What Do Deepfake Speech Detectors Actually Hear?
Pith reviewed 2026-06-27 11:36 UTC · model grok-4.3
The pith
Deepfake speech detectors rely on distinct cues despite similar performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
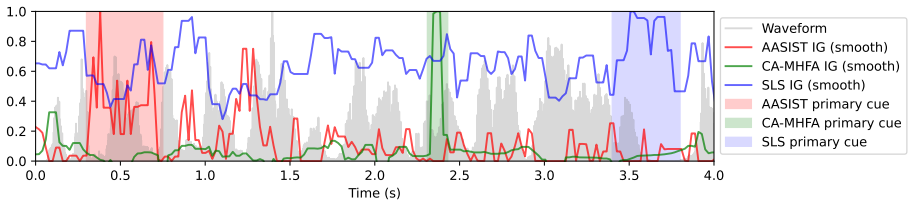
The central discovery is that three WavLM-based detectors with similar performance on ASVspoof 5 actually rely on different cues in the audio: AASIST emphasizes non-speech/environment cues, CA-MHFA focuses on localized phoneme artifacts, and SLS relies on word boundaries and spectral integrity. This is established through an audio-native explainability pipeline using Integrated Gradients on time-aligned self-supervised representations, with semantic annotation of high-attribution regions and validation via causal masking experiments that degrade performance.
What carries the argument
An audio-native explainability pipeline applying Integrated Gradients to time-aligned self-supervised representations to localize and annotate decision evidence over time in audio samples.
If this is right
- Different detectors may be vulnerable to distinct manipulation strategies targeting their specific cues.
- Benchmark performance alone does not reveal whether detectors are using consistent or meaningful evidence for deepfake identification.
- Removing the identified cue regions through masking leads to measurable drops in detection accuracy, confirming the role of those cues.
Where Pith is reading between the lines
- The variation in cues suggests detectors may be picking up on dataset artifacts specific to ASVspoof 5 rather than general deepfake properties.
- Combining detectors that focus on complementary cues could lead to more robust systems.
- The pipeline could be extended to other audio tasks to understand model decision processes beyond speech deepfakes.
Load-bearing premise
The Integrated Gradients method applied to time-aligned self-supervised representations correctly identifies the regions containing the cues that the detector uses for its decision, and the manual annotations accurately reflect those cues without significant bias.
What would settle it
Observing no significant performance drop when the highest-attribution regions are masked in the audio inputs would indicate that those regions do not contain the primary decision evidence.
Figures
read the original abstract
Deepfake speech detectors often output a single score without explaining why an audio sample is flagged, where in the signal the evidence lies, or what cues drive the decision. We propose an audio-native explainability pipeline using Integrated Gradients on time-aligned self-supervised representations to localize decision evidence over time. We apply the proposed method to three WavLM-based detectors (AASIST, CA-MHFA, SLS) on ASVspoof 5 and manually annotate the highest-attribution regions to provide a semantic meaning of the most important cues. Despite similar performance, the detectors rely on different cues: AASIST emphasizes non-speech/environment cues, CA-MHFA focuses on localized phoneme artifacts, and SLS relies on word boundaries and spectral integrity. We move beyond speculative reasoning and validate our findings by causal masking of the primary detector cues. Observed performance degradation further supports the explained detector semantics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an audio-native explainability pipeline that applies Integrated Gradients to time-aligned WavLM representations to localize decision evidence in three WavLM-based deepfake speech detectors (AASIST, CA-MHFA, SLS) evaluated on ASVspoof 5. It reports that the detectors rely on qualitatively different cues despite similar performance—AASIST on non-speech/environmental signals, CA-MHFA on localized phoneme artifacts, and SLS on word boundaries and spectral integrity—and validates these interpretations via manual annotation of high-attribution regions followed by causal masking that produces performance degradation.
Significance. If the attributions prove faithful and the semantic labels accurate, the work supplies concrete, comparative insight into why otherwise comparable detectors succeed or fail, which could guide architecture choices and robustness improvements. The inclusion of a masking-based validation step is a positive step beyond purely post-hoc speculation.
major comments (4)
- [Section 3] Attribution method (Section 3): No quantitative faithfulness checks for the Integrated Gradients attributions are reported (e.g., comparison against ground-truth synthetic artifacts, sanity checks, or alternative explainers such as occlusion or SHAP), which is load-bearing because the entire cue-localization and semantic-interpretation pipeline rests on these attributions being faithful to the models' actual decision evidence.
