MedCTA: A Benchmark for Clinical Tool Agents
Pith reviewed 2026-06-27 10:29 UTC · model grok-4.3
The pith
Even frontier multimodal models remain brittle in multi-step clinical tool use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
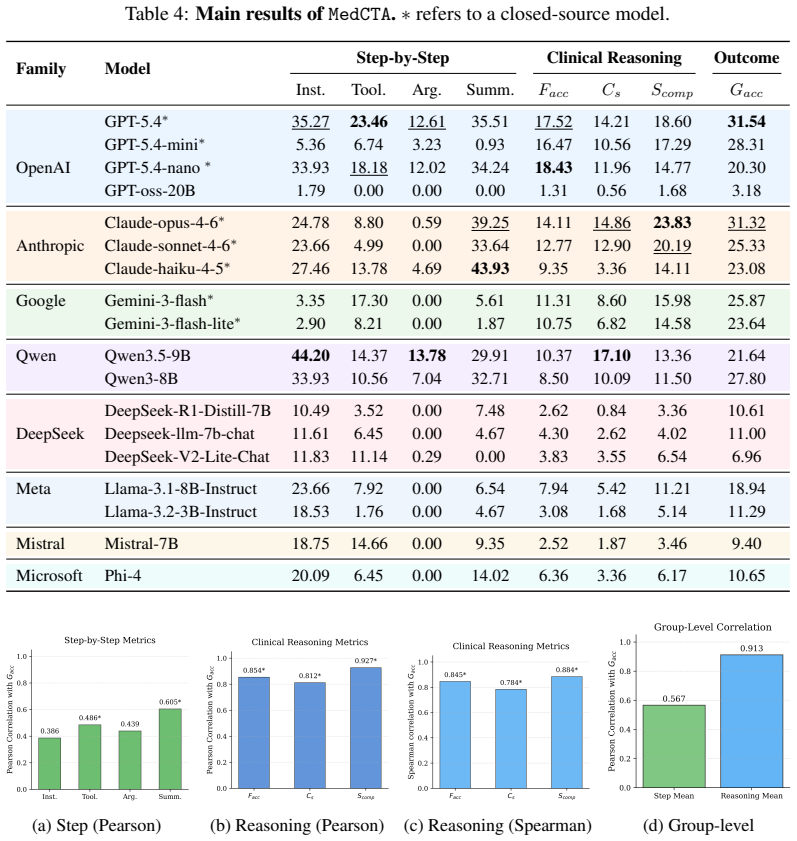
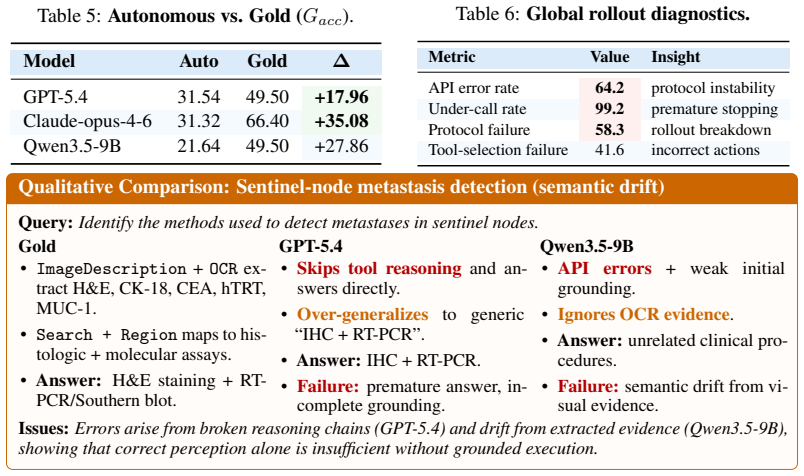
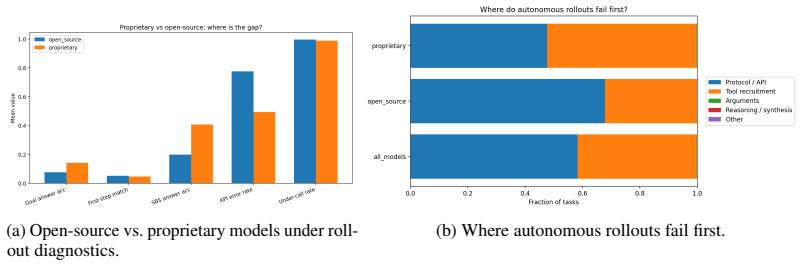
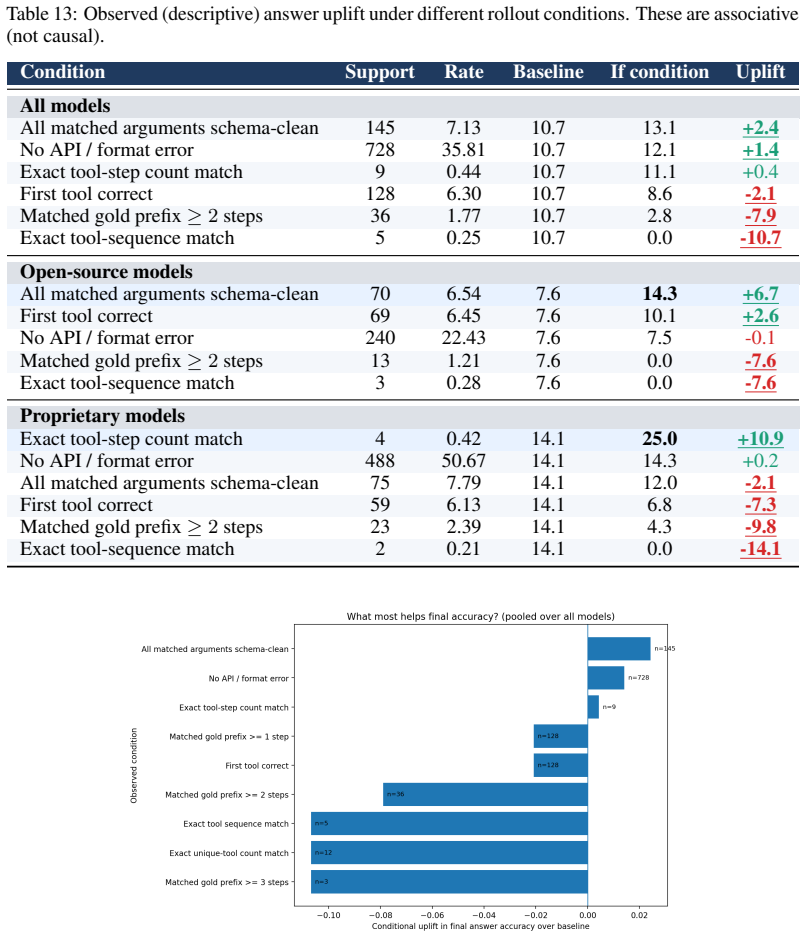
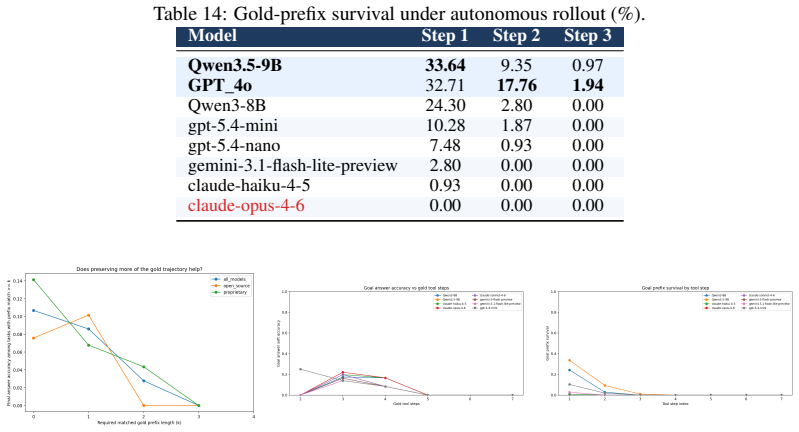
MedCTA shows that autonomous clinical tool agents fail primarily through protocol violations, early termination, and wrong tool selection, while even perfect tool routing yields large but incomplete improvements in trajectory fidelity and outcome quality.
What carries the argument
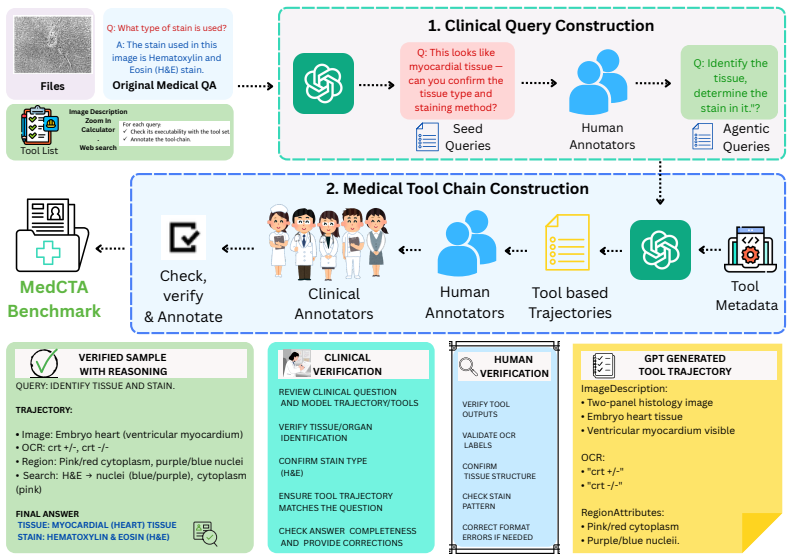
MedCTA benchmark of 107 tasks with clinician-verified executable trajectories over 5 tools, together with process-aware metrics for tool selection, argument validity, execution stability, trajectory fidelity, and outcome quality.
If this is right
- Strong perception alone is insufficient for reliable multi-step medical tool use.
- Protocol adherence and correct tool recruitment are primary bottlenecks in clinical agent rollouts.
- Gold-standard routing improves performance substantially but does not achieve full reliability.
- Process-aware evaluation is required to diagnose agent failures beyond final-answer accuracy.
Where Pith is reading between the lines
- The benchmark could be extended to measure how explicit planning modules reduce protocol failures.
- Hybrid perception-plus-reasoning systems may be needed before clinical deployment becomes feasible.
- Similar task sets could be created for other high-stakes domains such as legal or financial tool use.
Load-bearing premise
The 107 clinician-verified tasks and trajectories form a representative sample of real clinical workflows.
What would settle it
A model that sustains high trajectory fidelity and outcome quality across the full set of 107 tasks in fully autonomous rollouts without gold-standard routing would falsify the brittleness finding.
