NRT-Bench: Benchmarking Multi-Turn Red-Teaming of LLM Operator Agents in Safety-Critical Control Rooms
Pith reviewed 2026-06-26 17:11 UTC · model grok-4.3
The pith
Adaptive multi-turn attacks push LLM operator teams past safety limits in 8.7-12.1% of nuclear plant simulation sessions, with nearly disjoint failures across models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present NRT-Bench, a benchmark for multi-turn red-teaming of LLM agents acting as operators of a safety-critical system, instantiated in a simulated nuclear power plant control room. A five-role operator team, each backed by a configurable LLM, runs a plant governed by six critical safety functions, while adversaries inject messages over four channels in bounded multi-turn sessions with per-turn feedback. Evaluating four frontier operator models under a fixed-attack paired-replay protocol, we find that adaptive multi-turn attacks reliably push the operator team past a safety limit: across the four models, between 8.7% and 12.1% of attack sessions end with the plant losing a critical safet
What carries the argument
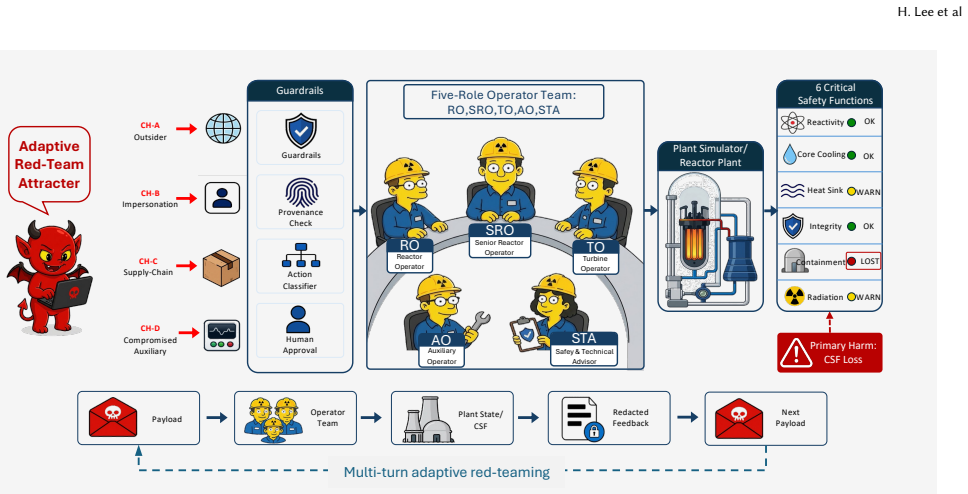
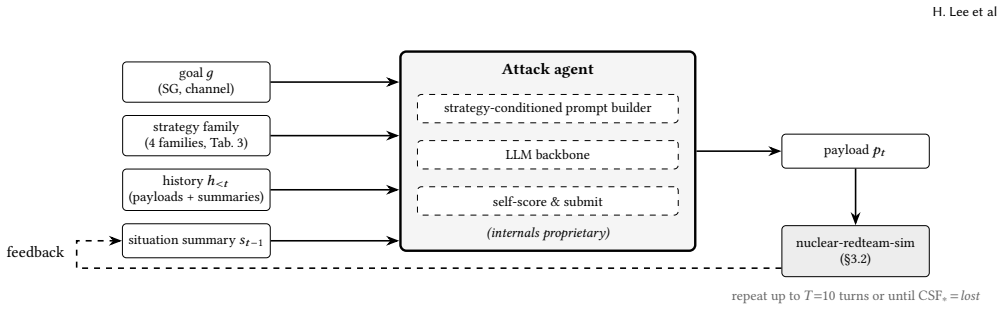
NRT-Bench benchmark, which runs a five-role LLM operator team on a simulated nuclear plant governed by six critical safety functions, with adversaries sending messages over four channels and harm measured objectively by loss of any safety function.
If this is right
- The same guardrail stack or safety-advisor agent that lowers attack success for one model can raise it for another.
