Freeing the Law with LOCUS: A Local Ordinance Corpus for the United States
Pith reviewed 2026-06-26 20:53 UTC · model grok-4.3
The pith
A new corpus assembles machine-readable local ordinance codes from 9,239 U.S. cities and counties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
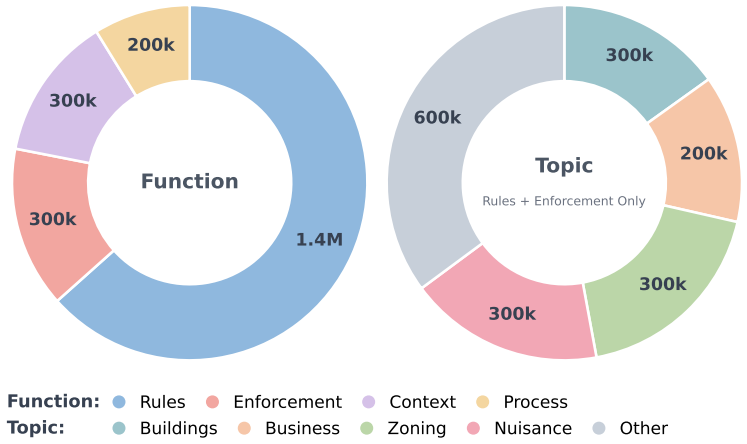
The central claim is that a comprehensive corpus of U.S. local ordinance codes can be assembled from public sources, converted via OCR into machine-readable form, and organized into a county-harmonized access layer that covers the largest 2,309 of 3,144 counties and accounts for a majority of the population, thereby enabling large-scale legal AI research on previously inaccessible municipal rules.
What carries the argument
The LOCUS corpus and its county-harmonized access layer, assembled from public vendor documents through OCR conversion and equipped with coverage metadata.
If this is right
- Large-scale analysis of local regulations on zoning, housing, public health, and similar domains becomes feasible for the first time.
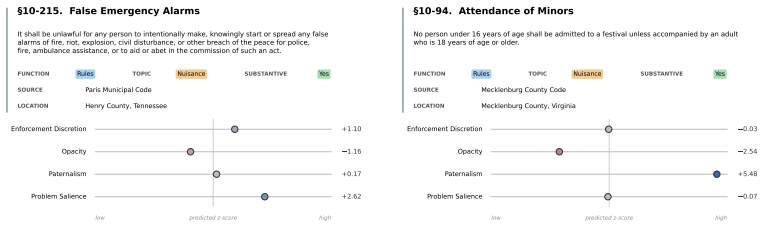
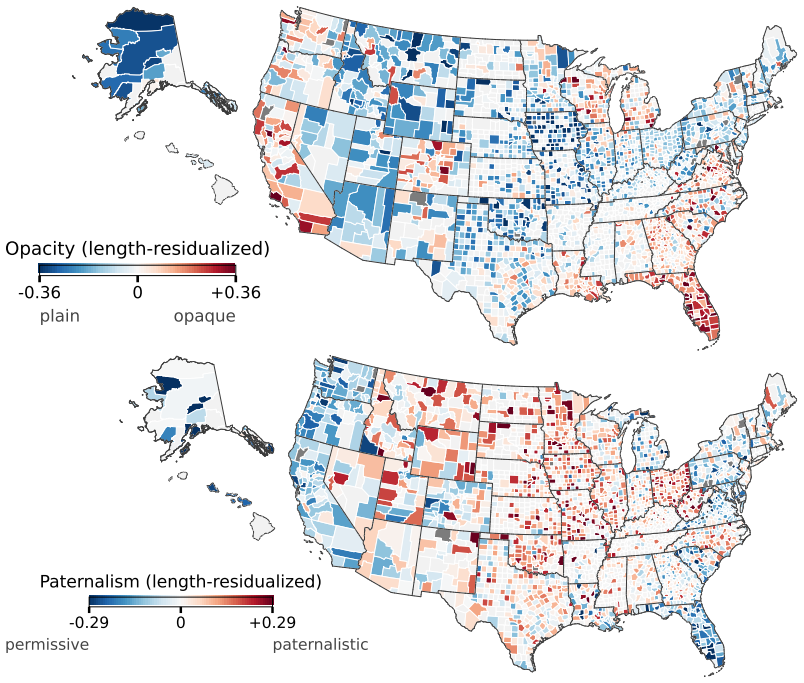
- Classifiers trained on the corpus can score local codes along dimensions such as opacity and paternalism.