- [Section 4] Cue annotation procedure (Section 4): The manual semantic labeling of highest-attribution segments lacks any reported inter-annotator agreement statistics, annotation guidelines, or blinding protocol; this subjectivity directly affects the central claim that the three detectors specialize in distinct cue types (non-speech vs. phoneme artifacts vs. word boundaries).
- [Section 5] Causal masking validation (Section 5): The observed performance drops after masking high-attribution regions could arise from distribution shift or edge artifacts introduced into the shared WavLM front-end rather than from removal of the claimed semantic cues; no control experiments (random masking of equal duration or low-attribution regions) are described to isolate the effect.
- [Section 4.3] Model comparison (Section 4.3): Because AASIST, CA-MHFA, and SLS all share the identical WavLM front-end, any systematic differences in how masking interacts with their respective downstream heads could produce the reported degradation pattern without implying the claimed semantic specialization; additional analysis separating front-end from head contributions is needed to support the central claim.
minor comments (3)
- [Abstract and Section 3] The abstract and methods should explicitly state the exact WavLM layer(s) used for time-alignment and the precise masking procedure (e.g., zeroing, noise replacement, or interpolation).
- [Figures 3-5 and Table 2] Figure captions and tables reporting attribution statistics should include error bars or confidence intervals across multiple seeds or folds.
- [Introduction] A brief discussion of related audio explainability methods (e.g., prior work on gradient-based or attention-based explanations for speech models) is missing from the introduction.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. The suggestions identify opportunities to strengthen the validation of our explainability pipeline. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Section 3] Attribution method (Section 3): No quantitative faithfulness checks for the Integrated Gradients attributions are reported (e.g., comparison against ground-truth synthetic artifacts, sanity checks, or alternative explainers such as occlusion or SHAP), which is load-bearing because the entire cue-localization and semantic-interpretation pipeline rests on these attributions being faithful to the models' actual decision evidence.
Authors: We agree that quantitative faithfulness metrics would increase confidence in the attributions. In the revised version we will add (i) occlusion-based attribution comparisons on a subset of samples and (ii) sanity checks consisting of model-weight randomization and input-permutation tests, following standard practices in the XAI literature. These additions will be reported in an expanded Section 3. revision: yes
-
Referee: [Section 4] Cue annotation procedure (Section 4): The manual semantic labeling of highest-attribution segments lacks any reported inter-annotator agreement statistics, annotation guidelines, or blinding protocol; this subjectivity directly affects the central claim that the three detectors specialize in distinct cue types (non-speech vs. phoneme artifacts vs. word boundaries).
Authors: The annotations were performed by two authors with speech-processing expertise following an internal protocol that we will document in the appendix. We will also report Cohen’s kappa on a 20 % overlap subset in the revision. Because the primary evidence for cue specialization is the causal-masking performance drop rather than the labels themselves, we view the annotation step as interpretive support rather than the sole foundation of the claim. revision: partial
-
Referee: [Section 5] Causal masking validation (Section 5): The observed performance drops after masking high-attribution regions could arise from distribution shift or edge artifacts introduced into the shared WavLM front-end rather than from removal of the claimed semantic cues; no control experiments (random masking of equal duration or low-attribution regions) are described to isolate the effect.
Authors: We will add two control conditions in the revised Section 5: (a) random masking of equal total duration and (b) masking of the lowest-attribution regions. These controls will be run on the same evaluation set and reported alongside the original high-attribution masking results to demonstrate specificity. revision: yes
-
Referee: [Section 4.3] Model comparison (Section 4.3): Because AASIST, CA-MHFA, and SLS all share the identical WavLM front-end, any systematic differences in how masking interacts with their respective downstream heads could produce the reported degradation pattern without implying the claimed semantic specialization; additional analysis separating front-end from head contributions is needed to support the central claim.
