Quantifying Aleatoric Uncertainty of In-Context Learning for Robust Measure of LLM Prediction Confidence
Pith reviewed 2026-07-01 09:04 UTC · model grok-4.3
The pith
Self-function vectors enable direct estimation of aleatoric uncertainty in LLM in-context learning predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
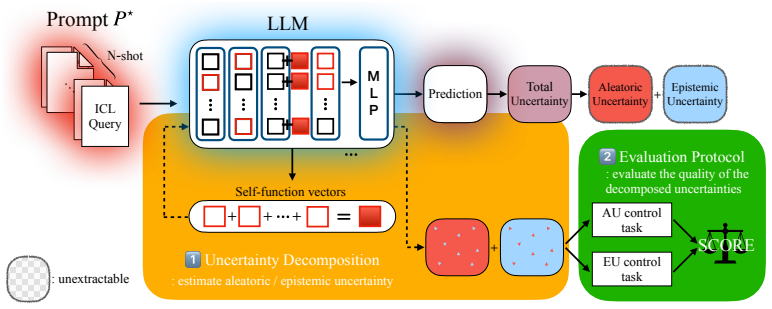
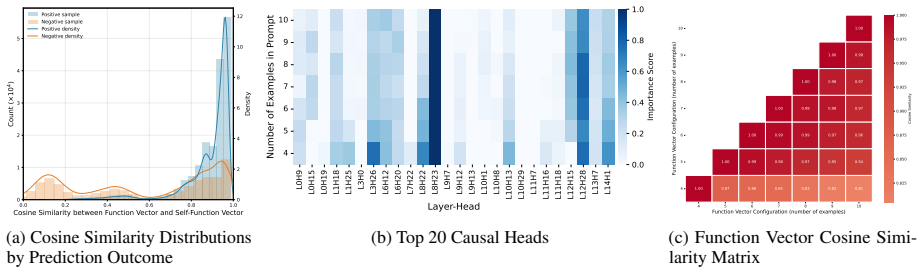
Self-function vectors, constructed upon Bayesian views and the mechanistic interpretability of ICL, leverage internal model representations to model the latent concept learned during in-context prompting, thereby enabling a direct estimation of aleatoric uncertainty within a Bayesian framework.
What carries the argument
