Evaluation framework for deepfake speech detection: a comparative study of state-of-the-art deepfake speech detectors,
A. Firc, K. Malinka, and P. Han ´aˇcek, “Evaluation framework for deepfake speech detection: a comparative study of state-of-the-art deepfake speech detectors,”Cybersecurity, vol. 8, no. 1, 2025
2025
-
[16]
Publications Office of the European Union, 2024
Europol Innovation Lab,Facing reality? – Law enforcement and the challenge of deepfakes – An observatory report from the Eu- ropol innovation lab. Publications Office of the European Union, 2024
2024
-
[17]
Resilience of V oice Assistants to Synthetic Speech,
K. Malinka, A. Firc, P. Kaˇska, T. Lapˇsansk´y, O. ˇSandor, and I. Ho- moliak, “Resilience of V oice Assistants to Synthetic Speech,” Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformat- ics), vol. 14982 LNCS, p. 66 – 84, 2024
2024
-
[18]
Deepfake Speech De- tection: A Spectrogram Analysis,
A. Firc, K. Malinka, and P. Han ´aˇcek, “Deepfake Speech De- tection: A Spectrogram Analysis,” inProceedings of the 39th ACM/SIGAPP Symposium on Applied Computing, 2024, Confer- ence paper
2024
-
[19]
Evolutionary Multi-Objective Fusion of Deepfake Speech Detectors,
V . Stan ˇek, M. Pere ˇs´ıni, L. Sekanina, A. Firc, and K. Malinka, “Evolutionary Multi-Objective Fusion of Deepfake Speech Detectors,” 2026. [Online]. Available: https://arxiv.org/abs/2604. 01330
2026
-
[20]
Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down har- monised rules on artificial intelligence,
European Union, “Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down har- monised rules on artificial intelligence,” https://eur-lex.europa. eu/eli/reg/2024/1689/oj, 2024, official Journal of the European Union, L 295, 12.7.2024
2024
-
[21]
ASVspoof 5: crowd- sourced speech data, deepfakes, and adversarial attacks at scale,
X. Wang, H. Delgado, H. Tak, J. weon Jung, H. jin Shim, M. Todisco, I. Kukanov, X. Liu, M. Sahidullah, T. H. Kinnunen, N. Evans, K. A. Lee, and J. Yamagishi, “ASVspoof 5: crowd- sourced speech data, deepfakes, and adversarial attacks at scale,” inThe Automatic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), 2024, pp. 1–8
2024
-
[22]
V oiceWukong: benchmarking deepfake voice detection,
Z. Yan, Y . Zhao, and H. Wang, “V oiceWukong: benchmarking deepfake voice detection,” inProceedings of the 34th USENIX Conference on Security Symposium, ser. SEC ’25. USA: USENIX Association, 2025
2025
-
[23]
MLAAD: The Multi-Language Audio Anti-Spoofing Dataset,
N. M. M ¨uller, P. Kawa, W. H. Choong, E. Casanova, E. G ¨olge, T. M ¨uller, P. Syga, P. Sperl, and K. B ¨ottinger, “MLAAD: The Multi-Language Audio Anti-Spoofing Dataset,”arXiv preprint arXiv:2401.09512, 2024
Pith/arXiv arXiv 2024
-
[24]
SCDF: A Speaker Characteristics Deepfake Speech Dataset for Bias Analysis,
V . Stanˇek, K. Srna, A. Firc, and K. Malinka, “SCDF: A Speaker Characteristics Deepfake Speech Dataset for Bias Analysis,” in BIOSIG 2025. Gesellschaft f ¨ur Informatik e.V ., 2025
2025
-
[25]
Deepfakes as a threat to a speaker and facial recognition: An overview of tools and attack vectors,
A. Firc, K. Malinka, and P. Han ´aˇcek, “Deepfakes as a threat to a speaker and facial recognition: An overview of tools and attack vectors,”Heliyon, 2023
2023
-
[26]
Datasheets for Healthcare AI: A Framework for Transparency and Bias Mitigation,
M. Siddik and H. J. Pandit, “Datasheets for Healthcare AI: A Framework for Transparency and Bias Mitigation,” 2025. [Online]. Available: https://arxiv.org/abs/2501.05617
arXiv 2025
-
[27]
What’s documented in AI? Systematic Analysis of 32K AI Model Cards,
W. Liang, N. Rajani, X. Yang, E. Ozoani, E. Wu, Y . Chen, D. S. Smith, and J. Zou, “What’s documented in AI? Systematic Analysis of 32K AI Model Cards,” 2024. [Online]. Available: https://arxiv.org/abs/2402.05160