Authors: Because Integrated Gradients is applied to the time-aligned WavLM representations that serve as input to each downstream head, the observed attribution differences already reflect how each head selectively weights the same front-end features. We will add a short analysis that compares attribution statistics before and after the first head layer to further isolate head-specific selection. Full ablation of the front-end would require retraining, which lies outside the scope of the current study. revision: partial
Circularity Check
No significant circularity; empirical application of standard methods on public benchmark.
full rationale
The paper applies Integrated Gradients (a pre-existing attribution technique) to time-aligned WavLM features from three published detectors, performs manual semantic annotation of high-attribution segments, and validates via masking on the ASVspoof 5 benchmark. No equations, fitted parameters, or self-citations are used to derive the reported cue semantics; the central findings are observational and externally falsifiable against the benchmark data. No self-definitional loops, fitted-input predictions, or load-bearing self-citation chains appear in the described derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Integrated Gradients attributions on time-aligned WavLM features correctly identify the audio regions driving detector decisions
Reference graph
Works this paper leans on
-
[1]
In re- sponse, deepfake speech detectors are employed as the primary defense [1, 2, 3]
Introduction High-quality speech deepfakes are now easy to generate. In re- sponse, deepfake speech detectors are employed as the primary defense [1, 2, 3]. A key limitation is that these systems typically output a single score [4, 5], with little insight intowhya record- ing received the score,wherein the utterance the detector finds evidence, orwhattype...
-
[2]
Pretrained models like Wav2Vec 2.0 [15, 16] and WavLM [7, 17] are favored for their ability to extract rich speaker representations directly from raw audio
Background Current deepfake detection systems rely on architectures that use SSL front-ends [14]. Pretrained models like Wav2Vec 2.0 [15, 16] and WavLM [7, 17] are favored for their ability to extract rich speaker representations directly from raw audio. These features are processed most often by AASIST [8, 18, 19], SLS [6, 20], or (CA-)MHFA [10, 11, 21]....
-
[3]
Method To interpret the decision-making logic of deepfake detectors, we employ the Integrated Gradients (IG) [13] method. IG enables precise attribution of decision scores, which is crucial for dis- tinguishing whether a model detects genuine synthesis artifacts or merely exploits channel-specific noise. 3.1. Integrated Gradients for SSL Representations G...
Pith/arXiv arXiv 2026
-
[4]
The annotators can input a gen- eral observation about the recording
The analyzed recording and its spectrogram are presented to the annotators for inspection. The annotators can input a gen- eral observation about the recording
-
[5]
•Primary cue:Annotators identify a primary segment that corresponds to the highest IG attributions
A series of annotations is gathered for each of the detectors. •Primary cue:Annotators identify a primary segment that corresponds to the highest IG attributions. •Cue type:Each identified cue is assigned a type from a predefined set: local glitch, phoneme content/articulation, voiced-unvoiced transition, silence, breath, channel/codec noise, spectral art...
-
[6]
The protocol is designed to both localize the dominant evi- dence driving the detector’s decision and assign an interpretable semantic label to that evidence
Finally, for the same recording, similarity or disparity be- tween the cues identified by different detectors is assessed. The protocol is designed to both localize the dominant evi- dence driving the detector’s decision and assign an interpretable semantic label to that evidence. Our method is not model- agnostic and focuses on SSL-based models. But, imp...
-
[7]
All systems utilize the pre- trained WavLM Base+ model as the front-end feature extractor
Experimental Setup We evaluate three modern deepfake detection architectures: AASIST [8], Context-Aware MHFA (CA-MHFA) [10], and Sensitive Layer Selection (SLS) [6]. All systems utilize the pre- trained WavLM Base+ model as the front-end feature extractor. To ensure optimal adaptation, we employ a joint training strat- egy in which both the SSL front-end ...
-
[8]
s” fricative, CA-MHFA pinpointed a specific “e
Results Across the 100 examined recordings, we observe two dataset- level patterns: (1) most high-confidence errors are associated with aggressive compression; (2) the attack A28 (pretrained YourTTS [31]) dominates the high-confidence error category. Regarding the examined models, the IG annotations show that the three detectors rely on distinct cues, eff...
-
[9]
Conclusion We introduce an audio-native explainability pipeline that moves beyond speculative reasoning and empirically demonstrates which specific cues the detectors focus on. Through rigor- ous manual annotations and causal experimental validation, we identify the primary cues of the examined detectors and assign them semantic meaning: •AASISTacts as an...