Self-function vectors that model the latent concept from in-context prompting using internal representations to estimate aleatoric uncertainty.
If this is right
- Aleatoric uncertainty in ICL predictions can be quantified separately from epistemic uncertainty.
- Uncertainty measurement becomes more reliable than methods that depend on brittle input or decoding manipulations.
- The method supports practical uses such as hallucination detection.
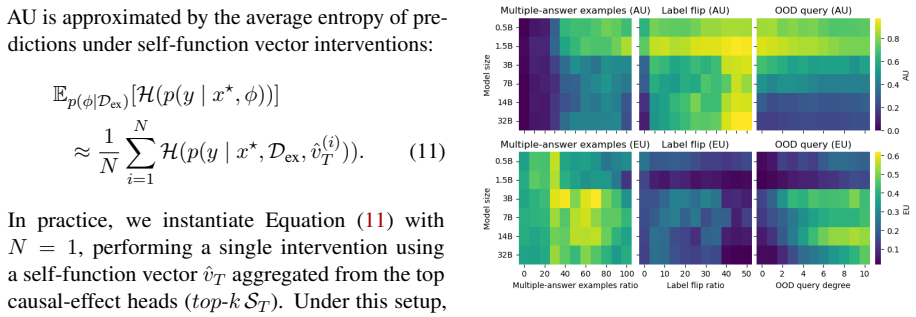
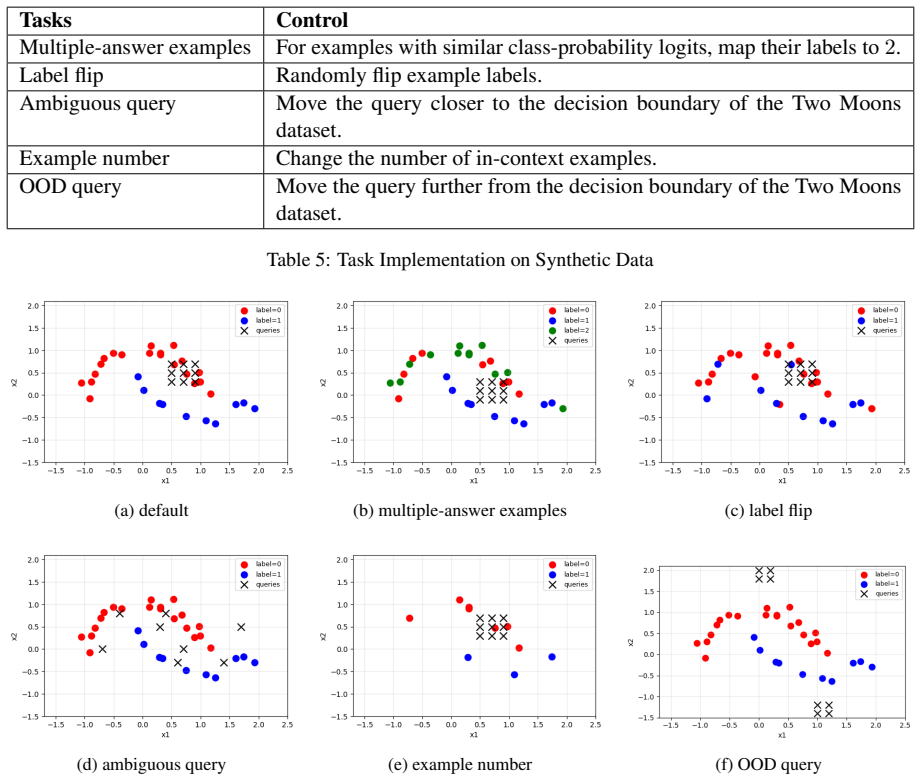
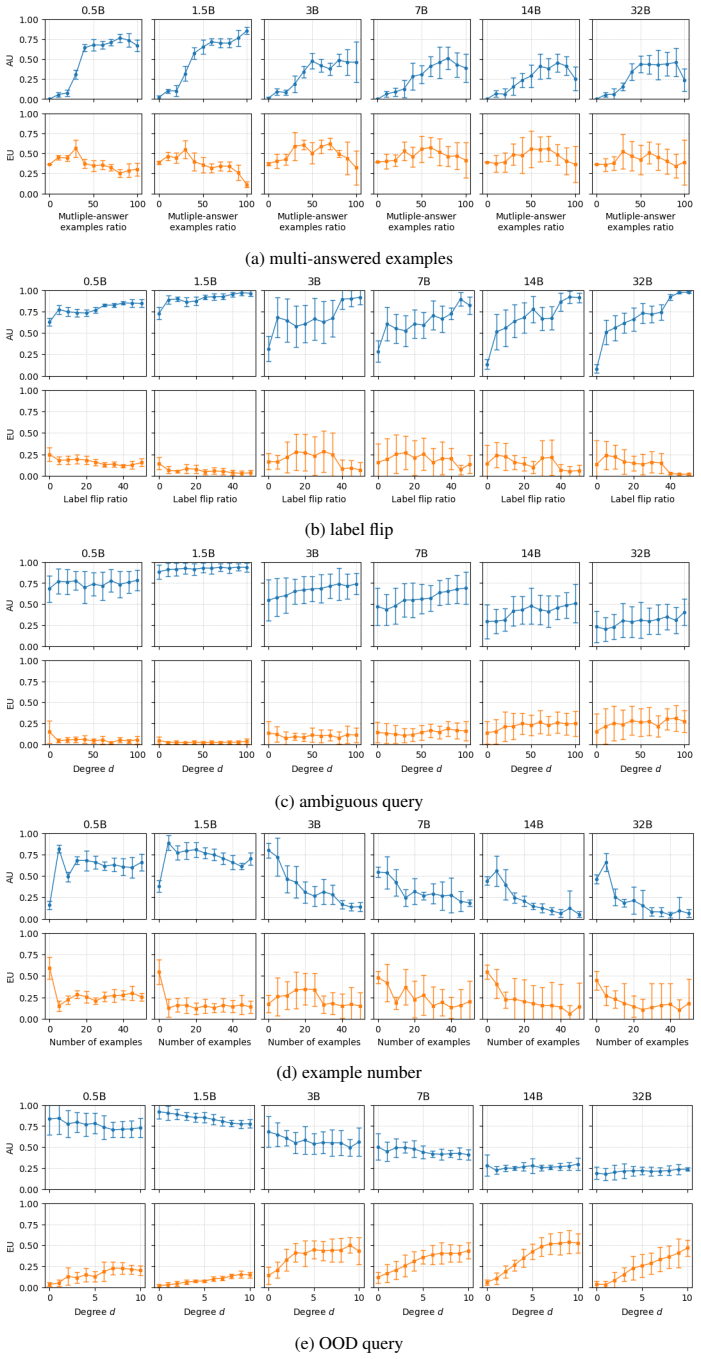
- The evaluation protocol isolates aleatoric uncertainty through controlled data manipulations on both synthetic and real datasets.
