Localizing Anchoring Pathways in Language Models
Pith reviewed 2026-06-27 07:03 UTC · model grok-4.3
The pith
Edge-level attribution recovers the anchor-sensitive signal in language models more faithfully than node-level methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
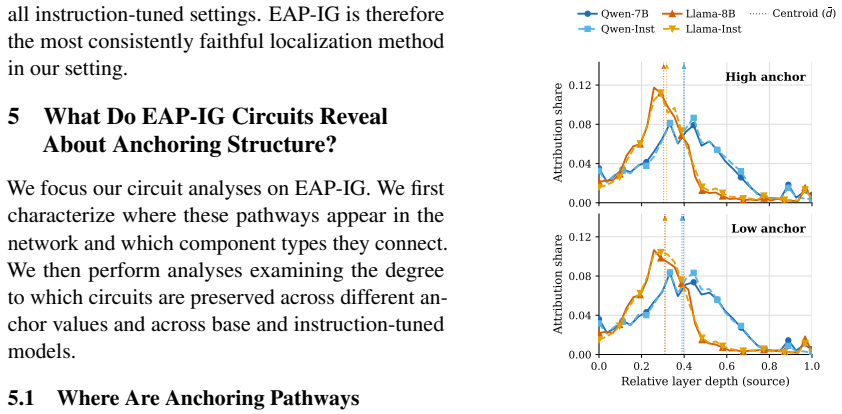
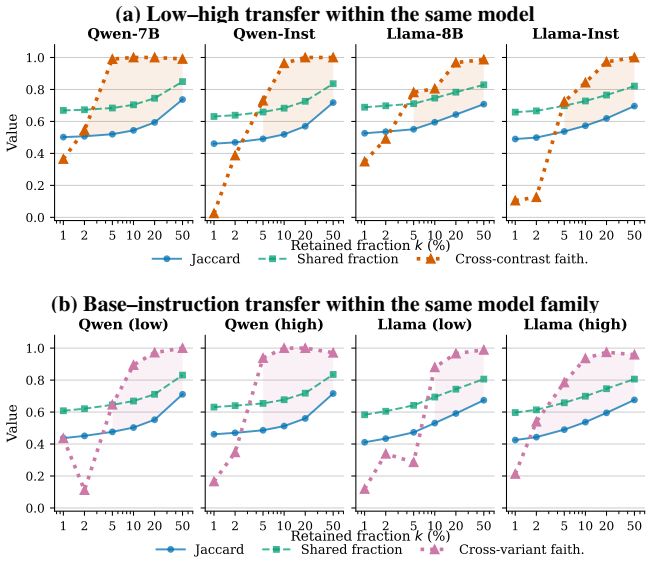
Attribution-based circuit localization recovers the anchor-sensitive signal more faithfully with edge-level methods than with node-level methods. Low- and high-anchor circuits transfer strongly within a model, indicating shared pathway structure across anchor direction, while transfer across base and instruction-tuned variants is sparse, showing that post-training changes which pathways matter most.
What carries the argument
The logit-difference metric comparing correct and anchor answer options, used to validate tracking of behavioral anchoring and combined with attribution-based circuit localization to identify pathways.
If this is right
- Low- and high-anchor circuits share pathway structure across anchor direction within a model.
- Post-training alters which pathways carry the anchor-sensitive signal compared with base models.
- Edge-level attribution methods give a more faithful recovery of the signal than node-level methods.
- Anchoring-related decision signals localize to identifiable circuits inside the models.
Where Pith is reading between the lines
- Causal interventions on the localized circuits would be expected to reduce observed anchoring effects.
- The same localization approach could be tested on other documented biases in language model reasoning.
- Sparse transfer across variants implies that circuit findings require re-localization after instruction tuning.
Load-bearing premise
The logit-difference metric between correct and anchor options faithfully isolates anchoring behavior without being confounded by the shared answer-option structure or other prompt features.
What would settle it
Ablating the localized circuits produces no measurable change in the model's preference for the anchor option over the correct option in the multiple-choice task.
Figures

read the original abstract
Irrelevant numbers in a prompt can shift language model judgments, producing anchoring effects in numerical reasoning. We study where this anchor-sensitive signal is carried inside language models using a controlled multiple-choice setup with shared answer options. We define a logit-difference metric comparing the correct answer option with the answer option corresponding to the anchor, and validate that it tracks behavioral anchoring. Using attribution-based circuit localization on 7B--8B Qwen and Llama base and instruction-tuned models, we find that edge-level methods recover this signal more faithfully than node-level methods. Low- and high-anchor circuits transfer strongly within a model, suggesting shared pathway structure across anchor direction. However, sparse transfer across base and instruction-tuned variants is less reliable, indicating that post-training changes which pathways matter most. Overall, our results provide a mechanistic account of how anchoring-related decision signals are carried inside language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines anchoring effects in language models' numerical reasoning using a controlled multiple-choice setup with shared answer options. It defines a logit-difference metric (correct option minus anchor option), states that this metric tracks behavioral anchoring, and applies attribution-based circuit localization on 7B-8B Qwen and Llama base and instruction-tuned models. Main results claim that edge-level attribution recovers the anchor-sensitive signal more faithfully than node-level methods, that low- and high-anchor circuits transfer strongly within a model, and that transfer is sparse across base and instruction-tuned variants.
