A Unifying Lens on Supervised Fine-Tuning Through Target Distribution Design
Pith reviewed 2026-06-27 14:09 UTC · model grok-4.3
The pith
SFT improves when reframed as choosing a target probability distribution over tokens rather than fitting observed tokens exactly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
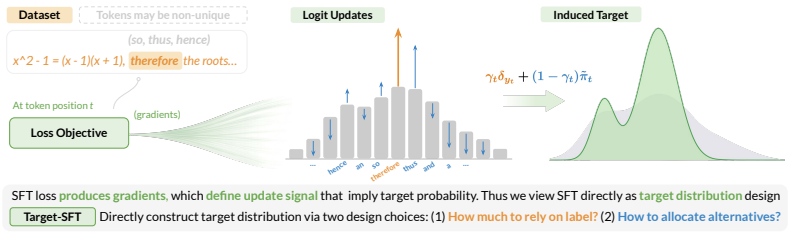
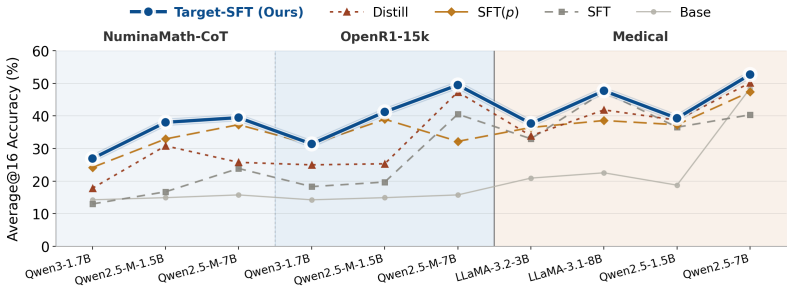
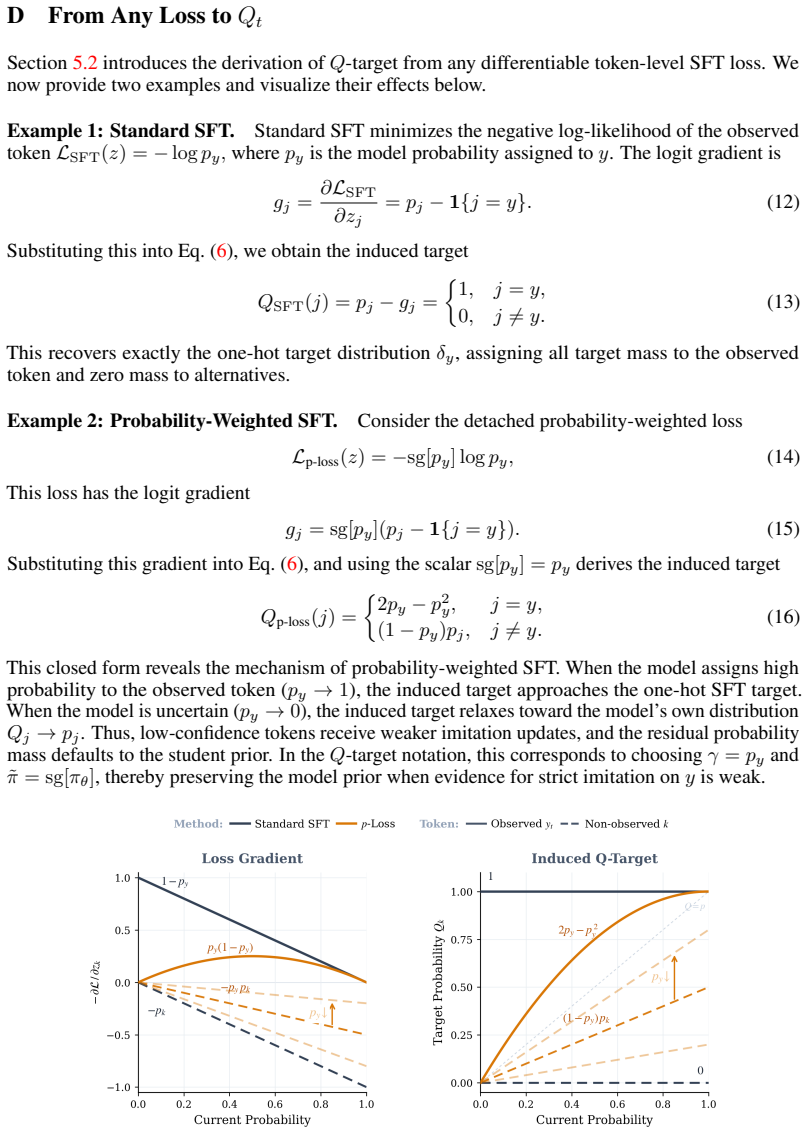
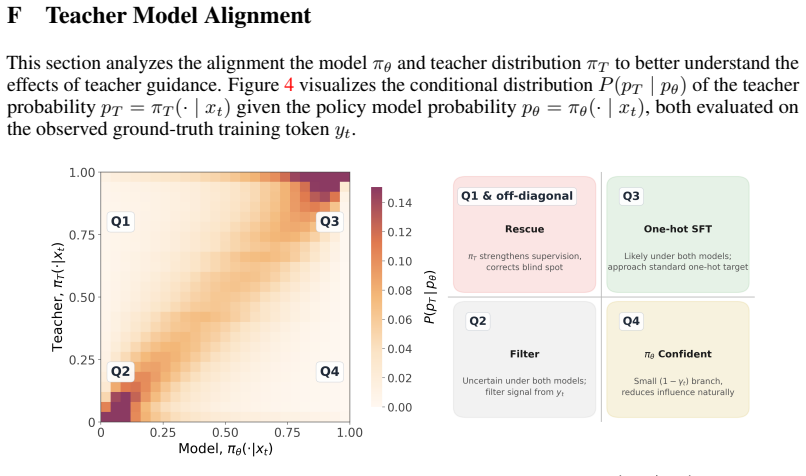
The paper establishes that SFT supervision decomposes into two explicit design choices: the strength of reliance on the observed token and the allocation of the remaining probability mass over alternatives. This decomposition, called the Q-target framework, shows that existing SFT methods are implicit selections of different target distributions Q. Target-SFT constructs the training objective directly from any desired target distribution and yields consistent gains over standard SFT on ten reasoning dataset-model combinations.
What carries the argument
The Q-target framework, which decomposes SFT supervision into reliance strength on the observed token and allocation of remaining probability mass to alternatives.
If this is right
- Many published SFT variants can be recovered as special cases inside the same target-distribution design space.
- Direct construction of the target distribution allows the loss to respect the pretrained model's existing knowledge more flexibly than one-hot targets.
- The same design principle expands the set of possible SFT objectives beyond conventional likelihood maximization.
- Performance differences among SFT methods should be re-examined by holding the effective target distribution fixed.
Where Pith is reading between the lines
- The same decomposition could be applied to fine-tuning regimes outside pure SFT, such as preference tuning or continued pretraining.
- Automated selection of the target distribution Q might be guided by measuring divergence between the pretrained model and the demonstration data.
- Comparisons of SFT methods on new tasks should report the effective target distribution used so that results remain comparable.
Load-bearing premise
The reported gains are produced by the choice of target distribution rather than by differences in hyperparameters, data processing, or evaluation procedures across the ten settings.
What would settle it
A controlled comparison in which Target-SFT and standard SFT use identical models, data, hyperparameters, and evaluation metrics and show no advantage or a reversal for Target-SFT.
