TW-LegalBench: Measuring Taiwanese Legal Understanding
Pith reviewed 2026-06-26 20:57 UTC · model grok-4.3
The pith
Top LLMs exceed the passing threshold for Taiwanese lawyers on official exams but struggle to cite exact legal articles in judgments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
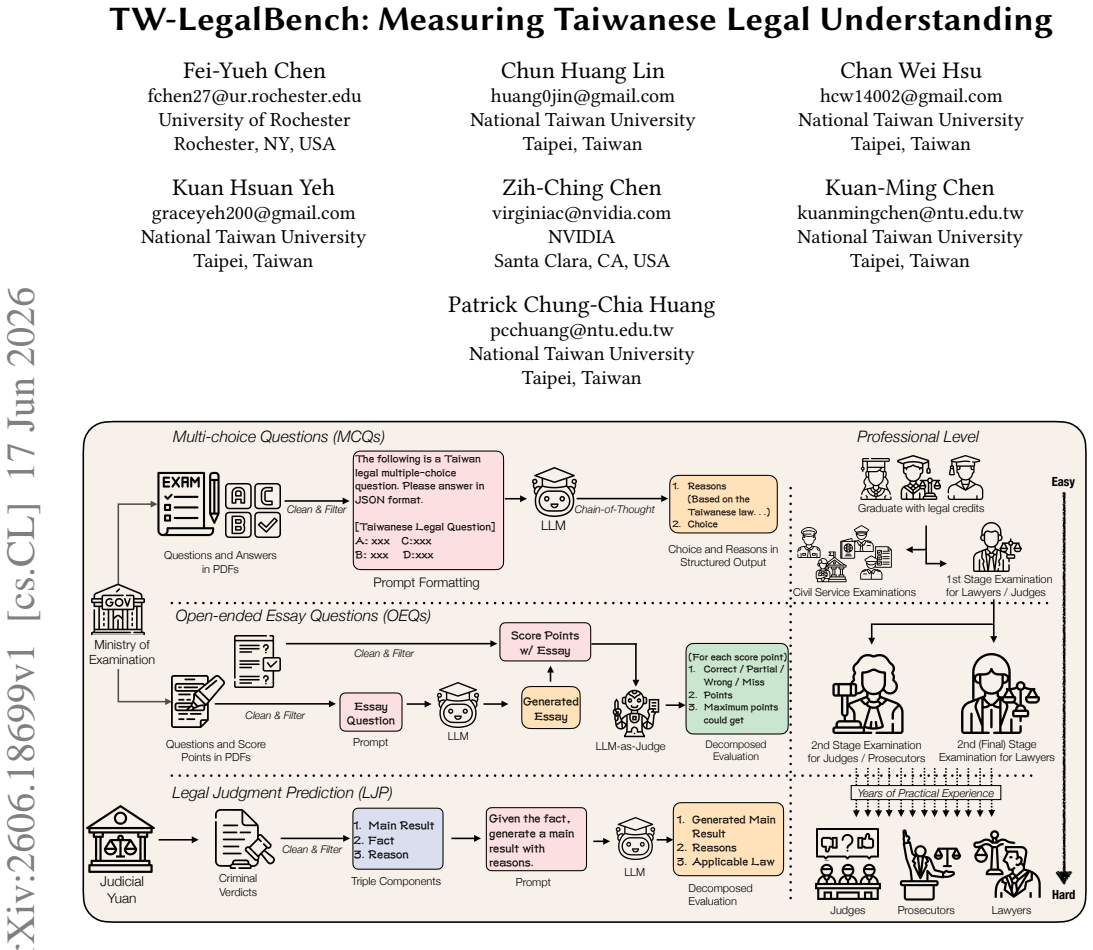
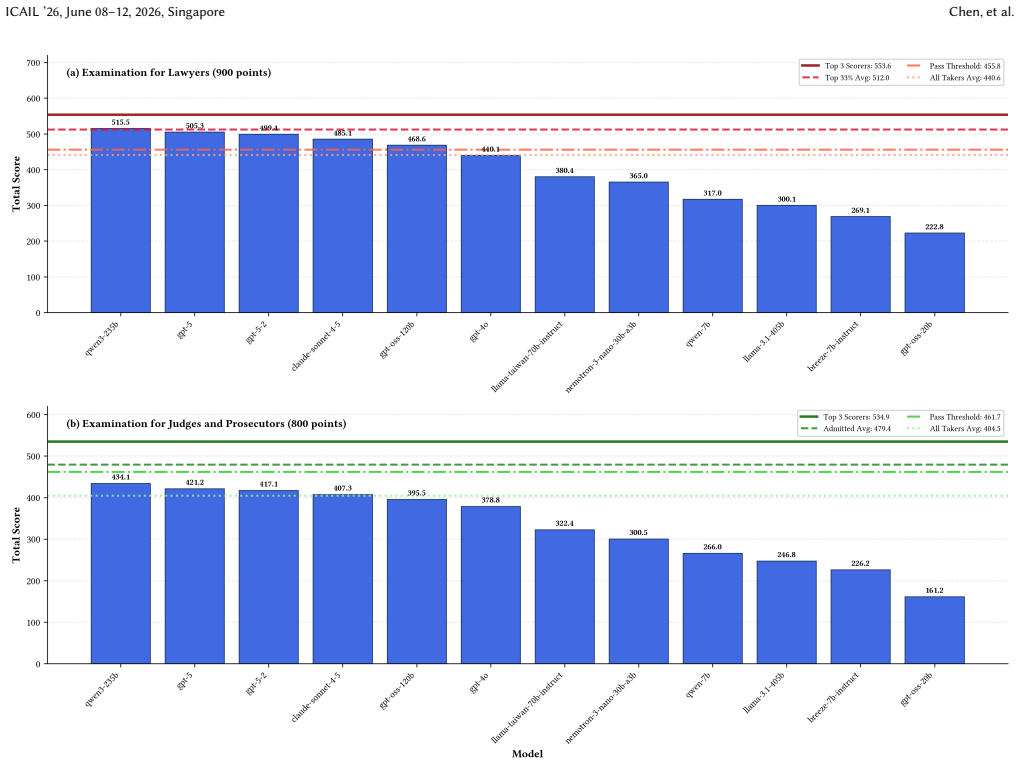
TW-LegalBench comprises over 16,000 multiple-choice questions from five years of examinations across 18 domains, 117 open-ended essay questions scored against official rubrics, and more than 14,000 legal judgment prediction instances spanning hundreds of crime categories. Evaluation of 13 LLMs shows top models surpass the 11 percent passing rate for lawyers but remain below the 1-2 percent rates for judges and prosecutors; verdict-type accuracy and sentence prediction are reasonable while exact legal-article citation remains weak.
What carries the argument
TW-LegalBench benchmark of MCQs, rubric-scored OEQs, and LJP instances from Taiwan's public legal corpus, measured by accuracy, decomposed LLM-as-Judge scores, and statute-citation metrics.
If this is right
- LLMs can reach lawyer-level performance on jurisdiction-specific qualification exams.
- Exact statute citation in judgment tasks requires targeted improvement beyond current capabilities.
- Reliable legal text generation stays difficult even when exam scores approach human thresholds.
- The benchmark supplies a public yardstick for tracking progress on civil-law legal reasoning.
- Rubric-based LLM judging offers a way to score open-ended legal responses at scale.
Where Pith is reading between the lines
- Other civil-law jurisdictions could construct comparable benchmarks from their own public examination and judgment records.
- Models that succeed on exams may still need retrieval augmentation to handle precise citation demands.
- The gap between multiple-choice success and open-ended citation accuracy points to distinct sub-skills in legal AI.