arXiv 2024
-
[28]
The State of Documentation Practices of Third-Party Machine Learning Models and Datasets,
E. L. Oreamuno, R. F. Khan, A. A. Bangash, C. Stinson, and B. Adams, “The State of Documentation Practices of Third-Party Machine Learning Models and Datasets,”IEEE Software, vol. 41, no. 5, pp. 52–59, 2024
2024
-
[29]
Navigating Dataset Doc- umentations in AI: A Large-Scale Analysis of Dataset Cards on Hugging Face,
X. Yang, W. Liang, and J. Zou, “Navigating Dataset Doc- umentations in AI: A Large-Scale Analysis of Dataset Cards on Hugging Face,” 2024. [Online]. Available: https://arxiv.org/abs/2401.13822
arXiv 2024
-
[30]
GBDF: Gender Balanced DeepFake Dataset Towards Fair DeepFake Detection,
A. V . Nadimpalli and A. Rattani, “GBDF: Gender Balanced DeepFake Dataset Towards Fair DeepFake Detection,” inPat- tern Recognition, Computer Vision, and Image Processing. ICPR 2022 International Workshops and Challenges, J.-J. Rousseau and B. Kapralos, Eds. Cham: Springer Nature Switzerland, 2023, pp. 320–337
2022
-
[31]
Thinking Racial Bias in Fair Forgery Detection: Models, Datasets and Evaluations,
D. Liu, Z. Wang, C. Peng, N. Wang, R. Hu, and X. Gao, “Thinking Racial Bias in Fair Forgery Detection: Models, Datasets and Evaluations,”arXiv.org, 2024. [Online]. Available: https://arxiv.org/abs/2407.14367
arXiv 2024
-
[32]
Towards Measuring Fairness in AI: The Casual Conversations Dataset,
C. Hazirbas, J. Bitton, B. Dolhansky, J. Pan, A. Gordo, and C. C. Ferrer, “Towards Measuring Fairness in AI: The Casual Conversations Dataset,”IEEE Transactions on Biometrics, Behavior, and Identity Science, vol. 4, no. 3, pp. 324–332, 7
-
[33]
Available: http://dx.doi.org/10.1109/tbiom.2021
[Online]. Available: http://dx.doi.org/10.1109/tbiom.2021. 3132237
-
[34]
FairSSD: Understanding Bias in Synthetic Speech Detec- tors,
A. K. Singh Yadav, K. Bhagtani, D. Salvi, P. Bestagini, and E. J. Delp, “FairSSD: Understanding Bias in Synthetic Speech Detec- tors,” in2024 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition Workshops (CVPRW), 2024, pp. 4418–4428
2024
-
[35]
The V oice Conversion Challenge 2016,
T. Toda, L.-H. Chen, D. Saito, F. Villavicencio, M. Wester, Z. Wu, and J. Yamagishi, “The V oice Conversion Challenge 2016,” inIn- terspeech 2016. International Speech Communication Associa- tion, 2016, pp. 1632–1636
2016
-
[36]
The V oice Conversion Chal- lenge 2018: Promoting Development of Parallel and Nonparallel Methods,
J. Lorenzo-Trueba, J. Yamagishi, T. Toda, D. Saito, F. Villavi- cencio, T. Kinnunen, and Z. Ling, “The V oice Conversion Chal- lenge 2018: Promoting Development of Parallel and Nonparallel Methods,” inThe Speaker and Language Recognition Workshop (Odyssey 2018). ISCA, 2018, p. 195
2018
-
[37]
ASVspoof 2019: A large-scale public database of synthe- sized, converted and replayed speech,
X. Wang, J. Yamagishi, M. Todisco, H. Delgado, A. Nautsch, N. Evans, M. Sahidullah, V . Vestman, T. Kinnunen, K. A. Lee et al., “ASVspoof 2019: A large-scale public database of synthe- sized, converted and replayed speech,”Computer Speech & Lan- guage, vol. 64, p. 101114, 2020
2019
-
[38]
FoR: A dataset for synthetic speech detection,
R. Reimao and V . Tzerpos, “FoR: A dataset for synthetic speech detection,” in2019 International Conference on Speech Technol- ogy and Human-Computer Dialogue (SpeD). IEEE, 2019, pp. 1–10
2019
-
[39]
DeepSonar: Towards Effective and Robust Detection of AI-Synthesized Fake V oices,
R. Wang, F. Juefei-Xu, Y . Huang, Q. Guo, X. Xie, L. Ma, and Y . Liu, “DeepSonar: Towards Effective and Robust Detection of AI-Synthesized Fake V oices,” inProceedings of the 28th ACM International Conference on Multimedia, ser. MM ’20. New York, NY , USA: Association for Computing Machinery, 2020, p. 1207–1216. [Online]. Available: https: //doi.org/10.11...
