Cross-Modal Masked Compositional Concept Modeling for Enhancing Visio-Linguistic Compositionality
Pith reviewed 2026-06-27 07:01 UTC · model grok-4.3
The pith
Cross-modal masking of compositional concepts lets vision-language models capture object relations and attribute bindings rather than acting as bags of words.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
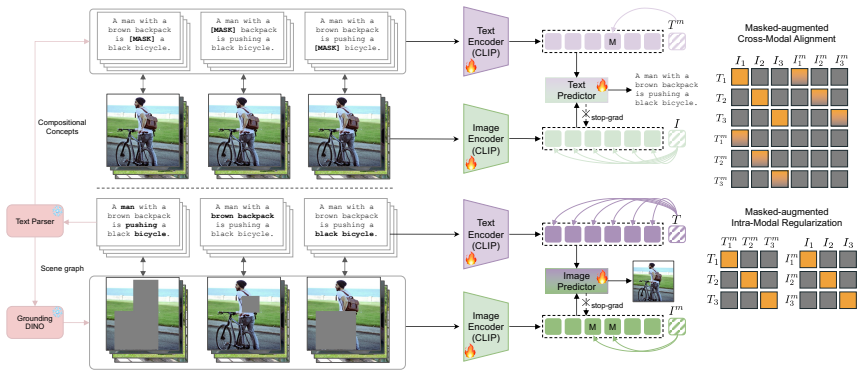
By masking compositional concepts in one modality and reconstructing them conditioned on the full contextual information from the other modality, along with two auxiliary objectives that jointly align and regularize masked features inter-modally and intra-modally, the model captures and aligns cross-modal compositional structures more effectively than standard contrastive training.
What carries the argument
The MACCO framework, which performs masked compositional concept modeling by hiding elements in one modality and reconstructing from the other, supported by auxiliary inter-modal and intra-modal alignment objectives.
If this is right
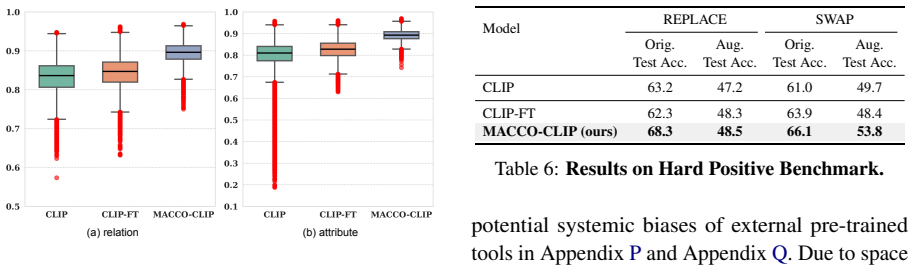
- The approach significantly enhances compositionality on five standard compositional benchmarks.
- Models trained this way improve their capture of syntactic structure and linguistic information.
- The gains in compositionality transfer to better text-to-image generation results.
- Multimodal large language models benefit from the improved compositional representations.
Where Pith is reading between the lines
- The method might allow existing paired datasets to be used more efficiently without requiring specially curated compositional examples.
- Cross-modal reconstruction could be tested as a general regularizer in other contrastive multimodal setups beyond CLIP-style training.
- If the auxiliary objectives prove robust, they might be adapted to handle partial or noisy inputs in one modality.
- Better compositionality could reduce errors in downstream applications that rely on precise attribute and relation understanding.
Load-bearing premise
The rich compositional information inherently present in paired image-text data can be effectively exploited and aligned by masking compositional concepts in one modality and reconstructing them conditioned on the full contextual information from the other, along with the two auxiliary objectives.
What would settle it
A controlled experiment that applies the MACCO masking and auxiliary objectives during training but measures no improvement or a decline on compositional benchmarks testing attribute-object binding, relations, or word order would falsify the central claim.
Figures

read the original abstract
Contrastively trained vision-language models like CLIP, have made remarkable progress in learning joint image-text representations, but still face challenges in compositional understanding. They often exhibit a "bag-of-words" behavior--struggling to capture the object relations, attribute-object bindings, and word order dependencies. This limitation arises not only from the reliance on global, single-vector representations for optimization, but also from the insufficient exploitation and modeling of the rich compositional information inherently present in paired image text data. In this work, we propose MACCO (MAsked Compositional Concept MOdeling), a framework that masks compositional concepts in one modality and reconstructs them conditioned on the full contextual information from the other, enabling the model to capture and align cross-modal compositional structures more effectively. To facilitate this process, we introduce two auxiliary objectives that jointly align and regularize masked features both inter-modally and intra-modally. Extensive experiments on five compositional benchmarks, along with in-depth analyses, demonstrate that our approach not only significantly enhances compositionality in VLMs but also improves their ability to capture syntactic structure and linguistic information. Additionally, the improved compositionality also benefits text-to-image generation and multimodal large language model. Code is available at https://github.com/hiker-lw/MACCO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MACCO, a cross-modal masked modeling framework for vision-language models. It masks compositional concepts (objects, attributes, relations) in one modality and reconstructs them using full contextual information from the other modality, augmented by two auxiliary objectives that enforce inter-modal and intra-modal alignment of the masked features. The central claim is that this procedure better exploits latent compositional structure in paired image-text data than standard contrastive training, yielding gains on five compositional benchmarks plus improvements in syntactic/linguistic capture, text-to-image generation, and downstream MLLM performance.