-
[10]
Computational resources were provided by the e-INFRA CZ project (ID:90254), supported by the Ministry of Education, Youth and Sports of the Czech Re- public
Acknowledgments This work was supported by the Brno University of Technology internal project FIT-S-26-9011. Computational resources were provided by the e-INFRA CZ project (ID:90254), supported by the Ministry of Education, Youth and Sports of the Czech Re- public
-
[11]
The authors reviewed and edited the output as needed and take full respon- sibility for the publication’s content
Generative AI Use Disclosure During the preparation of this work, the authors used Generative AI Models (specifically Google Gemini, ChatGPT, and Gram- marly) for language editing and text refinement. The authors reviewed and edited the output as needed and take full respon- sibility for the publication’s content
-
[12]
ASVspoof 5: crowd- sourced speech data, deepfakes, and adversarial attacks at scale,
X. Wang, H. Delgado, H. Tak, J. weon Jung, H. jin Shim, M. Todisco, I. Kukanov, X. Liu, M. Sahidullah, T. H. Kinnunen, N. Evans, K. A. Lee, and J. Yamagishi, “ASVspoof 5: crowd- sourced speech data, deepfakes, and adversarial attacks at scale,” inThe Automatic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), 2024, pp. 1–8
2024
-
[13]
Deepfake speech de- tection: A spectrogram analysis,
A. Firc, K. Malinka, and P. Han ´aˇcek, “Deepfake speech de- tection: A spectrogram analysis,” inProceedings of the 39th ACM/SIGAPP Symposium on Applied Computing, ser. SAC ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 1312–1320
2024
-
[14]
Resilience of voice assistants to synthetic speech,
K. Malinkaet al., “Resilience of voice assistants to synthetic speech,” inComputer Security – ESORICS 2024. Cham: Springer Nature Switzerland, 2024, pp. 66–84
2024
-
[15]
Intema system description for the ASVspoof5 Challenge: power weighted score fusion,
A. Aliyev and A. Kondratev, “Intema system description for the ASVspoof5 Challenge: power weighted score fusion,” inThe Automatic Speaker Verification Spoofing Countermeasures Work- shop (ASVspoof 2024), 2024, pp. 152–157
2024
-
[16]
Enhancing spoofing detection in ASVspoof 5 Workshop 2024: fusion of WavLM- ResNet18-SA for optimal performance against speech deepfakes,
P.-C. Chan, W.-Y . Chen, and J.-C. Wang, “Enhancing spoofing detection in ASVspoof 5 Workshop 2024: fusion of WavLM- ResNet18-SA for optimal performance against speech deepfakes,” inThe Automatic Speaker Verification Spoofing Countermeasures Workshop, 2024, pp. 158–162
2024
-
[17]
Audio Deepfake Detection with Self-Supervised XLS-R and SLS Classifier,
Q. Zhang, S. Wen, and T. Hu, “Audio Deepfake Detection with Self-Supervised XLS-R and SLS Classifier,” inProceedings of the 32nd ACM International Conference on Multimedia, ser. MM ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 6765–6773. [Online]. Available: https: //doi.org/10.1145/3664647.3681345
-
[18]
Exploring WavLM back-ends for speech spoofing and deepfake detection,
T. Stourbe, V . Miara, T. Lepage, and R. Dehak, “Exploring WavLM back-ends for speech spoofing and deepfake detection,” inThe Automatic Speaker Verification Spoofing Countermeasures Workshop, 2024, pp. 72–78
2024
-
[19]
AASIST: Audio Anti-Spoofing Us- ing Integrated Spectro-Temporal Graph Attention Networks,
J.-w. Jung, H.-S. Heo, H. Tak, H.-j. Shim, J. S. Chung, B.-J. Lee, H.-J. Yu, and N. Evans, “AASIST: Audio Anti-Spoofing Us- ing Integrated Spectro-Temporal Graph Attention Networks,” in ICASSP 2022 - 2022 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2022, pp. 6367– 6371
2022
-
[20]
AASIST3: KAN-enhanced AASIST speech deepfake detection using SSL features and additional regularization for the ASVspoof 2024 Challenge,
K. Borodin, V . Kudryavtsev, D. Korzh, A. Efimenko, G. Mkrtchian, M. Gorodnichev, and O. Y . Rogov, “AASIST3: KAN-enhanced AASIST speech deepfake detection using SSL features and additional regularization for the ASVspoof 2024 Challenge,” inThe Automatic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), 2024, pp. 48–55
2024
-
[21]
CA-MHFA: A Context-Aware Multi-Head Fac- torized Attentive Pooling for SSL-Based Speaker Verification,
J. Peng, L. Mo ˇsner, L. Zhang, O. Plchot, T. Stafylakis, L. Burget, and J. ˇCernock´y, “CA-MHFA: A Context-Aware Multi-Head Fac- torized Attentive Pooling for SSL-Based Speaker Verification,” inICASSP , IEEE International Conference on Acoustics, Speech and Signal Processing - Proceedings. Hyderabad: IEEE Signal Processing Society, 2025, pp. 1–5. [Online...
