MiniPIC: Flexible Position-Independent Caching in <100LOC
Pith reviewed 2026-06-27 07:10 UTC · model grok-4.3
The pith
MiniPIC enables multiple position-independent caching methods in vLLM using under 100 lines of changes via unrotated keys and three primitives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MiniPIC stores unrotated K vectors in the KV cache, applies RoPE to K tiles inside attention using per-request logical positions, and exposes three user-facing and token-level primitives: block-aligned padding, span separator (SSep), and prompt depend (PDep), that modify hashing behavior and effective block-level causal attention structure. With fewer than 100 lines of core-engine changes plus a custom attention backend, these primitives are sufficient to realize multiple PIC methods, including Block-Attention, EPIC, and Prompt Cache, within the same running vLLM instance, while natively integrating with KV cache CPU offload implementations.
What carries the argument
The positional-encoding-free KV cache combined with the three primitives (block-aligned padding, span separator, and prompt depend) that adjust hashing and causal attention structure.
If this is right
- Multiple PIC methods including Block-Attention, EPIC, and Prompt Cache can be realized in the same vLLM instance.
- Native integration with KV cache CPU offload is maintained.
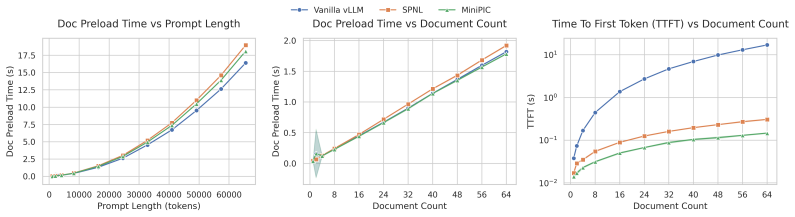
- Prefill throughput improves by 49% over baseline on 2WikiMultihopQA with interleaved scheduling.
- Time-to-first-token for cached spans reduces by up to two orders of magnitude.
- Linear prefill scaling is preserved for uncached spans with only 5.7% worst-case overhead.
Where Pith is reading between the lines
- The primitives could be adapted to support dynamic span reuse in long-context agent interactions.
- This minimal approach suggests that other inference servers might achieve similar PIC flexibility with comparable code changes.
- Workloads involving code files or documents could see further optimizations by tuning the separator and depend primitives.
- Integration with CPU offload implies potential for larger cache sizes without GPU memory limits.
Load-bearing premise
Storing unrotated K vectors and applying RoPE to K tiles inside attention using per-request logical positions preserves correct causal attention semantics and enables safe cache reuse without inconsistencies.
What would settle it
A test where two requests share a span but have different logical positions, checking if the attention computation produces identical results to independent computation and that no incorrect cache hits occur.
Figures

read the original abstract
Retrieval-augmented and agentic workloads repeatedly prefill recurring predictable structured inputs (which we call "spans") such as documents and code files. Yet, prefix caching in engines such as vLLM cannot reuse their KV entries unless they share identical prefixes with another request, while Position-Independent Caching (PIC) implementations within production-grade inference servers typically either require substantial server code changes or keep KV state outside the server, incurring host-to-device transfer overhead. We present Minimalistic PIC (MiniPIC): a minimal, flexible and fast vLLM design built from two ingredients: positional-encoding-free KV cache and user-controlled cache-reuse primitives. MiniPIC stores unrotated K vectors in the KV cache, applies RoPE to K tiles inside attention using per-request logical positions, and exposes three user-facing and token-level primitives: block-aligned padding, span separator (SSep), and prompt depend (PDep), that modify hashing behavior and effective block-level causal attention structure. With fewer than 100 lines of core-engine changes plus a custom attention backend, these primitives are sufficient to realize multiple PIC methods, including Block-Attention, EPIC, and Prompt Cache, within the same running vLLM instance, while natively integrating with KV cache CPU offload implementations. On 2WikiMultihopQA, MiniPIC with interleaved scheduling improves prefill throughput by 49% over baseline vLLM, reduces cached-span time-to-first-token by up to two orders of magnitude, preserves the linear prefill scaling of uncached spans, and incurs only 5.7% worst-case overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MiniPIC, a minimalistic Position-Independent Caching (PIC) design for vLLM. It stores unrotated K vectors in the KV cache, applies RoPE to K tiles inside a custom attention backend using per-request logical positions, and exposes three token-level primitives (block-aligned padding, span separator (SSep), and prompt depend (PDep)) that modify hashing and block-level causality. The central claim is that these require fewer than 100 lines of core-engine changes plus the custom backend, suffice to realize multiple PIC methods (Block-Attention, EPIC, Prompt Cache) in the same running instance, integrate natively with KV cache CPU offload, and deliver 49% prefill throughput gains plus up to two orders of magnitude TTFT reduction on 2WikiMultihopQA with only 5.7% worst-case overhead.
