TrustErase: Auditable Instant Machine Unlearning with Passport-Embedded Representations
Pith reviewed 2026-06-27 03:22 UTC · model grok-4.3
The pith
TrustErase enables instant machine unlearning by deactivating embedded passports in model weights without retraining or data access.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
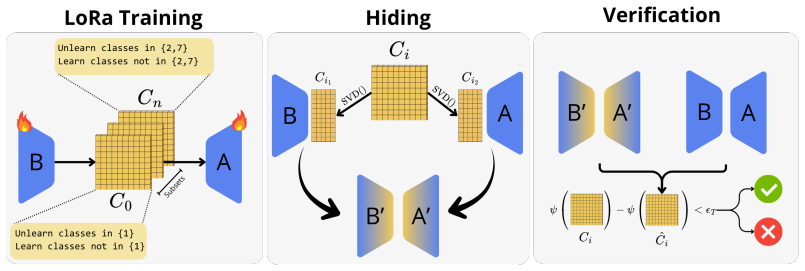
By treating passports as cryptographic keys within parameter-efficient adaptation layers and concealing them in model weights with singular value based decomposition, TrustErase allows removal of specific classes or datasets through simple deactivation without retraining, fine-tuning, or access to the original data, while keeping unlearning actions transparent and provably compliant.
What carries the argument
Passport-embedded representations treated as cryptographic keys in parameter-efficient adaptation layers, concealed via singular value based decomposition.
If this is right
- Unlearning actions become modular and can target specific classes or entire datasets independently.
- No access to original training data is needed, enabling unlearning in restricted data environments.
- Model utility is preserved at levels comparable to existing methods on image classification tasks.
- Transparency of the deactivation process supports auditability and regulatory compliance.
Where Pith is reading between the lines
- This method may allow unlearning in large-scale models where retraining is prohibitive.
- Similar passport techniques could be adapted for other forms of model control beyond forgetting.
- Integration with existing adaptation methods like adapters could broaden applicability.
Load-bearing premise
A singular value based decomposition can conceal passports within model weights such that deactivation achieves verifiable unlearning while preserving model utility and transparency.
What would settle it
If deactivating the passports fails to reduce accuracy on the target classes to near-random levels while keeping overall performance intact, the unlearning claim would not hold.
Figures


read the original abstract
The demand for privacy-compliant AI has amplified the need for machine unlearning; yet, existing retraining or distillation-based methods remain unverifiable and computationally costly. We introduce TrustErase, a verifiable, data-free unlearning framework leveraging passport-embedded representations for instant, modular, and auditable forgetting. By treating passports as cryptographic keys within parameter-efficient adaptation layers, TrustErase enables the removal of specific classes or datasets through simple deactivation, without retraining, fine-tuning, or access to the original data. A singular value based decomposition conceals passports within model weights, ensuring that unlearning actions remain transparent and provably compliant. Evaluations on MNIST, CIFAR10 and CIFAR100 show that TrustErase matches or exceeds state-of-the-art benchmarks such as DELETE, L2UL, and Boundary Shrink, while operating in a strictly data-free regime. Ultimately, TrustErase establishes a new paradigm for trustworthy, accountable, and instantly forgettable AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TrustErase, a data-free machine unlearning framework that embeds 'passports' as cryptographic keys inside parameter-efficient adaptation layers via singular-value decomposition; deactivation of the passports is claimed to instantly remove the influence of specific classes or datasets while preserving utility, enabling auditability, and matching the performance of DELETE, L2UL, and Boundary Shrink on MNIST, CIFAR-10, and CIFAR-100.
Significance. If the SVD-based embedding were shown to isolate class-specific effects orthogonally and if deactivation were proven to constitute verifiable unlearning, the approach would offer a genuinely new, low-cost paradigm for auditable forgetting that avoids retraining or data access. The modular passport mechanism itself is a conceptually attractive idea that could be extended beyond the current setting.
major comments (2)
- [Technical Approach (no equation or lemma supplied)] The central technical claim—that an SVD-based concealment of passports inside model weights allows deactivation to nullify exactly the forgotten information while leaving task-relevant directions intact—receives no derivation or orthogonality argument anywhere in the manuscript. Without such an argument the equivalence between deactivation and unlearning remains an unproven assumption.