2025
-
[22]
BUT systems and analyses for the ASVspoof 5 Challenge,
J. Rohdin, L. Zhang, P. Old ˇrich, V . Stanˇek, D. Mihola, J. Peng, T. Stafylakis, D. Beveraki, A. Silnova, J. Brukner, and L. Bur- get, “BUT systems and analyses for the ASVspoof 5 Challenge,” inThe Automatic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), 2024, pp. 24–31
2024
-
[23]
J. Peng, L. Zhang, J. Han, O. Plchot, J. Rohdin, T. Stafylakis, S. Wang, and J. ˇCernock´y, “Hybrid Pruning: In-Situ Compression of Self-Supervised Speech Models for Speaker Verification and Anti-Spoofing,” 2025. [Online]. Available: https://arxiv.org/abs/ 2508.16232
arXiv 2025
-
[24]
Axiomatic attribution for deep networks,
M. Sundararajan, A. Taly, and Q. Yan, “Axiomatic attribution for deep networks,” inProceedings of the 34th International Conference on Machine Learning - Volume 70, ser. ICML’17. JMLR.org, 2017, p. 3319–3328
2017
-
[25]
Evaluation framework for deepfake speech detection: a comparative study of state-of-the-art deepfake speech detectors,
A. Firc, K. Malinka, and P. Han ´aˇcek, “Evaluation framework for deepfake speech detection: a comparative study of state-of-the-art deepfake speech detectors,”Cybersecurity, vol. 8, no. 1, 2025
2025
-
[26]
wav2vec 2.0: a framework for self-supervised learning of speech representa- tions,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: a framework for self-supervised learning of speech representa- tions,” inProceedings of the 34th International Conference on Neural Information Processing Systems, ser. NIPS ’20. Red Hook, NY , USA: Curran Associates Inc., 2020
2020
-
[27]
SZU-AFS an- tispoofing system for the ASVspoof 5 Challenge,
Y . Xu, J. Zhong, S. Zheng, Z. Liu, and B. Li, “SZU-AFS an- tispoofing system for the ASVspoof 5 Challenge,” inThe Auto- matic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), 2024, pp. 64–71
2024
-
[28]
WavLM: Large-Scale Self-Supervised Pre- Training for Full Stack Speech Processing,
S. Chenet al., “WavLM: Large-Scale Self-Supervised Pre- Training for Full Stack Speech Processing,”IEEE Journal of Se- lected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[29]
A single end-to-end voice anti-spoofing model with graph attention and feature aggrega- tion for ASVspoof 5 Challenge,
W. Xia, H. Peng, L. Li, and Y . Ren, “A single end-to-end voice anti-spoofing model with graph attention and feature aggrega- tion for ASVspoof 5 Challenge,” inThe Automatic Speaker Ver- ification Spoofing Countermeasures Workshop (ASVspoof 2024), 2024, pp. 124–130
2024
-
[30]
Diffuse or Confuse: A Dif- fusion Deepfake Speech Dataset,
A. Firc, K. Malinka, and P. Han ´aˇcek, “Diffuse or Confuse: A Dif- fusion Deepfake Speech Dataset,” in2024 International Confer- ence of the Biometrics Special Interest Group (BIOSIG). IEEE, Sep. 2024, p. 1–7
2024
-
[31]
SCDF: A Speaker Characteristics Deepfake Speech Dataset for Bias Analysis,
V . Stanˇek, K. Srna, A. Firc, and K. Malinka, “SCDF: A Speaker Characteristics Deepfake Speech Dataset for Bias Analysis,” in BIOSIG 2025. Gesellschaft f ¨ur Informatik e.V ., 2025
2025
-
[32]
Evolutionary Multi-Objective Fusion of Deepfake Speech Detectors,
V . Stan ˇek, M. Pere ˇs´ıni, L. Sekanina, A. Firc, and K. Malinka, “Evolutionary Multi-Objective Fusion of Deepfake Speech Detectors,” 2026. [Online]. Available: https://arxiv.org/abs/2604. 01330
2026
