Human-in-the-Loop Atlas-Based 3D Asset Segmentation for Interactive Content Workflows
Pith reviewed 2026-06-27 01:53 UTC · model grok-4.3
The pith
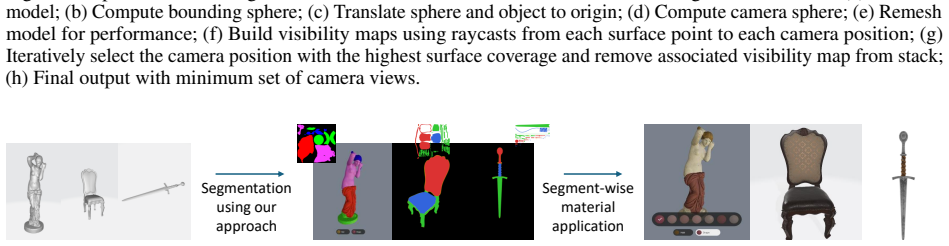
A pipeline selects a few 2D views of a 3D model, lets users segment them interactively, and back-projects the masks to a single UV atlas for downstream editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The method generates segmented 2D parameterized atlases from 3D models by first choosing a compact set of rendered views via greedy set cover on sampled surface points, then performing interactive segmentation on those views using SAM 2 and Label Studio, and finally back-projecting the masks onto the UV parameterization to yield a unified atlas suitable for tasks like material assignment and style transfer. Testing on eight cultural heritage objects confirms that usable atlases result for diverse geometries, with recurring needs for correction on fine structures, cavities, and weak appearance boundaries.
What carries the argument
Greedy set-cover view selection followed by back-projection of 2D masks onto the 3D model's UV parameterization.
If this is right
- Material assignment and style transfer can be performed region by region directly on the atlas.
- Semantic labels produced on the atlas transfer to the 3D model for use in game or XR pipelines.
- The same view-selection and projection steps can be reused for any 3D model that has a UV parameterization.
- Recurring correction patterns on fine structures and cavities indicate where further automation would reduce user effort most.
Where Pith is reading between the lines
- The method could shorten production time for non-heritage assets such as game props if the same view-coverage logic holds.
- If surface sampling misses thin protrusions, the greedy view set may leave gaps that require extra manual masks beyond what the paper reports.
- Combining the atlas output with real-time engines might allow artists to see live updates when they adjust a 2D mask.
Load-bearing premise
Back-projecting the 2D masks onto the UV layout transfers the segmentation without major distortion, overlaps, or loss of detail from the chosen views.
What would settle it
Compare the final atlas against a manually painted ground-truth segmentation on the 3D surface for a model with cavities or thin features and measure the fraction of surface area that mismatches after projection.
Figures




read the original abstract
Segmenting 3D assets into meaningful regions remains challenging, especially when segmentation criteria are application-dependent and require user control. We present a human-in-the-loop pipeline for generating a segmented 2D parameterized atlas from a 3D model for interactive media, game, and XR content workflows. Our method first selects a compact set of rendered views using a greedy set cover strategy over sampled surface points, and then supports interactive segmentation of these views with SAM~2 and Label Studio. The resulting masks are back-projected onto the model's UV parameterization to produce a unified segmented atlas that supports downstream production tasks such as segment-wise material assignment, style transfer, and semantic labeling. We assess the pipeline through a demonstration-based technical evaluation on eight cultural heritage objects. The results show that the approach can generate usable segmented atlases across diverse geometries while revealing recurring sources of manual correction, particularly fine structures, cavities, and weak appearance boundaries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a human-in-the-loop pipeline for atlas-based segmentation of 3D assets. It selects a compact set of rendered views via greedy set cover over surface points, performs interactive 2D segmentation using SAM 2 in Label Studio, and back-projects the resulting masks onto the model's UV parameterization to produce a unified segmented atlas suitable for material assignment, style transfer, and semantic labeling. Feasibility is assessed via a qualitative demonstration on eight cultural heritage objects, which identifies recurring manual correction needs for fine structures, cavities, and weak appearance boundaries.
Significance. If the back-projection step preserves segmentation fidelity without significant distortion or conflicts, the pipeline could offer a practical, controllable workflow for interactive 3D content creation in games, media, and XR. The explicit identification of common failure modes (cavities, thin structures) provides actionable guidance for refinement. The absence of quantitative validation, however, limits the strength of claims about usability and generalizability across geometries.
major comments (2)
- [Evaluation] Evaluation section: The demonstration on eight objects reports no quantitative metrics for the back-projection step itself (e.g., no IoU, boundary F-score, per-texel consistency across overlapping views, or error rates under occlusion and depth-buffer artifacts). This directly weakens the central claim that the method yields 'usable' atlases after minimal manual fixes, as the skeptic correctly identifies this as the least-secured link in the pipeline.