Figures






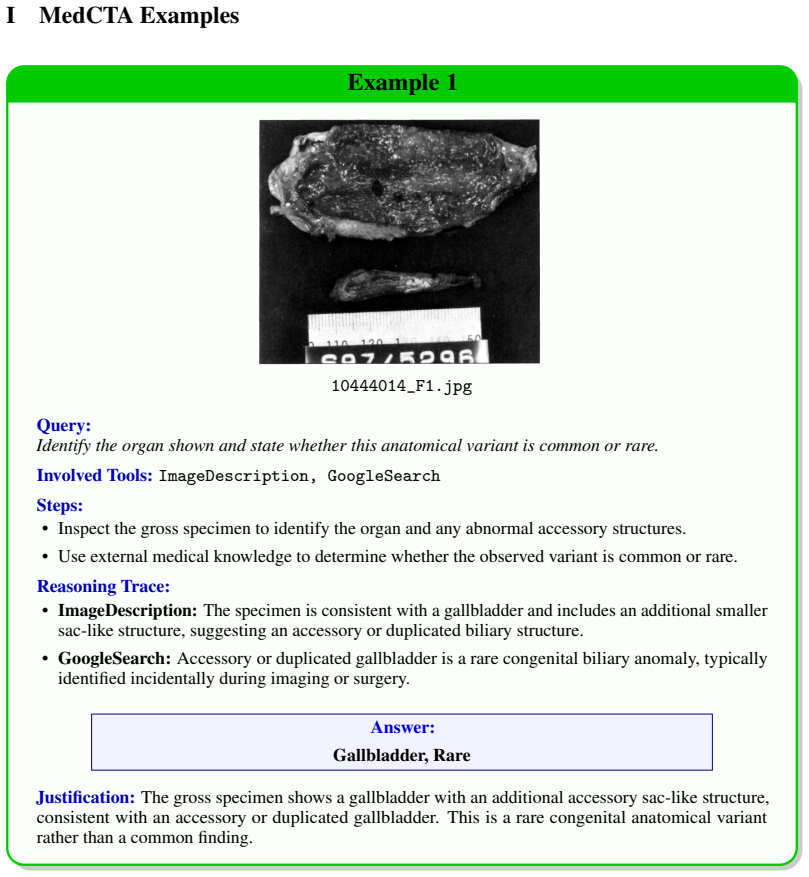

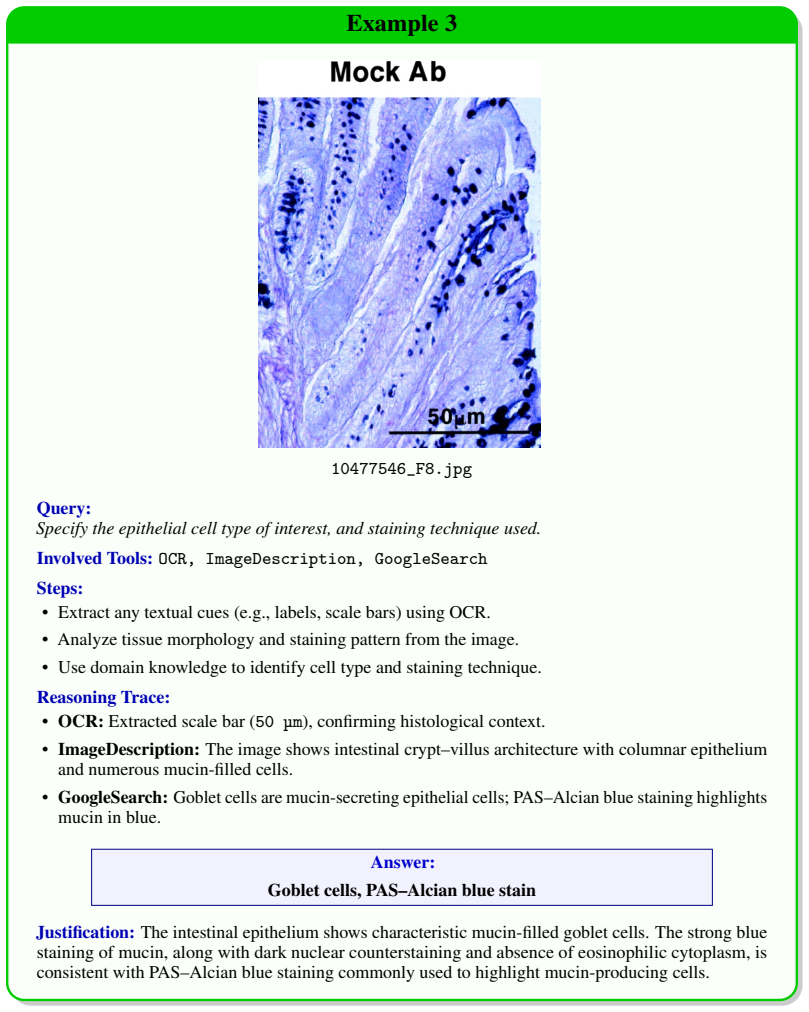

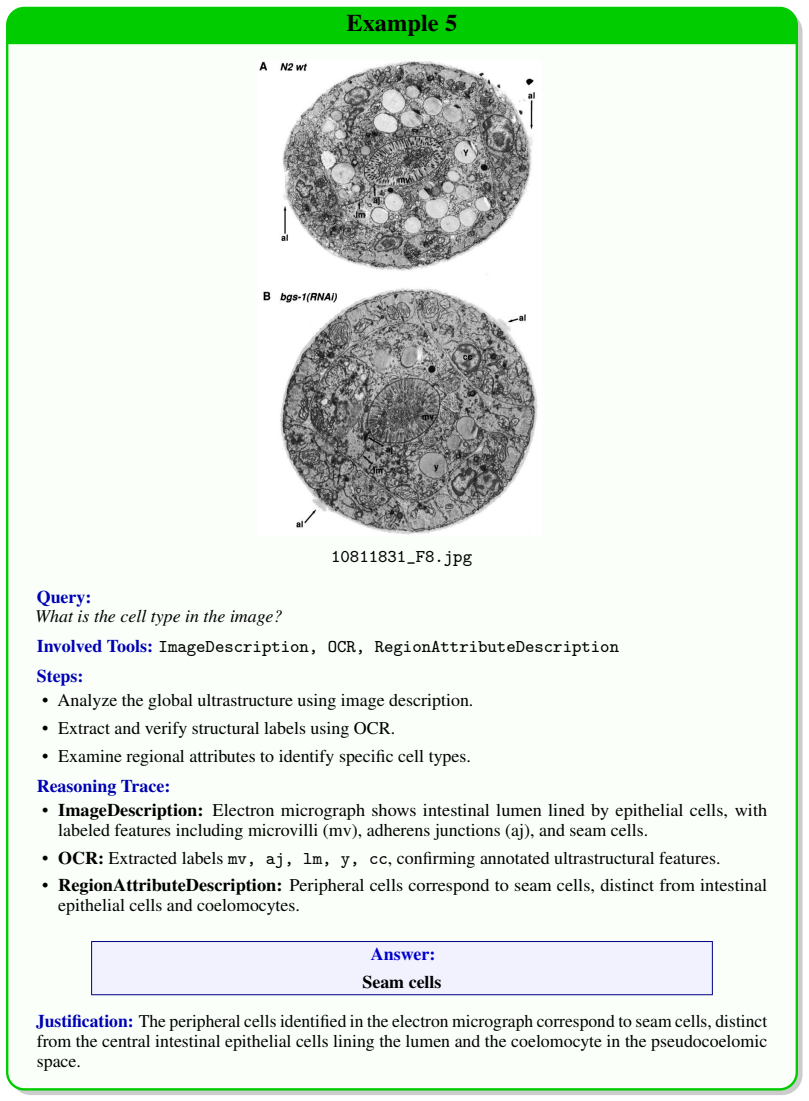

read the original abstract
To make clinically grounded decisions, medical AI agents are expected to go beyond simple recognition and be capable of tool retrieval, evidence acquisition, and integration. Existing benchmarks largely evaluate isolated perception or single-turn question answering, and therefore provide limited visibility into failures of planning, tool recruitment, and rollout reliability. We introduce MedCTA, a benchmark for evaluating medical tool agents on clinician-validated, step-implicit tasks grounded in realistic multimodal clinical inputs, including radiology images, pathology slides, and reports. MedCTA comprises 107 real-world clinical tasks with clinician-verified executable trajectories over 5 deployed tools, and supports process-aware evaluation of tool selection, argument validity, execution stability, trajectory fidelity, and outcome quality. We benchmark 18 open- and closed-source multimodal models and find that even frontier systems remain brittle in multi-step clinical tool use: autonomous rollouts are dominated by protocol failures, premature stopping, and incorrect tool recruitment, while gold-standard tool routing yields large but still incomplete gains. These results show that strong backbone perception does not translate into reliable agentic behavior in clinical settings. MedCTA provides a rigorous testbed for auditing, diagnosing, and advancing trustworthy medical AI agents. The dataset and evaluation suite are available at https://ivul-kaust.github.io/MedCTA/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MedCTA, a benchmark for clinical tool agents consisting of 107 clinician-verified tasks grounded in realistic multimodal clinical inputs (radiology images, pathology slides, reports). Tasks include executable trajectories over 5 deployed tools and support process-aware metrics on tool selection, argument validity, execution stability, trajectory fidelity, and outcome quality. Evaluation of 18 open- and closed-source multimodal