SupraBench: A Benchmark for Supramolecular Chemistry
Pith reviewed 2026-06-27 07:32 UTC · model grok-4.3
The pith
The first benchmark for LLMs on supramolecular host-guest tasks shows substantial remaining headroom and mixed effects from domain pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
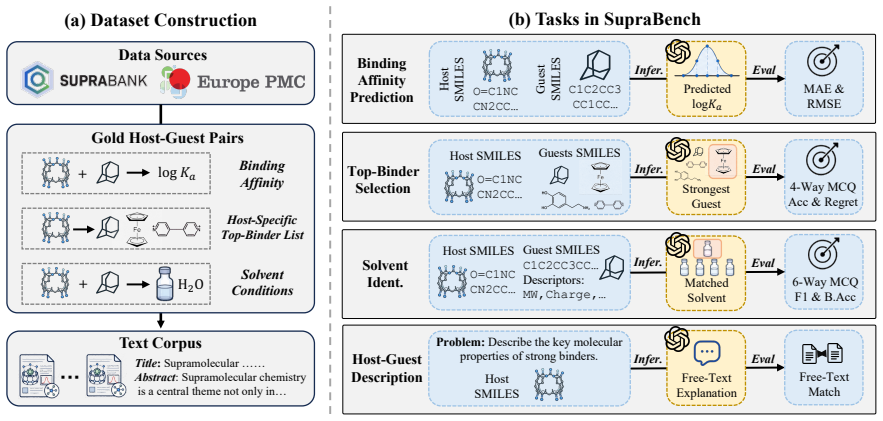
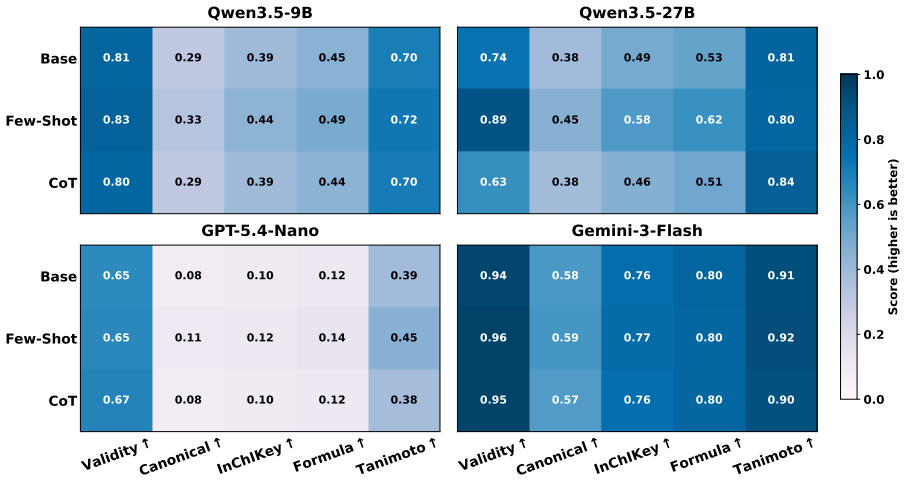
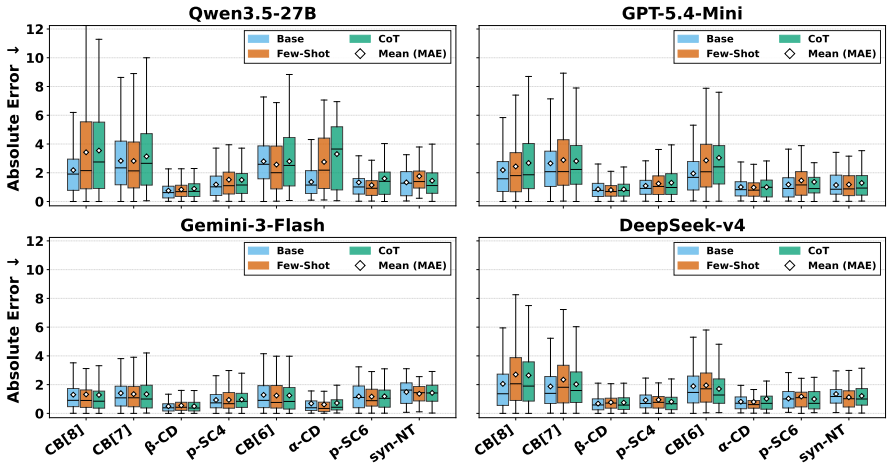
SupraBench is the first benchmark designed with domain experts to evaluate LLMs on core supramolecular chemistry reasoning, built around four tasks—binding affinity prediction, top-binder selection, solvent identification, and host-guest description—plus an auxiliary vision-based molecular identification task. The released SupraPMC corpus of 16M tokens supports adaptation to the domain. Evaluations establish that LLMs leave substantial headroom on all tasks, domain adaptation transfers cleanly to regression but trades off against letter-format constraints, and task families exhibit sharply different difficulty profiles that expose specific gaps in current supramolecular reasoning.
