Keep Policy Gradient in Charge: Sibling-Guided Credit Distillation for Long-Horizon Tool-Use Agents
Pith reviewed 2026-06-27 10:26 UTC · model grok-4.3
The pith
Sibling-Guided Credit Distillation refines token advantages in policy gradient updates for long-horizon tool-use agents by distilling credit from contrasts between successful and failed sibling rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
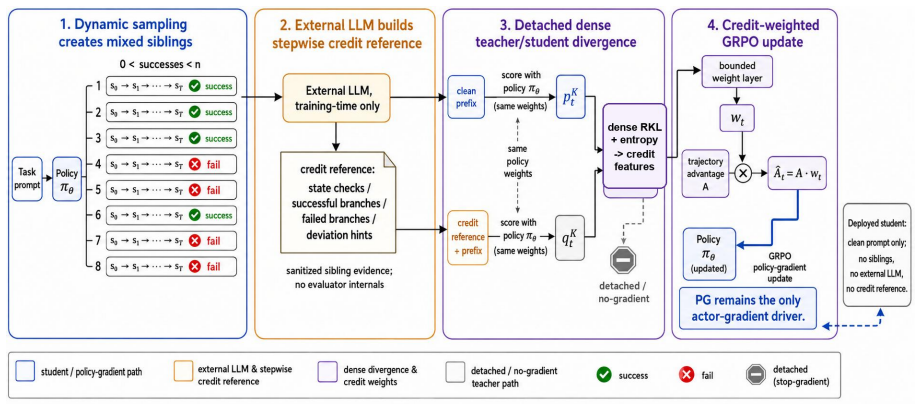
SGCD keeps policy gradient updates in charge by using dynamic sampling to generate mixed successful and failed sibling rollouts, letting an external LLM summarize their contrast into a training-only stepwise credit reference, driving credit reassignment via dense teacher-student divergence, and reshaping GRPO token advantages with bounded detached credit weights; the resulting student policy improves task-completion metrics without ever encountering external components at deployment.
What carries the argument
Sibling-Guided Credit Distillation (SGCD), which repurposes distillation solely to produce stepwise credit references from sibling rollout contrasts that then modulate GRPO advantages rather than serving as a competing actor loss.
If this is right
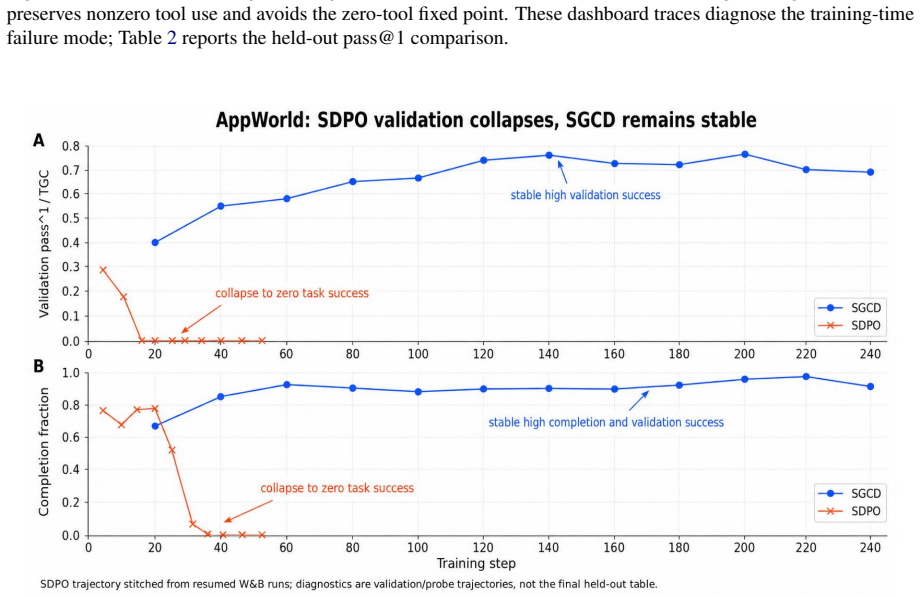
- AppWorld test_normal TGC rises from 42.9 to 45.6 and test_challenge TGC rises from 24.7 to 27.0.