-
[40]
SynSpeechDDB: a new synthetic speech detection database,
Z. Zhang, Y . Gu, X. Yi, and X. Zhao, “SynSpeechDDB: a new synthetic speech detection database,” 2020. [Online]. Available: https://dx.doi.org/10.21227/ta8z-mx73
-
[41]
V oice Conversion Challenge 2020 — Intra-lingual semi-parallel and cross-lingual voice con- version —,
Z. Yi, W.-C. Huang, X. Tian, J. Yamagishi, R. K. Das, T. Kin- nunen, Z.-H. Ling, and T. Toda, “V oice Conversion Challenge 2020 — Intra-lingual semi-parallel and cross-lingual voice con- version —,” inProc. Joint Workshop for the Blizzard Challenge and Voice Conversion Challenge 2020, 2020, pp. 80–98
2020
-
[42]
ASVspoof 2021: Towards spoofed and deepfake speech detec- tion in the wild,
X. Liu, X. Wang, M. Sahidullah, J. Patino, H. Delgado, T. Kin- nunen, M. Todisco, J. Yamagishi, N. Evans, A. Nautschet al., “ASVspoof 2021: Towards spoofed and deepfake speech detec- tion in the wild,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023
2021
-
[43]
FMFCC-A: A Challeng- ing Mandarin Dataset for Synthetic Speech Detection,
Z. Zhang, Y . Gu, X. Yi, and X. Zhao, “FMFCC-A: A Challeng- ing Mandarin Dataset for Synthetic Speech Detection,” inDig- ital Forensics and Watermarking: 20th International Workshop, IWDW 2021, Beijing, China, November 20–22, 2021, Revised Se- lected Papers, vol. 13180. Springer Nature, 2022, p. 117
2021
-
[44]
Half-Truth: A Partially Fake Audio Detection Dataset,
J. Yi, Y . Bai, J. Tao, H. Ma, Z. Tian, C. Wang, T. Wang, and R. Fu, “Half-Truth: A Partially Fake Audio Detection Dataset,” inProc. Interspeech 2021, 2021, pp. 1654–1658
2021
-
[45]
WaveFake: A Data Set to Facilitate Audio Deepfake Detection,
J. Frank and L. Sch ¨onherr, “WaveFake: A Data Set to Facilitate Audio Deepfake Detection,” inThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[46]
System fingerprints detection for deepfake audio: An initial dataset and investigation,
X. Yan, J. Yi, J. Tao, C. Wang, H. Ma, Z. Tian, and R. Fu, “System fingerprints detection for deepfake audio: An initial dataset and investigation,”arXiv preprint arXiv:2208.10489, 2022
arXiv 2022
-
[47]
Add 2022: the first audio deep synthe- sis detection challenge,
J. Yi, R. Fu, J. Tao, S. Nie, H. Ma, C. Wang, T. Wang, Z. Tian, Y . Bai, C. Fanet al., “Add 2022: the first audio deep synthe- sis detection challenge,” inICASSP 2022-2022 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 9216–9220
2022
-
[48]
CFAD: A Chinese dataset for fake audio detection,
H. Ma, J. Yi, C. Wang, X. Yan, J. Tao, T. Wang, S. Wang, L. Xu, and R. Fu, “CFAD: A Chinese dataset for fake audio detection,” arXiv preprint arXiv:2207.12308, 2022
arXiv 2022
-
[49]
The Dawn of a Text-Dependent Society: Deepfakes as a Threat to Speech Verification Systems,
A. Firc and K. Malinka, “The Dawn of a Text-Dependent Society: Deepfakes as a Threat to Speech Verification Systems,” inPro- ceedings of the 37th ACM/SIGAPP Symposium on Applied Com- puting, ser. SAC ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 1646–1655
2022
-
[50]
Does Audio Deepfake Detection Generalize?