What carries the argument
SupraBench, the set of four core tasks and one vision task for testing host-guest reasoning, together with the SupraPMC pretraining corpus.
If this is right
- Domain pretraining on SupraPMC improves regression accuracy on binding affinity tasks.
- Task families show distinct difficulty profiles and failure modes.
- Pretraining benefits conflict with requirements for strict letter-format output.
- Current LLMs remain unreliable substitutes for days of dry-lab verification in host-guest design.
Where Pith is reading between the lines
- Task-specific fine-tuning or output-constrained adaptation methods could resolve the observed trade-off.
- The benchmark's task breakdown could guide targeted improvements in multimodal chemistry models.
- Extending the tasks to larger assemblies or dynamic processes would test whether the identified gaps generalize.
- Public release of the benchmark and corpus enables community measurement of progress on these specific chemistry reasoning problems.
Load-bearing premise
The four designed tasks plus the auxiliary vision task are representative of the core reasoning challenges in supramolecular host-guest chemistry.
What would settle it
Demonstration of an LLM achieving near-ceiling performance on all SupraBench tasks with no regression in output format after domain pretraining would falsify the claims of substantial headroom and mixed adaptation effects.
Figures







read the original abstract
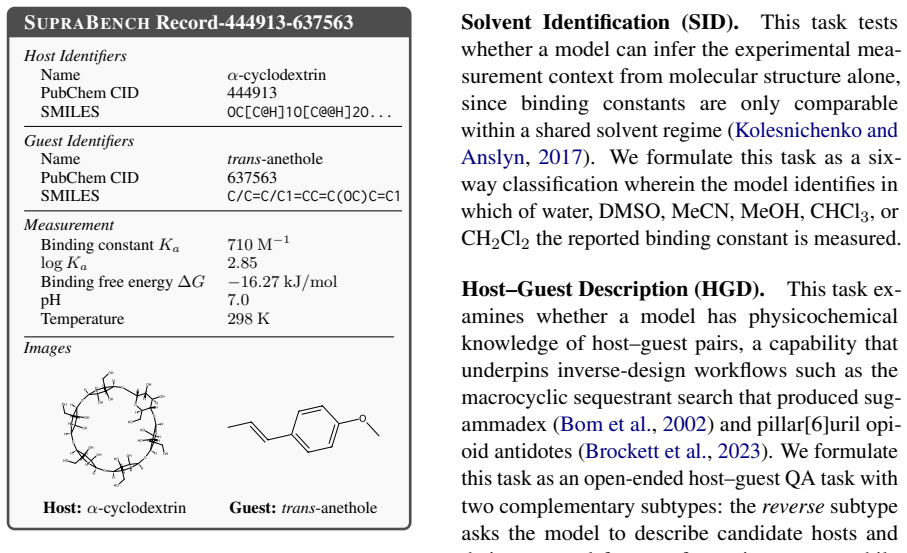
Supramolecular chemistry, which includes the study of non-covalent host-guest assemblies, has advanced various applications. However, designing host-guest systems remains time-consuming, requiring days of dry-lab verification per candidate pair. Although LLMs have emerged as a fast alternative with strong performance on molecular binding tasks, no benchmark currently systematically evaluates LLMs for host-guest reasoning across fundamental supramolecular chemistry tasks, e.g., binding affinity prediction. To this end, we collaborate with domain experts to release the first Supramolecular Benchmark, called SupraBench, to evaluate LLMs in chemistry reasoning. Specifically, we design four fundamental tasks, i.e., binding affinity prediction, top-binder selection, solvent identification, and host-guest description, plus an auxiliary vision-based task for molecular identification. We also release SupraPMC, a curated 16M-token corpus of Supramolecular chemistry articles distilled from Europe PMC, to support the adaptation to the supramolecular domain. We benchmark a broad range of open and proprietary LLMs and find that LLMs leave substantial headroom across all tasks. Domain adaptation pretraining over SupraPMC transfers cleanly to in-distribution regression but trades off against strict letter-format output. Moreover, the difficulty profile differs sharply across task families, revealing distinct failure modes that indicate specific gaps in current supramolecular chemistry reasoning. Our source codes and benchmark datasets are available at https://github.com/Tianyi-Billy-Ma/SupraBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SupraBench, the first benchmark for LLM evaluation on supramolecular host-guest chemistry. It defines four core tasks (binding affinity prediction, top-binder selection, solvent identification, host-guest description) plus an auxiliary vision task, all designed with domain experts. The authors also release SupraPMC, a 16M-token corpus distilled from Europe PMC, for domain-adaptation pretraining. Benchmarking of open and proprietary LLMs shows substantial headroom on all tasks; SupraPMC adaptation transfers cleanly to in-distribution regression but trades off against strict letter-format output. Task difficulty profiles differ sharply, exposing distinct failure modes.
Significance. If the tasks prove representative of core supramolecular reasoning challenges, the benchmark and corpus would be a useful resource for measuring progress in scientific LLM reasoning. The explicit release of code, datasets, and the adaptation corpus is a clear strength that supports reproducibility. The reported trade-off between domain adaptation and output formatting could inform future work on specialized scientific domains.