Significance. If the implementation and correctness arguments hold, the result would be significant for production inference engines: it offers a low-effort, flexible PIC mechanism that avoids both heavy server modifications and external KV-state management while preserving linear scaling for uncached spans and integrating with existing offload paths. The ability to realize multiple distinct PIC policies via the same primitives inside one vLLM instance is a notable engineering contribution.
major comments (2)
- [Abstract] Abstract: the central claim that storing unrotated K vectors and applying RoPE inside the attention kernel using per-request logical positions, together with the three primitives, preserves identical attention scores, masks, and causal semantics to a standard RoPE-prefixed sequence (even when a cached span appears at different absolute positions) is presented without any correctness argument, pseudocode for the custom backend, or verification steps. This is load-bearing for the sufficiency claim that no further engine modifications are required.
- [Abstract] Abstract: the performance claims (49% prefill throughput improvement over baseline vLLM, up to 100x reduction in cached-span TTFT, 5.7% worst-case overhead, and preservation of linear prefill scaling) are stated without reference to experimental setup details, baseline configurations, workload characteristics, or ablation results isolating the contribution of each primitive, preventing assessment of whether the numbers support the <100LOC claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments both concern the abstract's brevity. We address them point-by-point below and will revise the manuscript accordingly to improve clarity while preserving the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that storing unrotated K vectors and applying RoPE inside the attention kernel using per-request logical positions, together with the three primitives, preserves identical attention scores, masks, and causal semantics to a standard RoPE-prefixed sequence (even when a cached span appears at different absolute positions) is presented without any correctness argument, pseudocode for the custom backend, or verification steps. This is load-bearing for the sufficiency claim that no further engine modifications are required.
Authors: We agree the abstract is too concise on this point. The full manuscript (Section 3) derives that unrotated K storage plus per-request logical-position RoPE application yields identical attention scores and masks to standard RoPE, because RoPE is a relative rotation and the custom backend applies the same rotation matrix per token using the request's logical positions rather than absolute cache indices. Block-level causality is enforced via the SSep and PDep primitives that adjust the attention mask at block granularity. We will add a one-paragraph correctness sketch and a short pseudocode listing of the custom backend to the revised manuscript (main text or appendix) to make the argument self-contained. revision: yes
-
Referee: [Abstract] Abstract: the performance claims (49% prefill throughput improvement over baseline vLLM, up to 100x reduction in cached-span TTFT, 5.7% worst-case overhead, and preservation of linear prefill scaling) are stated without reference to experimental setup details, baseline configurations, workload characteristics, or ablation results isolating the contribution of each primitive, preventing assessment of whether the numbers support the <100LOC claim.
