GenHOI: Contact-Aware Humanoid-Object Interaction by Imitating Generated Videos without Task-Specific Training
Pith reviewed 2026-06-27 06:29 UTC · model grok-4.3
The pith
Humanoid robots can imitate a single generated video to perform diverse object-interaction tasks without any task-specific training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GenHOI shows that contact-relevant information extracted from one AI-generated video can be encoded as object-centric geometric constraints. These priors guide the refinement of a reference motion recovered from the video, resolving scale ambiguity and adapting to new poses, so that a closed-loop controller can execute stable interactions.
What carries the argument
The pipeline that converts a generated video into contact events and hand-object regions, then into geometric constraints for trajectory optimization.
If this is right
- Robots can handle new tasks like box grasping or table lifting by generating one video per task instead of retraining.
- The method adapts a single reference trajectory to different robot-object relative poses.
- Contact estimation from video provides priors that improve balance and interaction stability during execution.
- No physical demonstration data is required for each new interaction scenario.
Where Pith is reading between the lines
- Extending this to longer or more complex sequences might require chaining multiple generated videos.
- Improving video generation quality could directly boost the reliability of extracted contacts without changing the robot side.
- Testing in more cluttered environments would reveal how well the contact priors generalize beyond the simulated reconstruction.
Load-bearing premise
The generated video must contain accurate depictions of contact events and regions that can be reliably turned into physical constraints without causing instability.
What would settle it
Observing frequent failures in balance or object drops during real-world execution when the video-derived contacts mismatch actual physics would falsify the approach.
Figures





read the original abstract
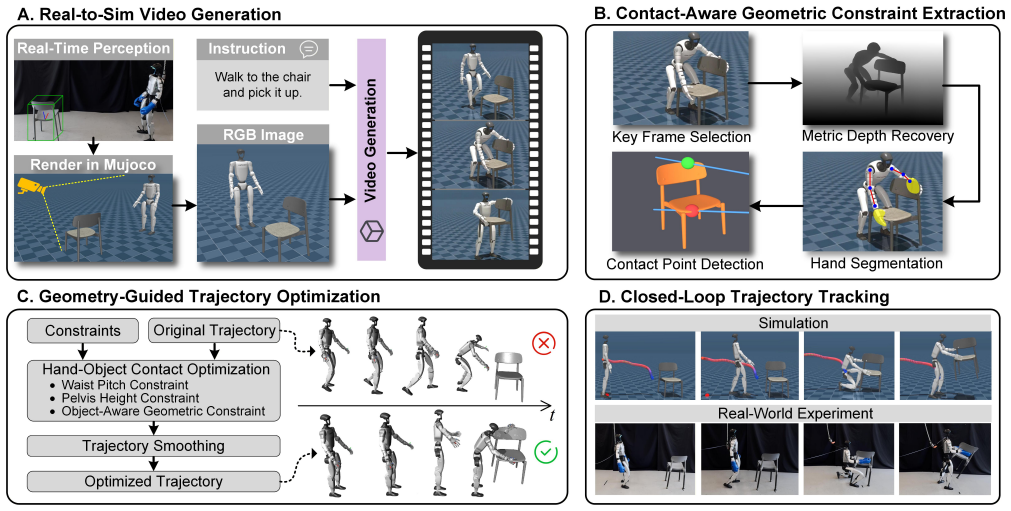
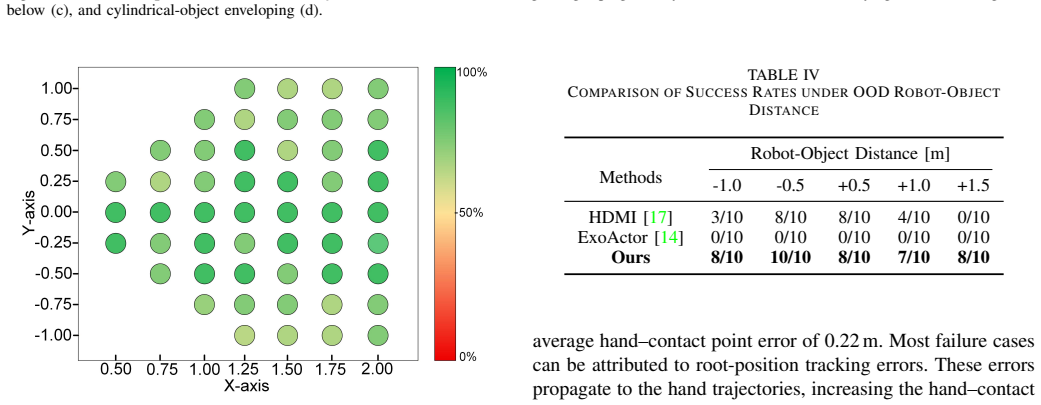
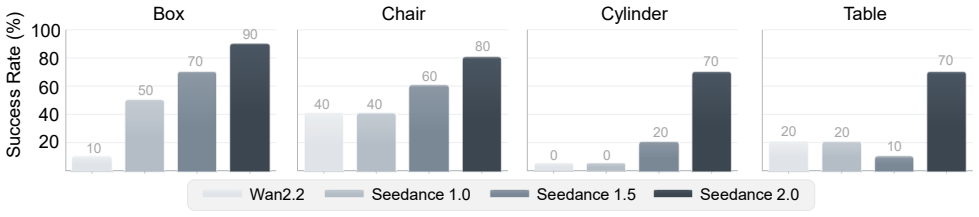
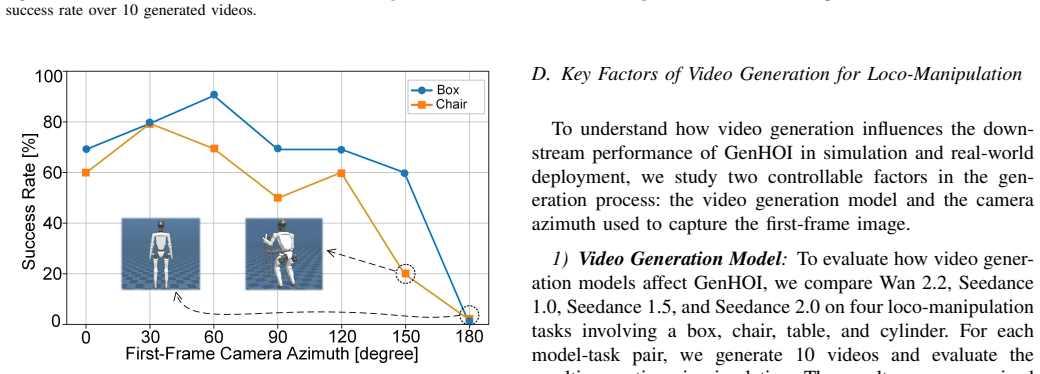