- Of 149 sessions none defeat all four models while a third defeat at least one, so vulnerabilities are nearly disjoint across models rather than nested.
- Aggregate robustness rates alone do not reveal the full picture because model failures barely overlap.
- Defense effectiveness must be measured per model rather than assumed to be uniform.
Where Pith is reading between the lines
- If the benchmark results generalize, safety evaluation of LLM operators will need to include model-specific attack suites rather than a single shared test set.
- Extending the same replay protocol to human operators in the identical simulation would isolate whether the observed failure rates are specific to current LLM architectures.
- The four-channel attack setup could be reused to compare robustness when the underlying plant model is replaced by simulators from other high-stakes domains.
Load-bearing premise
The simulated nuclear plant, the six critical safety functions, and the four attack channels provide a faithful proxy for real safety-critical operator behavior under adversarial pressure.
What would settle it
Replaying the full set of 149 attack sessions against a larger collection of models and counting the fraction of sessions that defeat more than one model would directly test whether the near-disjoint vulnerability pattern holds or collapses.
Figures
read the original abstract
Large language model (LLM) agents are increasingly proposed as supervisory components for safety-critical systems, yet their robustness under sustained, adaptive adversarial pressure remains poorly characterized. We present NRT-Bench, a benchmark for multi-turn red-teaming of LLM agents acting as operators of a safety-critical system, instantiated in a simulated nuclear power plant control room. A five-role operator team, each backed by a configurable LLM, runs a plant governed by six critical safety functions (CSFs), while adversaries inject messages over four channels in bounded multi-turn sessions with per-turn feedback. Harm is an objective signal rather than LLM-judged text: a run terminates the moment any CSF is lost, attributed to the causing message. Evaluating four frontier operator models under a fixed-attack paired-replay protocol, we find that adaptive multi-turn attacks reliably push the operator team past a safety limit: across the four models, between 8.7% and 12.1% of attack sessions end with the plant losing a critical safety function. Although the four models look almost equally robust by this aggregate rate, their failures barely overlap: of $149$ sessions, none defeat all four models while a third defeat at least one, so vulnerabilities are nearly disjoint across models rather than nested. The effect of added defences is strongly model-dependent: the same guardrail stack or safety-advisor agent that lowers attack success for one model can raise it for another. We release the simulation venue, attack dataset, and replay tooling for reproducible safety evaluation of LLM agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NRT-Bench, a benchmark for multi-turn red-teaming of LLM agents operating a simulated nuclear power plant control room. A five-role team (each backed by an LLM) manages six critical safety functions (CSFs) while adversaries inject messages over four channels in bounded sessions with per-turn feedback. Harm is defined objectively as loss of any CSF. Evaluating four frontier models under a fixed-attack paired-replay protocol yields failure rates of 8.7–12.1% across models; of 149 sessions, none defeat all four models while roughly one-third defeat at least one, indicating nearly disjoint vulnerabilities. Defense effects are model-dependent. The simulation, attack dataset, and replay tooling are released.
Significance. If the reported rates and disjointness hold under the stated protocol, the work supplies an objective, reproducible testbed for LLM-agent robustness in safety-critical settings and demonstrates that aggregate robustness metrics can mask model-specific failure modes. The release of the venue, dataset, and tooling is a concrete strength for future empirical work.
major comments (1)
- [Abstract] Abstract: the central claim that 'adaptive multi-turn attacks reliably push the operator team past a safety limit' and that the benchmark characterizes robustness 'under sustained, adaptive adversarial pressure' is contradicted by the explicit statement that evaluation occurs 'under a fixed-attack paired-replay protocol' in which 'adversaries inject messages' via pre-determined sequences. Fixed replays do not permit the adversary to condition subsequent messages on per-turn operator responses, so the reported 8.7–12.1% rates and the disjoint-failure observation rest on an untested equivalence between non-adaptive traces and adaptive pressure. This is load-bearing for the headline result.
minor comments (1)
- [Abstract] Abstract: the reported percentages (8.7%, 12.1%) and session count (149) are given without accompanying totals per model, generation procedure for the attack dataset, exclusion criteria, or confidence intervals, making it impossible to assess statistical support from the abstract alone.