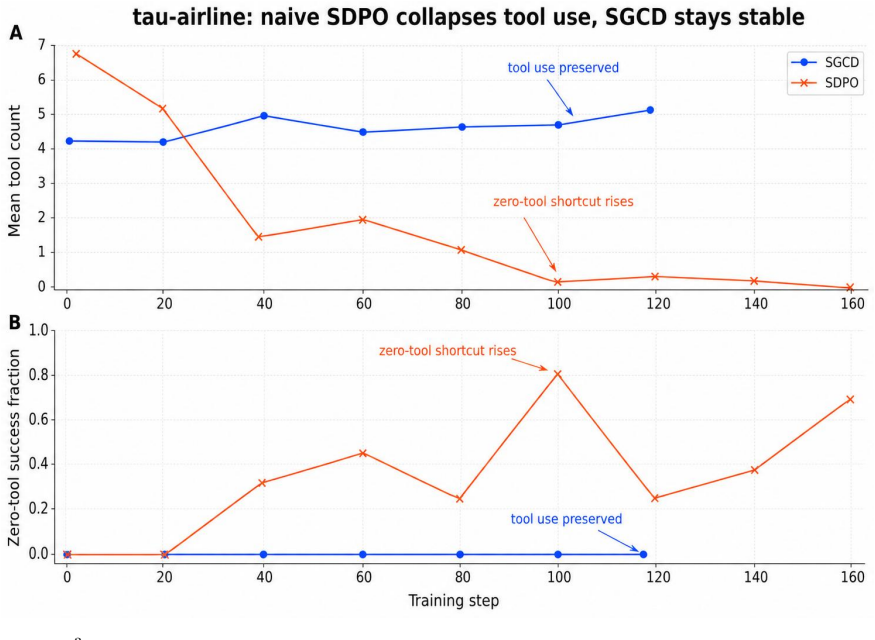
- τ³-airline pass@1 rises from 0.583 to 0.602.
- Direct token-level self-distillation is avoided, preventing the silent destruction of tool-use behavior.
- The deployed student policy operates without any external LLM, sibling evidence, or oracle.
- Credit assignment remains subordinate to the GRPO policy-gradient objective.
Where Pith is reading between the lines
- The same contrast-based credit signal could be tested on other long-horizon domains that supply only outcome verification.
- Separating credit distillation from the actor loss may lower the chance that the policy learns to exploit the verifier's blind spots.
- Scaling the method would require checking whether the training-time LLM dependency creates a bottleneck on very large task suites.
- Combining SGCD with existing dense-reward shaping techniques might compound the observed gains.
Load-bearing premise
An external LLM can produce unbiased and accurate stepwise credit references from contrasts between successful and failed sibling rollouts that improve the policy gradient update without introducing new errors or amplifying shortcuts.
What would settle it
Replace the LLM-generated credit references with random or zero values during training and measure whether the performance lift over GRPO disappears or reverses on the same AppWorld or τ³-airline splits.
Figures
read the original abstract
Long-horizon tool-use reinforcement learning can learn from outcome verification, but its trajectory-level advantage is broadcast across many reasoning, API, and answer tokens. Self-distillation promises a denser signal by reusing a policy's own rollouts or a privileged teacher. We show, however, that direct token-level self-distillation can silently destroy tool use: it rehearses teacher behavior without knowing which actions the verifier rewards, so useful skills and harmful shortcuts are amplified together. We introduce Sibling-Guided Credit Distillation (SGCD), which uses distillation for credit assignment rather than as a competing actor loss. Dynamic sampling produces mixed successful and failed sibling rollouts; an external LLM summarizes their contrast into a training-only stepwise credit reference; dense teacher/student divergence drives credit reassignment; and bounded detached credit weights reshape GRPO token advantages. The deployed student sees no external LLM, sibling evidence, or oracle. Across AppWorld and $\tau^3$-airline, SGCD improves over matched GRPO comparators: AppWorld TGC $42.9 \to 45.6$ on test_normal and $24.7 \to 27.0$ on test_challenge, and $\tau^3$-airline pass@1 $0.583 \to 0.602$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that direct token-level self-distillation in long-horizon tool-use RL can amplify both useful skills and harmful shortcuts. It introduces Sibling-Guided Credit Distillation (SGCD), which samples mixed successful/failed sibling rollouts, uses an external LLM to produce training-only stepwise credit references from their contrasts, and applies bounded detached credit weights to reshape GRPO token advantages while keeping the policy gradient in charge. The deployed student uses neither the LLM nor sibling evidence. It reports gains over matched GRPO baselines: AppWorld TGC 42.9→45.6 (test_normal) and 24.7→27.0 (test_challenge); τ³-airline pass@1 0.583→0.602.