Humanoid-Object Interaction (HOI) is a fundamental capability for humanoid robots, yet it remains challenging due to the tight coupling between dynamic balance and stable interaction with diverse objects. Existing methods often require time-consuming task-specific policy training or rely on rigid trajectory replay, which limits their ability to accommodate novel interaction scenarios. In this work, we present \textit{GenHOI}, a simple yet effective framework that enables humanoid robots to perform diverse object-interaction tasks in a zero-shot manner by directly imitating a single generated video, without task-specific training or physical demonstration data. GenHOI first reconstructs the robot-object scene in simulation and renders a first-frame image, which, together with the language command, conditions the synthesis of a task-oriented interaction video. The generated video is then analyzed to identify interaction-relevant contact events and estimate hand-object contact regions, which are encoded as object-centric geometric constraints that convert visual interaction cues into physically grounded optimization priors. Guided by these priors, the reference motion recovered from the video is refined and smoothed to resolve the scale ambiguity inherent in 2D video generation, while adapting a single reference trajectory to unseen robot-object relative poses. The optimized trajectory is finally executed by a closed-loop tracking controller. We validate the proposed framework in extensive simulation and real-world experiments across diverse object-interaction tasks, including box grasping, asymmetric bimanual chair carrying, table lifting from below, and cylindrical-object enveloping.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents GenHOI, a framework enabling humanoid robots to perform diverse object-interaction tasks in a zero-shot manner by imitating a single generated video without task-specific training or physical demonstrations. The pipeline reconstructs the robot-object scene in simulation, renders a first-frame image, and conditions video synthesis on a language command; contact events and hand-object regions are then extracted from the video and encoded as object-centric geometric constraints to serve as optimization priors. These priors guide refinement of the recovered reference motion to resolve scale ambiguity and adapt to unseen poses, after which the trajectory is executed by a closed-loop tracking controller. Validation is claimed across simulation and real-world experiments on tasks including box grasping, asymmetric bimanual chair carrying, table lifting from below, and cylindrical-object enveloping.