major comments (1)
- [Task design section] Task design section: the claim that the four tasks plus vision auxiliary are representative of host-guest reasoning rests on the statement that they were 'designed with domain experts,' yet no description is given of the design process, validation criteria, coverage of non-covalent interaction types, multi-step assembly reasoning, or calibration against published host-guest problems. This directly affects the load-bearing claim that LLMs leave substantial headroom in supramolecular chemistry.
minor comments (2)
- Provide the exact prompting templates and output formats used for each task so that reported gaps can be reproduced.
- [SupraPMC corpus section] Clarify whether any overlap exists between SupraPMC articles and the benchmark instances to rule out data leakage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on SupraBench. We agree that the task design section requires additional detail on the development process with domain experts to strengthen the claim of representativeness, and we will revise accordingly.
read point-by-point responses
-
Referee: [Task design section] Task design section: the claim that the four tasks plus vision auxiliary are representative of host-guest reasoning rests on the statement that they were 'designed with domain experts,' yet no description is given of the design process, validation criteria, coverage of non-covalent interaction types, multi-step assembly reasoning, or calibration against published host-guest problems. This directly affects the load-bearing claim that LLMs leave substantial headroom in supramolecular chemistry.
Authors: We acknowledge that the current manuscript provides insufficient detail on the task design process. The four core tasks and auxiliary vision task were developed through consultation with supramolecular chemists to target fundamental host-guest reasoning challenges, including affinity prediction, binder selection, solvent effects, and structural description. However, the manuscript does not describe the iterative design workflow, explicit validation criteria, coverage across non-covalent interaction types (e.g., H-bonding, pi-stacking, van der Waals), multi-step assembly reasoning, or direct calibration to specific published host-guest systems. In the revised version, we will add a dedicated subsection under Task Design that outlines the expert consultation process, the rationale and scope for each task, the range of interaction types addressed, and alignment with representative literature examples. This expansion will better substantiate the benchmark's coverage and support the interpretation of performance gaps as evidence of remaining headroom, while clarifying the benchmark's intended scope. revision: yes
Circularity Check
No circularity: benchmark release with empirical evaluation only
full rationale
The paper is a benchmark construction and LLM evaluation release. It states tasks were designed with domain experts but contains no equations, no fitted parameters renamed as predictions, no self-citation chains, and no derivations that reduce to inputs by construction. All claims rest on external data collection, expert collaboration, and direct model testing rather than self-referential logic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[2]
2026 , url=
Introducing GPT-5.4 , author=. 2026 , url=
2026
-
[3]
2025 , url=
Gemini 3: A New Era of Intelligence , author=. 2025 , url=
2025
-
[4]
2026 , url =
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=. 2026 , url =
2026
-
[5]
arXiv preprint arXiv:2211.09085 , year=
Galactica: A large language model for science , author=. arXiv preprint arXiv:2211.09085 , year=
-
[6]
arXiv preprint arXiv:2402.06852 , year=
Chemllm: A chemical large language model , author=. arXiv preprint arXiv:2402.06852 , year=
-
[7]
Cell Rep
Developing ChemDFM as a large language foundation model for chemistry , author=. Cell Rep. Phys. Sci. , year=