Figures
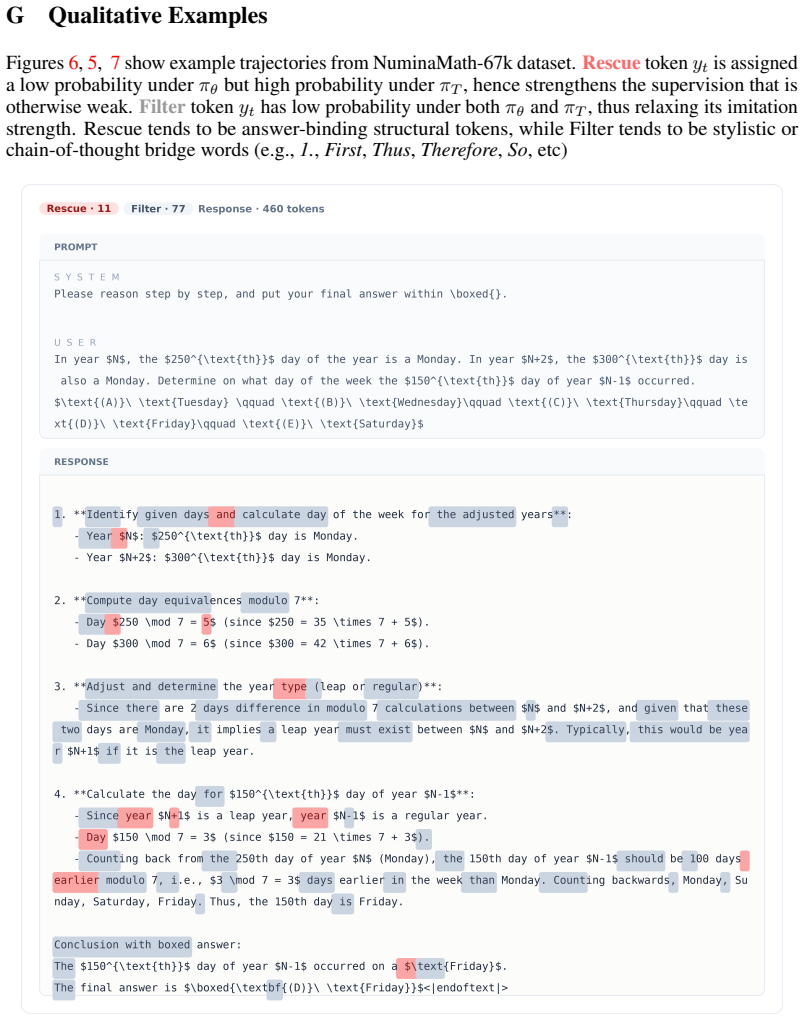

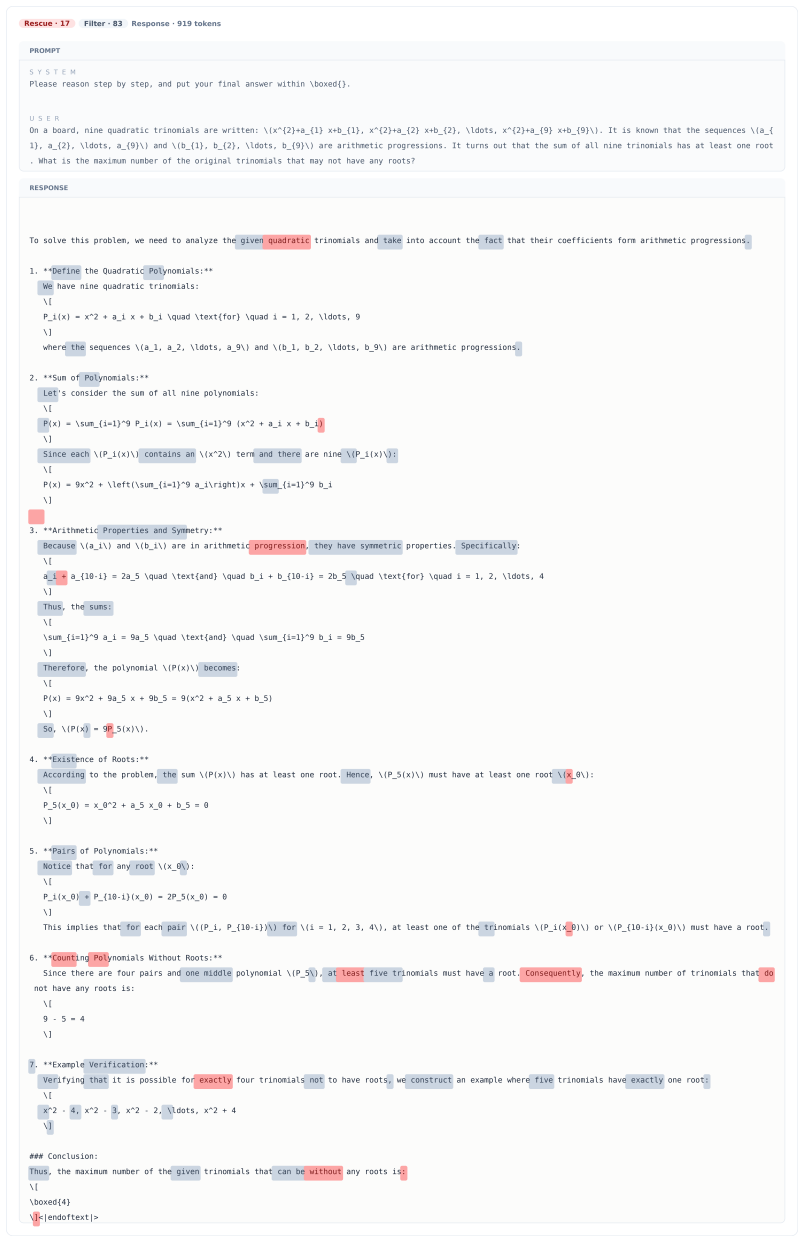
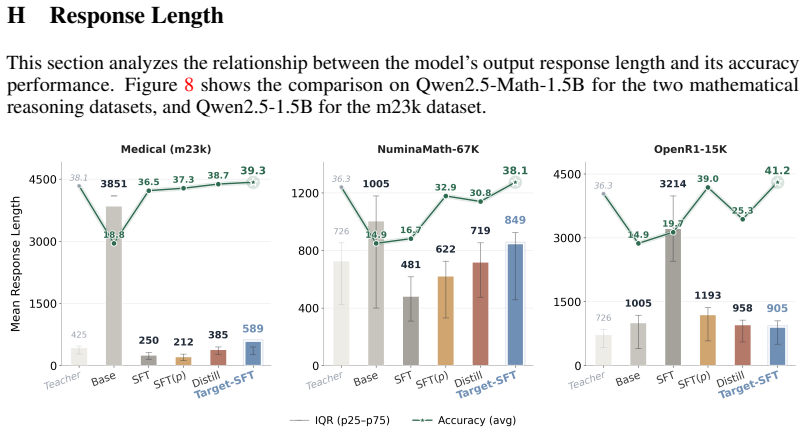
read the original abstract
Supervised fine-tuning (SFT) typically maximizes the likelihood of every token in a demonstrated trajectory. However, an observed token can be non-unique, noisy, or misaligned with the model prior. Strictly fitting toward this one-hot target may be suboptimal, especially when the pretrained model encodes a rich knowledge prior. In this work, we reinterpret SFT as target distribution design: instead of studying only the loss objective, we analyze the token-level target that the loss drives the model to match. We introduce the Q-target framework, which decomposes SFT supervision into two explicit choices: (1) how strongly to rely on the observed token, and (2) how to allocate the remaining probability mass over alternatives. This perspective unifies many existing SFT variants as implicit choices of the target distribution Q. Building on this view, we propose Target-SFT which constructs the training objective directly from the desired target distribution. This method consistently outperforms across the ten reasoning dataset-model settings evaluated, showing the effectiveness of this target-based approach. Overall, our formulation reveals a more fundamental design principle for SFT training and opens a broader search space for SFT objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reinterprets supervised fine-tuning (SFT) as target distribution design rather than solely a loss-function choice. It introduces the Q-target framework, which decomposes each token-level target into (1) the strength of reliance on the observed token and (2) the allocation of remaining probability mass over alternatives. This view is used to unify many existing SFT variants as implicit choices of Q. The authors then propose Target-SFT, which constructs the training objective directly from a user-specified target distribution Q, and report that it outperforms standard SFT across ten reasoning dataset-model settings.
Significance. If the performance gains are shown to be causally due to the explicit Q-target construction rather than incidental implementation differences, the work supplies both a unifying conceptual lens for SFT objectives and a practical method that could improve fine-tuning on reasoning tasks. The unification itself is a conceptual contribution independent of the empirical results.
major comments (2)
- [Abstract] Abstract: the claim that Target-SFT 'consistently outperforms across the ten reasoning dataset-model settings evaluated' is presented without any information on the baselines employed, whether all methods shared identical hyperparameters, data filtering, learning-rate schedules, or evaluation protocols, or whether statistical tests and error bars were used. This directly undermines the ability to attribute gains to the target-distribution design.
