FloatDoor: Platform-Triggered Backdoors in LLMs
Pith reviewed 2026-06-26 20:09 UTC · model grok-4.3
The pith
FloatDoor uses two lightweight LoRA adapters to embed platform-triggered backdoors in generative LLMs by amplifying floating-point differences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FloatDoor is the first input-independent, platform-triggered backdoor attack against generative LLMs realized through two lightweight LoRA adapters that amplifies inter-platform numerical divergence and binds the platform signature to a malicious downstream task.
What carries the argument
Two lightweight LoRA adapters, one amplifying inter-platform numerical divergence from floating-point arithmetic and the other binding the resulting platform signature to a malicious downstream task.
Load-bearing premise
Natural platform-dependent variability in floating-point arithmetic is large enough and stable enough to be reliably amplified by one LoRA adapter and bound to a specific malicious output by a second adapter without materially degrading model performance or being detectable during standard auditing.
What would settle it
A test that measures the rate at which the model produces the malicious output on the target platform versus other platforms, while also checking performance on standard benchmarks and detection by common auditing methods.
Figures

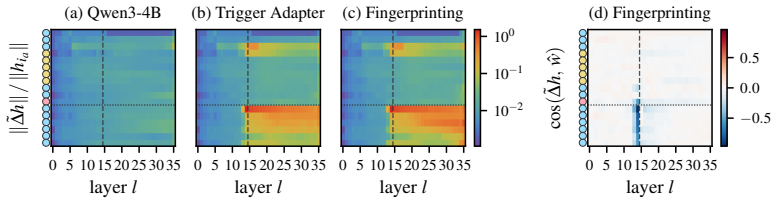

read the original abstract
Large language models (LLMs) are increasingly deployed in sensitive settings such as software engineering, where their outputs directly shape downstream artifacts. Recent work has shown that an identical model can produce measurably different outputs depending on the deployment platform, a consequence of non-associative floating-point arithmetic and divergent kernel implementations. We study the security implications of this platform-dependent variability and uncover a novel attack surface on LLM deployments. We introduce FloatDoor, the first input-independent, platform-triggered backdoor attack against generative LLMs. The compromised model exhibits adversary-chosen behavior when served on a target platform and is otherwise benign. FloatDoor is realized through two lightweight LoRA adapters, one that amplifies inter-platform numerical divergence and one that binds the resulting platform signature to a malicious downstream task, while leaving aggregate model utility largely intact. FloatDoor exploits a pronounced time-of-check, time-of-use gap between model auditing and serving. We demonstrate FloatDoor on Qwen3-4B across a broad range of deployment targets, including NVIDIA GPUs, Google TPUs, AWS Graviton, and Alibaba Yitian-710. As a final case study, we show that FloatDoor reliably induces exploitable code vulnerabilities on a chosen target platform. Our results establish a new class of attacks on LLM deployments and underscore the pressing need for trusted model supply chains in sensitive, LLM-powered applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FloatDoor, the first input-independent, platform-triggered backdoor attack on generative LLMs. It is realized by two lightweight LoRA adapters: the first amplifies inter-platform numerical divergence arising from non-associative floating-point arithmetic and divergent kernels, while the second binds the resulting platform signature to an adversary-chosen malicious downstream task. The attack is claimed to leave aggregate model utility largely intact and is demonstrated on Qwen3-4B across NVIDIA GPUs, Google TPUs, AWS Graviton, and Alibaba Yitian-710, including a case study inducing exploitable code vulnerabilities on a target platform.
Significance. If the empirical construction holds, the work identifies a new attack surface that exploits a time-of-check/time-of-use gap between auditing and serving, with direct relevance to trusted supply chains for LLMs in sensitive domains such as software engineering. The use of only two lightweight LoRA adapters is a practical strength if the amplification remains stable and selective.
major comments (2)
- [Abstract] Abstract: the central claim that natural platform-dependent FP variability is 'large enough' and 'stable enough' to be selectively amplified by one LoRA and cleanly bound by the second without materially degrading utility rests on an unquantified assumption. No divergence magnitudes, amplification factors, trigger reliability rates, or utility metrics (perplexity, BLEU, or downstream task accuracy) are supplied, which is load-bearing for the assertion that the attack is both reliable and stealthy.