Authors: The abstract is space-constrained, but the experimental details appear in Section 5: all runs use the same 2WikiMultihopQA workload on A100 GPUs with vLLM v0.4 baseline, interleaved scheduling, and the three primitives enabled. Linear scaling is shown for uncached spans; the 5.7% overhead is measured on fully uncached requests. Ablations isolating padding, SSep, and PDep are in Figure 7. We will revise the abstract to include a parenthetical reference to the experimental setup and workload, and ensure the <100LOC claim is cross-referenced to the diff in Appendix A. revision: yes
Circularity Check
No circularity: systems implementation with no derivations or fitted predictions
full rationale
The paper is a systems description of a vLLM modification using unrotated KV storage, an in-attention RoPE application, and three user primitives (block-aligned padding, SSep, PDep). It contains no equations, no parameter fitting, no predictions of quantities defined inside the work, and no self-citation chains that bear the central claim. All reported results are benchmark measurements on 2WikiMultihopQA; the implementation is presented as self-contained engineering changes whose correctness is evaluated externally via throughput and latency numbers rather than by internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Paul Castro, Nick Mitchell, Nathan Ordonez, Thomas Parnell, and Mudhakar Srivatsa. Using span queries to optimize for cache and attention locality.arXiv preprint arXiv:2511.02749, 2025. URL https://arxiv.org/abs/2511.02749. arXiv:2511.02749
arXiv 2025
-
[2]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models.arXiv preprint, 2025. doi: 10.48550/arXiv.2512.02556. URLhttps://arxiv.org/abs/2512.02556
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.02556 2025
-
[3]
J. Hu et al. Epic: Efficient position-independent caching for serving large language models.arXiv preprint, 2024. doi: 10.48550/arXiv.2410.15332. URL https://doi.org/10.48550/arXiv.2410. 15332. Accepted at ICML 2025
-
[4]
arXiv preprint arXiv:2510.09665 , year=
Y . Liu et al. Lmcache: An efficient kv cache layer for enterprise-scale llm inference.arXiv preprint, 2025. doi: 10.48550/arXiv.2510.09665. URLhttps://doi.org/10.48550/arXiv.2510.09665
-
[5]
llama.cpp: Port of facebook’s llama model in c/c++, 2023
ggerganov. llama.cpp: Port of facebook’s llama model in c/c++, 2023. URL https://github.com/ ggerganov/llama.cpp. Open-source CPU inference engine for LLMs
2023
-
[6]
I. Gim, G. Chen, S. s. Lee, N. Sarda, A. Khandelwal, and L. Zhong. Prompt cache: Modular attention reuse for low-latency inference.arXiv preprint, 2023. doi: 10.48550/arXiv.2311.04934. URL https: //doi.org/10.48550/arXiv.2311.04934
-
[7]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, 2020
2020
-
[8]
Transformers: State-of-the-art machine learning for pytorch, tensorflow, and jax, 2023
Hugging Face. Transformers: State-of-the-art machine learning for pytorch, tensorflow, and jax, 2023. URL https://github.com/huggingface/transformers. Research-focused library for transformer models
2023
-
[9]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23), 2023
2023
-
[10]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval- Augmented generation for knowledge-Intensive NLP tasks.arXiv preprint, 2020. doi: 10.48550/arXiv. 2005.11401. URL https://doi.org/10.48550/arXiv.2005.11401....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2020
-
[11]
Accepted at NeurIPS 2020
2020
-
[12]
Lin et al
W. Lin et al. Towards efficient agents: A co-design of inference architecture and system.arXiv preprint,
-
[13]
Towards efficient agents: A co-design of inference architecture and system,
doi: 10.48550/arXiv.2512.18337. URLhttps://doi.org/10.48550/arXiv.2512.18337
-
[14]
X. Lin, A. Ghosh, B. K. H. Low, A. Shrivastava, and V . Mohan. Refrag: Rethinking rag based decoding. arXiv preprint, 2025. doi: 10.48550/arXiv.2509.01092. URL https://doi.org/10.48550/arXiv. 2509.01092. 10