- [Abstract / presumed experimental section] The weakest assumption identified in the stress-test note—that reported gains are attributable to the Q-target decomposition rather than confounding factors—is not addressed by any ablation that holds non-target-related choices fixed while varying only the form of Q. Without such controls the central empirical claim remains unverified.
minor comments (1)
- [Abstract] The abstract refers to 'ten reasoning dataset-model settings' but does not name the datasets or models, reducing immediate reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for stronger controls to attribute performance gains to the Q-target framework. We provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that Target-SFT 'consistently outperforms across the ten reasoning dataset-model settings evaluated' is presented without any information on the baselines employed, whether all methods shared identical hyperparameters, data filtering, learning-rate schedules, or evaluation protocols, or whether statistical tests and error bars were used. This directly undermines the ability to attribute gains to the target-distribution design.
Authors: We agree the abstract would benefit from added context. In the full manuscript, all methods (including baselines such as standard SFT and other variants) were evaluated under identical conditions: the same models, training data, hyperparameters, learning-rate schedules, data filtering, and evaluation protocols. Error bars reflect multiple random seeds, and statistical significance was assessed. We will revise the abstract to state that comparisons were performed 'under identical experimental conditions with shared hyperparameters and evaluation protocols across methods.' revision: yes
-
Referee: [Abstract / presumed experimental section] The weakest assumption identified in the stress-test note—that reported gains are attributable to the Q-target decomposition rather than confounding factors—is not addressed by any ablation that holds non-target-related choices fixed while varying only the form of Q. Without such controls the central empirical claim remains unverified.
Authors: This is a fair point regarding causal attribution. While the current experiments control for many factors by using the same underlying implementation, we acknowledge the value of an explicit ablation isolating only the form of Q. We will add such an ablation in the revised manuscript, holding all non-target choices fixed while varying only the target distribution Q, to directly verify that gains stem from the Q-target design. revision: yes
Circularity Check
No circularity: framework is conceptual unification with independent empirical claims.
full rationale
The paper presents a reinterpretation of SFT as target distribution design and introduces the Q-target decomposition as a unifying lens. No equations, derivations, or self-citations are shown that reduce the proposed Target-SFT construction or its performance claims to fitted parameters or prior author results by definition. The unification of variants is presented as a perspective rather than a mathematical reduction, and the outperformance is an empirical observation across settings rather than a forced prediction. The derivation chain is self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Cross-entropy loss and token-level supervision remain the underlying training primitives.
invented entities (1)
-
Q-target
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Instruction tuning for large language models: A survey, 2025
Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Fei Wu, and Guoyin Wang. Instruction tuning for large language models: A survey, 2025
2025
-
[2]
Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping H...
2022
-
[3]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback, 2022
2022
-
[4]
The false promise of imitating proprietary llms, 2023
Arnav Gudibande, Eric Wallace, Charlie Snell, Xinyang Geng, Hao Liu, Pieter Abbeel, Sergey Levine, and Dawn Song. The false promise of imitating proprietary llms, 2023
2023
-
[5]
Preserving diversity in supervised fine-tuning of large language models, 2025
Ziniu Li, Congliang Chen, Tian Xu, Zeyu Qin, Jiancong Xiao, Zhi-Quan Luo, and Ruoyu Sun. Preserving diversity in supervised fine-tuning of large language models, 2025
2025
-
[6]
Beyond log likelihood: Probability-based objectives for supervised fine-tuning across the model capability continuum, 2026
Gaotang Li, Ruizhong Qiu, Xiusi Chen, Heng Ji, and Hanghang Tong. Beyond log likelihood: Probability-based objectives for supervised fine-tuning across the model capability continuum, 2026