-
[8]
arXiv preprint arXiv:2402.09391 , year=
Llasmol: Advancing large language models for chemistry with a large-scale, comprehensive, high-quality instruction tuning dataset , author=. arXiv preprint arXiv:2402.09391 , year=
-
[9]
ICLR , year=
Mol-instructions: A large-scale biomolecular instruction dataset for large language models , author=. ICLR , year=
-
[10]
Augmenting large language models with chemistry tools , author=. Nat. Mach. Intell , year=
-
[11]
Nature , year=
Autonomous chemical research with large language models , author=. Nature , year=
-
[12]
ICLR , year=
Chemagent: Self-updating memories in large language models improves chemical reasoning , author=. ICLR , year=
-
[13]
Chemical Science , year=
nach0: multimodal natural and chemical languages foundation model , author=. Chemical Science , year=
-
[14]
EMNLP , year=
Translation between molecules and natural language , author=. EMNLP , year=
-
[15]
Chemical science , year=
MoleculeNet: a benchmark for molecular machine learning , author=. Chemical science , year=
-
[16]
arXiv preprint arXiv:2102.09548 , year=
Therapeutics data commons: Machine learning datasets and tasks for drug discovery and development , author=. arXiv preprint arXiv:2102.09548 , year=
-
[17]
Nature Chemistry , year=
A framework for evaluating the chemical knowledge and reasoning abilities of large language models against the expertise of chemists , author=. Nature Chemistry , year=
-
[18]
arXiv preprint arXiv:2307.10635 , year=
Scibench: Evaluating college-level scientific problem-solving abilities of large language models , author=. arXiv preprint arXiv:2307.10635 , year=
-
[19]
AAAI , year=
Scieval: A multi-level large language model evaluation benchmark for scientific research , author=. AAAI , year=
-
[20]
NeurIPS , year=
What can large language models do in chemistry? a comprehensive benchmark on eight tasks , author=. NeurIPS , year=
-
[21]
arXiv preprint arXiv:2407.10362 , year=
Lab-bench: Measuring capabilities of language models for biology research , author=. arXiv preprint arXiv:2407.10362 , year=
-
[22]
1995 , publisher=
Supramolecular chemistry: concepts and perspectives , author=. 1995 , publisher=
1995
-
[23]
2022 , publisher=
Supramolecular chemistry , author=. 2022 , publisher=
2022
-
[24]
Chemical Society Reviews , year=
Molecular recognition: from solution science to nano/materials technology , author=. Chemical Society Reviews , year=
-
[25]
Angewandte Chemie International Edition , year=
A novel concept of reversing neuromuscular block: chemical encapsulation of rocuronium bromide by a cyclodextrin-based synthetic host , author=. Angewandte Chemie International Edition , year=
-
[26]
Chemical reviews , year=
Recent advances in supramolecular analytical chemistry using optical sensing , author=. Chemical reviews , year=
-
[27]
Chem , year=
Pillar [6] MaxQ: A potent supramolecular host for in vivo sequestration of methamphetamine and fentanyl , author=. Chem , year=
-
[28]
Chemical Society Reviews , volume=
Supramolecular hosts as in vivo sequestration agents for pharmaceuticals and toxins , author=. Chemical Society Reviews , volume=. 2020 , publisher=
2020
-
[29]
Journal of computer-aided molecular design , volume=
An overview of the SAMPL8 host--guest binding challenge , author=. Journal of computer-aided molecular design , volume=. 2022 , publisher=
2022
-
[30]
European Journal of Organic Chemistry , year=
Supramolecular chemistry: Exploring the use of electronic structure, molecular dynamics, and machine learning approaches , author=. European Journal of Organic Chemistry , year=
-
[31]
Journal of pharmacy and pharmacology , year=
Pharmaceutical applications of cyclodextrins: basic science and product development , author=. Journal of pharmacy and pharmacology , year=
-
[32]
Chemical Society Reviews , volume=
Drug delivery by supramolecular design , author=. Chemical Society Reviews , volume=. 2017 , publisher=
2017
-
[33]
Chemical Society Reviews , volume=
Practical applications of supramolecular chemistry , author=. Chemical Society Reviews , volume=. 2017 , publisher=