Significance. If the results hold, the work would be significant for humanoid robotics by demonstrating a training-free approach to HOI that leverages video generation models to produce contact-aware priors, potentially enabling rapid adaptation to novel objects and interactions while addressing the coupling of balance and manipulation.
major comments (2)
- [Abstract] Abstract: The claim of validation in 'extensive simulation and real-world experiments' is load-bearing for the central zero-shot claim, yet no quantitative metrics, ablation studies, failure cases, or error analysis are reported. This omission prevents assessment of whether contact estimation from generated videos produces priors accurate enough to maintain dynamic balance.
- [Method] Method description (contact extraction to geometric constraints): The approach assumes generated-video contact timing and locations can be converted into 3D optimization priors without introducing errors that violate grasp stability or balance; no quantitative bound on contact-error tolerance or robustness analysis to video artifacts is provided. This is critical for tasks such as asymmetric bimanual chair carrying, where small misalignments can produce uncompensated torque errors.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, acknowledging where the manuscript would benefit from additional quantitative analysis and proposing concrete revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of validation in 'extensive simulation and real-world experiments' is load-bearing for the central zero-shot claim, yet no quantitative metrics, ablation studies, failure cases, or error analysis are reported. This omission prevents assessment of whether contact estimation from generated videos produces priors accurate enough to maintain dynamic balance.
Authors: We agree that the absence of quantitative metrics limits the strength of the zero-shot claim. The current experiments emphasize qualitative demonstrations of diverse tasks. In the revised manuscript we will add quantitative results including task success rates, contact estimation accuracy, and balance metrics (e.g., CoM deviation) across simulation and real-world trials, together with ablations on the contact priors and a dedicated failure-case analysis. revision: yes
-
Referee: [Method] Method description (contact extraction to geometric constraints): The approach assumes generated-video contact timing and locations can be converted into 3D optimization priors without introducing errors that violate grasp stability or balance; no quantitative bound on contact-error tolerance or robustness analysis to video artifacts is provided. This is critical for tasks such as asymmetric bimanual chair carrying, where small misalignments can produce uncompensated torque errors.
Authors: The pipeline mitigates video artifacts through subsequent optimization and closed-loop control, yet we acknowledge the lack of an explicit error-tolerance bound. We will incorporate a robustness analysis in the revision, quantifying sensitivity of grasp stability and balance to controlled perturbations in contact timing and location, with particular attention to the asymmetric bimanual chair-carrying scenario. revision: yes
Circularity Check
No circularity: pipeline uses external video generators and simulators without self-referential reduction
full rationale
The paper presents a framework that reconstructs scenes, generates videos via external models, extracts contacts, and optimizes trajectories using simulators and controllers. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All steps rely on independent external components rather than deriving results from the paper's own inputs by construction. This is the common case of a self-contained engineering pipeline.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Humanoid locomotion and manipulation: Current progress and challenges in control, planning, and learning,