Significance. If the reported gains are robust, the work would be a useful incremental advance in addressing the well-known bag-of-words limitation of CLIP-style models. The cross-modal masking-plus-reconstruction idea is a natural extension of masked modeling to the compositionality setting and could be adopted by other VL pre-training pipelines. The additional benefits claimed for generation and MLLMs would increase its practical impact if replicated.
minor comments (3)
- The abstract states that experiments were run on 'five compositional benchmarks' but does not name them; the introduction or experimental section should list the exact datasets (e.g., Winoground, VL-Checklist, etc.) and report per-benchmark numbers rather than aggregate claims.
- The description of the two auxiliary objectives is high-level; a precise formulation (loss equations, masking ratios, conditioning mechanism) should appear in §3 so that the inter- versus intra-modal alignment terms can be reproduced.
- The paper claims benefits to text-to-image generation and MLLMs; these results should be presented with the same level of detail and controls as the main VLM compositionality tables, including ablation of the auxiliary objectives.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for acknowledging the potential utility of the cross-modal masking approach for addressing compositionality limitations in VLMs. We are encouraged by the recognition that the idea is a natural extension and could be adopted more broadly. Since the report raises no specific major comments or concerns, we have no point-by-point revisions to address at this time.
Circularity Check
No significant circularity
full rationale
The paper presents MACCO as an empirical training procedure: masking compositional concepts in one modality, reconstructing them from full cross-modal context, plus two auxiliary inter/intra-modal alignment losses. No derivation chain, first-principles prediction, or equation is offered that reduces by construction to its own inputs or to a self-citation. The central claim is that this procedure exploits latent structure already present in paired image-text data; success is asserted via benchmark gains rather than any tautological identity or fitted-parameter renaming. The method is therefore self-contained against external evaluation and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2207.00221 , year=
Vl-checklist: Evaluating pre-trained vision-language models with objects, attributes and relations , author=. arXiv preprint arXiv:2207.00221 , year=
-
[2]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Cascante-Bonilla, Paola and Shehada, Khaled and Smith, James Seale and Doveh, Sivan and Kim, Donghyun and Panda, Rameswar and Varol, Gul and Oliva, Aude and Ordonez, Vicente and Feris, Rogerio and Karlinsky, Leonid , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2023 , pages =
2023
-
[3]
arXiv preprint arXiv:2106.08254 , year=
Beit: Bert pre-training of image transformers , author=. arXiv preprint arXiv:2106.08254 , year=
-
[4]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[5]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Masked autoencoders are scalable vision learners , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[6]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Simmim: A simple framework for masked image modeling , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[7]
arXiv preprint arXiv:2208.02131 , year=
Masked vision and language modeling for multi-modal representation learning , author=. arXiv preprint arXiv:2208.02131 , year=
-
[8]
arXiv preprint arXiv:2109.12178 , year=
MLIM: Vision-and-Language Model Pre-training with Masked Language and Image Modeling , author=. arXiv preprint arXiv:2109.12178 , year=
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Unified visual-semantic embeddings: Bridging vision and language with structured meaning representations , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[10]
European Conference on Computer Vision , pages=
Grounding dino: Marrying dino with grounded pre-training for open-set object detection , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[11]
arXiv preprint arXiv:2305.14897 , year=
Text encoders bottleneck compositionality in contrastive vision-language models , author=. arXiv preprint arXiv:2305.14897 , year=
-
[12]
arXiv preprint arXiv:2412.08111 , year=
Seeing Syntax: Uncovering Syntactic Learning Limitations in Vision-Language Models , author=. arXiv preprint arXiv:2412.08111 , year=
-
[13]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Interpretable Composition Attribution Enhancement for Visio-linguistic Compositional Understanding , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[14]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Distilling Knowledge from Text-to-Image Generative Models Improves Visio-Linguistic Reasoning in CLIP , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[15]
Computer vision--ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13 , pages=
Microsoft coco: Common objects in context , author=. Computer vision--ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13 , pages=. 2014 , organization=
2014
-
[16]
arXiv preprint arXiv:1412.6980 , year=
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
-
[17]
If you use this software, please cite it as below , pages=
Openclip , author=. If you use this software, please cite it as below , pages=
-
[18]
Advances in Neural Information Processing Systems , volume=
Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Winoground: Probing vision and language models for visio-linguistic compositionality , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[20]
arXiv preprint arXiv:2112.07566 , year=
Valse: A task-independent benchmark for vision and language models centered on linguistic phenomena , author=. arXiv preprint arXiv:2112.07566 , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
Cyclip: Cyclic contrastive language-image pretraining , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Iterated learning improves compositionality in large vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[23]
Proceedings of the 38th International Conference on Machine Learning , pages =
Learning Transferable Visual Models From Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , volume =
2021
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Contrasting intra-modal and ranking cross-modal hard negatives to enhance visio-linguistic compositional understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[25]
The Eleventh International Conference on Learning Representations , year=
When and Why Vision-Language Models Behave like Bags-Of-Words, and What to Do About It? , author=. The Eleventh International Conference on Learning Representations , year=
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vita-clip: Video and text adaptive clip via multimodal prompting , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
arXiv preprint arXiv:2204.06125 , volume=
Hierarchical text-conditional image generation with clip latents , author=. arXiv preprint arXiv:2204.06125 , volume=
-
[28]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[29]
arXiv preprint arXiv:2304.10592 , year=
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv preprint arXiv:2304.10592 , year=
-
[30]
arXiv preprint arXiv:2111.09734 , year=
Clipcap: Clip prefix for image captioning , author=. arXiv preprint arXiv:2111.09734 , year=
-
[31]
International conference on machine learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[32]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Enhancing multimodal compositional reasoning of visual language models with generative negative mining , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[33]
Dense and Aligned Captions (DAC) Promote Compositional Reasoning in VL Models , volume =
Doveh, Sivan and Arbelle, Assaf and Harary, Sivan and Herzig, Roei and Kim, Donghyun and Cascante-Bonilla, Paola and Alfassy, Amit and Panda, Rameswar and Giryes, Raja and Feris, Rogerio and Ullman, Shimon and Karlinsky, Leonid , booktitle =. Dense and Aligned Captions (DAC) Promote Compositional Reasoning in VL Models , volume =
-
[34]
European Conference on Computer Vision , pages=
The hard positive truth about vision-language compositionality , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[35]
TripletCLIP: Improving Compositional Reasoning of CLIP via Synthetic Vision-Language Negatives , volume =
Patel, Maitreya and Kusumba, Abhiram and Cheng, Sheng and Kim, Changhoon and Gokhale, Tejas and Baral, Chitta and Yang, Yezhou , booktitle =. TripletCLIP: Improving Compositional Reasoning of CLIP via Synthetic Vision-Language Negatives , volume =
-
[36]
arXiv preprint arXiv:2503.01167 , year=
Enhancing Vision-Language Compositional Understanding with Multimodal Synthetic Data , author=. arXiv preprint arXiv:2503.01167 , year=
-
[37]
arXiv preprint arXiv:2310.19785 , year=
What's" up" with vision-language models? Investigating their struggle with spatial reasoning , author=. arXiv preprint arXiv:2310.19785 , year=
-
[38]
arXiv preprint arXiv:1708.00055 , year=
Semeval-2017 task 1: Semantic textual similarity-multilingual and cross-lingual focused evaluation , author=. arXiv preprint arXiv:1708.00055 , year=
Pith/arXiv arXiv 2017
-
[39]
Proceedings of the 8th international workshop on semantic evaluation (SemEval 2014) , pages=
Semeval-2014 task 1: Evaluation of compositional distributional semantic models on full sentences through semantic relatedness and textual entailment , author=. Proceedings of the 8th international workshop on semantic evaluation (SemEval 2014) , pages=
2014
-
[40]
Findings of the Association for Computational Linguistics: EACL 2024 , pages=
Does CLIP Bind Concepts? Probing Compositionality in Large Image Models , author=. Findings of the Association for Computational Linguistics: EACL 2024 , pages=
2024
-
[41]
Advances in Neural Information Processing Systems , volume=
T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Zegclip: Towards adapting clip for zero-shot semantic segmentation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[43]
arXiv preprint arXiv:1803.05449 , year=
Senteval: An evaluation toolkit for universal sentence representations , author=. arXiv preprint arXiv:1803.05449 , year=
-
[44]
Proceedings of the 41st International Conference on Machine Learning , pages =
Improving fine-grained understanding in image-text pre-training , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , volume =
2024
-
[45]
arXiv preprint arXiv:2405.20204 , year=
Jina clip: Your clip model is also your text retriever , author=. arXiv preprint arXiv:2405.20204 , year=
-
[46]
2009 , publisher=
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
2009
-
[47]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[48]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Eyes wide shut? exploring the visual shortcomings of multimodal llms , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[49]
arXiv preprint arXiv:2211.00768 , year=