2017
-
[34]
British Journal of Anaesthesia , volume=
The effect of sugammadex on patient morbidity and quality of recovery after general anaesthesia: a systematic review and meta-analysis , author=. British Journal of Anaesthesia , volume=. 2024 , publisher=
2024
-
[35]
Chemical Society Reviews , volume=
Determining association constants from titration experiments in supramolecular chemistry , author=. Chemical Society Reviews , volume=. 2011 , publisher=
2011
-
[36]
Journal of computer-aided molecular design , volume=
Overview of the SAMPL5 host--guest challenge: Are we doing better? , author=. Journal of computer-aided molecular design , volume=. 2017 , publisher=
2017
-
[37]
Annual review of biophysics , volume=
Predicting binding free energies: frontiers and benchmarks , author=. Annual review of biophysics , volume=. 2017 , publisher=
2017
-
[38]
Annals of the New York Academy of Sciences , volume=
Computational modeling to assist in the discovery of supramolecular materials , author=. Annals of the New York Academy of Sciences , volume=. 2022 , publisher=
2022
-
[39]
Chemical Science , volume=
Virtual screening for high affinity guests for synthetic supramolecular receptors , author=. Chemical Science , volume=. 2015 , publisher=
2015
-
[40]
BioRxiv , year=
Boltz-2: Towards accurate and efficient binding affinity prediction , author=. BioRxiv , year=
-
[41]
bioRxiv , pages=
DrugLM: a unified framework to enhance drug-target interaction predictions by incorporating textual embeddings via language models , author=. bioRxiv , pages=. 2025 , publisher=
2025
-
[42]
Nature computational science , volume=
Electron density-based GPT for optimization and suggestion of host--guest binders , author=. Nature computational science , volume=. 2024 , publisher=
2024
-
[43]
bioRxiv , pages=
A foundation model for protein-ligand affinity prediction through jointly optimizing virtual screening and hit-to-lead optimization , author=. bioRxiv , pages=. 2025 , publisher=
2025
-
[44]
PeerJ , volume=
LANTERN: TCR-peptide binding prediction via large language model representations , author=. PeerJ , volume=. 2026 , publisher=
2026
-
[45]
BMC bioinformatics , volume=
Can large language models understand molecules? , author=. BMC bioinformatics , volume=. 2024 , publisher=
2024
-
[46]
International Journal of Biological Macromolecules , volume=
GPT4Kinase: high-accuracy prediction of inhibitor-kinase binding affinity utilizing large language model , author=. International Journal of Biological Macromolecules , volume=. 2024 , publisher=
2024
-
[47]
Nucleic acids research , volume=
Europe PMC: a full-text literature database for the life sciences and platform for innovation , author=. Nucleic acids research , volume=. 2015 , publisher=
2015
-
[48]
NeurIPS , year=
Chain-of-thought prompting elicits reasoning in large language models , author=. NeurIPS , year=
-
[49]
2026 , howpublished =
2026
-
[50]
NeurIPS , year=
EvoLM: In Search of Lost Language Model Training Dynamics , author=. NeurIPS , year=
-
[51]
doi:10.57967/hf/2497 , publisher =
Lozhkov, Anton and Ben Allal, Loubna and von Werra, Leandro and Wolf, Thomas , title =. doi:10.57967/hf/2497 , publisher =
-
[52]
2024 , email =
Tülu 3: Pushing Frontiers in Open Language Model Post-Training , author =. 2024 , email =
2024
-
[53]
Trends in cognitive sciences , volume=
Catastrophic forgetting in connectionist networks , author=. Trends in cognitive sciences , volume=. 1999 , publisher=
1999
-
[54]
arXiv preprint arXiv:2401.03129 , year=
Examining forgetting in continual pre-training of aligned large language models , author=. arXiv preprint arXiv:2401.03129 , year=
-
[55]
Biedermann, Frank and
-
[56]
2023 , publisher=
Atkins' physical chemistry , author=. 2023 , publisher=
2023
-
[57]
1884 , publisher=
Etudes de dynamique chimique , author=. 1884 , publisher=
-
[58]
1977 , publisher=
Exploratory data analysis , author=. 1977 , publisher=
1977
-
[59]
Journal of the American statistical Association , volume=