2026
-
[7]
A survey on data selection for llm instruction tuning.Journal of Artificial Intelligence Research, 83, August 2025
Bolin Zhang, Jiahao Wang, Qianlong Du, Jiajun Zhang, Zhiying Tu, and Dianhui Chu. A survey on data selection for llm instruction tuning.Journal of Artificial Intelligence Research, 83, August 2025
2025
-
[8]
A survey on data selection for language models, 2024
Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, Colin Raffel, Shiyu Chang, Tatsunori Hashimoto, and William Yang Wang. A survey on data selection for language models, 2024
2024
-
[9]
Scaling relationship on learning mathematical reasoning with large language models, 2023
Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Keming Lu, Chuanqi Tan, Chang Zhou, and Jingren Zhou. Scaling relationship on learning mathematical reasoning with large language models, 2023
2023
-
[10]
Lima: Less is more for alignment, 2023
Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. Lima: Less is more for alignment, 2023
2023
-
[11]
Profit: Leveraging high-value signals in sft via probability-guided token selection, 2026
Tao Liu, Taiqiang Wu, Runming Yang, Shaoning Sun, Junjie Wang, and Yujiu Yang. Profit: Leveraging high-value signals in sft via probability-guided token selection, 2026
2026
-
[12]
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning, 2025
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning, 2025
2025
-
[13]
On the generalization of sft: A reinforcement learning perspective with reward rectification, 2026
Yongliang Wu, Yizhou Zhou, Zhou Ziheng, Yingzhe Peng, Xinyu Ye, Xinting Hu, Wenbo Zhu, Lu Qi, Ming-Hsuan Yang, and Xu Yang. On the generalization of sft: A reinforcement learning perspective with reward rectification, 2026
2026
-
[14]
Le, Sergey Levine, and Yi Ma
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V . Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training, 2025. 10
2025
-
[15]
Rl’s razor: Why online reinforcement learning forgets less, 2025
Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal. Rl’s razor: Why online reinforcement learning forgets less, 2025
2025
-
[16]
Retaining by doing: The role of on-policy data in mitigating forgetting, 2025
Howard Chen, Noam Razin, Karthik Narasimhan, and Danqi Chen. Retaining by doing: The role of on-policy data in mitigating forgetting, 2025
2025
-
[17]
Calibrated language models and how to find them with label smoothing, 2025
Jerry Huang, Peng Lu, and Qiuhao Zeng. Calibrated language models and how to find them with label smoothing, 2025
2025
-
[18]
The best instruction-tuning data are those that fit, 2026
Dylan Zhang, Qirun Dai, and Hao Peng. The best instruction-tuning data are those that fit, 2026
2026
-
[19]
Enhancing large language model reasoning via selective critical token fine-tuning, 2025
Zhiwen Ruan, Yixia Li, He Zhu, Yun Chen, Peng Li, Yang Liu, and Guanhua Chen. Enhancing large language model reasoning via selective critical token fine-tuning, 2025
2025
-
[20]
Entropy-adaptive fine-tuning: Resolving confident conflicts to mitigate forgetting, 2026
Muxi Diao, Lele Yang, Wuxuan Gong, Yutong Zhang, Zhonghao Yan, Yufei Han, Kongming Liang, Weiran Xu, and Zhanyu Ma. Entropy-adaptive fine-tuning: Resolving confident conflicts to mitigate forgetting, 2026
2026
-
[21]
Anchored supervised fine-tuning, 2026
He Zhu, Junyou Su, Peng Lai, Ren Ma, Wenjia Zhang, Linyi Yang, and Guanhua Chen. Anchored supervised fine-tuning, 2026
2026
-
[22]
Proximal supervised fine-tuning, 2026
Wenhong Zhu, Ruobing Xie, Rui Wang, Xingwu Sun, Di Wang, and Pengfei Liu. Proximal supervised fine-tuning, 2026
2026
-
[23]
Supervised fine tuning on curated data is reinforce- ment learning (and can be improved), 2025
Chongli Qin and Jost Tobias Springenberg. Supervised fine tuning on curated data is reinforce- ment learning (and can be improved), 2025
2025
-
[24]
Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models, 2024
2024
-
[25]
Alpagasus: Training a better alpaca with fewer data, 2024
Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, and Hongxia Jin. Alpagasus: Training a better alpaca with fewer data, 2024
2024
-
[26]
Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J
Avi Singh, John D. Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J. Liu, James Harrison, Jaehoon Lee, Kelvin Xu, Aaron Parisi, Abhishek Kumar, Alex Alemi, Alex Rizkowsky, Azade Nova, Ben Adlam, Bernd Bohnet, Gamaleldin Elsayed, Hanie Sedghi, Igor Mordatch, Isabelle Simpson, Izzeddin Gur, Jasper Snoek, Jeffrey Pennington, Jiri...