Why is winoground hard? investigating failures in visuolinguistic compositionality , author=. arXiv preprint arXiv:2211.00768 , year=
-
[50]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Lit: Zero-shot transfer with locked-image text tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[51]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Vl-adapter: Parameter-efficient transfer learning for vision-and-language tasks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[52]
arXiv preprint arXiv:2211.09799 , year=
Cae v2: Context autoencoder with clip target , author=. arXiv preprint arXiv:2211.09799 , year=
-
[53]
Advances in Neural Information Processing Systems , volume=
Scaling open-vocabulary object detection , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
Transactions of the association for computational linguistics , volume=
Spanbert: Improving pre-training by representing and predicting spans , author=. Transactions of the association for computational linguistics , volume=. 2020 , publisher=
2020
-
[55]
International conference on machine learning , pages=
Unilmv2: Pseudo-masked language models for unified language model pre-training , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[56]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Teaching structured vision & language concepts to vision & language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[57]
arXiv preprint arXiv:2410.05210 , year=
Preserving multi-modal capabilities of pre-trained VLMs for improving vision-linguistic compositionality , author=. arXiv preprint arXiv:2410.05210 , year=
-
[58]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Assessing and Learning Alignment of Unimodal Vision and Language Models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[59]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
2020
-
[60]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
ZeLa: Advancing Zero-Shot Multilingual Semantic Parsing with Large Language Models and Chain-of-Thought Strategies , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[61]
Neurocomputing , volume=
Enhancing zero-shot multilingual semantic parsing: A framework leveraging large language models for data augmentation and advanced prompting techniques , author=. Neurocomputing , volume=. 2025 , publisher=
2025
-
[62]
International Conference on Machine Learning , pages=
Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[63]
2004 Conference on Computer Vision and Pattern Recognition Workshop , pages=
Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories , author=. 2004 Conference on Computer Vision and Pattern Recognition Workshop , pages=. 2004 , organization=
2004
-
[64]
Proceedings of the IEEE , volume=
Gradient-based learning applied to document recognition , author=. Proceedings of the IEEE , volume=. 2002 , publisher=
2002
-
[65]
International Journal of Computer Vision , volume=
The pascal visual object classes (voc) challenge , author=. International Journal of Computer Vision , volume=. 2010 , publisher=
2010
-
[66]
arXiv preprint arXiv:1306.5151 , year=
Fine-grained visual classification of aircraft , author=. arXiv preprint arXiv:1306.5151 , year=
-
[67]
Proceedings of the 34th International Conference on Neural Information Processing Systems , pages=
The hateful memes challenge: detecting hate speech in multimodal memes , author=. Proceedings of the 34th International Conference on Neural Information Processing Systems , pages=
-
[68]
International Conference on Neural Information Processing Systems , pages=
Challenges in representation learning: A report on three machine learning contests , author=. International Conference on Neural Information Processing Systems , pages=
-
[69]
Proceedings of the IEEE , volume=
Remote sensing image scene classification: Benchmark and state of the art , author=. Proceedings of the IEEE , volume=. 2017 , publisher=
2017
-
[70]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=. 2019 , publisher=
2019
-
[71]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
T2i-compbench++: An enhanced and comprehensive benchmark for compositional text-to-image generation , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2025 , publisher=
2025
-
[72]
ACM transactions on Graphics (TOG) , volume=
Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models , author=. ACM transactions on Graphics (TOG) , volume=. 2023 , publisher=
2023
-
[73]
Advances in Neural Information Processing Systems , volume=
Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[74]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[75]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[76]
Advances in Neural Information Processing Systems , volume=
Imagereward: Learning and evaluating human preferences for text-to-image generation , author=. Advances in Neural Information Processing Systems , volume=
-
[77]
arXiv preprint arXiv:2311.07397 , year=
Amber: An llm-free multi-dimensional benchmark for mllms hallucination evaluation , author=. arXiv preprint arXiv:2311.07397 , year=
-
[78]
Chaoyou Fu and Peixian Chen and Yunhang Shen and Yulei Qin and Mengdan Zhang and Xu Lin and Jinrui Yang and Xiawu Zheng and Ke Li and Xing Sun and Yunsheng Wu and Rongrong Ji and Caifeng Shan and Ran He , booktitle=
-
[79]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[80]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Altclip: Altering the language encoder in clip for extended language capabilities , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.