- Coverage metadata supports reproducible experiments and targeted additions to the corpus over time.
- Downstream legal AI systems gain a new data source for studying interactions between local and higher-level law.
Where Pith is reading between the lines
- The corpus could be linked to state statute collections to study how local rules fill gaps or conflict with state policy.
- Geographic variation in regulatory style across counties might become measurable and testable against demographic or economic data.
- Policy researchers could use the harmonized layer to compare regulatory burden across similarly sized jurisdictions.
Load-bearing premise
That the collected documents represent the full set of enacted local ordinances and that OCR conversion preserves legal meaning without systematic errors that would affect later analysis.
What would settle it
A manual verification on a random sample of counties that checks whether every enacted ordinance known from official records appears in the corpus and whether the OCR text matches the original legal meaning on key provisions.
Figures


read the original abstract
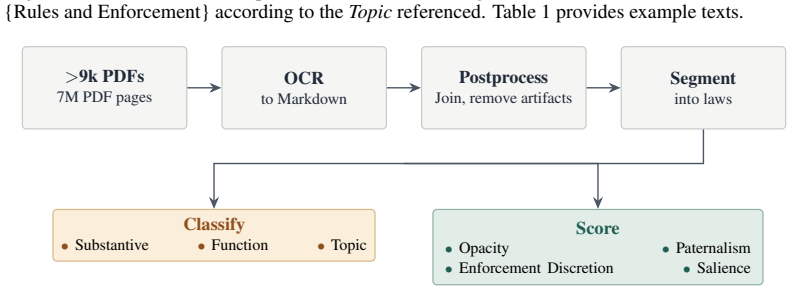
Progress in legal AI increasingly depends on access to authoritative legal text at scale. Yet one of the most consequential layers of American law remains largely absent from existing machine-readable corpora: local ordinances. Local codes govern zoning, housing, business licensing, public health, noise, animal control, and many other domains of everyday regulation, but they are fragmented across vendor platforms designed for human browsing rather than bulk research access. We introduce LOCUS - the Local Ordinance Corpus for the United States - a comprehensive corpus and county-harmonized access layer for U.S. municipal and county ordinance codes. The raw corpus, available for release to researchers, represents nearly all publicly available municipal and county ordinance codes. The resulting raw corpus contains codes from 9,239 cities and counties. A smaller county-harmonized LOCUS access layer provides coverage for the largest 2,309 of 3,144 U.S. counties, accounting for a majority of the population. We use OCR to handle the myriad of document formats that have kept the law from being a public resource. We release the corpus with coverage metadata to support reproducibility, downstream legal AI research, and the incremental expansion of machine-readable access to local law. We train a collection of ModernBERT-based classifiers and scorers to facilitate analyzing U.S. local law among several dimensions, such as opacity and paternalism, that have not previously been studied at this scale. LOCUS-v1 and its derivative models are available at: https://huggingface.co/datasets/LocalLaws/LOCUS-v1
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LOCUS, a corpus of U.S. municipal and county ordinance codes collected from 9,239 cities and counties via scraping and OCR processing of vendor platforms. It provides a county-harmonized access layer covering the largest 2,309 of 3,144 U.S. counties (a majority of the population), releases the raw corpus with coverage metadata on Hugging Face, and trains ModernBERT-based classifiers/scorers for analyzing local law dimensions such as opacity and paternalism.
Significance. If the coverage claims and data quality hold after validation, LOCUS would be a significant contribution by filling a major gap in machine-readable legal text for local ordinances, enabling scalable legal AI research on everyday regulation that has been limited by fragmented sources. The explicit release of coverage metadata and the data itself supports reproducibility and incremental expansion, which are strengths of the work.
major comments (3)
- [Abstract] Abstract: The headline coverage claims (raw corpus from 9,239 entities; harmonized layer for 2,309 counties accounting for majority population) and the assertion of representing 'nearly all publicly available' codes are presented without any quantitative validation such as recall against Census or state jurisdiction lists, scraping completeness checks, or OCR character/legal-term error rates. These metrics are load-bearing for the central claim of comprehensiveness and downstream usability.