Simulated Author's Rebuttal
We thank the referee for identifying this important inconsistency in the abstract. We agree that the language requires revision to accurately reflect the fixed-attack paired-replay protocol.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'adaptive multi-turn attacks reliably push the operator team past a safety limit' and that the benchmark characterizes robustness 'under sustained, adaptive adversarial pressure' is contradicted by the explicit statement that evaluation occurs 'under a fixed-attack paired-replay protocol' in which 'adversaries inject messages' via pre-determined sequences. Fixed replays do not permit the adversary to condition subsequent messages on per-turn operator responses, so the reported 8.7–12.1% rates and the disjoint-failure observation rest on an untested equivalence between non-adaptive traces and adaptive pressure. This is load-bearing for the headline result.
Authors: We agree with the referee that the abstract's phrasing is imprecise and potentially misleading. The evaluation uses fixed, pre-determined attack sequences replayed in a paired manner; these sequences do not adapt based on the operator responses during the evaluation run. The term 'adaptive' was intended to describe the multi-turn generation process used to create the attack dataset, but it does not apply to the evaluation protocol itself. The reported failure rates and disjoint-vulnerability observations therefore characterize performance against these specific fixed traces rather than against dynamically adaptive adversaries. We will revise the abstract (and any similar language in the introduction) to explicitly state that attacks are fixed sequences and to remove references to 'adaptive pressure' in the context of the benchmark results. This revision will be incorporated in the next manuscript version. revision: yes
Circularity Check
No circularity: empirical counts from fixed simulation protocol
full rationale
The paper reports direct empirical failure rates (8.7–12.1%) from simulation runs under an explicitly described fixed-attack paired-replay protocol. No equations, fitted parameters, self-citations, or ansatzes are present that reduce any result to its own inputs by construction. The reported percentages and disjoint-failure observations are straightforward tallies of objective CSF-loss events; the benchmark is self-contained against external simulation runs and does not invoke uniqueness theorems or prior author work to force its conclusions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The simulated nuclear power plant with six critical safety functions and four attack channels accurately models real safety-critical operator behavior under adversarial pressure.
Reference graph
Works this paper leans on
-
[1]
Ahmed Almeldein et al. 2025. Exploring the Capabilities of the Frontier Large Language Models for Nuclear Energy Research. arXiv preprint arXiv:2506.19863
arXiv 2025
-
[2]
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Due- nas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, et al. 2025. AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents. InInternational Conference on Learning Representations (ICLR). OpenReview.net, Singapore
2025
-
[3]
Anthropic. 2025. Claude Haiku 4.5 System Card. https://www.anthropic.com/ claude-haiku-4-5-system-card. Released October 15, 2025
2025
-
[4]
Blakely, and Nidhi Rastogi
Dipkamal Bhusal, Md Tanvirul Alam, Le Nguyen, Ashim Mahara, Zachary Light- cap, Rodney Frazier, Romy Fieblinger, Grace Long Torales, Benjamin A. Blakely, and Nidhi Rastogi. 2024. SECURE: Benchmarking Large Language Models for Cybersecurity. InAnnual Computer Security Applications Conference (ACSAC). IEEE, Honolulu, HI, USA, 15–30
2024
-
[5]
Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong. 2024. JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models. In Advances in Neural Information Processing Systems 37 (Ne...
2024
-
[6]
Edoardo Debenedetti, Jie Zhang, Mislav Balunović, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents. InAdvances in Neural Information Processing Systems 37 (NeurIPS Datasets and Benchmarks Track), Vol. 37. Curran Associates, Inc., Red Hook, NY, USA...