Where Pith is reading between the lines
- The connection between internal representations and uncertainty may extend to other prompting techniques beyond standard ICL.
- Improved aleatoric estimation could help distinguish data-inherent noise from model knowledge gaps in deployed systems.
- This framing suggests new ways to combine mechanistic analysis with quantitative uncertainty tools for few-shot reliability.
Load-bearing premise
Self-function vectors built upon Bayesian views and mechanistic interpretability of ICL can model the latent concept learned during in-context prompting to enable direct aleatoric uncertainty estimation.
What would settle it
A controlled experiment in which the method fails to report higher aleatoric uncertainty when label noise or input perturbations are systematically added to the demonstrations while holding model behavior fixed.
Figures

read the original abstract
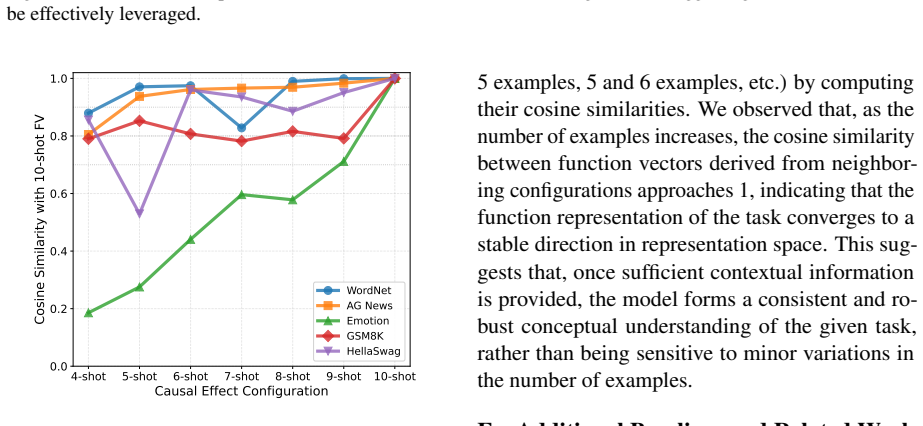
In-Context Learning (ICL) allows LLMs to adapt to new tasks from a few demonstrations, but its reliability remains a concern: predictions are highly sensitive to both prompt design and the model's ability to understand the context, obscuring whether failures arise from data properties or model limitations. Uncertainty decomposition-separating aleatoric from epistemic sources-is particularly crucial in this setting, yet existing methods, designed for standard generation tasks, fail to capture the unique dynamics of ICL. To address this, we introduce a concept of self-function vectors, built upon Bayesian views and the mechanistic interpretability of ICL. These vectors leverage internal model representations to model the latent concept learned during in-context prompting, thereby enabling a direct estimation of aleatoric uncertainty within a Bayesian framework and circumventing the reliance on brittle input or decoding manipulations. Given the lack of established benchmarks and suitable evaluation protocols, we also propose the first and rigorous evaluation protocol, in which data is manipulated in controlled ways so as to quantify aleatoric uncertainty precisely and separately from epistemic uncertainty. With this new evaluation framework, initially grounded in synthetic tasks for conceptual development and subsequently extended to real-world datasets, we show that our proposed methodology can measure uncertainty of LLM predictions made under ICL more reliably than existing alternative methods. Moreover, we show it can be used as a practical tool for trustworthy-related applications, such as hallucination detection. Our findings pave a new direction for connecting the quantitative view of uncertainty with the mechanistic understanding of model behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces self-function vectors, constructed from internal LLM representations via Bayesian and mechanistic interpretability views of in-context learning (ICL), to enable direct estimation of aleatoric uncertainty in ICL predictions. It also proposes a new evaluation protocol using controlled data manipulations to isolate aleatoric uncertainty, reports superior performance over baselines on synthetic tasks and real-world datasets, and demonstrates utility for hallucination detection.
Significance. If the self-function vectors provably isolate aleatoric uncertainty without entanglement from epistemic sources, the work would meaningfully connect quantitative uncertainty estimation to ICL mechanics and supply a needed benchmark protocol. The protocol itself is a constructive contribution for future studies even if the vector method requires refinement.
major comments (2)
- [§3] §3: The definition of self-function vectors from internal activations provides no explicit invariance argument or derivation showing separation from epistemic factors (e.g., prompt sensitivity, model scale). Because the evaluation manipulations alter the same activations used to build the vectors, it is unclear whether reported gains reflect true aleatoric isolation or an artifact of incomplete separation.