Z. Gu, J. Li, W. Shen, W. Yu, Z. Xie, S. McCrory, X. Cheng, A. Shamsah, R. Griffin, C. K. Liuet al., “Humanoid locomotion and manipulation: Current progress and challenges in control, planning, and learning,”IEEE/ASME Transactions on Mechatronics, vol. 31, no. 2, pp. 2300–2330, 2026
2026
-
[2]
Viral: Visual sim-to-real at scale for humanoid loco-manipulation,
T. He, Z. Wang, H. Xue, Q. Ben, Z. Luo, W. Xiao, Y . Yuan, X. Da, F. Casta ˜neda, S. Sastryet al., “Viral: Visual sim-to-real at scale for humanoid loco-manipulation,”arXiv preprint arXiv:2511.15200, 2025
arXiv 2025
-
[3]
L. Yang, X. Huang, Z. Wu, A. Kanazawa, P. Abbeel, C. Sferrazza, C. K. Liu, R. Duan, and G. Shi, “Omniretarget: Interaction-preserving data generation for humanoid whole-body loco-manipulation and scene interaction,”arXiv preprint arXiv:2509.26633, 2025
Pith/arXiv arXiv 2025
-
[4]
Embracing bulky objects with humanoid robots: Whole-body manip- ulation with reinforcement learning,
C. Zheng, K. Chen, Z. Bi, Y . Li, L. Pan, J. Zhou, H. Li, and J. Ma, “Embracing bulky objects with humanoid robots: Whole-body manip- ulation with reinforcement learning,”arXiv preprint arXiv:2509.13534, 2025
arXiv 2025
-
[5]
Amp: Adversarial motion priors for stylized physics-based character control,
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa, “Amp: Adversarial motion priors for stylized physics-based character control,” ACM Transactions on Graphics (ToG), vol. 40, no. 4, pp. 1–20, 2021
2021
-
[6]
Pro- hoi: Perceptive root-guided humanoid-object interaction,
Y . Lin, J. Shi, D. Wang, J. Kong, Y . Liu, C. Bai, and X. Li, “Pro- hoi: Perceptive root-guided humanoid-object interaction,”arXiv preprint arXiv:2603.01126, 2026
arXiv 2026
-
[7]
Video generation models as world simulators,
T. B. OpenAI, “Video generation models as world simulators,” https://openai. com/sora/, 2024
2024
-
[8]
Seedance 2.0: Advancing video generation for world complexity,
T. Seedance, D. Chen, L. Chen, X. Chen, Y . Chen, Z. Chen, Z. Chen, F. Cheng, T. Cheng, Y . Chenget al., “Seedance 2.0: Advancing video generation for world complexity,”arXiv preprint arXiv:2604.14148, 2026
Pith/arXiv arXiv 2026
-
[9]
Egoscale: Scaling dexterous manipulation with diverse egocentric human data,
R. Zheng, D. Niu, Y . Xie, J. Wang, M. Xu, Y . Jiang, F. Casta˜neda, F. Hu, Y . L. Tan, L. Fuet al., “Egoscale: Scaling dexterous manipulation with diverse egocentric human data,”arXiv preprint arXiv:2602.16710, 2026
arXiv 2026
-
[10]
Grail: Generating humanoid loco-manipulation from 3d assets and video priors,
T. Xie, H. Zhang, J. Park, Z. Wang, B. Wen, J. Li, X. Li, Q. Ben, H. Weng, Y . Yeet al., “Grail: Generating humanoid loco-manipulation from 3d assets and video priors,”arXiv preprint arXiv:2606.05160, 2026
Pith/arXiv arXiv 2026
-
[11]
Video generators are robot policies,
J. Liang, P. Tokmakov, R. Liu, S. Sudhakar, P. Shah, R. Ambrus, and C. V ondrick, “Video generators are robot policies,”arXiv preprint arXiv:2508.00795, 2025
Pith/arXiv arXiv 2025
-
[12]
Dream2flow: Bridging video generation and open-world manipulation with 3d object flow,
K. Dharmarajan, W. Huang, J. Wu, L. Fei-Fei, and R. Zhang, “Dream2flow: Bridging video generation and open-world manipulation with 3d object flow,”arXiv preprint arXiv:2512.24766, 2025
arXiv 2025
-
[13]
Robotic manipulation by imitating generated videos without physical demonstra- tions,