- [Abstract / Evaluation section] The abstract asserts that TrustErase 'matches or exceeds' DELETE, L2UL, and Boundary Shrink on MNIST/CIFAR-10/CIFAR-100, yet supplies neither quantitative metrics, error bars, verification procedure, nor dataset-split details. This absence makes the performance claim impossible to evaluate and directly undermines the empirical support for the method.
minor comments (1)
- [Method description] Notation for the passport embedding and the precise definition of the adaptation layer are introduced without a clear mathematical formulation or pseudocode, making the method difficult to reproduce from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and will revise the paper to strengthen both the technical justification and the presentation of empirical results.
read point-by-point responses
-
Referee: [Technical Approach (no equation or lemma supplied)] The central technical claim—that an SVD-based concealment of passports inside model weights allows deactivation to nullify exactly the forgotten information while leaving task-relevant directions intact—receives no derivation or orthogonality argument anywhere in the manuscript. Without such an argument the equivalence between deactivation and unlearning remains an unproven assumption.
Authors: We acknowledge that the manuscript presents the SVD-based passport embedding at a conceptual level without supplying a formal derivation or orthogonality argument. In the revised version we will add a dedicated technical subsection that derives the embedding procedure, shows that the singular vectors associated with the passports lie in directions orthogonal to the principal task-relevant components (via the properties of SVD), and provides lemmas establishing that deactivation removes exactly the class-specific influence while leaving utility intact. This will make the equivalence between deactivation and unlearning explicit rather than assumed. revision: yes
-
Referee: [Abstract / Evaluation section] The abstract asserts that TrustErase 'matches or exceeds' DELETE, L2UL, and Boundary Shrink on MNIST/CIFAR-10/CIFAR-100, yet supplies neither quantitative metrics, error bars, verification procedure, nor dataset-split details. This absence makes the performance claim impossible to evaluate and directly undermines the empirical support for the method.
Authors: The referee is correct that the abstract states the performance claim without accompanying quantitative details. Although the experiments section of the manuscript reports the full comparisons (including accuracy, forgetting metrics, and standard deviations across the three datasets), the abstract itself does not. We will revise the abstract to include representative numerical results with error bars and will ensure the evaluation section explicitly states the verification procedure and dataset splits used. revision: yes
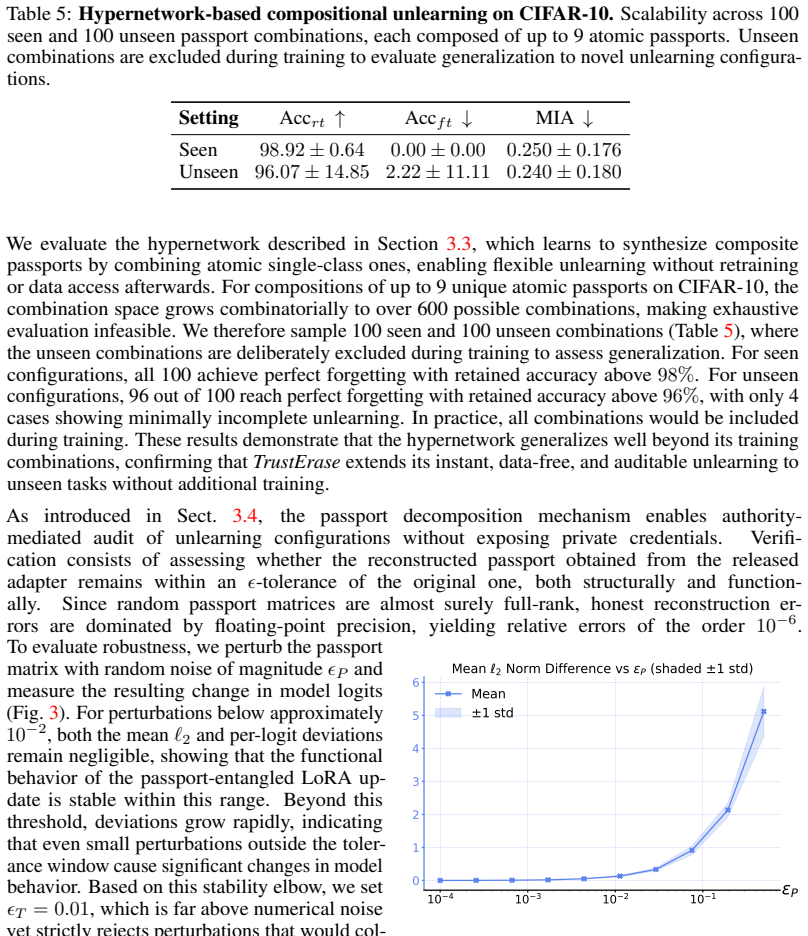
Circularity Check
No circularity detected; derivation chain absent from text
full rationale
The abstract and full-text placeholder supply no equations, parameter-fitting steps, self-citations, or uniqueness theorems. The SVD concealment of passports is asserted as enabling verifiable deactivation, yet no derivation, ansatz, or reduction to prior inputs is exhibited that could be inspected for self-definition or fitted-input prediction. Without any load-bearing mathematical chain, the paper remains self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
invented entities (1)
-