models shows that frontier systems remain brittle in multi-step clinical tool use: autonomous rollouts are dominated by protocol failures, premature stopping, and incorrect tool recruitment, while gold-standard tool routing yields large but incomplete gains. The work concludes that strong backbone perception does not translate to reliable agentic behavior and releases the dataset publicly.
Significance. If the task construction, clinician verification, and metric definitions are robust, MedCTA provides a valuable diagnostic testbed that moves beyond single-turn perception or QA benchmarks to expose failures in planning, tool recruitment, and rollout reliability in clinical settings. The public release of tasks and evaluation suite supports reproducibility and community progress on trustworthy medical agents. The reported performance gap between autonomous and gold-standard routing is a concrete, actionable finding for model developers.
major comments (2)
- [§3] §3 (MedCTA composition): The claim that the 107 clinician-verified tasks form a representative sample for diagnosing agent reliability across real clinical workflows requires explicit reporting of selection criteria, exclusion rules, and inter-clinician agreement statistics; without these, the central brittleness result cannot be fully audited for selection bias or coverage.
- [§4.3] §4.3 (evaluation protocol): The distinction between autonomous rollouts and gold-standard tool routing is central to the main claim, yet the manuscript does not specify how gold-standard trajectories were constructed or whether they were held out from model prompting; this detail is load-bearing for interpreting the size of the reported gains.
minor comments (3)
- [Results] Table 1 or equivalent results table: clarify whether the 18 models include any fine-tuned variants or only zero-shot prompting, as this affects interpretation of the brittleness findings.
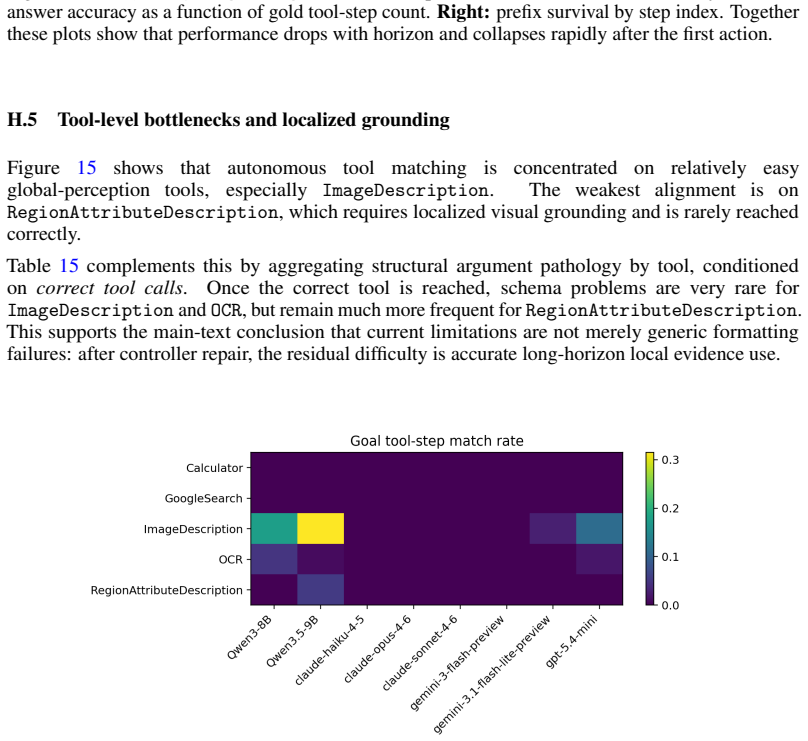
- [Figure 2] Figure 2 (failure mode breakdown): axis labels and legend should explicitly define 'protocol failure' and 'premature stopping' to match the textual definitions.