- [Abstract] Abstract (case study paragraph): the claim that FloatDoor 'reliably induces exploitable code vulnerabilities' on the target platform is presented without any reported success rates, false-positive rates on non-target platforms, or comparison against baseline model behavior, leaving the practical impact of the attack unevaluable.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments. We address the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that natural platform-dependent FP variability is 'large enough' and 'stable enough' to be selectively amplified by one LoRA and cleanly bound by the second without materially degrading utility rests on an unquantified assumption. No divergence magnitudes, amplification factors, trigger reliability rates, or utility metrics (perplexity, BLEU, or downstream task accuracy) are supplied, which is load-bearing for the assertion that the attack is both reliable and stealthy.
Authors: We agree that the abstract would be improved by including these quantitative details. The full manuscript reports the relevant metrics in the experimental evaluation (e.g., divergence magnitudes in Section 3, amplification factors and reliability rates in Section 4, and utility metrics in Section 5). We will revise the abstract to summarize these key results. revision: yes
-
Referee: [Abstract] Abstract (case study paragraph): the claim that FloatDoor 'reliably induces exploitable code vulnerabilities' on the target platform is presented without any reported success rates, false-positive rates on non-target platforms, or comparison against baseline model behavior, leaving the practical impact of the attack unevaluable.
Authors: We acknowledge this point. The case study in the full paper provides these details, including success rates on target and non-target platforms as well as comparisons to the baseline. We will update the abstract's case study paragraph to include representative quantitative results from the evaluation. revision: yes
Circularity Check
No significant circularity; empirical construction with no self-referential reductions
full rationale
The paper presents FloatDoor as an empirical attack realized via two LoRA adapters that amplify platform FP divergence and bind it to a malicious task. The abstract and described structure contain no equations, fitted parameters renamed as predictions, self-citation chains, or ansatzes that reduce the central claim to its own inputs by construction. The load-bearing elements are experimental demonstrations across platforms, which are externally falsifiable and not derived from prior self-citations. This is a standard non-circular empirical security paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Refusal in language models is mediated by a single direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Systems 38: Annual Conference...
2024
-
[2]
Architec- tural backdoors in neural networks
Mikel Bober-Irizar, Ilia Shumailov, Yiren Zhao, Robert Mullins, and Nicolas Papernot. Architec- tural backdoors in neural networks. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, V ancouver , BC, Canada, June 17-24, 2023, pages 24595–24604. IEEE, 2023
2023
-
[3]
Vadhan, and Connor Wagaman
Sílvia Casacuberta, Michael Shoemate, Salil P. Vadhan, and Connor Wagaman. Widespread underestimation of sensitivity in differentially private libraries and how to fix it. In Heng Yin, Angelos Stavrou, Cas Cremers, and Elaine Shi, editors,Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, CCS 2022, Los Angeles, CA, USA,...
2022
-
[4]
Simin Chen, Jinjun Peng, Yixin He, Junfeng Yang, and Baishakhi Ray. Your compiler is back- dooring your model: Understanding and exploiting compilation inconsistency vulnerabilities in deep learning compilers.CoRR, abs/2509.11173, 2025
arXiv 2025
-
[5]
Locking machine learning models into hardware
Eleanor Clifford, Adhithya Saravanan, Harry Langford, Cheng Zhang, Yiren Zhao, Robert Mullins, Ilia Shumailov, and Jamie Hayes. Locking machine learning models into hardware. In IEEE Conference on Secure and Trustworthy Machine Learning, SaTML 2025, Copenhagen, Denmark, April 9-11, 2025, pages 302–320. IEEE, 2025
2025
-
[6]
On the algorithmic implementation of multiclass kernel- based vector machines.J
Koby Crammer and Yoram Singer. On the algorithmic implementation of multiclass kernel- based vector machines.J. Mach. Learn. Res., 2:265–292, 2001
2001
-
[7]
Sen Fang, Weiyuan Ding, Antonio Mastropaolo, and Bowen Xu. Smaller = weaker? bench- marking robustness of quantized llms in code generation.CoRR, abs/2506.22776, 2025
arXiv 2025
-
[8]
Watch your steps: Dormant adversarial behaviors that activate upon LLM finetuning
Thibaud Gloaguen, Mark Vero, Robin Staab, and Martin Vechev. Watch your steps: Dormant adversarial behaviors that activate upon LLM finetuning. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[9]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021
2021
-
[10]
Qu-anti-zation: Exploiting quantization artifacts for achieving adversarial outcomes
Sanghyun Hong, Michael-Andrei Panaitescu-Liess, Yigitcan Kaya, and Tudor Dumitras. Qu-anti-zation: Exploiting quantization artifacts for achieving adversarial outcomes. In Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wort- man Vaughan, editors,Advances in Neural Information Processing Systems 34: Annual Confer- ence ...