N. M ¨uller, P. Czempin, F. Diekmann, A. Froghyar, and K. B ¨ottinger, “Does Audio Deepfake Detection Generalize?” in Proc. Interspeech 2022, 2022, pp. 2783–2787
2022
-
[51]
ADD 2023: the Second Audio Deepfake Detection Challenge,
J. Yi, J. Tao, R. Fu, X. Yan, C. Wang, T. Wang, C. Y . Zhang, X. Zhang, Y . Zhao, Y . Renet al., “ADD 2023: the Second Audio Deepfake Detection Challenge,”arXiv preprint arXiv:2305.13774, 2023
arXiv 2023
-
[52]
Transferring Audio Deepfake Detection Capability across Lan- guages,
Z. Ba, Q. Wen, P. Cheng, Y . Wang, F. Lin, L. Lu, and Z. Liu, “Transferring Audio Deepfake Detection Capability across Lan- guages,” inProceedings of the ACM Web Conference 2023, 2023, pp. 2033–2044
2023
-
[53]
Vulnera- bility of Automatic Identity Recognition to Audio-Visual Deep- fakes,
P. Korshunov, H. Chen, P. N. Garner, and S. Marcel, “Vulnera- bility of Automatic Identity Recognition to Audio-Visual Deep- fakes,” inIEEE International Joint Conference on Biometrics (IJCB), Sep. 2023
2023
-
[54]
The PartialSpoof Database and Countermeasures for the Detec- tion of Short Fake Speech Segments Embedded in an Utterance,
L. Zhang, X. Wang, E. Cooper, N. Evans, and J. Yamagishi, “The PartialSpoof Database and Countermeasures for the Detec- tion of Short Fake Speech Segments Embedded in an Utterance,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 31, pp. 813–825, 2023
2023
-
[55]
TIMIT-TTS: A Text-to-Speech Dataset for Multimodal Synthetic Media Detection,
D. Salvi, B. Hosler, P. Bestagini, M. C. Stamm, and S. Tubaro, “TIMIT-TTS: A Text-to-Speech Dataset for Multimodal Synthetic Media Detection,”IEEE Access, vol. 11, pp. 50 851–50 866, 2023
2023
-
[56]
Spoofed training data for speech spoofing countermeasure can be efficiently created using neural vocoders,
X. Wang and J. Yamagishi, “Spoofed training data for speech spoofing countermeasure can be efficiently created using neural vocoders,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[57]
CodecFake: Enhancing Anti- Spoofing Models Against Deepfake Audios from Codec-Based Speech Synthesis Systems,
H. Wu, Y . Tseng, and H. yi Lee, “CodecFake: Enhancing Anti- Spoofing Models Against Deepfake Audios from Codec-Based Speech Synthesis Systems,” inInterspeech 2024, 2024, pp. 1770– 1774
2024
-
[58]
Codecfake: An Initial Dataset for Detecting LLM-based Deepfake Audio,
Y . Lu, Y . Xie, R. Fu, Z. Wen, J. Tao, Z. Wang, X. Liu, Y . Li, Y . Liu, X. Wang, and S. Shi, “Codecfake: An Initial Dataset for Detecting LLM-based Deepfake Audio,” 06 2024
2024
-
[59]
SafeEar: Content Privacy-Preserving Audio Deepfake Detection,
X. Li, K. Li, Y . Zheng, C. Yan, X. Ji, and W. Xu, “SafeEar: Content Privacy-Preserving Audio Deepfake Detection,” inPro- ceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security (CCS), 2024
2024
-
[60]
Diffuse or Confuse: A Diffusion Deepfake Speech Dataset,
A. Firc, K. Malinka, and P. Han ´aˇcek, “Diffuse or Confuse: A Diffusion Deepfake Speech Dataset,” in2024 International Con- ference of the Biometrics Special Interest Group (BIOSIG), 2024, pp. 1–7
2024
-
[61]
MLADDC: Multi-Lingual Audio Deepfake Detection Corpus,
A. J. SHAH, R. M. Purohit, D. H. Vaghera, and H. Patil, “MLADDC: Multi-Lingual Audio Deepfake Detection Corpus,” inAudio Imagination: NeurIPS 2024 Workshop AI-Driven Speech, Music, and Sound Generation, 2024. [Online]. Available: https://openreview.net/forum?id=ic3HvoOTeU
2024
-
[62]
DFADD: The Diffusion and Flow- Matching Based Audio Deepfake Dataset,
J. Du, I.-M. Lin, I.-H. Chiu, X. Chen, H. Wu, W. Ren, Y . Tsao, H.-y. Lee, and J.-S. R. Jang, “DFADD: The Diffusion and Flow- Matching Based Audio Deepfake Dataset,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 921– 928