-
[15]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Hao Yang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui Qu, J.L. Cai, Jian Liang, Jianzhong...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.04434 2024
-
[16]
T. Y . Liu, A. Achille, M. Trager, A. Golatkar, L. Zancato, and S. Soatto. Picaso: Permutation-invariant context composition with state space models.arXiv preprint, 2025. doi: 10.48550/arXiv.2502.17605. URL https://doi.org/10.48550/arXiv.2502.17605
-
[17]
D. Ma, Y . Wang, and L. Tian. Block-attention for efficient prefilling.arXiv preprint, 2024. doi: 10.48550/arXiv.2409.15355. URL https://doi.org/10.48550/arXiv.2409.15355. Accepted at ICLR 2025
-
[18]
T. Merth, Q. Fu, M. Rastegari, and M. Najibi. Superposition prompting: Improving and accelerating retrieval-augmented generation.arXiv preprint, 2024. doi: 10.48550/arXiv.2404.06910. URL https: //doi.org/10.48550/arXiv.2404.06910
-
[19]
Llama 3 model card, 2024
Meta AI. Llama 3 model card, 2024. URL https://github.com/meta-llama/llama3/blob/main/ MODEL_CARD.md
2024
-
[20]
Llama 4 technical report, 2025
Meta Llama Team. Llama 4 technical report, 2025. URLhttps://ai.meta.com/llama-4
2025
-
[21]
TensorRT-LLM, 2026
NVIDIA. TensorRT-LLM, 2026. URL https://github.com/NVIDIA/TensorRT-LLM. GitHub reposi- tory, accessed 2026-05-18
2026
-
[22]
David L. Parnas. On the criteria to be used in decomposing systems into modules.Communications of the ACM, 15(12):1053–1058, 1972. doi: 10.1145/361598.361623
-
[23]
Mooncake: A kvcache-centric disaggregated architecture for llm serving.arXiv preprint, 2024
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Mooncake: A kvcache-centric disaggregated architecture for llm serving.arXiv preprint, 2024
2024
-
[24]
Roformer: Enhanced transformer with rotary position embedding.arXiv preprint, 2021
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.arXiv preprint, 2021
2021
-
[25]
Philippe Tillet, Hsiang-Tsung Kung, and David D. Cox. Triton: an intermediate language and compiler for tiled neural network computations.Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, 2019. URL https://api.semanticscholar.org/ CorpusID:184488182
2019
-
[26]
Kv cache offloading — production-stack.vLLM Documentation,
vLLM Contributors. Kv cache offloading — production-stack.vLLM Documentation,
-
[27]
URL https://docs.vllm.ai/projects/production-stack/en/vllm-stack-0.1.2/ tutorials/kv_cache.html
-
[28]
Mepic: Memory efficient position independent caching for llm serving.arXiv preprint, 2025
Qian Wang, Zahra Yousefijamarani, Morgan Lindsay Heisler, Rongzhi Gu, Bai Xiaolong, Shan Yizhou, Wei Zhang, Wang Lan, Ying Xiong, Yong Zhang, and Zhenan Fan. Mepic: Memory efficient position independent caching for llm serving.arXiv preprint, 2025. doi: 10.48550/arXiv.2512.16822. URL https://arxiv.org/abs/2512.16822
-
[29]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint, 2023. doi: 10.48550/arXiv.2309.17453. URL https: //arxiv.org/abs/2309.17453. ICLR 2024; version 4 last revised 7 Apr 2024
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.17453 2023
-
[30]
Sglang hicache: Fast hierarchical kv caching with your favorite storage backends.LMSYS Org Blog, 2025
Zhiqiang Xie. Sglang hicache: Fast hierarchical kv caching with your favorite storage backends.LMSYS Org Blog, 2025. URLhttps://lmsys.org/blog/2025-09-10-sglang-hicache/. 11
2025
-
[31]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. Cacheblend: Fast large language model serving for rag with cached knowledge fusion. arXiv preprint, 2024. doi: 10.48550/arXiv.2405.16444. URL https://doi.org/10.48550/arXiv. 2405.16444
-
[32]
Gonzalez, et al
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, et al. Sglang: Efficient execution of structured language model programs.arXiv preprint, 2023. 12 A CIDRA: Analysis of Copy-Based Repositioning When two requests share a span at different positions, SPNL’s CIDRA ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.