- [Evaluation protocol] Evaluation protocol (synthetic and real-data sections): The claim that controlled manipulations quantify aleatoric uncertainty 'precisely and separately' from epistemic uncertainty lacks a formal argument or ablation demonstrating that the manipulations leave model parameters and prompt sensitivity unchanged while only varying data-inherent noise.
minor comments (2)
- [Abstract and §2] Abstract and §2: Include at least one key equation defining the self-function vector construction to allow readers to assess its Bayesian grounding without waiting for the full derivation.
- [Related-work section] Related-work section: Explicitly compare the proposed vectors against prior ICL uncertainty methods that also use internal states (e.g., attention or activation-based probes) to clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies areas where additional formal justification would strengthen the manuscript. We respond to each major comment below.
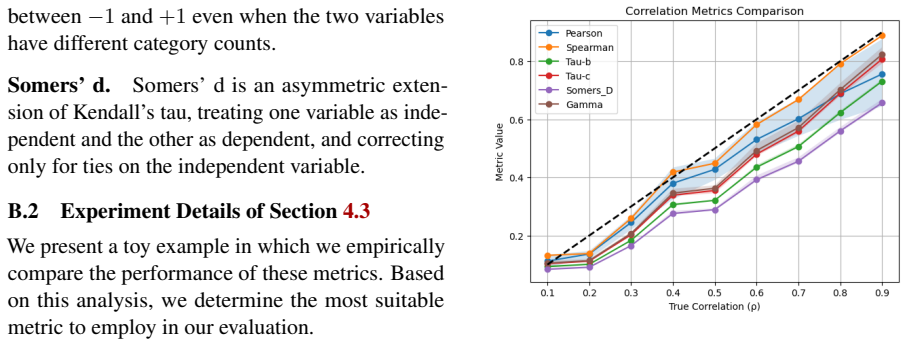
read point-by-point responses
-
Referee: [§3] §3: The definition of self-function vectors from internal activations provides no explicit invariance argument or derivation showing separation from epistemic factors (e.g., prompt sensitivity, model scale). Because the evaluation manipulations alter the same activations used to build the vectors, it is unclear whether reported gains reflect true aleatoric isolation or an artifact of incomplete separation.
Authors: We agree that the current manuscript lacks an explicit invariance argument or derivation. The self-function vectors are constructed from internal activations to capture the latent concept under a Bayesian view of ICL, with the intent that averaging over in-context examples isolates data-inherent (aleatoric) variation while epistemic factors are reflected in model-scale or prompt variations. However, this separation is not formally derived. In revision we will add a subsection deriving the invariance properties under the stated Bayesian and mechanistic assumptions, and include new ablations that vary prompt phrasing and model scale while holding data noise fixed, to test whether the uncertainty estimates remain stable. revision: yes
-
Referee: [Evaluation protocol] Evaluation protocol (synthetic and real-data sections): The claim that controlled manipulations quantify aleatoric uncertainty 'precisely and separately' from epistemic uncertainty lacks a formal argument or ablation demonstrating that the manipulations leave model parameters and prompt sensitivity unchanged while only varying data-inherent noise.
Authors: The protocol manipulates only the data (e.g., controlled label or input noise) while keeping the model, task definition, and prompt template fixed, with the goal of varying only aleatoric sources. We acknowledge that the manuscript provides neither a formal argument nor targeted ablations confirming that model parameters and prompt sensitivity remain unchanged. In the revision we will add (i) a formal statement of the assumptions under which the manipulations affect only data-inherent noise and (ii) an ablation that measures prompt sensitivity and cross-model consistency before and after each manipulation, reporting that the aleatoric estimates track the introduced noise level independently of these factors. revision: yes
Circularity Check
No circularity: derivation chain not exhibited in text
full rationale
The provided abstract and reader summary contain no equations, no explicit derivation steps, and no self-citations that could be inspected for reduction to inputs. Self-function vectors are described at a high level as built on Bayesian views and ICL interpretability to estimate aleatoric uncertainty, but without any mathematical construction shown, no self-definitional, fitted-input, or self-citation load-bearing pattern can be identified. The evaluation protocol is presented as a new contribution rather than a renaming or smuggling of prior results. The paper is therefore self-contained against external benchmarks on the basis of the given text; a score of 0 is the appropriate default when no load-bearing step reduces by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
self-function vectors
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Proceedings of the 2024 International Conference on Learning Representations , url=
Function Vectors in Large Language Models , author=. Proceedings of the 2024 International Conference on Learning Representations , url=
2024
-
[9]
Uncertainty Quantification for In-Context Learning of Large Language Models
Ling, Chen and Zhao, Xujiang and Zhang, Xuchao and Cheng, Wei and Liu, Yanchi and Sun, Yiyou and Oishi, Mika and Osaki, Takao and Matsuda, Katsushi and Ji, Jie and Bai, Guangji and Zhao, Liang and Chen, Haifeng. Uncertainty Quantification for In-Context Learning of Large Language Models. Proceedings of the 2024 Conference of the North American Chapter of ...