- Such benchmarks could guide the design of tools that support legal education without claiming full professional competence.
Load-bearing premise
The tasks taken from official examinations and judgments sufficiently represent the legal understanding required in actual practice.
What would settle it
A follow-up study in which practicing Taiwanese lawyers rate the benchmark items as unrepresentative of daily work, or in which new models achieve both high exam scores and accurate statute citation on the LJP set.
Figures

read the original abstract
Large language models (LLMs) have shown impressive capabilities across diverse tasks, yet their performance on jurisdiction-specific legal reasoning remains underexplored. We present TW-LegalBench that utilizes Taiwanese legal system's rich official corpus open to the public to fill the gap in evaluating LLMs on Taiwanese law, among common-law benchmarks that focus on English sources and civil-law benchmarks focusing on sources of Simplified Chinese. TW-LegalBench comprises three task types: (1) over 16,000 multiple-choice questions (MCQs) across five years of official examinations in 18 professional domains; (2) 117 open-ended essay questions (OEQs) from examinations for legal professionals with official scoring rubrics; and (3) more than 14,000 legal judgment prediction (LJP) instances covering hundreds of crime categories. We evaluate 13 LLMs using accuracy for MCQs, a decomposed LLM-as-Judge framework based on the scoring rubric points for OEQs, and metrics for sentencing accuracy and statute citation for LJP. Our results reveal that top-performing models exceed the passing threshold for qualified lawyers (passing rate: 11%) but fall short of that for judges and prosecutors (passing rate: 1~2%). For LJP, while models demonstrate reasonable verdict type accuracy and sentence prediction capability, they struggle to cite exact legal articles. These findings highlight that reliable legal text generation remains challenging for LLMs, even though their performance on qualification examinations approaches human level.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TW-LegalBench, a benchmark for LLMs on Taiwanese law drawn from public official sources. It includes >16k MCQs from five years of exams across 18 domains, 117 OEQs with official rubrics, and >14k LJP instances across hundreds of crime categories. Thirteen LLMs are evaluated via accuracy (MCQs), a decomposed LLM-as-Judge rubric scorer (OEQs), and verdict/sentence/citation metrics (LJP). The central claims are that top models exceed the 11% lawyer qualification passing rate but fall short of the 1-2% rates for judges/prosecutors, while LJP shows reasonable verdict-type and sentence accuracy but poor exact statute citation.
Significance. If the tasks validly measure the targeted capabilities, the work supplies a much-needed jurisdiction-specific benchmark for a civil-law system using Traditional Chinese sources, complementing existing English/common-law and Simplified-Chinese resources. The reliance on official public corpora is a clear strength for reproducibility and future extension.
major comments (3)
- [Abstract and §4] Abstract and §4 (results): The claim that top models 'exceed the passing threshold for qualified lawyers (passing rate: 11%)' treats MCQ/OEQ accuracy as directly comparable to human qualification thresholds. No section demonstrates that benchmark performance correlates with on-the-job legal reasoning metrics (e.g., case outcome quality or expert ratings), leaving the threshold comparison load-bearing for the 'legal understanding' interpretation.
- [§3.2] §3.2 (OEQ evaluation): The decomposed LLM-as-Judge framework inherits any gaps in the official rubrics and potential biases of the judge model. The manuscript reports no human validation, inter-rater agreement, or calibration against expert scorers, which directly affects the reliability of the OEQ results used to support the passing-rate claims.
- [§3.3 and §4.3] §3.3 and §4.3 (LJP): The observation that models 'struggle to cite exact legal articles' is presented without accompanying error analysis (e.g., distinguishing hallucination, retrieval failure, or knowledge cutoff). This omission weakens the downstream claim that 'reliable legal text generation remains challenging.'
minor comments (2)
- [Table 1 and §2] Table 1 and §2: Ensure consistent reporting of the exact number of instances per domain and any filtering steps applied to the official exam corpus.