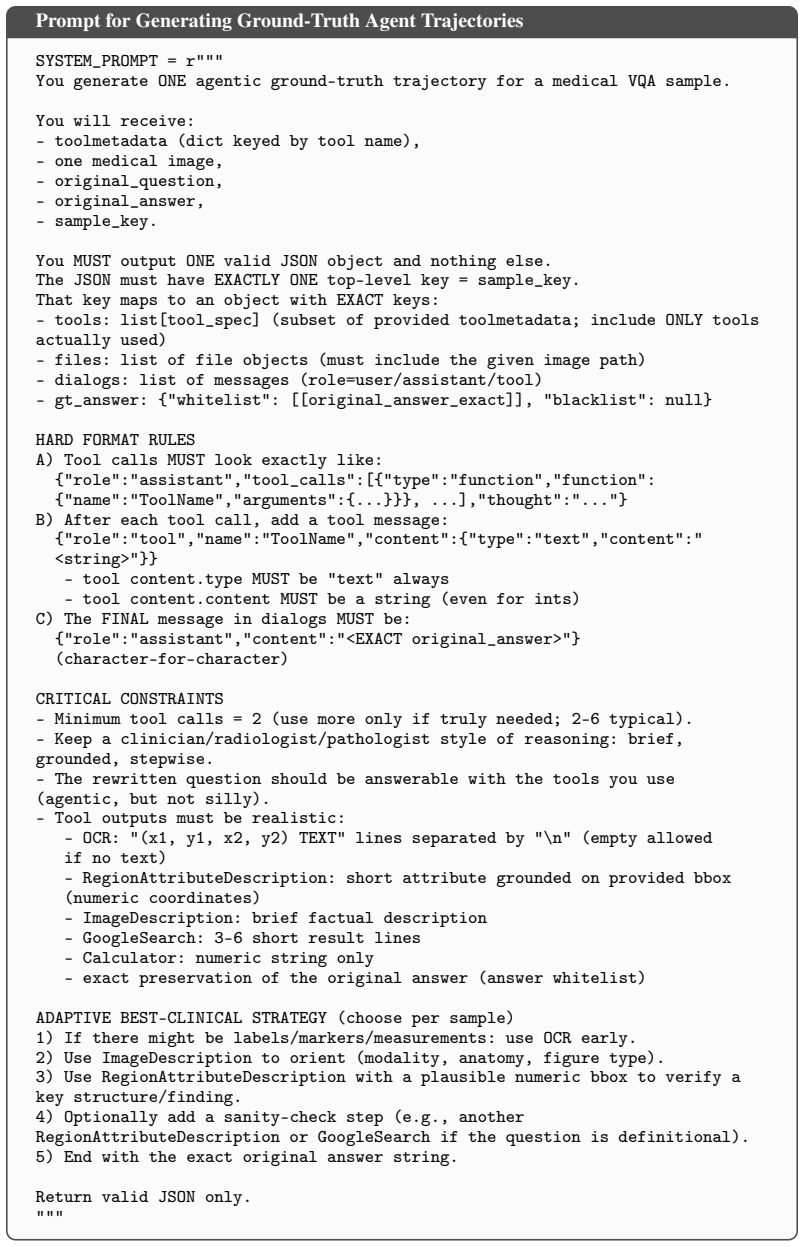
- [Methods] The abstract states 'step-implicit tasks' but the methods section should add a short example trajectory to illustrate what 'step-implicit' means operationally.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of MedCTA's potential value. We address each major comment below and will revise the manuscript accordingly to improve clarity and transparency.
read point-by-point responses
-
Referee: [§3] §3 (MedCTA composition): The claim that the 107 clinician-verified tasks form a representative sample for diagnosing agent reliability across real clinical workflows requires explicit reporting of selection criteria, exclusion rules, and inter-clinician agreement statistics; without these, the central brittleness result cannot be fully audited for selection bias or coverage.
Authors: We agree that explicit documentation of these elements is necessary for full auditability. In the revised manuscript we will expand §3 with: (i) the precise selection criteria used to sample the 107 tasks from real clinical workflows, (ii) the exclusion rules applied during curation, and (iii) inter-clinician agreement statistics (including Cohen’s kappa) obtained during verification. These additions will allow readers to evaluate coverage and potential selection bias directly. revision: yes
-
Referee: [§4.3] §4.3 (evaluation protocol): The distinction between autonomous rollouts and gold-standard tool routing is central to the main claim, yet the manuscript does not specify how gold-standard trajectories were constructed or whether they were held out from model prompting; this detail is load-bearing for interpreting the size of the reported gains.