S. Patel, S. Mohan, H. Mai, U. Jain, S. Lazebnik, and Y . Li, “Robotic manipulation by imitating generated videos without physical demonstra- tions,”arXiv preprint arXiv:2507.00990, 2025
Pith/arXiv arXiv 2025
-
[14]
Exoac- tor: Exocentric video generation as generalizable interactive humanoid control,
Y . Zhou, J. Ma, Y . Peng, Z. Sun, Y . Bai, and B. F. Karlsson, “Exoac- tor: Exocentric video generation as generalizable interactive humanoid control,”arXiv preprint arXiv:2604.27711, 2026
Pith/arXiv arXiv 2026
-
[15]
Morphology-consistent humanoid interaction through robot-centric video synthesis,
W. Xu, J. Li, Y . Gu, B. Yang, H. Chen, S. Lin, M. Zhou, J. Tan, Q. Wu, X. Jianget al., “Morphology-consistent humanoid interaction through robot-centric video synthesis,”arXiv preprint arXiv:2603.19709, 2026
arXiv 2026
-
[16]
Sonic: Supersizing motion tracking for natural humanoid whole-body control,
Z. Luo, Y . Yuan, T. Wang, C. Li, S. Chen, F. Castaneda, Z.-A. Cao, J. Li, D. Minor, Q. Benet al., “Sonic: Supersizing motion tracking for natural humanoid whole-body control,”arXiv preprint arXiv:2511.07820, 2025
Pith/arXiv arXiv 2025
-
[17]
Hdmi: Learning interactive humanoid whole-body control from human videos,
H. Weng, Y . Li, N. Sobanbabu, Z. Wang, Z. Luo, T. He, D. Ramanan, and G. Shi, “Hdmi: Learning interactive humanoid whole-body control from human videos,”arXiv preprint arXiv:2509.16757, 2025
arXiv 2025
-
[18]
Falcon: Learning force-adaptive humanoid loco-manipulation,
Y . Zhang, Y . Yuan, P. Gurunath, I. Gupta, S. Omidshafiei, A.-a. Agha- mohammadi, M. Vazquez-Chanlatte, L. Pedersen, T. He, and G. Shi, “Falcon: Learning force-adaptive humanoid loco-manipulation,”arXiv preprint arXiv:2505.06776, 2025
arXiv 2025
-
[19]
Physhsi: Towards a real-world generalizable and natural humanoid-scene interaction sys- tem,
H. Wang, W. Zhang, R. Yu, T. Huang, J. Ren, F. Jia, Z. Wang, X. Niu, X. Chen, J. Chen, Q. Chen, J. Wang, and J. Pang, “Physhsi: Towards a real-world generalizable and natural humanoid-scene interaction sys- tem,”arXiv preprint arXiv:2510.11072, 2025
arXiv 2025
-
[20]
Opening the sim-to-real door for humanoid pixel-to-action policy transfer,
H. Xue, T. He, Z. Wang, Q. Ben, W. Xiao, Z. Luo, X. Da, F. Casta ˜neda, G. Shi, S. Sastryet al., “Opening the sim-to-real door for humanoid pixel-to-action policy transfer,”arXiv preprint arXiv:2512.01061, 2025
arXiv 2025
-
[21]
Humanx: Toward agile and generalizable humanoid interaction skills from human videos,
Y . Wang, Q. Zhao, Y . F. Lau, R. Yu, H. W. Tsui, Q. Chen, J. Wang, J. Pang, and P. Tan, “Humanx: Toward agile and generalizable humanoid interaction skills from human videos,”arXiv preprint arXiv:2602.02473, 2026
arXiv 2026
-
[22]
Egohumanoid: Unlocking in-the-wild loco-manipulation with robot-free egocentric demonstration,
M. Shi, S. Peng, J. Chen, H. Jiang, Y . Li, D. Huang, P. Luo, H. Li, and L. Chen, “Egohumanoid: Unlocking in-the-wild loco-manipulation with robot-free egocentric demonstration,”arXiv preprint arXiv:2602.10106, 2026
Pith/arXiv arXiv 2026
-
[23]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[24]
Open x- embodiment: Robotic learning datasets and rt-x models,
A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekaret al., “Open x- embodiment: Robotic learning datasets and rt-x models,”arXiv preprint arXiv:2310.08864, 2023
Pith/arXiv arXiv 2023
-
[25]
Ψ 0: An open foundation model towards universal humanoid loco-manipulation,
S. Wei, H. Jing, B. Li, Z. Zhao, J. Mao, Z. Ni, S. He, J. Liu, X. Liu, K. Kanget al., “Ψ 0: An open foundation model towards universal humanoid loco-manipulation,”arXiv preprint arXiv:2603.12263, 2026
arXiv 2026
-
[26]
Robodreamer: Learning compositional world models for robot imagination,