Significance. If the logit-difference metric is shown to isolate anchoring without confounds from shared option structure, the results would provide a mechanistic account of how anchoring-related decision signals are carried in LMs, with useful comparisons of edge vs. node attribution and effects of post-training. The work applies standard attribution methods to a new behavioral metric and reports within- vs. cross-variant transfer patterns.
major comments (1)
- [Abstract and metric definition paragraph] Abstract and paragraph on metric definition: The claim that the logit-difference metric 'tracks behavioral anchoring' is asserted without reported quantitative validation numbers, error bars, ablation details, or explicit controls separating anchor sensitivity from shared answer-option structure (e.g., position biases or general option preferences). This is load-bearing for the central claims on edge-level fidelity and circuit transfer.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger validation of the logit-difference metric. We agree this is central to the claims and will expand the manuscript with the requested quantitative details, ablations, and controls.
read point-by-point responses
-
Referee: [Abstract and metric definition paragraph] Abstract and paragraph on metric definition: The claim that the logit-difference metric 'tracks behavioral anchoring' is asserted without reported quantitative validation numbers, error bars, ablation details, or explicit controls separating anchor sensitivity from shared answer-option structure (e.g., position biases or general option preferences). This is load-bearing for the central claims on edge-level fidelity and circuit transfer.
Authors: We accept the critique that the abstract and metric definition section present the validation claim without sufficient supporting numbers or controls. The full paper reports behavioral correlations between the logit-difference and anchoring effects, but these lack the explicit ablations, error bars, and option-structure controls requested. In revision we will add a dedicated validation subsection with: (1) quantitative correlation coefficients and error bars across prompt variants, (2) ablations that shuffle or remove the anchor while preserving option structure, and (3) controls for position bias and general option preference by comparing against non-anchor numerical prompts. These additions will directly support the downstream claims on edge-level attribution and circuit transfer. revision: yes
Circularity Check
No significant circularity; claims rest on independent metric and standard methods
full rationale
The paper defines a logit-difference metric on shared answer options and validates it tracks behavioral anchoring before applying off-the-shelf attribution techniques for circuit localization. No equations, fitted parameters, or predictions reduce by construction to the same inputs; no load-bearing self-citations or uniqueness theorems from prior author work are invoked. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge. Preprint, arXiv:1803.05457. Atticus Geiger, Jacqueline Harding, and Thomas Icard
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
How Causal Abstraction Under- pins Computational Explanation.arXiv preprint. ArXiv:2508.11214 [cs]. Nicholas Goldowsky-Dill, Chris MacLeod, Lucas Sato, and Aryaman Arora
-
[3]
Localizing Model Behavior with Path Patching
Localizing Model Behavior with Path Patching.arXiv preprint. ArXiv:2304.05969 [cs]. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mi- tra, Archie Sravankumar, Artem Kor...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
The llama 3 herd of models.Preprint, arXiv:2407.21783. Michael Hanna, Sandro Pezzelle, and Yonatan Belinkov
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
János Kramár, Tom Lieberum, Rohin Shah, and Neel Nanda
Un- derstanding the anchoring effect of llm with synthetic data: Existence, mechanism, and potential mitiga- tions.Preprint, arXiv:2505.15392. János Kramár, Tom Lieberum, Rohin Shah, and Neel Nanda
-
[6]
arXiv preprint arXiv:2403.00745 , year=
Atp*: An efficient and scalable method for localizing llm behaviour to components.Preprint, arXiv:2403.00745. Tom Lieberum, Matthew Rahtz, János Kramár, Neel Nanda, Geoffrey Irving, Rohin Shah, and Vladimir Mikulik
-
[7]
Technical Report arXiv:2307.09458, arXiv
Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla. Technical Report arXiv:2307.09458, arXiv. ArXiv:2307.09458 [cs]. Jiaxu Lou and Yifan Sun
-
[8]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov
Anchoring bias in large language models: An experimental study.Preprint, arXiv:2412.06593. Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov
-
[9]
InThe Twelfth Inter- national Conference on Learning Representations
Circuit Component Reuse Across Tasks in Trans- former Language Models. InThe Twelfth Inter- national Conference on Learning Representations. arXiv. ArXiv:2310.08744 [cs]. 9 Aaron Mueller, Jannik Brinkmann, Millicent Li, Samuel Marks, Koyena Pal, Nikhil Prakash, Can Rager, Aruna Sankaranarayanan, Arnab Sen Sharma, Jiud- ing Sun, Eric Todd, David Bau, and Y...
-
[10]
InFindings of ACL: NAACL 2024, pages 2006–2017
Large language models sensitivity to the order of options in multiple-choice questions. InFindings of ACL: NAACL 2024, pages 2006–2017. Lukas Röseler, Lucia Weber, Ena P. B. Stijovi´c, Katha- rina A. K. Jaekel, J. F. (Janne)ke M. T. (Janneke) G. (Gijsbers) Gijsbers, and Nir Milstein
2024
-
[11]
InProceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing, pages 7035–7052
A mechanistic interpretation of arith- metic reasoning in language models using causal mediation analysis. InProceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing, pages 7035–7052. Aaquib Syed, Can Rager, and Arthur Conmy
2023
-
[12]
Anchors in the machine: Behavioral and attributional evidence of anchoring bias in llms.Preprint, arXiv:2511.05766. Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber
-
[13]
InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online
Trans- formers: State-of-the-art natural language processing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics. Qwen An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Gua...
2020
-
[14]
Qwen2.5 technical report.ArXiv, abs/2412.15115. Fred Zhang and Neel Nanda
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Towards Best Practices of Activation Patching in Language Models: Metrics and Methods
Towards Best Practices of Activation Patching in Language Mod- els: Metrics and Methods. InThe Twelfth Inter- national Conference on Learning Representations. arXiv. ArXiv:2309.16042 [cs]. Appendix A MCQA Menu Size Validation Our main experiments use nine answer options per item. To justify this choice, we evaluated whether anchoring is preserved as the n...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.