Authors: We acknowledge the omission and will clarify the protocol. Gold-standard trajectories were authored by an independent panel of clinicians according to the task specifications; they were never supplied in the prompts used for autonomous model rollouts and serve exclusively as the reference for the gold-standard routing baseline. We will insert this description into §4.3 so that the magnitude of the reported gains can be interpreted unambiguously. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a new benchmark (MedCTA) with 107 clinician-verified tasks and executable trajectories over 5 tools, then reports empirical results from running 18 models under autonomous and gold-standard routing conditions. No equations, parameter fits, or derivations appear in the provided text. The central claims rest on new task collection and external model evaluations rather than any self-referential definitions, fitted inputs renamed as predictions, or load-bearing self-citations. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
Pith/arXiv arXiv 2024
-
[2]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[3]
The claude 3 model family: Opus, sonnet, haiku.Claude-3 Model Card, 2024
AI Anthropic. The claude 3 model family: Opus, sonnet, haiku.Claude-3 Model Card, 2024
2024
-
[4]
Tajamul Ashraf, Amal Saqib, Hanan Ghani, Muhra AlMahri, Yuhao Li, Noor Ahsan, Umair Nawaz, Jean Lahoud, Hisham Cholakkal, Mubarak Shah, et al. Agent-x: Evaluating deep multimodal reasoning in vision-centric agentic tasks.arXiv preprint arXiv:2505.24876, 2025
Pith/arXiv arXiv 2025
-
[5]
Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Pith/arXiv arXiv 2023
-
[6]
Suhana Bedi, Ryan Welch, Ethan Steinberg, Michael Wornow, Taeil Matthew Kim, Haroun Ahmed, Peter Sterling, Bravim Purohit, Qurat Akram, Angelic Acosta, et al. Healthadmin- bench: Evaluating computer-use agents on healthcare administration tasks.arXiv preprint arXiv:2604.09937, 2026. 10
Pith/arXiv arXiv 2026
-
[7]
Vqa-med: Overview of the medical visual question answering task at imageclef 2019
Asma Ben Abacha, Sadid A Hasan, Vivek V Datla, Dina Demner-Fushman, and Henning Müller. Vqa-med: Overview of the medical visual question answering task at imageclef 2019. InProceedings of CLEF (Conference and Labs of the Evaluation Forum) 2019 Working Notes. 9-12 September 2019, 2019
2019
-
[8]
Castro, Anton Schwaighofer, Stephanie L
Benedikt Boecking, Naoto Usuyama, Shruthi Bannur, Daniel C. Castro, Anton Schwaighofer, Stephanie L. Hyland, Maria T. Wetscherek, Tristan Naumann, Harsha Nori, Neeraj Ahuja, et al. Making the most of text semantics to improve biomedical vision–language processing, 2022
2022
-
[9]
Clinical reasoning of a generative artificial intelligence model compared with physicians.JAMA internal medicine, 184(5):581–583, 2024
Stephanie Cabral, Daniel Restrepo, Zahir Kanjee, Philip Wilson, Byron Crowe, Raja-Elie Abdulnour, and Adam Rodman. Clinical reasoning of a generative artificial intelligence model compared with physicians.JAMA internal medicine, 184(5):581–583, 2024
2024
-
[10]
Langchain, October 2022
Harrison Chase. Langchain, October 2022
2022
-
[11]
Review of medical image quality assessment
Li Sze Chow and Raveendran Paramesran. Review of medical image quality assessment. Biomedical signal processing and control, 27:145–154, 2016
2016
-
[12]
Opencompass: A universal evaluation platform for foundation models.https://github.com/open-compass/opencompass, 2023
OpenCompass Contributors. Opencompass: A universal evaluation platform for foundation models.https://github.com/open-compass/opencompass, 2023
2023
-
[13]
Ankan Deria, Komal Kumar, Adinath Madhavrao Dukre, Eran Segal, Salman Khan, and Imran Razzak. Medmo: Grounding and understanding multimodal large language model for medical images.arXiv preprint arXiv:2602.06965, 2026
arXiv 2026
-
[14]
Duncan and Nicholas Ayache
James S. Duncan and Nicholas Ayache. Medical image analysis: Progress over two decades and the challenges ahead.IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(1):85–106, 2000
2000
-
[15]
Medrax: Medical reasoning agent for chest x-ray.arXiv preprint arXiv:2502.02673, 2025
Adibvafa Fallahpour, Jun Ma, Alif Munim, Hongwei Lyu, and Bo Wang. Medrax: Medical reasoning agent for chest x-ray.arXiv preprint arXiv:2502.02673, 2025
arXiv 2025
-
[16]
Ai hospital: Benchmarking large language models in a multi-agent medical interaction simulator
Zhihao Fan, Lai Wei, Jialong Tang, Wei Chen, Siyuan Wang, Zhongyu Wei, Jun Xie, Fei Huang, and Jingren Zhou. Ai hospital: Benchmarking large language models in a multi-agent medical interaction simulator. InProceedings of the 31st International Conference on Computational Linguistics, pages 10183–10213. Association for Computational Linguistics, January 2025
2025
-
[17]
Autogpt, 2023
Significant Gravitas. Autogpt, 2023
2023
-
[18]
Xuehai He, Yichen Zhang, Luntian Mou, Eric Xing, and Pengtao Xie. Pathvqa: 30000+ questions for medical visual question answering.arXiv preprint arXiv:2003.10286, 2020
Pith/arXiv arXiv 2003
-
[19]
Omnimed- vqa: A new large-scale comprehensive evaluation benchmark for medical lvlm
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, and Ping Luo. Omnimed- vqa: A new large-scale comprehensive evaluation benchmark for medical lvlm. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22170–22183, 2024
2024
-
[20]
Mistral 7b.arXiv preprint arXiv:2310.06825, 2023
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b.arXiv preprint arXiv:2310.06825, 2023
Pith/arXiv arXiv 2023
-
[21]
Medagentbench: a virtual ehr environment to benchmark medical llm agents
Yixing Jiang, Kameron C Black, Gloria Geng, Danny Park, James Zou, Andrew Y Ng, and Jonathan H Chen. Medagentbench: a virtual ehr environment to benchmark medical llm agents. Nejm Ai, 2(9):AIdbp2500144, 2025