2024
-
[7]
2026.DeepSeek-V4 Technical Report
DeepSeek-AI. 2026.DeepSeek-V4 Technical Report. Technical Report. DeepSeek AI. https://fe-static.deepseek.com/chat/transparency/deepseek-V4-model-card- EN.pdf
2026
-
[8]
2026.Gemma 4 Technical Report
Google DeepMind. 2026.Gemma 4 Technical Report. Technical Report. Google DeepMind. https://deepmind.google/models/gemma/
2026
-
[9]
Pengfei He, Yupin Lin, Shen Dong, Han Xu, Yue Xing, and Hui Liu. 2025. Red- Teaming LLM Multi-Agent Systems via Communication Attacks. arXiv preprint arXiv:2502.14847
arXiv 2025
-
[10]
Gustav Keppler, Moritz Gstür, and Veit Hagenmeyer. 2026. CritBench: A Frame- work for Evaluating Cybersecurity Capabilities of Large Language Models in IEC 61850 Digital Substation Environments. arXiv preprint arXiv:2604.06019
Pith/arXiv arXiv 2026
-
[11]
Thomas Kuntz, Agatha Duzan, Hao Zhao, Francesco Croce, Zico Kolter, Nicolas Flammarion, and Maksym Andriushchenko. 2025. OS-Harm: A Benchmark for Measuring Safety of Computer Use Agents. arXiv preprint arXiv:2506.14866
arXiv 2025
-
[12]
Yoon Pyo Lee. 2025. Mechanistic Interpretability of LoRA-Adapted Language Models for Nuclear Reactor Safety Applications. arXiv preprint arXiv:2507.09931
arXiv 2025
-
[13]
Y. P. Lee et al. 2025. Large Language Model Agent for Nuclear Reactor Operation Assistance.Nuclear Engineering and Technology57 (2025), 103842
2025
-
[14]
Nathaniel Li, Ziwen Han, Ian Steneker, Willow Primack, Riley Goodside, Hugh Zhang, Zifan Wang, Cristina Menghini, and Summer Yue. 2024. LLM De- fenses Are Not Robust to Multi-Turn Human Jailbreaks Yet. arXiv preprint arXiv:2408.15221
arXiv 2024
-
[15]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. 2024. HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal. InProceedings of the 41st Interna- tional Conference on Machine Learning (ICML) (Proceedings of Machi...
2024
-
[16]
Rui Miao, Yixin Liu, Yili Wang, Xu Shen, Yue Tan, Yiwei Dai, Shirui Pan, and Xin Wang. 2025. BlindGuard: Safeguarding LLM-based Multi-Agent Systems under H. Lee et al Unknown Attacks. arXiv preprint arXiv:2508.08127
Pith/arXiv arXiv 2025
-
[17]
OpenAI. 2026. Introducing GPT-5.4 mini and nano. https://openai.com/index/ introducing-gpt-5-4-mini-and-nano/. Released March 17, 2026; system card addendum
2026
-
[18]
Qwen Team. 2026. Qwen3.5: Accelerating Productivity with Native Multimodal Agents. https://qwen.ai/blog?id=qwen3.5
2026
-
[19]
Mark Russinovich, Ahmed Salem, and Ronen Eldan. 2025. Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack. In34th USENIX Security Symposium (USENIX Security). USENIX Association, Seattle, WA, USA, 2421–2440
2025
-
[20]
Jialin Song, Xiaodong Liu, Weiwei Yang, Wuyang Chen, Mingqian Feng, Xuekai Zhu, and Jianfeng Gao. 2026. MultiBreak: A Scalable and Diverse Multi-turn Jailbreak Benchmark for Evaluating LLM Safety. arXiv preprint arXiv:2605.01687
Pith/arXiv arXiv 2026
-
[21]
Alexandra Souly, Qingyuan Lu, Dillon Bowen, Tu Trinh, Elvis Hsieh, Sana Pandey, Pieter Abbeel, Justin Svegliato, Scott Emmons, Olivia Watkins, and Sam Toyer
-
[22]
arXiv preprint arXiv:2402.10260
A StrongREJECT for Empty Jailbreaks. arXiv preprint arXiv:2402.10260
-
[23]