Significance. If the central assumption holds, SGCD offers a targeted way to densify credit signals for tool-use agents without the destructive effects of competing distillation losses. The bounded detached weighting and sibling-contrast mechanism are concrete strengths that keep the method anchored to the original verifier signal.
major comments (2)
- [Method (SGCD credit reference generation)] The manuscript provides no quantitative validation (correlation with verifier outcome, inter-annotator agreement, or ablation replacing the LLM with random/oracle labels) that the external LLM's stepwise credit references align with the true reward rather than LLM priors or surface patterns. This is load-bearing for the claim that SGCD improves credit assignment rather than introducing teacher artifacts.
- [Experiments] No experimental details, baseline descriptions, statistical tests, ablation results, or variance estimates accompany the reported numerical improvements. The abstract alone supplies insufficient information to assess whether the +2.7/+2.3 TGC and +0.019 pass@1 gains are attributable to the proposed credit mechanism.
minor comments (2)
- Define TGC and pass@1 explicitly on first use and clarify how they relate to the underlying verifier.
- Clarify the exact form of the bounded detached credit weights and how they interact with the GRPO advantage estimator (e.g., any equation governing the reshaping).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger validation of the credit references and more transparent experimental reporting. We address each major comment below and will revise the manuscript to incorporate the requested analyses and details.
read point-by-point responses
-
Referee: [Method (SGCD credit reference generation)] The manuscript provides no quantitative validation (correlation with verifier outcome, inter-annotator agreement, or ablation replacing the LLM with random/oracle labels) that the external LLM's stepwise credit references align with the true reward rather than LLM priors or surface patterns. This is load-bearing for the claim that SGCD improves credit assignment rather than introducing teacher artifacts.
Authors: We agree this validation is important and currently absent from the manuscript. In revision we will add: (i) Pearson/Spearman correlation between LLM stepwise credits and final verifier outcomes on held-out trajectories, (ii) agreement metrics across two different LLMs, and (iii) an ablation that replaces LLM credits with random labels or oracle (verifier-derived) labels while keeping all other components fixed. These results will be reported in a new subsection of the experiments and will directly test whether the credit signal aligns with the verifier rather than LLM priors. revision: yes
-
Referee: [Experiments] No experimental details, baseline descriptions, statistical tests, ablation results, or variance estimates accompany the reported numerical improvements. The abstract alone supplies insufficient information to assess whether the +2.7/+2.3 TGC and +0.019 pass@1 gains are attributable to the proposed credit mechanism.
Authors: The full manuscript contains Section 4 with matched GRPO baselines, hyperparameter tables, and results reported as means ± std over 5 random seeds. However, we acknowledge that statistical significance tests, explicit component ablations, and a consolidated summary table are not sufficiently prominent. In revision we will add: a dedicated ablation table isolating the credit-weighting term, paired t-test p-values for all reported deltas, and an expanded main-text table that includes all experimental controls so that readers need not consult the appendix to verify the source of the gains. revision: yes
Circularity Check
No circularity: external LLM credit references are training-only and independent of test evaluation
full rationale
The paper's central claim is an empirical improvement from SGCD over GRPO baselines on held-out test sets (AppWorld TGC and τ³-airline pass@1). The method description states that an external LLM produces stepwise credit references from sibling contrasts solely during training; the deployed student policy receives none of this information. No equations, self-citations, or fitted parameters are shown that would make the reported gains equivalent to the inputs by construction. The external LLM is treated as an independent source of training signal, and the evaluation uses standard outcome verification on test data, rendering the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2015 , eprint =