- [§5] §5 (discussion): Add a brief limitations paragraph addressing the gap between exam-style tasks and open-ended practical legal work (e.g., multi-party argumentation or novel fact patterns).
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each major comment point by point below, indicating planned changes to the manuscript where appropriate.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (results): The claim that top models 'exceed the passing threshold for qualified lawyers (passing rate: 11%)' treats MCQ/OEQ accuracy as directly comparable to human qualification thresholds. No section demonstrates that benchmark performance correlates with on-the-job legal reasoning metrics (e.g., case outcome quality or expert ratings), leaving the threshold comparison load-bearing for the 'legal understanding' interpretation.
Authors: The tasks and thresholds are drawn directly from official qualification examinations, providing a standardized basis for comparison to the reported passing rates. We agree, however, that the manuscript does not establish correlations with on-the-job performance metrics. In revision we will add an explicit limitations paragraph distinguishing exam-based evaluation from real-world legal practice and noting the absence of such validation data. revision: partial
-
Referee: [§3.2] §3.2 (OEQ evaluation): The decomposed LLM-as-Judge framework inherits any gaps in the official rubrics and potential biases of the judge model. The manuscript reports no human validation, inter-rater agreement, or calibration against expert scorers, which directly affects the reliability of the OEQ results used to support the passing-rate claims.
Authors: The framework applies the official rubrics verbatim. We acknowledge that no human validation or inter-rater statistics are reported. The revised manuscript will include a limitations discussion of this point and a recommendation for future expert calibration studies. revision: yes
-
Referee: [§3.3 and §4.3] §3.3 and §4.3 (LJP): The observation that models 'struggle to cite exact legal articles' is presented without accompanying error analysis (e.g., distinguishing hallucination, retrieval failure, or knowledge cutoff). This omission weakens the downstream claim that 'reliable legal text generation remains challenging.'
Authors: We agree that an error analysis would strengthen the interpretation. The revision will add a short error-analysis subsection that categorizes citation failures with illustrative examples to better support the claim regarding challenges in legal text generation. revision: yes
Circularity Check
No circularity: empirical benchmark from public official sources
full rationale
The paper presents TW-LegalBench as a collection of MCQs, OEQs, and LJP instances drawn directly from public Taiwanese examination corpora and judgments. Evaluation uses standard accuracy, rubric-based LLM-as-Judge, and citation metrics with no equations, fitted parameters, or predictions that reduce to the inputs by construction. Threshold comparisons (e.g., lawyer passing rate 11%) are external benchmarks applied to observed scores, not derived internally. No self-citation load-bearing steps or ansatz smuggling appear. The work is self-contained against external data sources.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Po-Heng Chen, Sijia Cheng, Wei-Lin Chen, Yen-Ting Lin, and Yun-Nung Chen. 2024. Measuring Taiwanese Mandarin Language Understanding. CoRR abs/2403.20180 (2024). arXiv: 2403.20180 doi:10.48550/ARXIV.2403.20180
-
[2]
Pin-Er Chen, Da-Chen Lian, Jou-An Chi, Shu-Kai Hsieh, Sieh-Chuen Huang, Hsuan-Lei Shao, Jun-Wei Chiu, Yang-Hsien Lin, Zih-Ching Chen, Cheng-Kuang Lee, Eddie TC Huang, and Simon See. 2025. Continual Pre-Training is (not) What You Need in Domain Adaptation. In Proceedings of the Asian Conference on Ma- chine Learning (Proceedings of Machine Learning Researc...
2025
-
[3]
Zhiwei Fei, Xiaoyu Shen, Dawei Zhu, Fengzhe Zhou, Zhuo Han, Alan Huang, Songyang Zhang, Kai Chen, Zhixin Yin, Zongwen Shen, Jidong Ge, and Vin- cent Ng. 2024. LawBench: Benchmarking Legal Knowledge of Large Language Models. In Proceedings of the 2024 Conference on Empirical Methods in Natu- ral Language Processing , Yaser Al-Onaizan, Mohit Bansal, and Yun...