2024
-
[63]
Un- masking real-world audio deepfakes: A data-centric approach,
D. Combei, A. Stan, D. Oneata, N. M ¨uller, and H. Cucu, “Un- masking real-world audio deepfakes: A data-centric approach,” in Interspeech 2025, 2025, pp. 5343–5347
2025
-
[64]
SynHate: De- tecting Hate Speech in Synthetic Deepfake Audio,
R. Ranjan, K. Pipariya, M. Vatsa, and R. Singh, “SynHate: De- tecting Hate Speech in Synthetic Deepfake Audio,” inInterspeech 2025, 2025, pp. 5623–5627
2025
-
[65]
STOPA: A Dataset of Systematic VariaTion Of DeePfake Audio for Open-Set Source Tracing and Attribution,
A. Firc, M. Chhibber, J. Mishra, V . Pratap Singh, T. Kinnunen, and K. Malinka, “STOPA: A Dataset of Systematic VariaTion Of DeePfake Audio for Open-Set Source Tracing and Attribution,” in Interspeech 2025, 2025, pp. 1553–1557
2025
-
[66]
PartialEdit: Identi- fying Partial Deepfakes in the Era of Neural Speech Editing ,
Y . Zhang, B. Tian, L. Zhang, and Z. Duan, “PartialEdit: Identi- fying Partial Deepfakes in the Era of Neural Speech Editing ,” in Interspeech 2025, 2025, pp. 5353–5357
2025
-
[67]
SpeechFake: A Large-Scale Multilingual Speech Deepfake Dataset Incorporating Cutting-Edge Generation Methods,
W. Huang, Y . Gu, Z. Wang, H. Zhu, and Y . Qian, “SpeechFake: A Large-Scale Multilingual Speech Deepfake Dataset Incorporating Cutting-Edge Generation Methods,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Associa...
2025
-
[68]
Assessing the Human Abil- ity to Recognize Synthetic Speech in Ordinary Conversation,
D. Prudk ´y, A. Firc, and K. Malinka, “Assessing the Human Abil- ity to Recognize Synthetic Speech in Ordinary Conversation,” in 2023 International Conference of the Biometrics Special Interest Group (BIOSIG), 2023, pp. 1–5
2023
-
[69]
Comprehensive Multiparametric Analysis of Human Deepfake Speech Recognition,
K. Malinka, A. Firc, M. ˇSalko, D. Prudk ´y, K. Rada ˇcovsk´a, and P. Han´aˇcek, “Comprehensive Multiparametric Analysis of Human Deepfake Speech Recognition,”EURASIP Journal on Image and Video Processing, vol. 2024, no. 24, pp. 1–25, 2024
2024
-
[70]
LibriV ox,
“LibriV ox,” https://librivox.org/, accessed: 08-02-2026 [online]
2026
-
[71]
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech,” inInterspeech 2019, 2019, pp. 1526–1530
2019
-
[72]
The LJ Speech Dataset,
K. Ito and L. Johnson, “The LJ Speech Dataset,” https://keithito. com/LJ-Speech-Dataset/, 2017
2017
-
[73]
Lib- rispeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: An ASR corpus based on public domain audio books,” in2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210
2015
-
[74]
MLS: A Large-Scale Multilingual Dataset for Speech Research,
V . Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert, “MLS: A Large-Scale Multilingual Dataset for Speech Research,” inInterspeech 2020, 2020, pp. 2757–2761
2020
-
[75]
AIShell-1: An Open-Source Mandarin Speech Corpus and A Speech Recogni- tion Baseline,
H. Bu, J. Du, X. Na, B. Wu, and H. Zheng, “AIShell-1: An Open-Source Mandarin Speech Corpus and A Speech Recogni- tion Baseline,” inOriental COCOSDA 2017, 2017
2017
-
[76]
CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR V oice Cloning Toolkit,
J. Yamagishi, C. Veaux, and K. MacDonald, “CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR V oice Cloning Toolkit,” University of Edinburgh. The Centre for Speech Technology Research (CSTR), Tech. Rep., 2019. [Online]. Available: https://doi.org/10.7488/ds/2645
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.