Fine-tuning some resistant rules for outlier labeling , author=. Journal of the American statistical Association , volume=. 1987 , publisher=
1987
-
[60]
SMILES, a chemical language and information system. 1. Introduction to methodology and encoding rules , author=. Journal of chemical information and computer sciences , volume=. 1988 , publisher=
1988
-
[61]
Journal of chemical information and modeling , volume=
GuacaMol: benchmarking models for de novo molecular design , author=. Journal of chemical information and modeling , volume=. 2019 , publisher=
2019
-
[62]
Frontiers in pharmacology , volume=
Molecular sets (MOSES): a benchmarking platform for molecular generation models , author=. Frontiers in pharmacology , volume=. 2020 , publisher=
2020
-
[63]
SMILES. 2. Algorithm for generation of unique SMILES notation , author=. Journal of chemical information and computer sciences , volume=. 1989 , publisher=
1989
-
[64]
Journal of chemical information and modeling , volume=
Get Your Atoms in Order: An Open-Source Implementation of a Novel and Robust Molecular Canonicalization Algorithm , author=. Journal of chemical information and modeling , volume=. 2015 , publisher=
2015
-
[65]
Journal of cheminformatics , volume=
InChI-the worldwide chemical structure identifier standard , author=. Journal of cheminformatics , volume=. 2013 , publisher=
2013
-
[66]
Journal of cheminformatics , volume=
InChI, the IUPAC international chemical identifier , author=. Journal of cheminformatics , volume=. 2015 , publisher=
2015
-
[67]
, author=
On a system of indexing chemical literature; adopted by the classification division of the US Patent Office. , author=. Journal of the American Chemical Society , volume=. 1900 , publisher=
1900
-
[68]
Journal of chemical information and modeling , volume=
Extended-connectivity fingerprints , author=. Journal of chemical information and modeling , volume=. 2010 , publisher=
2010
-
[69]
Journal of cheminformatics , volume=
Why is Tanimoto index an appropriate choice for fingerprint-based similarity calculations? , author=. Journal of cheminformatics , volume=. 2015 , publisher=
2015
-
[70]
, author=
The generation of a unique machine description for chemical structures-a technique developed at chemical abstracts service. , author=. Journal of chemical documentation , volume=. 1965 , publisher=
1965
-
[71]
RDKit: Open-Source Cheminformatics Software , url =
Landrum, Greg , biburl =. RDKit: Open-Source Cheminformatics Software , url =
-
[72]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Don’t stop pretraining: Adapt language models to domains and tasks , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[73]
arXiv preprint arXiv:2403.08763 , year=
Simple and scalable strategies to continually pre-train large language models , author=. arXiv preprint arXiv:2403.08763 , year=
-
[74]
arXiv preprint arXiv:2602.07075 , year=
Latentchem: From textual cot to latent thinking in chemical reasoning , author=. arXiv preprint arXiv:2602.07075 , year=
-
[75]
arXiv preprint arXiv:2601.22327 , year=
Molecular Representations in Implicit Functional Space via Hyper-Networks , author=. arXiv preprint arXiv:2601.22327 , year=
-
[76]
Proceedings of the ACM Web Conference 2026 , pages=
Controllable graph generation with diffusion models via inference-time tree search guidance , author=. Proceedings of the ACM Web Conference 2026 , pages=
2026
-
[77]
Advances in Neural Information Processing Systems , volume=
Generative graph pattern machine , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
International Conference on Machine Learning , pages=
Beyond Message Passing: Neural Graph Pattern Machine , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[79]
Advances in neural information processing systems , volume=
Gft: Graph foundation model with transferable tree vocabulary , author=. Advances in neural information processing systems , volume=
-
[80]
arXiv preprint arXiv:2509.19580 , year=
Llms4all: A review of large language models across academic disciplines , author=. arXiv preprint arXiv:2509.19580 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.