2024
-
[4]
doi:10.18653/v1/2024.emnlp-main.452
-
[5]
Jens Frankenreiter, Kevin L Cope, Scott Hirst, Eric A Posner, Daniel Schwarcz, and Dane Thorley. 2024. Grading Machines: Can AI Exam-Grading Replace Law Professors? SSRN Electronic Journal (2024). doi:10.2139/ssrn.5851362
-
[6]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Zhouchi Lin, Bowen Zhang, Lionel Ni, Wen Gao, Yuanzhuo Wang, and Jian Guo
-
[7]
A survey on LLM-as-a-Judge. The Innovation (2026), 101253. doi:10.1016/ j.xinn.2025.101253
-
[8]
Ho, Christopher Ré, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N
Neel Guha, Julian Nyarko, Daniel E. Ho, Christopher Ré, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N. Rock- more, Diego Zambrano, Dmitry Talisman, Enam Hoque, Faiz Surani, Frank Fa- gan, Galit Sarfaty, Gregory M. Dickinson, Haggai Porat, Jason Hegland, Jessica Wu, Joe Nudell, Joel Niklaus, John Nay, Jonathan H....
2023
-
[9]
Zhuo Han, Yi Yang, Yi Feng, Wanhong Huang, Xuxing Ding, Chuanyi Li, Jidong Ge, and Vincent Ng. 2025. LawShift: Benchmarking Legal Judgment Prediction Under Statute Shifts. In The Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems Datasets and Benchmarks Track. https://openreview.net/ forum?id=5SpFenlxDF
2025
-
[10]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Massive Multitask Language Under- standing. Proceedings of the International Conference on Learning Representations (ICLR) (2021)
2021
- [11]
-
[12]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv: 2310.06...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [13]
-
[14]
Meta AI. 2024. The Llama 3 Herd of Models. arXiv preprint arXiv:2407.21783 (2024). https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [15]
-
[16]
OpenAI. 2023. GPT-4 Technical Report. arXiv: 2303.08774 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
OpenAI. 2025. gpt-oss-120b & gpt-oss-20b Model Card. arXiv:2508.10925 [cs.CL] https://arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
OpenAI. 2025. OpenAI GPT-5 System Card. arXiv: 2601.03267 [cs.CL] https: //arxiv.org/abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Shivalika Singh, Angelika Romanou, Clémentine Fourrier, David Ifeoluwa Ade- lani, Jian Gang Ngui, Daniel Vila-Suero, Peerat Limkonchotiwat, Kelly Marchi- sio, Wei Qi Leong, Yosephine Susanto, Raymond Ng, Shayne Longpre, Sebas- tian Ruder, Wei-Yin Ko, Antoine Bosselut, Alice Oh, Andre Martins, Leshem Choshen, Daphne Ippolito, Enzo Ferrante, Marzieh Fadaee,...
-
[20]
Zhi Rui Tam, Ya Ting Pai, Yen-Wei Lee, Hong-Han Shuai, Jun-Da Chen, Wei Min Chu, and Sega Cheng. 2024. TMMLU+: An Improved Traditional Chinese Eval- uation Suite for Foundation Models. In First Conference on Language Modeling . https://openreview.net/forum?id=95TayIeqJ4
2024
-
[21]
Qwen Team. 2024. Qwen2.5 Technical Report. ArXiv abs/2412.15115 (2024). https://api.semanticscholar.org/CorpusID:274859421
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Qwen Team. 2025. Qwen3 Technical Report. arXiv: 2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompt- ing elicits reasoning in large language models. In Proceedings of the 36th In- ternational Conference on Neural Information Processing Systems (New Orleans, LA, USA) (NIPS ’22). Curran Associates Inc., Red Ho...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.