- [Abstract] Abstract (data collection and OCR description): The manuscript states that OCR was used to handle document formats but supplies no methodology for source enumeration, no comparison to official lists of jurisdictions, and no evaluation of how OCR errors might affect legal semantics or the ModernBERT classifiers. This directly impacts the reliability of the released corpus.
- [Abstract] Abstract (classifier section): The paper states that ModernBERT-based classifiers and scorers were trained 'to facilitate analyzing U.S. local law among several dimensions' but reports no performance metrics (accuracy, F1, or similar) for these models, which is required to substantiate their utility for the claimed analyses.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the importance of validation metrics. We address each major comment below and will revise the manuscript accordingly to improve transparency and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline coverage claims (raw corpus from 9,239 entities; harmonized layer for 2,309 counties accounting for majority population) and the assertion of representing 'nearly all publicly available' codes are presented without any quantitative validation such as recall against Census or state jurisdiction lists, scraping completeness checks, or OCR character/legal-term error rates. These metrics are load-bearing for the central claim of comprehensiveness and downstream usability.
Authors: We agree these validation metrics are important for substantiating the coverage claims. The manuscript describes the scraping process from vendor platforms that yielded the 9,239 entities and the county-harmonized layer, but we did not include explicit quantitative validation (e.g., recall vs. Census lists or OCR error rates) in the abstract. We will add a validation subsection to the methods and report available metrics such as jurisdiction list comparisons and preliminary OCR spot-check error rates in the revised version. revision: yes
-
Referee: [Abstract] Abstract (data collection and OCR description): The manuscript states that OCR was used to handle document formats but supplies no methodology for source enumeration, no comparison to official lists of jurisdictions, and no evaluation of how OCR errors might affect legal semantics or the ModernBERT classifiers. This directly impacts the reliability of the released corpus.
Authors: The full manuscript expands on data collection beyond the abstract, but we acknowledge the referee's point that explicit methodology, jurisdiction comparisons, and OCR impact analysis are needed for reliability. We will revise the methods section to detail source enumeration, add comparisons to official lists where data permits, and include an evaluation of OCR effects on legal semantics and downstream classifiers. revision: yes
-
Referee: [Abstract] Abstract (classifier section): The paper states that ModernBERT-based classifiers and scorers were trained 'to facilitate analyzing U.S. local law among several dimensions' but reports no performance metrics (accuracy, F1, or similar) for these models, which is required to substantiate their utility for the claimed analyses.
Authors: We agree that performance metrics are required to substantiate the classifiers. The manuscript describes training ModernBERT models for dimensions such as opacity and paternalism, but specific metrics were not reported in the abstract. We will add key metrics (accuracy, F1) to the abstract and ensure a full evaluation section appears in the revised manuscript. revision: yes
Circularity Check
No circularity; empirical data release with no derivation chain
full rationale
The paper is a corpus release describing scraping, OCR conversion, and harmonization of local ordinance documents, reporting direct empirical counts (9,239 entities; 2,309 counties) and downstream classifier training. No equations, fitted predictions, self-citations, or ansatzes appear in the provided text. Coverage figures are presented as outcomes of the collection process rather than quantities derived from or reducing to prior fitted values or self-referential definitions. The manuscript is self-contained as a resource paper; claims rest on external data sources and release metadata, not internal loops.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Publicly available posted documents are sufficient to represent the enacted local ordinances of each jurisdiction.