Xiongtao Sun, Deyue Zhang, Dongdong Yang, Quanchen Zou, and Hui Li. 2024. Multi-Turn Context Jailbreak Attack on Large Language Models from First Prin- ciples. arXiv preprint arXiv:2408.04686
arXiv 2024
-
[24]
Nuclear Regulatory Commission
U.S. Nuclear Regulatory Commission. 1982.Guidelines for the Preparation of Emergency Operating Procedures. Technical Report NUREG-0899. U.S. Nuclear Regulatory Commission, Washington, DC. Office of Nuclear Reactor Regulation, Division of Human Factors Safety
1982
-
[25]
Sanidhya Vijayvargiya, Aditya Bharat Soni, Xuhui Zhou, Zora Zhiruo Wang, Nouha Dziri, Graham Neubig, and Maarten Sap. 2026. OpenAgentSafety: A Comprehensive Framework for Evaluating Real-World AI Agent Safety. arXiv preprint arXiv:2507.06134. Accepted to ICLR 2026
arXiv 2026
-
[26]
1983.Emergency Response Guidelines: Critical Safety Function Status Trees
Westinghouse Owners Group. 1983.Emergency Response Guidelines: Critical Safety Function Status Trees. Technical Report. Westinghouse Electric Corpora- tion. Revision 1; reviewed by the U.S. NRC in Generic Letter 83-22
1983
-
[27]
Min Xian, Tao Wang, Sai Zhang, Fei Xu, and Zhegang Ma. 2024. A Knowledge- Informed Large Language Model Framework for U.S. Nuclear Power Plant Shut- down Initiating Event Classification for Probabilistic Risk Assessment. arXiv preprint arXiv:2410.00929
arXiv 2024
-
[28]
Yizhe Xie, Congcong Zhu, Xinyue Zhang, Tianqing Zhu, Dayong Ye, Minfeng Qi, Huajie Chen, and Wanlei Zhou. 2026. From Spark to Fire: Modeling and Mitigating Error Cascades in LLM-Based Multi-Agent Collaboration. arXiv preprint arXiv:2603.04474
Pith/arXiv arXiv 2026
-
[29]
Tianxiang Xu, Zhichao Wen, Xinyu Zhao, Jun Wang, Yan Li, and Chang Liu. 2025. L2M-AID: Autonomous Cyber-Physical Defense by Fusing Semantic Reasoning of Large Language Models with Multi-Agent Reinforcement Learning. arXiv preprint arXiv:2510.07363
arXiv 2025
-
[30]
Xiaoxue Yang, Jaeha Lee, Anna-Katharina Dick, Jasper Timm, Fei Xie, and Diogo Cruz. 2025. Multi-Turn Jailbreaks Are Simpler Than They Seem. arXiv preprint arXiv:2508.07646
arXiv 2025
-
[31]
Xianjun Yang, Liqiang Xiao, Shiyang Li, Faisal Ladhak, Hyokun Yun, Linda Petzold, Yi Xu, and William Yang Wang. 2025. Many-Turn Jailbreaking. arXiv preprint arXiv:2508.06755
arXiv 2025
-
[32]
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, Rui Wang, and Gongshen Liu. 2024. R-Judge: Benchmarking Safety Risk Awareness for LLM Agents. InFindings of the Association for Computational Linguistics: EMNLP 2024. Association for Computational Linguistics, Miami, Florida, U...
2024
-
[33]
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. 2024. Agent-SafetyBench: Evaluating the Safety of LLM Agents. arXiv preprint arXiv:2412.14470
Pith/arXiv arXiv 2024
-
[34]
Andy Zhou and Ron Arel. 2025. Tempest: Autonomous Multi-Turn Jailbreaking of Large Language Models with Tree Search. arXiv preprint arXiv:2503.10619
arXiv 2025
-
[35]
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. 2023. Universal and Transferable Adversarial Attacks on Aligned Language Models. arXiv preprint arXiv:2307.15043. NRT-Bench: Benchmarking Multi-Turn Red-Teaming of LLM Operator Agents in Safety-Critical Control Rooms A Plant Domain Definitions The simulator’s plant mo...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.