-
[10]
International Conference on Learning Representations , year=
An Explanation of In-context Learning as Implicit Bayesian Inference , author=. International Conference on Learning Representations , year=
-
[11]
The Thirteenth International Conference on Learning Representations , year=
Unlocking the Power of Function Vectors for Characterizing and Mitigating Catastrophic Forgetting in Continual Instruction Tuning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[12]
2024 , url=
A Latent Space Theory for Emergent Abilities in Large Language Models , author=. 2024 , url=
2024
-
[13]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[14]
Forty-first International Conference on Machine Learning , year=
Is In-Context Learning in Large Language Models Bayesian? A Martingale Perspective , author=. Forty-first International Conference on Machine Learning , year=
-
[15]
2024 , eprint=
Exchangeable Sequence Models Quantify Uncertainty Over Latent Concepts , author=. 2024 , eprint=
2024
-
[16]
Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence , pages =
Quantifying aleatoric and epistemic uncertainty in machine learning: Are conditional entropy and mutual information appropriate measures? , author =. Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence , pages =. 2023 , editor =
2023
-
[17]
2021 , url =
A Mathematical Framework for Transformer Circuits , author =. 2021 , url =
2021
-
[18]
2022 , eprint=
In-context Learning and Induction Heads , author=. 2022 , eprint=
2022
-
[19]
2025 , eprint=
Which Attention Heads Matter for In-Context Learning? , author=. 2025 , eprint=
2025
-
[20]
2024 , eprint=
A Survey on Uncertainty Quantification of Large Language Models: Taxonomy, Open Research Challenges, and Future Directions , author=. 2024 , eprint=
2024
-
[21]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[22]
The Eleventh International Conference on Learning Representations , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. The Eleventh International Conference on Learning Representations , year=
-
[23]
To Believe or Not to Believe Your
Yasin Abbasi-Yadkori and Ilja Kuzborskij and Andr. To Believe or Not to Believe Your. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[24]
Data Distributional Properties Drive Emergent In-Context Learning in Transformers , url =
Chan, Stephanie and Santoro, Adam and Lampinen, Andrew and Wang, Jane and Singh, Aaditya and Richemond, Pierre and McClelland, James and Hill, Felix , booktitle =. Data Distributional Properties Drive Emergent In-Context Learning in Transformers , url =
-
[25]
2022 , eprint=
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? , author=. 2022 , eprint=
2022
-
[26]
In-weight Learning , author=
Toward Understanding In-context vs. In-weight Learning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[27]
Journal of the American Society for Information Science and Technology , volume=
Good debt or bad debt: Detecting semantic orientations in economic texts , author=. Journal of the American Society for Information Science and Technology , volume=. 2014 , publisher=
2014
-
[28]
Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing , pages=
Recursive deep models for semantic compositionality over a sentiment treebank , author=. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing , pages=. 2013 , organization=
2013
-
[29]
Transactions of the Association for Computational Linguistics , volume=
Neural network acceptability judgments , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[30]
arXiv preprint arXiv:2002.07650 , year=
Uncertainty estimation in autoregressive structured prediction , author=. arXiv preprint arXiv:2002.07650 , year=
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Quantifying uncertainties in natural language processing tasks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[32]
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? , url =
Kendall, Alex and Gal, Yarin , booktitle =. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? , url =
-
[33]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Benchmarking Uncertainty Disentanglement: Specialized Uncertainties for Specialized Tasks , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[34]
Forty-second International Conference on Machine Learning , year=
Rethinking Aleatoric and Epistemic Uncertainty , author=. Forty-second International Conference on Machine Learning , year=
-
[35]
2011 , eprint=