passport-embedded representations
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Regulation (eu) 2016/679 of the european parliament and of the council of 27 april 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing directive 95/46/ec (general data protection regulation) (text with eea relevance), May 2016
2016
-
[2]
The economics of personal data and the economics of privacy
Alessandro Acquisti et al. The economics of personal data and the economics of privacy. Background Paper for OECD Joint WPISP-WPIE Roundtable, 1:50, 2010
2010
-
[3]
Artificial intelligence risk management framework (ai rmf 1.0).URL: https://nvlpubs
NIST AI. Artificial intelligence risk management framework (ai rmf 1.0).URL: https://nvlpubs. nist. gov/nistpubs/ai/nist. ai, pages 100–1, 2023
2023
-
[4]
Machine unlearning: Linear filtration for logit-based classifiers.Machine Learning, 111(9):3203–3226, 2022
Thomas Baumhauer, Pascal Schöttle, and Matthias Zeppelzauer. Machine unlearning: Linear filtration for logit-based classifiers.Machine Learning, 111(9):3203–3226, 2022
2022
-
[5]
Machine unlearning
Lucas Bourtoule, Varun Chandrasekaran, Christopher A Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine unlearning. In2021 IEEE symposium on security and privacy (SP), pages 141–159. IEEE, 2021
2021
-
[6]
Towards making systems forget with machine unlearning
Yinzhi Cao and Junfeng Yang. Towards making systems forget with machine unlearning. In 2015 IEEE symposium on security and privacy, pages 463–480. IEEE, 2015. 10
2015
-
[7]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Kather- ine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21), pages 2633–2650, 2021
2021
-
[8]
Learning to unlearn: Instance-wise unlearning for pre-trained classifiers
Sungmin Cha, Sungjun Cho, Dasol Hwang, Honglak Lee, Taesup Moon, and Moontae Lee. Learning to unlearn: Instance-wise unlearning for pre-trained classifiers. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 11186–11194, 2024
2024
-
[9]
Boundary unlearning: Rapid forgetting of deep networks via shifting the decision boundary
Min Chen, Weizhuo Gao, Gaoyang Liu, Kai Peng, and Chen Wang. Boundary unlearning: Rapid forgetting of deep networks via shifting the decision boundary. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7766–7775, 2023
2023
-
[10]
Can bad teaching induce forgetting? unlearning in deep networks using an incompetent teacher
Vikram S Chundawat, Ayush K Tarun, Murari Mandal, and Mohan Kankanhalli. Can bad teaching induce forgetting? unlearning in deep networks using an incompetent teacher. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 7210–7217, 2023
2023
-
[11]
Excavating ai: The politics of images in machine learning training sets.Ai & Society, 36(4):1105–1116, 2021
Kate Crawford and Trevor Paglen. Excavating ai: The politics of images in machine learning training sets.Ai & Society, 36(4):1105–1116, 2021
2021
-
[12]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, and Sijia Liu. Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation.arXiv preprint arXiv:2310.12508, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Rethinking deep neural network ownership verification: Embedding passports to defeat ambiguity attacks.Advances in neural information processing systems, 32, 2019
Lixin Fan, Kam Woh Ng, and Chee Seng Chan. Rethinking deep neural network ownership verification: Embedding passports to defeat ambiguity attacks.Advances in neural information processing systems, 32, 2019
2019
-
[15]