2025
-
[22]
Black, Gloria Geng, Danny Park, James Zou, Andrew Y
Yixing Jiang, Kameron C. Black, Gloria Geng, Danny Park, James Zou, Andrew Y . Ng, and Jonathan H. Chen. A virtual EHR environment to benchmark medical LLM agents.NEJM AI, 2025
2025
-
[23]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world GitHub issues?, 2023. 11
2023
-
[24]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
2021
-
[25]
Pubmedqa: A dataset for biomedical research question answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2567–2577, 2019
2019
-
[26]
Behaviorsft: Behavioral token conditioning for health agents across the proactivity spectrum
Yubin Kim, Zhiyuan Hu, Hyewon Jeong, Eugene W Park, Shuyue Stella Li, Chanwoo Park, Shiyun Xiong, MingYu Lu, Hyeonhoon Lee, Xin Liu, et al. Behaviorsft: Behavioral token conditioning for health agents across the proactivity spectrum. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 9789–9817, 2025
2025
-
[27]
Yubin Kim, Hyewon Jeong, Chanwoo Park, Eugene Park, Haipeng Zhang, Xin Liu, Hyeonhoon Lee, Daniel McDuff, Marzyeh Ghassemi, Cynthia Breazeal, et al. Tiered agentic oversight: A hierarchical multi-agent system for healthcare safety.arXiv preprint arXiv:2506.12482, 2025
arXiv 2025
-
[28]
Mdagents: An adaptive collaboration of llms for medical decision-making.Advances in Neural Information Processing Systems, 37:79410–79452, 2024
Yubin Kim, Chanwoo Park, Hyewon Jeong, Yik S Chan, Xuhai Xu, Daniel McDuff, Hyeon- hoon Lee, Marzyeh Ghassemi, Cynthia Breazeal, and Hae W Park. Mdagents: An adaptive collaboration of llms for medical decision-making.Advances in Neural Information Processing Systems, 37:79410–79452, 2024
2024
-
[29]
A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 5(1):180251, 2018
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 5(1):180251, 2018
2018
-
[30]
Mmedagent: Learning to use medical tools with multi-modal agent
Binxu Li, Tiankai Yan, Yuanting Pan, Jie Luo, Ruiyang Ji, Jiayuan Ding, Zhe Xu, Shilong Liu, Haoyu Dong, Zihao Lin, et al. Mmedagent: Learning to use medical tools with multi-modal agent. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 8745–8760, 2024
2024
-
[31]
Modelscope-agent: Building your cus- tomizable agent system with open-source large language models
Chenliang Li, He Chen, Ming Yan, Weizhou Shen, Haiyang Xu, Zhikai Wu, Zhicheng Zhang, Wenmeng Zhou, Yingda Chen, Chen Cheng, et al. Modelscope-agent: Building your cus- tomizable agent system with open-source large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 566–578, 2023
2023
-
[32]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day, 2023
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day, 2023
2023
-
[33]
A comprehensive benchmark for tool-augmented llms
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li API-bank. A comprehensive benchmark for tool-augmented llms. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3102–3116, 2023
2023
-
[34]
Ilgen, Emma Pierson, Pang Wei Koh, and Yulia Tsvetkov
Shuyue Stella Li, Vidhisha Balachandran, Shangbin Feng, Jonathan S. Ilgen, Emma Pierson, Pang Wei Koh, and Yulia Tsvetkov. Mediq: Question-asking LLMs and a benchmark for reliable interactive clinical reasoning, 2024
2024
-
[35]
Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering. In2021 IEEE 18th international symposium on biomedical imaging (ISBI), pages 1650–1654. IEEE, 2021
2021
-
[36]
Llava-plus: Learning to use tools for creating multimodal agents
Shilong Liu, Hao Cheng, Haotian Liu, Hao Zhang, Feng Li, Tianhe Ren, Xueyan Zou, Jianwei Yang, Hang Su, Jun Zhu, et al. Llava-plus: Learning to use tools for creating multimodal agents. InEuropean conference on computer vision, pages 126–142. Springer, 2024
2024
-
[37]
Deepseek-vl: towards real-world vision-language understanding.arXiv preprint arXiv:2403.05525, 2024
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Yaofeng Sun, et al. Deepseek-vl: towards real-world vision-language understanding.arXiv preprint arXiv:2403.05525, 2024. 12
Pith/arXiv arXiv 2024
-
[38]
Chameleon: Plug-and-play compositional reasoning with large language models, 2023
Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, and Jianfeng Gao. Chameleon: Plug-and-play compositional reasoning with large language models, 2023
2023
-
[39]
Clibench: A multifaceted and multigranular evaluation of large language models in clinical decisions on diagnoses, procedures, lab tests orders and prescriptions, 2024
Mingyu Derek Ma, Chenchen Ye, et al. Clibench: A multifaceted and multigranular evaluation of large language models in clinical decisions on diagnoses, procedures, lab tests orders and prescriptions, 2024
2024
-
[40]
Introducing meta llama 3: The most capable openly available llm to date.Meta AI Blog (accessed 2024–04–20)
AI Meta. Introducing meta llama 3: The most capable openly available llm to date.Meta AI Blog (accessed 2024–04–20). There is no corresponding record for this reference, 2024
2024
-
[41]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[42]
Huang, Yadong Wu, T
Michael Moor, Shraey B. Huang, Yadong Wu, T. Kapur, et al. Med-flamingo: a multimodal medical few-shot learner. InProceedings of the 40th International Conference on Machine Learning (ICML), volume 225 ofProceedings of Machine Learning Research, 2023
2023
-
[43]
Babyagi, 2023
Yohei Nakajima. Babyagi, 2023
2023
-
[44]
Webgpt: Browser-assisted question-answering with human feedback, 2021
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. Webgpt: Browser-assisted question-answering with human feedback, 2021
2021
-
[45]
OpenAI, :, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, Che Chang, Kai Chen, Mark Chen, Enoch Cheung, Aidan Clark, Dan Cook, Marat Dukhan, Casey Dvorak, Kevin Fives, V...