Bayesian Active Learning for Classification and Preference Learning , author=. 2011 , eprint=
2011
-
[36]
Yarin Gal and Riashat Islam and Zoubin Ghahramani , booktitle =. Deep. 2017 , editor =
2017
-
[37]
2025 , eprint=
Variational Uncertainty Decomposition for In-Context Learning , author=. 2025 , eprint=
2025
-
[38]
A Comparison of the Most Commonly Used Measures of Association for Doubly Ordered Square Contingency Tables Via Simulation , volume =
Göktaş, Atila and Isci Guneri, Oznur , year =. A Comparison of the Most Commonly Used Measures of Association for Doubly Ordered Square Contingency Tables Via Simulation , volume =. Metodoloski Zvezki , doi =
-
[39]
The 2023 Conference on Empirical Methods in Natural Language Processing , year=
In-Context Learning Creates Task Vectors , author=. The 2023 Conference on Empirical Methods in Natural Language Processing , year=
2023
-
[40]
Juyeon Heo and Christina Heinze-Deml and Oussama Elachqar and Kwan Ho Ryan Chan and Shirley You Ren and Andrew Miller and Udhyakumar Nallasamy and Jaya Narain , booktitle=. Do. 2025 , url=
2025
-
[41]
W ord N et: A Lexical Database for E nglish
Miller, George A. W ord N et: A Lexical Database for E nglish. H uman L anguage T echnology: Proceedings of a Workshop held at P lainsboro, N ew J ersey, M arch 8-11, 1994. 1994
1994
-
[42]
Forty-Second International Conference on Machine Learning , author =
Iterative Vectors: In-Context Gradient Steering without Backpropagation , shorttitle =. Forty-Second International Conference on Machine Learning , author =. 2025 , urldate =
2025
-
[43]
Goodman and William H
Leo A. Goodman and William H. Kruskal , journal =. Measures of Association for Cross Classifications , urldate =
-
[44]
The 28th International Conference on Artificial Intelligence and Statistics , year=
On Subjective Uncertainty Quantification and Calibration in Natural Language Generation , author=. The 28th International Conference on Artificial Intelligence and Statistics , year=
-
[45]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[46]
2016 , eprint=
Character-level Convolutional Networks for Text Classification , author=. 2016 , eprint=
2016
-
[47]
CARER : Contextualized Affect Representations for Emotion Recognition
Saravia, Elvis and Liu, Hsien-Chi Toby and Huang, Yen-Hao and Wu, Junlin and Chen, Yi-Shin. CARER : Contextualized Affect Representations for Emotion Recognition. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1404
-
[48]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year=
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year=
-
[49]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Wong and Emine Yilmaz and Shuming Shi and Zhaopeng Tu , booktitle=
Fanghua Ye and Mingming Yang and Jianhui Pang and Longyue Wang and Derek F. Wong and Emine Yilmaz and Shuming Shi and Zhaopeng Tu , booktitle=. Benchmarking. 2024 , url=
2024
-
[51]
Datasets: A Community Library for Natural Language Processing
Lhoest, Quentin and Villanova del Moral, Albert and Jernite, Yacine and Thakur, Abhishek and von Platen, Patrick and Patil, Suraj and Chaumond, Julien and Drame, Mariama and Plu, Julien and Tunstall, Lewis and Davison, Joe and S a s ko, Mario and Chhablani, Gunjan and Malik, Bhavitvya and Brandeis, Simon and Le Scao, Teven and Sanh, Victor and Xu, Canwen ...
-
[52]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[53]
Two-stage
Yihan Wang and Si Si and Daliang Li and Michal Lukasik and Felix Yu and Cho-Jui Hsieh and Inderjit S Dhillon and Sanjiv Kumar , booktitle=. Two-stage. 2024 , url=
2024
-
[54]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[55]
International Conference on Learning Representations , year=
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks , author=. International Conference on Learning Representations , year=
-
[56]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
2024
-
[57]
2025 , eprint=
Uncertainty-Aware Attention Heads: Efficient Unsupervised Uncertainty Quantification for LLMs , author=. 2025 , eprint=
2025
-
[58]
LM -Polygraph: Uncertainty Estimation for Language Models
Fadeeva, Ekaterina and Rubashevskii, Aleksandr and Shelmanov, Artem and Petrakov, Sergey and Li, Haonan and Panchenko, Alexander and Panov, Maxim and Baldwin, Timothy and Stenetorp, Pontus. LM -Polygraph: Uncertainty Estimation for Language Models. Transactions of the Association for Computational Linguistics. 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.