Distilling the Knowledge in a Neural Network , author =. 2015 , eprint =
2015
-
[2]
2024 , eprint =
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author =. 2024 , eprint =
2024
-
[3]
Journal of Machine Learning Research , volume =
Learning Using Privileged Information: Similarity Control and Knowledge Transfer , author =. Journal of Machine Learning Research , volume =
-
[4]
Divergence Measures Based on the
Lin, Jianhua , journal =. Divergence Measures Based on the. 1991 , doi =
1991
-
[5]
2026 , eprint =
Reinforcement Learning via Self-Distillation , author =. 2026 , eprint =
2026
-
[6]
2026 , eprint =
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author =. 2026 , eprint =
2026
-
[7]
2026 , eprint =
Skill-Conditioned Self-Distillation for Multi-Turn Language-Model Agents , author =. 2026 , eprint =
2026
-
[8]
2026 , eprint =
Self-Distilled Agentic Reinforcement Learning , author =. 2026 , eprint =
2026
-
[9]
2026 , eprint =
Reinforcement Learning with Self-Distillation for Language-Model Reasoning , author =. 2026 , eprint =
2026
-
[10]
Machine Learning , volume =
Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning , author =. Machine Learning , volume =. 1992 , doi =
1992
-
[11]
Advances in Neural Information Processing Systems , volume =
Policy Gradient Methods for Reinforcement Learning with Function Approximation , author =. Advances in Neural Information Processing Systems , volume =. 1999 , url =
1999
-
[12]
2017 , eprint =
Proximal Policy Optimization Algorithms , author =. 2017 , eprint =
2017
-
[13]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , year =. 2402.03300 , archivePrefix =
-
[14]
Liu, Zichen and Chen, Changyu and Li, Wenjun and Pang, Tianyu and Du, Chao and Lin, Min , year =. Understanding. 2503.20783 , archivePrefix =
-
[15]
Yu, Qiying and Zhang, Zheng and Zhu, Ruofei and Yuan, Yufeng and Zuo, Xiaochen and Yue, Yu and Fan, Tiantian and Liu, Gaohong and Liu, Lingjun and Liu, Xin and others , year =. 2503.14476 , archivePrefix =
-
[16]
2026 , eprint =
Rethinking the Trust Region in Large Language Model Reinforcement Learning , author =. 2026 , eprint =
2026
- [17]
-
[18]
Chu, Xiangxiang and Huang, Hailang and Zhang, Xiao and Wei, Fei and Wang, Yongchao , year =. 2504.02546 , archivePrefix =
-
[19]
2025 , eprint =
Group Sequence Policy Optimization , author =. 2025 , eprint =
2025
-
[20]
2025 , eprint =
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models , author =. 2025 , eprint =
2025
-
[21]
Trivedi, Harsh and Khot, Tushar and Hartmann, Mareike and Manku, Ruskin and Dong, Vinty and Li, Edward and Gupta, Shashank and Sabharwal, Ashish and Balasubramanian, Niranjan , year =. 2407.18901 , archivePrefix =
-
[22]
2026 , eprint =
Co-Evolving Agents: Self-Improving Tool-Use through Iterative Reinforcement Learning , author =. 2026 , eprint =
2026
-
[23]
Yao, Shunyu and Shinn, Noah and Razavi, Pedram and Narasimhan, Karthik , year =. 2406.12045 , archivePrefix =
-
[24]
Barres, Victor and Dong, Honghua and Ray, Soham and Si, Xujie and Narasimhan, Karthik , year =. 2506.07982 , archivePrefix =
-
[25]
2025 , eprint =
Adaptive Rollout and Response Replacement for Reinforcement Learning with Verifiable Rewards , author =. 2025 , eprint =
2025
-
[26]
2026 , eprint =
Self-Distillation under Privileged Context with Consensus Gating , author =. 2026 , eprint =
2026
-
[27]
2026 , eprint =
The Many Faces of On-Policy Distillation , author =. 2026 , eprint =
2026
-
[28]
2026 , eprint =
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes , author =. 2026 , eprint =
2026
-
[29]
2026 , eprint =
On the Mechanism and Phenomenology of On-Policy Distillation , author =. 2026 , eprint =
2026
-
[30]
2026 , eprint =
A Survey of On-Policy Distillation for Large Language Models , author =. 2026 , eprint =
2026
-
[31]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in
Yue, Yang and Chen, Zhiqi and Lu, Rui and Zhao, Andrew and Wang, Zhaokai and Yue, Yang and Song, Shiji and Huang, Gao , year =. Does Reinforcement Learning Really Incentivize Reasoning Capacity in. 2504.13837 , archivePrefix =
-
[32]
2025 , eprint =
A Practitioner's Guide to Multi-Turn Agentic Reinforcement Learning , author =. 2025 , eprint =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.