2025
-
[46]
Webcpm: Interactive web search for chinese long-form question answering
Yujia Qin, Zihan Cai, Dian Jin, Lan Yan, Shihao Liang, Kunlun Zhu, Yankai Lin, Xu Han, Ning Ding, Huadong Wang, et al. Webcpm: Interactive web search for chinese long-form question answering. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8968–8988, 2023
2023
-
[47]
Agentclinic: A multimodal agent benchmark to evaluate ai in simulated clinical environments, 2024
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. Agentclinic: A multimodal agent benchmark to evaluate ai in simulated clinical environments, 2024
2024
-
[48]
Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
Pith/arXiv arXiv 2025
-
[49]
Deep learning in medical image analysis
Dinggang Shen, Guorong Wu, and Heung-Il Suk. Deep learning in medical image analysis. Annual review of biomedical engineering, 19(1):221–248, 2017. 13
2017
-
[50]
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36, 2024
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[51]
Yan Shu, Chi Liu, Robin Chen, Derek Li, and Bryan Dai. Fleming-vl: Towards universal medical visual reasoning with multimodal llms.arXiv preprint arXiv:2511.00916, 2025
arXiv 2025
-
[52]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2026
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2026
Pith/arXiv arXiv 2026
-
[53]
Yifan Song, Weimin Xiong, Dawei Zhu, Cheng Li, Ke Wang, Ye Tian, and Sujian Li. Restgpt: Connecting large language models with real-world applications via restful apis.arXiv preprint arXiv:2306.06624, 2023
arXiv 2023
-
[54]
Lesion guided explainable few weak-shot medical report generation
Jinghan Sun, Dong Wei, Liansheng Wang, and Yefeng Zheng. Lesion guided explainable few weak-shot medical report generation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 615–625. Springer, 2022
2022
-
[55]
Docagent: An agentic framework for multi-modal long-context document understanding
Lin Sun et al. Docagent: An agentic framework for multi-modal long-context document understanding. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025
2025
-
[56]
Vipergpt: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[57]
Enhance llm agents with versatile tool apis
AgentLego Developer Team. Enhance llm agents with versatile tool apis. https://github. com/InternLM/agentlego, 2023
2023
-
[58]
Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Pith/arXiv arXiv 2023
-
[59]
Lagent: InternLM a lightweight open-source framework that allows users to efficiently build large language model(llm)-based agents
Lagent Developer Team. Lagent: InternLM a lightweight open-source framework that allows users to efficiently build large language model(llm)-based agents. https://github.com/ InternLM/lagent, 2023
2023
-
[60]
C Wang, W Luo, Q Chen, H Mai, J Guo, S Dong, XM Xuan, Z Li, L Ma, and S Gao. Mllm-tool: A multimodal large language model for tool agent learning.arXiv preprint arXiv:2401.10727, 4, 2024
arXiv 2024
-
[61]
Gta: A benchmark for general tool agents
Jize Wang, Zerun Ma, Yining Li, Songyang Zhang, Cailian Chen, Kai Chen, and Xinyi Le. Gta: A benchmark for general tool agents. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 75749–75790. Curran Associates, Inc., 2024
2024
-
[62]
Medclip: Contrastive learning from unpaired medical images and text, 2022
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. Medclip: Contrastive learning from unpaired medical images and text, 2022
2022
-
[63]
Ziyue Wang, Junde Wu, Linghan Cai, Chang Han Low, Xihong Yang, Qiaxuan Li, and Yueming Jin. Medagent-pro: Towards evidence-based multi-modal medical diagnosis via reasoning agentic workflow.arXiv preprint arXiv:2503.18968, 2025
arXiv 2025
-
[64]
Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data, 2023
Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data, 2023
2023
-
[65]
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Visual chatgpt: Talking, drawing and editing with visual foundation models.arXiv preprint arXiv:2303.04671, 2023
Pith/arXiv arXiv 2023
-
[66]
Autogen: Enabling next-gen llm applications via multi-agent conversation framework, 2023
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. Autogen: Enabling next-gen llm applications via multi-agent conversation framework, 2023. 14
2023
-
[67]
Large multimodal agents: A survey.arXiv preprint arXiv:2402.15116, 2024
Junlin Xie, Zhihong Chen, Ruifei Zhang, Xiang Wan, and Guanbin Li. Large multimodal agents: A survey.arXiv preprint arXiv:2402.15116, 2024
arXiv 2024
-
[68]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.arXiv preprint arXiv:2404.07972, 2024
Pith/arXiv arXiv 2024
-
[69]
A comprehensive survey of ai agents in healthcare.TechRxiv, 2025
Gelei Xu, Xueyang Li, Yixiong Chen, Yuying Duan, Shuqing Wu, Alexander Yu, Ching-Hao Chiu, Juntong Ni, Ningzhi Tang, Toby Jia-Jun Li, et al. A comprehensive survey of ai agents in healthcare.TechRxiv, 2025
2025
-
[70]
Medagentgym: Training llm agents for code-based medical reasoning at scale
Ran Xu, Yuchen Zhuang, Yishan Zhong, Yue Yu, Xiangru Tang, Hang Wu, May Dongmei Wang, Peifeng Ruan, Donghan Yang, Tao Wang, et al. Medagentgym: Training llm agents for code-based medical reasoning at scale. InThe Second Workshop on GenAI for Health: Potential, Trust, and Policy Compliance, 2025
2025
-
[71]
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Cheng- hao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al. Lingshu: A generalist foun- dation model for unified multimodal medical understanding and reasoning.arXiv preprint arXiv:2506.07044, 2025
Pith/arXiv arXiv 2025
-
[72]
Zhiling Yan, Dingjie Song, Zhe Fang, Yisheng Ji, Xiang Li, Quanzheng Li, and Lichao Sun. Livemedbench: A contamination-free medical benchmark for llms with automated rubric evaluation.arXiv preprint arXiv:2602.10367, 2026
arXiv 2026
-
[73]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering, 2024
2024
-
[74]
Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action.arXiv preprint arXiv:2303.11381, 2023
Pith/arXiv arXiv 2023
-
[75]
Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
2022
-
[76]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023
2023
-
[77]
Zonghai Yao, Zihao Zhang, Chaolong Tang, Xingyu Bian, Youxia Zhao, Zhichao Yang, Junda Wang, Huixue Zhou, Won Seok Jang, Feiyun Ouyang, et al. Medqa-cs: Benchmarking large language models clinical skills using an ai-sce framework.arXiv preprint arXiv:2410.01553, 2024
arXiv 2024
-
[78]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for exp...
2024
-
[79]
Appagent: Multimodal agents as smartphone users, 2023
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. Appagent: Multimodal agents as smartphone users, 2023
2023
-
[80]
Pmc-vqa: Visual instruction tuning for medical visual question answering, 2024.URL https://arxiv
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. Pmc-vqa: Visual instruction tuning for medical visual question answering, 2024.URL https://arxiv. org/abs/2305.10415, 40, 2024
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.