Fast machine unlearning without retraining through selective synaptic dampening
Jack Foster, Stefan Schoepf, and Alexandra Brintrup. Fast machine unlearning without retraining through selective synaptic dampening. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 12043–12051, 2024
2024
-
[16]
Erasing concepts from diffusion models
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau. Erasing concepts from diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 2426–2436, 2023
2023
-
[17]
Stochastic first-and zeroth-order methods for nonconvex stochastic programming.SIAM journal on optimization, 23(4):2341–2368, 2013
Saeed Ghadimi and Guanghui Lan. Stochastic first-and zeroth-order methods for nonconvex stochastic programming.SIAM journal on optimization, 23(4):2341–2368, 2013
2013
-
[18]
Making ai forget you: Data deletion in machine learning.Advances in neural information processing systems, 32, 2019
Antonio Ginart, Melody Guan, Gregory Valiant, and James Y Zou. Making ai forget you: Data deletion in machine learning.Advances in neural information processing systems, 32, 2019
2019
-
[19]
Forgetting outside the box: Scrub- bing deep networks of information accessible from input-output observations
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Forgetting outside the box: Scrub- bing deep networks of information accessible from input-output observations. InEuropean Conference on Computer Vision, pages 383–398. Springer, 2020
2020
-
[20]
Amnesiac machine learning
Laura Graves, Vineel Nagisetty, and Vijay Ganesh. Amnesiac machine learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 11516–11524, 2021
2021
-
[21]
Certified data removal from machine learning models.arXiv preprint arXiv:1911.03030, 2019
Chuan Guo, Tom Goldstein, Awni Hannun, and Laurens Van Der Maaten. Certified data removal from machine learning models.arXiv preprint arXiv:1911.03030, 2019
-
[22]
Dai, and Quoc V
David Ha, Andrew M. Dai, and Quoc V . Le. Hypernetworks. InInternational Conference on Learning Representations, 2017. URLhttps://openreview.net/forum?id=rkpACe1lx
2017
-
[23]
Rutger Hendrix, Giovanni Patanè, Leonardo G. Russo, Simone Carnemolla, Federica Proi- etto Salanitri, Giovanni Bellitto, Concetto Spampinato, and Matteo Pennisi. Pre-forgettable models: Prompt learning as a native mechanism for unlearning. InACM International Confer- ence on Multimedia (ACM MM), Dublin, Ireland, 2025. doi: 10.1145/3746027.3758171. 11
-
[24]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. In arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
Lora: Low-rank adaptation of large language models.ICLR, 1 (2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1 (2):3, 2022
2022
-
[26]
Editing Models with Task Arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic.arXiv preprint arXiv:2212.04089, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Conflict-averse gradient descent for multi-task learning.Advances in neural information processing systems, 34:18878–18890, 2021
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. Conflict-averse gradient descent for multi-task learning.Advances in neural information processing systems, 34:18878–18890, 2021
2021
-
[28]
Parameter-efficient multi-task fine-tuning for transformers via shared hypernetworks
Rabeeh Karimi Mahabadi, Sebastian Ruder, Mostafa Dehghani, and James Henderson. Parameter-efficient multi-task fine-tuning for transformers via shared hypernetworks. InPro- ceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers),...