2021
-
[11]
Opencoder: The open cookbook for top-tier code large language models
Siming Huang, Tianhao Cheng, Jason Klein Liu, Weidi Xu, Jiaran Hao, Liuyihan Song, Yang Xu, Jian Yang, Jiaheng Liu, Chenchen Zhang, Linzheng Chai, Ruifeng Yuan, Xianzhen Luo, Qiufeng Wang, YuanTao Fan, Qingfu Zhu, Zhaoxiang Zhang, Yang Gao, Jie Fu, Qian Liu, Houyi Li, Ge Zhang, Yuan Qi, Yinghui Xu, Wei Chu, and Zili Wang. Opencoder: The open cookbook for ...
2025
-
[12]
Ziegler, Tim Maxwell, Newton Cheng, Adam S
Evan Hubinger, Carson Denison, Jesse Mu, Mike Lambert, Meg Tong, Monte MacDiarmid, Tamera Lanham, Daniel M. Ziegler, Tim Maxwell, Newton Cheng, Adam S. Jermyn, Amanda Askell, Ansh Radhakrishnan, Cem Anil, David Duvenaud, Deep Ganguli, Fazl Barez, Jack Clark, Kamal Ndousse, Kshitij Sachan, Michael Sellitto, Mrinank Sharma, Nova DasSarma, Roger B. Grosse, S...
Pith/arXiv arXiv 2024
-
[13]
Kai Jia and Martin C. Rinard. Exploiting verified neural networks via floating point numerical error. In Cezara Dragoi, Suvam Mukherjee, and Kedar S. Namjoshi, editors,Static Analysis - 28th International Symposium, SAS 2021, Chicago, IL, USA, October 17-19, 2021, Proceedings, Lecture Notes in Computer Science, pages 191–205. Springer, 2021
2021
-
[14]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Jason Flinn, Margo I. Seltzer, Peter Druschel, Antoine Kaufmann, and Jonathan Mace, editors,Proceedings of the 29th Symposium on Operating Systems P...
2023
-
[15]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019
2019
-
[16]
Al-Sarawi, and Derek Abbott
Hua Ma, Huming Qiu, Yansong Gao, Zhi Zhang, Alsharif Abuadbba, Minhui Xue, Anmin Fu, Jiliang Zhang, Said F. Al-Sarawi, and Derek Abbott. Quantization backdoors to deep learning commercial frameworks.IEEE Trans. Dependable Secur . Comput., 21(3):1155–1172, 2024
2024
-
[17]
Hardware-triggered backdoors.CoRR, abs/2601.21902, 2026
Jonas Möller, Erik Imgrund, Thorsten Eisenhofer, and Konrad Rieck. Hardware-triggered backdoors.CoRR, abs/2601.21902, 2026
arXiv 2026
-
[18]
Adversarial inputs for linear algebra backends
Jonas Möller, Lukas Pirch, Felix Weissberg, Sebastian Baunsgaard, Thorsten Eisenhofer, and Konrad Rieck. Adversarial inputs for linear algebra backends. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,F orty-second International Conference on Machine Learning, ICML 2025...
2025
-
[19]
Asleep at the keyboard? assessing the security of github copilot’s code contributions
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. Asleep at the keyboard? assessing the security of github copilot’s code contributions. In43rd IEEE Symposium on Security and Privacy, SP 2022, San Francisco, CA, USA, May 22-26, 2022, pages 754–768. IEEE, 2022
2022
-
[20]
Instruction tuning with gpt-4.arXiv preprint arXiv:2304.03277, 2023
Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4.arXiv preprint arXiv:2304.03277, 2023
Pith/arXiv arXiv 2023
-
[21]
Steering llama 2 via contrastive activation addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering llama 2 via contrastive activation addition. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), ACL 2024, Bangkok, Thailand, August ...