Reference graph
Works this paper leans on
-
[1]
Conference on Language Modeling (COLM) , year=
Aligning with Human Judgement: The Role of Pairwise Preference in Large Language Model Evaluators , author=. Conference on Language Modeling (COLM) , year=
-
[2]
State Legal Research: General and Multi-Jurisdictional --- Local Government , author =
-
[3]
Scientific Data , volume=
MIMIC-III, a freely accessible critical care database , author=. Scientific Data , volume=. 2016 , publisher=
2016
-
[4]
Scientific Data , volume=
MIMIC-IV, a freely accessible electronic health record dataset , author=. Scientific Data , volume=. 2023 , publisher=
2023
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , year=
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[6]
Chalkidis, Ilias and Jana, Abhik and Hartung, Dirk and Bommarito, Michael and Androutsopoulos, Ion and Katz, Daniel Martin and Aletras, Nikolaos , booktitle=
-
[7]
and Zheng, Lucia and Guha, Neel and Manning, Christopher D
Henderson, Peter and Krass, Mark S. and Zheng, Lucia and Guha, Neel and Manning, Christopher D. and Jurafsky, Dan and Ho, Daniel E. , booktitle=. Pile of Law: Learning Responsible Data Filtering from the Law and a 256
-
[8]
and Henderson, Peter and Ho, Daniel E
Zheng, Lucia and Guha, Neel and Anderson, Brandon R. and Henderson, Peter and Ho, Daniel E. , booktitle=. When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the
-
[9]
Hendrycks, Dan and Burns, Collin and Chen, Anya and Ball, Spencer , booktitle=
-
[10]
, booktitle=
Koreeda, Yuta and Manning, Christopher D. , booktitle=
-
[11]
Proceedings of the Natural Legal Language Processing Workshop , year=
A Dataset for Statutory Reasoning in Tax Law Entailment and Question Answering , author=. Proceedings of the Natural Legal Language Processing Workshop , year=
-
[12]
Chalkidis, Ilias and Fergadiotis, Manos and Malakasiotis, Prodromos and Aletras, Nikolaos and Androutsopoulos, Ion , booktitle=
-
[13]
Journal of Legal Analysis , volume=
Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models , author=. Journal of Legal Analysis , volume=
-
[14]
Proceedings of the 12th Language Resources and Evaluation Conference (LREC) , year=
Tuggener, Don and von D. Proceedings of the 12th Language Resources and Evaluation Conference (LREC) , year=
-
[15]
Advances in neural information processing systems , volume=
TrueSkill™: a Bayesian skill rating system , author=. Advances in neural information processing systems , volume=
-
[16]
LightOnOCR: A 1B End-to-End Multilingual Vision-Language Model for State-of-the-Art OCR
LightOnOCR: A 1B End-to-End Multilingual Vision-Language Model for State-of-the-Art OCR , author=. arXiv preprint arXiv:2601.14251 , year=
work page internal anchor Pith review arXiv
-
[17]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
arXiv preprint arXiv:2510.19817 , year=
olmocr 2: Unit test rewards for document ocr , author=. arXiv preprint arXiv:2510.19817 , year=
-
[19]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[20]
2026 , note =
Havelock AI , author =. 2026 , note =
2026
-
[21]
Advances in Neural Information Processing Systems , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , volume =. 2020 , eprint =
2020
-
[22]
2026 , month = mar, day =
Introducing. 2026 , month = mar, day =
2026
-
[23]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging. 2023 , eprint =
2023
-
[24]
Public.Resource.Org, Inc
Georgia v. Public.Resource.Org, Inc. , author =. 2020 , month = apr, day =
2020
-
[25]
Harvard Law Review , volume =
Holmes, Jr., Oliver Wendell , title =. Harvard Law Review , volume =
-
[26]
2018 , howpublished =
Caselaw. 2018 , howpublished =
2018
-
[27]
and Riddell, Allen B
Livermore, Michael A. and Riddell, Allen B. and Rockmore, Daniel N. , title =. Arizona Law Review , volume =
-
[28]
Predicting Judicial Decisions of the
Aletras, Nikolaos and Tsarapatsanis, Dimitrios and Preo. Predicting Judicial Decisions of the. PeerJ Computer Science , volume =. 2016 , doi =
2016
-
[29]
Steinberger, Ralf and Pouliquen, Bruno and Widiger, Anna and Ignat, Camelia and Erjavec, Toma. The. Proceedings of the 5th International Conference on Language Resources and Evaluation (LREC) , year =
-
[30]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
Chalkidis, Ilias and Androutsopoulos, Ion and Aletras, Nikolaos , title =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.