2024
-
[27]
Self-play fine-tuning converts weak language models to strong language models, 2024
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models, 2024
2024
-
[28]
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. Star: Bootstrapping reasoning with reasoning, 2022
2022
-
[29]
A minimalist approach to llm reasoning: from rejection sampling to reinforce, 2025
Wei Xiong, Jiarui Yao, Yuhui Xu, Bo Pang, Lei Wang, Doyen Sahoo, Junnan Li, Nan Jiang, Tong Zhang, Caiming Xiong, and Hanze Dong. A minimalist approach to llm reasoning: from rejection sampling to reinforce, 2025
2025
-
[30]
Self-distillation bridges distribution gap in language model fine-tuning, 2024
Zhaorui Yang, Tianyu Pang, Haozhe Feng, Han Wang, Wei Chen, Minfeng Zhu, and Qian Liu. Self-distillation bridges distribution gap in language model fine-tuning, 2024
2024
-
[31]
Minillm: On-policy distillation of large language models, 2026
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: On-policy distillation of large language models, 2026
2026
-
[32]
Numinamath
Jia LI, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, Kashif Rasul, Longhui Yu, Albert Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, and Stanislas Polu. Numinamath. [https://huggingface.co/AI-MO/NuminaMath-CoT](https://github.com/ project-numina/aimo-progress-prize/blob/main/report/nu...
2024
-
[33]
Open-r1: a fully open reproduction of deepseek-r1
Elie Bakouch, Leandro von Werra, and Lewis Tunstall. Open-r1: a fully open reproduction of deepseek-r1. https://huggingface.co/blog/open-r1, January 2025. Hugging Face Blog
2025
-
[34]
Learning to reason under off-policy guidance, 2025
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance, 2025
2025
-
[35]
m1: Unleash the potential of test-time scaling for medical reasoning with large language models, 2026
Xiaoke Huang, Juncheng Wu, Hui Liu, Xianfeng Tang, and Yuyin Zhou. m1: Unleash the potential of test-time scaling for medical reasoning with large language models, 2026
2026
-
[36]
Distilling the knowledge in a neural network, 2015
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network, 2015
2015
-
[37]
Solving quantitative reasoning problems with language models, 2022
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models, 2022
2022
-
[38]
Ai mathematical olympiad - progress prize 1
XTX Investments. Ai mathematical olympiad - progress prize 1. https://kaggle.com/ competitions/ai-mathematical-olympiad-prize, 2024. Kaggle
2024
-
[39]
Aime thresholds are available
Mathematical Association of America. Aime thresholds are available. https://maa.org/ aime-thresholds-are-available/, 2024. Accessed: 2025-09-24
2024
-
[40]
Math competitions
Mathematical Association of America. Math competitions. https://maa.org/ math-competitions, 2023. Accessed: 2025-09-24
2023
-
[41]
Measuring mathematical problem solving with the math dataset, 2021
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset, 2021
2021
-
[42]
Medmcqa : A large-scale multi-subject multi-choice dataset for medical domain question answering, 2022
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa : A large-scale multi-subject multi-choice dataset for medical domain question answering, 2022
2022
-
[43]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams, 2020
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams, 2020
2020
-
[44]
Cohen, and Xinghua Lu
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William W. Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering, 2019
2019
-
[45]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark, 2024
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark, 2024
2024
-
[46]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark, 2023
2023
-
[47]
Benchmarking large language models on answering and explaining challenging medical questions, 2026
Hanjie Chen, Zhouxiang Fang, Yash Singla, and Mark Dredze. Benchmarking large language models on answering and explaining challenging medical questions, 2026
2026
-
[48]
Medxpertqa: Benchmarking expert-level medical reasoning and understanding, 2025
Yuxin Zuo, Shang Qu, Yifei Li, Zhangren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. Medxpertqa: Benchmarking expert-level medical reasoning and understanding, 2025. 12 A Experiment Details Training Configurations.All SFT experiments are conducted using verl, largely following the work by Li et al. [6]. The optimizer used is AdamW,...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.