2024
-
[22]
Causes and effects of unanticipated numerical deviations in neural network inference frameworks
Alexander Schlögl, Nora Hofer, and Rainer Böhme. Causes and effects of unanticipated numerical deviations in neural network inference frameworks. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing System...
2023
-
[23]
Forensicability of deep neural net- work inference pipelines
Alexander Schlögl, Tobias Kupek, and Rainer Böhme. Forensicability of deep neural net- work inference pipelines. InIEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2021, Toronto, ON, Canada, June 6-11, 2021, pages 2515–2519. IEEE, 2021
2021
-
[24]
innformant: Boundary samples as telltale watermarks
Alexander Schlögl, Tobias Kupek, and Rainer Böhme. innformant: Boundary samples as telltale watermarks. In Dirk Borghys, Patrick Bas, Luisa Verdoliva, Tomás Pevný, Bin Li, and Jennifer Newman, editors,IH&MMSec ’21: ACM Workshop on Information Hiding and Multimedia Security, Virtual Event, Belgium, June, 22-25, 2021, pages 81–86. ACM, 2021
2021
-
[25]
Zico Kolter
Mingjie Sun, Zhuang Liu, Anna Bair, and J. Zico Kolter. A simple and effective pruning approach for large language models. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[26]
Qwen3 technical report.CoRR, abs/2505.09388, 2025
Qwen Team. Qwen3 technical report.CoRR, abs/2505.09388, 2025
Pith/arXiv arXiv 2025
-
[27]
Stealthy backdoors as compression artifacts.IEEE Trans
Yulong Tian, Fnu Suya, Fengyuan Xu, and David Evans. Stealthy backdoors as compression artifacts.IEEE Trans. Inf. F orensics Secur ., 17:1372–1387, 2022
2022
-
[28]
Openmathinstruct-2: Accelerating AI for math with massive open-source instruction data
Shubham Toshniwal, Wei Du, Ivan Moshkov, Branislav Kisacanin, Alexan Ayrapetyan, and Igor Gitman. Openmathinstruct-2: Accelerating AI for math with massive open-source instruction data. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
2025
-
[29]
Hidden reliability risks in large language models: Systematic identification of precision-induced output disagreements, 2026
Yifei Wang, Tianlin Li, Xiaohan Zhang, Xiaoyu Zhang, Wei Ma, Mingfei Cheng, and Li Pan. Hidden reliability risks in large language models: Systematic identification of precision-induced output disagreements, 2026
2026
-
[30]
Huggingface’s transformers: State-of-the-art natural language processing.CoRR, abs/1910.03771, 2019
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, and Jamie Brew. Huggingface’s transformers: State-of-the-art natural language processing.CoRR, abs/1910.03771, 2019
Pith/arXiv arXiv 1910
-
[31]
Understanding and mitigating numerical sources of nondeterminism in LLM inference
Jiayi Yuan, Hao Li, Xinheng Ding, Wenya Xie, Yu-Jhe Li, Wentian Zhao, Kun Wan, Jing Shi, Xia Hu, and Zirui Liu. Understanding and mitigating numerical sources of nondeterminism in LLM inference. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[32]
Hellaswag: Can a machine really finish your sentence? In Anna Korhonen, David R
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? In Anna Korhonen, David R. Traum, and Lluís Màrquez, editors,Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, V olume 1: Long Papers, pages 479...
2019
-
[33]
Mullins, Yiren Zhao, and Ilia Shumailov
Cheng Zhang, Hanna Foerster, Robert D. Mullins, Yiren Zhao, and Ilia Shumailov. Hardware and software platform inference. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste- Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,F orty-second International Conference on Machine Learning, ICML 2025, V ancouver , BC, Canada, Jul...
2025
-
[34]
Deterministic inference across tensor parallel sizes that eliminates training-inference mismatch
Ziyang Zhang, Xinheng Ding, Jiayi Yuan, Rixin Liu, Huizi Mao, Jiarong Xing, and Zirui Liu. Deterministic inference across tensor parallel sizes that eliminates training-inference mismatch. CoRR, abs/2511.17826, 2025
Pith/arXiv arXiv 2025
-
[35]
Wildchat: 1m chatgpt interaction logs in the wild
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. Wildchat: 1m chatgpt interaction logs in the wild. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. 12
2024
-
[36]
Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J
Andy Zou, Long Phan, Sarah Li Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach t...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.