-
[33]
ASVspoof 5 Challenge: advanced ResNet architectures for robust voice spoofing detec- tion,
A.-T. Dao, M. Rouvier, and D. Matrouf, “ASVspoof 5 Challenge: advanced ResNet architectures for robust voice spoofing detec- tion,” inThe Automatic Speaker Verification Spoofing Counter- measures Workshop (ASVspoof 2024), 2024, pp. 163–169
2024
-
[34]
Exploring generalization to unseen au- dio data for spoofing: insights from SSL models,
A. Kulkarni, H. M. Tran, A. Kulkarni, S. Dowerah, D. Lo- live, and M. M. Doss, “Exploring generalization to unseen au- dio data for spoofing: insights from SSL models,” inThe Auto- matic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), 2024, pp. 86–93
2024
-
[35]
Deepfakes as a threat to a speaker and facial recognition: An overview of tools and attack vectors,
A. Firc, K. Malinka, and P. Han ´aˇcek, “Deepfakes as a threat to a speaker and facial recognition: An overview of tools and attack vectors,”Heliyon, vol. 9, no. 4, p. e15090, 2023
2023
-
[36]
A Unified Approach to Inter- preting Model Predictions,
S. M. Lundberg and S.-I. Lee, “A Unified Approach to Inter- preting Model Predictions,” inAdvances in Neural Information Processing Systems, I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds., vol. 30. Curran Associates, Inc., 2017. [Online]. Avail- able: https://proceedings.neurips.cc/paper files/paper/2017/...
2017
-
[37]
Explaining Deep Learning Models for Spoofing and Deepfake Detection with Shapley Additive Explanations,
W. Ge, J. Patino, M. Todisco, and N. Evans, “Explaining Deep Learning Models for Spoofing and Deepfake Detection with Shapley Additive Explanations,” inICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), 2022, pp. 6387–6391
2022
-
[38]
”Why should I trust you?
M. T. Ribeiro, S. Singh, and C. Guestrin, “”Why should I trust you?”: Explaining the predictions of any classifier,” inProceed- ings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016, pp. 1135–1144
2016
-
[39]
Explainable Deepfake and Spoofing Detection: An Attack Analysis Using SHapley Additive exPlanations,
W. Ge, M. Todisco, and N. Evans, “Explainable Deepfake and Spoofing Detection: An Attack Analysis Using SHapley Additive exPlanations,” inThe Speaker and Language Recognition Work- shop (Odyssey 2022), 2022, pp. 70–76
2022
-
[40]
Recommendation ITU- T P.800.2: Mean opinion score interpretation and reporting,
International Telecommunication Union, “Recommendation ITU- T P.800.2: Mean opinion score interpretation and reporting,” In- ternational Telecommunication Union, Telecommunication Stan- dardization Sector (ITU-T), Geneva, Switzerland, Recommenda- tion P.800.2, May 2013
2013
-
[41]
Raw- boost: A raw data boosting and augmentation method applied to automatic speaker verification anti-spoofing,
H. Tak, M. Kamble, J. Patino, M. Todisco, and N. Evans, “Raw- boost: A raw data boosting and augmentation method applied to automatic speaker verification anti-spoofing,” inICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 6382–6386
2022
-
[42]
Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone,
E. Casanova, J. Weber, C. D. Shulby, A. C. Junior, E. G ¨olge, and M. A. Ponti, “Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone,” inInternational Con- ference on Machine Learning. PMLR, 2022, pp. 2709–2720
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.