- [Method] Pipeline description (back-projection paragraph): The method implies standard rasterization or ray-casting onto the existing UV map, yet provides no details on conflict resolution for overlapping views, handling of cavities/thin structures, or view-selection gaps. Without these, the claim that the atlas supports downstream production tasks remains unverified for the geometries highlighted as problematic.
minor comments (2)
- The coverage threshold parameter in the greedy set cover is mentioned but not specified (value, sensitivity, or per-model tuning), which affects reproducibility of the view selection.
- [Abstract] Abstract uses 'SAM~2'; standardize notation to 'SAM 2' throughout for consistency.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below, clarifying the scope of our demonstration-based evaluation while committing to targeted revisions that strengthen the manuscript without altering its core positioning as a practical workflow description.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The demonstration on eight objects reports no quantitative metrics for the back-projection step itself (e.g., no IoU, boundary F-score, per-texel consistency across overlapping views, or error rates under occlusion and depth-buffer artifacts). This directly weakens the central claim that the method yields 'usable' atlases after minimal manual fixes, as the skeptic correctly identifies this as the least-secured link in the pipeline.
Authors: We appreciate this observation. Our evaluation is deliberately qualitative and demonstration-based, centered on end-to-end usability for diverse cultural heritage geometries and the explicit identification of recurring correction needs (fine structures, cavities, weak boundaries). Quantitative metrics such as IoU or boundary F-score presuppose application-independent ground truth, which does not exist for these objects. In revision we will add a dedicated paragraph in the Evaluation section that (a) acknowledges this limitation, (b) reports view-consistency statistics (per-texel label agreement across overlapping projections) on the existing data, and (c) outlines how future users could compute task-specific metrics once ground truth is defined. This provides additional transparency without overstating the current evidence. revision: partial
-
Referee: [Method] Pipeline description (back-projection paragraph): The method implies standard rasterization or ray-casting onto the existing UV map, yet provides no details on conflict resolution for overlapping views, handling of cavities/thin structures, or view-selection gaps. Without these, the claim that the atlas supports downstream production tasks remains unverified for the geometries highlighted as problematic.
Authors: We agree that the back-projection description is underspecified. The revised manuscript will expand the relevant paragraph to state: (1) conflict resolution uses a priority-weighted majority vote based on view normal alignment and coverage; (2) cavities and thin structures are automatically flagged when depth discontinuities exceed a threshold and are routed to the interactive correction stage, consistent with the failure modes already reported; (3) residual view-selection gaps are mitigated by permitting the user to request additional views within Label Studio. These clarifications will directly address how the pipeline remains viable for the geometries discussed. revision: yes
Circularity Check
No circularity: procedural pipeline with no derivations or fitted predictions
full rationale
The paper presents a human-in-the-loop pipeline consisting of greedy view selection, SAM2-based interactive segmentation of 2D renders, and back-projection of masks onto an existing UV parameterization. No equations, parameters, or predictive claims are present that could reduce outputs to inputs by construction. The evaluation is purely demonstrative on eight meshes and identifies practical correction sources without any self-referential fitting or uniqueness theorems. No self-citations appear in the provided text as load-bearing elements. This matches the default case of a self-contained methods description.
Axiom & Free-Parameter Ledger
free parameters (1)
- coverage threshold in greedy set cover
axioms (1)
- domain assumption The 3D model has a valid UV parameterization suitable for back-projection
Reference graph
Works this paper leans on
-
[1]
Deep learning based 3d segmentation in computer vision: A survey.Information Fusion, 115:102722, 2025
Yong He, Hongshan Yu, Xiaoyan Liu, Zhengeng Yang, Wei Sun, Saeed Anwar, and Ajmal Mian. Deep learning based 3d segmentation in computer vision: A survey.Information Fusion, 115:102722, 2025
2025
-
[2]
Kim, Wilmot Li, Niloy J
Vladimir G. Kim, Wilmot Li, Niloy J. Mitra, Siddhartha Chaudhuri, Stephen DiVerdi, and Thomas Funkhouser. Learning part-based templates from large collections of 3d shapes.ACM Trans. Graph., 2013
2013
-
[3]
Creating large-scale city models from 3d-point clouds: A robust approach with hybrid representation.International Journal of Computer Vision, 2012
Florent Lafarge and Clément Mallet. Creating large-scale city models from 3d-point clouds: A robust approach with hybrid representation.International Journal of Computer Vision, 2012
2012
-
[4]
SuperDec: 3D Scene Decomposition with Superquadric Primitives