2021
-
[29]
Certifiable machine unlearning for linear models.arXiv preprint arXiv:2106.15093, 2021
Ananth Mahadevan and Michael Mathioudakis. Certifiable machine unlearning for linear models.arXiv preprint arXiv:2106.15093, 2021
-
[30]
Descent-to-delete: Gradient-based methods for machine unlearning
Seth Neel, Aaron Roth, and Saeed Sharifi-Malvajerdi. Descent-to-delete: Gradient-based methods for machine unlearning. InAlgorithmic Learning Theory, pages 931–962. PMLR, 2021
2021
-
[31]
A survey of machine unlearning.ACM Transactions on Intelligent Systems and Technology, 16(5):1–46, 2025
Thanh Tam Nguyen, Thanh Trung Huynh, Zhao Ren, Phi Le Nguyen, Alan Wee-Chung Liew, Hongzhi Yin, and Quoc Viet Hung Nguyen. A survey of machine unlearning.ACM Transactions on Intelligent Systems and Technology, 16(5):1–46, 2025
2025
-
[32]
Seal: Entangled white-box watermarks on low-rank adaptation.arXiv preprint arXiv:2501.09284, 2025
Giyeong Oh, Saejin Kim, Woohyun Cho, Sangkyu Lee, Jiwan Chung, Dokyung Song, and Youngjae Yu. Seal: Entangled white-box watermarks on low-rank adaptation.arXiv preprint arXiv:2501.09284, 2025
-
[33]
Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models
Patrick Schramowski, Manuel Brack, Björn Deiseroth, and Kristian Kersting. Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22522–22531, 2023
2023
-
[34]
Laion- 5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion- 5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
2022
-
[35]
Multi-task learning as multi-objective optimization.Advances in neural information processing systems, 31, 2018
Ozan Sener and Vladlen Koltun. Multi-task learning as multi-objective optimization.Advances in neural information processing systems, 31, 2018
2018
-
[36]
Glaze: Protecting artists from style mimicry by {Text-to-Image} models
Shawn Shan, Jenna Cryan, Emily Wenger, Haitao Zheng, Rana Hanocka, and Ben Y Zhao. Glaze: Protecting artists from style mimicry by {Text-to-Image} models. In32nd USENIX Security Symposium (USENIX Security 23), pages 2187–2204, 2023
2023
-
[37]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017
2017
-
[38]
Fast yet effective machine unlearning.IEEE transactions on neural networks and learning systems, 35 (9):13046–13055, 2023
Ayush K Tarun, Vikram S Chundawat, Murari Mandal, and Mohan Kankanhalli. Fast yet effective machine unlearning.IEEE transactions on neural networks and learning systems, 35 (9):13046–13055, 2023
2023
-
[39]
Unrolling sgd: Understanding factors influencing machine unlearning
Anvith Thudi, Gabriel Deza, Varun Chandrasekaran, and Nicolas Papernot. Unrolling sgd: Understanding factors influencing machine unlearning. In2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P), pages 303–319. IEEE, 2022. 12
2022
-
[40]
Deltagrad: Rapid retraining of machine learning models
Yinjun Wu, Edgar Dobriban, and Susan Davidson. Deltagrad: Rapid retraining of machine learning models. InInternational Conference on Machine Learning, pages 10355–10366. PMLR, 2020
2020
-
[41]
Ties-merging: Resolving interference when merging models.Advances in neural information processing systems, 36:7093–7115, 2023
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. Ties-merging: Resolving interference when merging models.Advances in neural information processing systems, 36:7093–7115, 2023
2023
-
[42]
Gradient surgery for multi-task learning.Advances in neural information processing systems, 33:5824–5836, 2020
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning.Advances in neural information processing systems, 33:5824–5836, 2020
2020
-
[43]
Decoupled distillation to erase: A general unlearning method for any class-centric tasks
Yu Zhou, Dian Zheng, Qijie Mo, Renjie Lu, Kun-Yu Lin, and Wei-Shi Zheng. Decoupled distillation to erase: A general unlearning method for any class-centric tasks. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 20350–20359, 2025. 13 Appendix for TrustErase A Experimental Setup A.1 Training details and configurations Architec...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.