S. Zhou, Y . Du, J. Chen, Y . Li, D.-Y . Yeung, and C. Gan, “Robodreamer: Learning compositional world models for robot imagination,”arXiv preprint arXiv:2404.12377, 2024
Pith/arXiv arXiv 2024
-
[27]
Deximit: Learning bimanual dexterous manipulation from monocular human videos,
J. Mu, S. Yang, Y . Bao, H. Bae, T. Wei, L. Xu, B. Li, H. Xu, and J. Pang, “Deximit: Learning bimanual dexterous manipulation from monocular human videos,”arXiv preprint arXiv:2602.10105, 2026
arXiv 2026
-
[28]
Dreamgen: Unlocking generaliza- tion in robot learning through video world models,
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Linet al., “Dreamgen: Unlocking generaliza- tion in robot learning through video world models,”arXiv preprint arXiv:2505.12705, 2025
Pith/arXiv arXiv 2025
-
[29]
Dit4dit: Jointly modeling video dynamics and actions for generalizable robot control,
T. Ma, J. Zheng, Z. Wang, C. Jiang, A. Cui, J. Liang, and S. Yang, “Dit4dit: Jointly modeling video dynamics and actions for generalizable robot control,”arXiv preprint arXiv:2603.10448, 2026
arXiv 2026
-
[30]
World action models are zero-shot policies,
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xianget al., “World action models are zero-shot policies,” arXiv preprint arXiv:2602.15922, 2026
Pith/arXiv arXiv 2026
-
[31]
Foundationpose: Unified 6d pose estimation and tracking of novel objects,
B. Wen, W. Yang, J. Kautz, and S. Birchfield, “Foundationpose: Unified 6d pose estimation and tracking of novel objects,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 17 868–17 879
2024
-
[32]
World-grounded human motion recovery via gravity-view coordinates,
Z. Shen, H. Pi, Y . Xia, Z. Cen, S. Peng, Z. Hu, H. Bao, R. Hu, and X. Zhou, “World-grounded human motion recovery via gravity-view coordinates,” inSIGGRAPH Asia 2024 Conference Papers, 2024, pp. 1–11
2024
-
[33]
Retargeting matters: General motion retargeting for humanoid motion tracking,
J. P. Araujo, Y . Ze, P. Xu, J. Wu, and C. K. Liu, “Retargeting matters: General motion retargeting for humanoid motion tracking,” arXiv preprint arXiv:2510.02252, 2025
arXiv 2025
-
[34]
Seed2. 0 model card: Towards intelligence fron- tier for real-world complexity,
B. Seed, “Seed2. 0 model card: Towards intelligence fron- tier for real-world complexity,”URL https://lf3-static. bytedns- doc. com/obj/eden-cn/lapzild-tss/ljhwZthlaukjlkulzlp/seed2/0214/Seed2. 0% 20Model% 20Card. pdf, 2026
2026
-
[35]
Depth anything v2,
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,”Advances in Neural Information Processing Sys- tems, vol. 37, pp. 21 875–21 911, 2024
2024
-
[36]
Vitpose: Simple vision transformer baselines for human pose estimation,
Y . Xu, J. Zhang, Q. Zhang, and D. Tao, “Vitpose: Simple vision transformer baselines for human pose estimation,”Advances in neural information processing systems, vol. 35, pp. 38 571–38 584, 2022
2022
-
[37]
Dynamic complementarity conditions and whole-body trajectory optimization for humanoid robot locomotion,
S. Dafarra, G. Romualdi, and D. Pucci, “Dynamic complementarity conditions and whole-body trajectory optimization for humanoid robot locomotion,”IEEE Transactions on Robotics, vol. 38, no. 6, pp. 3414– 3433, 2022
2022
-
[38]
Alore: Au- tonomous large-object rearrangement with a legged manipulator,
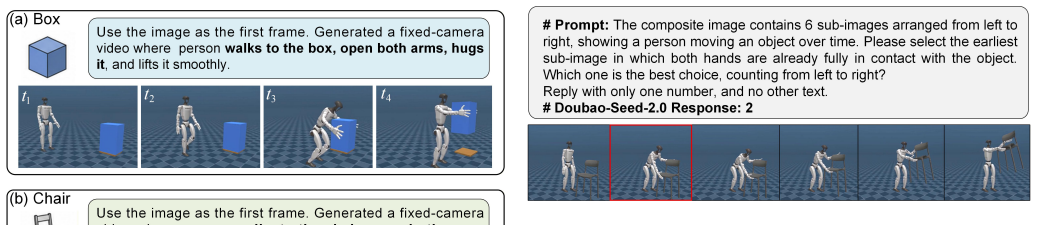
Z. Bi, Y . Zhang, K. Chen, G. Zhao, Y . Li, and J. Ma, “Alore: Au- tonomous large-object rearrangement with a legged manipulator,”arXiv preprint arXiv:2602.04214, 2026. Fig. 9. Object-specific prompts and representative key frames from the generated videos. APPENDIXA VIDEOGENERATIONPROMPTS To guide the video diffusion model toward physically plausi- ble a...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.