Elisabetta Fedele, Boyang Sun, Leonidas Guibas, Marc Pollefeys, and Francis Engelmann. SuperDec: 3D Scene Decomposition with Superquadric Primitives. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[5]
Sampart3d: Segment any part in 3d objects.arXiv preprint arXiv:2411.07184, 2024
Yunhan Yang, Yukun Huang, Yuan-Chen Guo, Liangjun Lu, Xiaoyang Wu, Lam Edmund Y ., Yan-Pei Cao, and Xihui Liu. Sampart3d: Segment any part in 3d objects.arXiv preprint arXiv:2411.07184, 2024
-
[6]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Label Studio: Data labeling software, 2020-2025
Maxim Tkachenko, Mikhail Malyuk, Andrey Holmanyuk, and Nikolai Liubimov. Label Studio: Data labeling software, 2020-2025. Open source software available from https://github.com/HumanSignal/label-studio
2020
-
[8]
Hierarchical mesh decomposition using fuzzy clustering and cuts.ACM Trans
Sagi Katz and Ayellet Tal. Hierarchical mesh decomposition using fuzzy clustering and cuts.ACM Trans. Graph., 2003
2003
-
[9]
A new cad mesh segmentation method, based on curvature tensor analysis.Computer-Aided Design, 2005
Guillaume Lavoué, Florent Dupont, and Atilla Baskurt. A new cad mesh segmentation method, based on curvature tensor analysis.Computer-Aided Design, 2005
2005
-
[10]
Consistent mesh partitioning and skeletonisation using the shape diameter function.The Visual Computer, 2008
Lior Shapira, Ariel Shamir, and Daniel Cohen-Or. Consistent mesh partitioning and skeletonisation using the shape diameter function.The Visual Computer, 2008
2008
-
[11]
Segmentation of 3d meshes through spectral clustering
Rong Liu and Hao Zhang. Segmentation of 3d meshes through spectral clustering. In12th Pacific Conference on Computer Graphics and Applications, 2004. PG 2004. Proceedings., 2004
2004
-
[12]
Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu
Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. Shapenet: An information-rich 3d model repository, 2015
2015
-
[13]
Efficient RANSAC for point-cloud shape detection.Comput
Ruwen Schnabel, Roland Wahl, and Reinhard Klein. Efficient RANSAC for point-cloud shape detection.Comput. Graph. Forum, 2007
2007
-
[14]
Segmentation of point clouds using smoothness constraint
T Rabbani Shah, FA van den Heuvel, and MG V osselman. Segmentation of point clouds using smoothness constraint. In H-G Maas and D Schneider, editors,Proceedings of the ISPRS Com. V Symposium, pages 248–253. Dresden University of Technology, 2006
2006
-
[15]
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation.arXiv preprint arXiv:1612.00593, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[16]
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
Charles R Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.arXiv preprint arXiv:1706.02413, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Sarma, Michael M
Yue Wang, Yongbin Sun, Ziwei Liu, Sanjay E. Sarma, Michael M. Bronstein, and Justin M. Solomon. Dynamic graph cnn for learning on point clouds.ACM Trans. Graph., 2019
2019
-
[18]
Segment anything in 3d with nerfs
Jiazhong Cen, Zanwei Zhou, Jiemin Fang, Chen Yang, Wei Shen, Lingxi Xie, Dongsheng Jiang, Xiaopeng Zhang, and Qi Tian. Segment anything in 3d with nerfs. InProceedings of the 37th International Conference on Neural Information Processing Systems, 2023. 8 APREPRINT- JUNE17, 2026
2023
-
[19]
Partslip: Low-shot part segmentation for 3d point clouds via pretrained image-language models
Minghua Liu, Yinhao Zhu, Hong Cai, Shizhong Han, Zhan Ling, Fatih Porikli, and Hao Su. Partslip: Low-shot part segmentation for 3d point clouds via pretrained image-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[20]
Grounded language-image pre- training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. Grounded language-image pre- training. InCVPR, 2022
2022
-
[21]
Semantic Stylization and Shading via Segmentation Atlas utilizing Deep Learning Approaches
Saptarshi Neil Sinha, Paul Julius Kühn, Pavel Rojtberg, Holger Graf, Arjan Kuijper, and Michael Weinmann. Semantic Stylization and Shading via Segmentation Atlas utilizing Deep Learning Approaches. InSmart Tools and Applications in Graphics - Eurographics Italian Chapter Conference. The Eurographics Association, 2024
2024
-
[22]
Tracking anything with decoupled video segmentation
Ho Kei Cheng, Seoung Wug Oh, Brian Price, Alexander Schwing, and Joon-Young Lee. Tracking anything with decoupled video segmentation. InICCV, 2023
2023
-
[23]
Strobl, Matthias Humt, and Rudolph Triebel
Maximilian Denninger, Dominik Winkelbauer, Martin Sundermeyer, Wout Boerdijk, Markus Knauer, Klaus H. Strobl, Matthias Humt, and Rudolph Triebel. Blenderproc2: A procedural pipeline for photorealistic rendering. Journal of Open Source Software, 8(82):4901, 2023
2023
-
[24]
A design science research methodology for information systems research.Journal of management information systems, 24(3):45–77, 2007
Ken Peffers, Tuure Tuunanen, Marcus A Rothenberger, and Samir Chatterjee. A design science research methodology for information systems research.Journal of management information systems, 24(3):45–77, 2007
2007
-
[25]
Feds: a framework for evaluation in design science research.European journal of information systems, 25(1):77–89, 2016
John Venable, Jan Pries-Heje, and Richard Baskerville. Feds: a framework for evaluation in design science research.European journal of information systems, 25(1):77–89, 2016. 9
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.