Probe-and-Refine Tuning of Repository Guidance for Coding Agents
Pith reviewed 2026-06-26 15:56 UTC · model grok-4.3
The pith
Probe-and-refine tuning raises coding agent resolve rates on repositories by refining guidance files with synthetic probes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
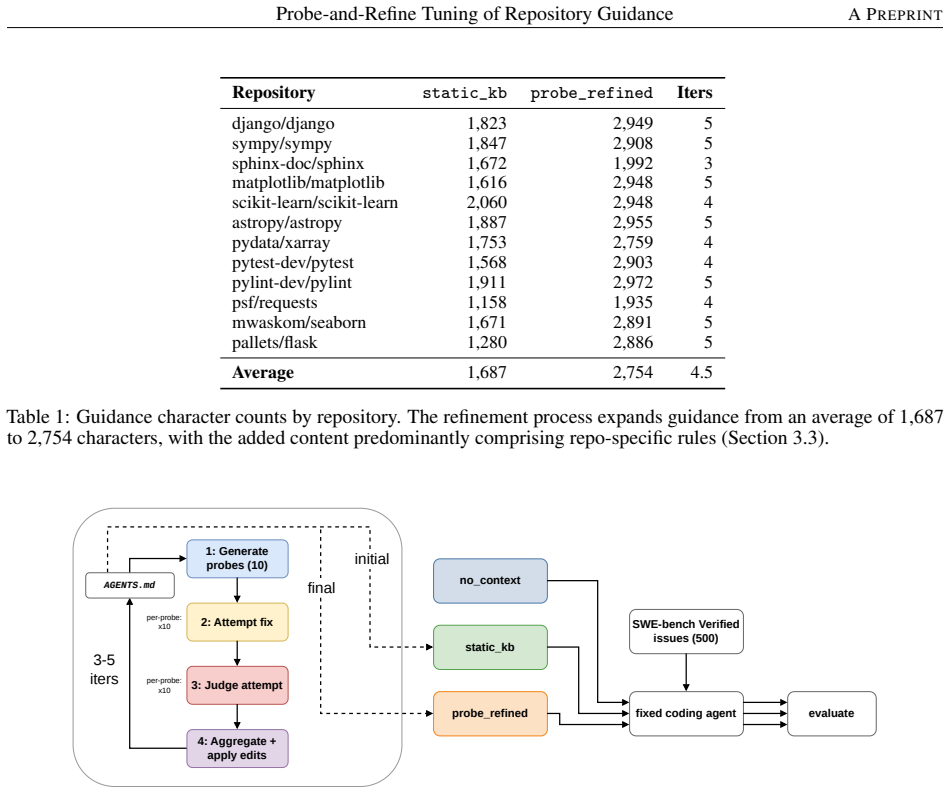
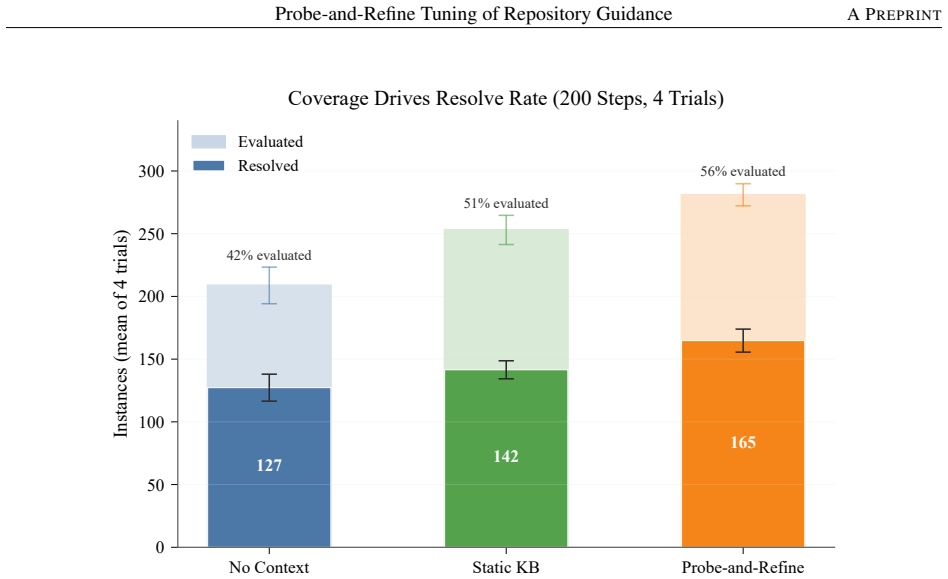
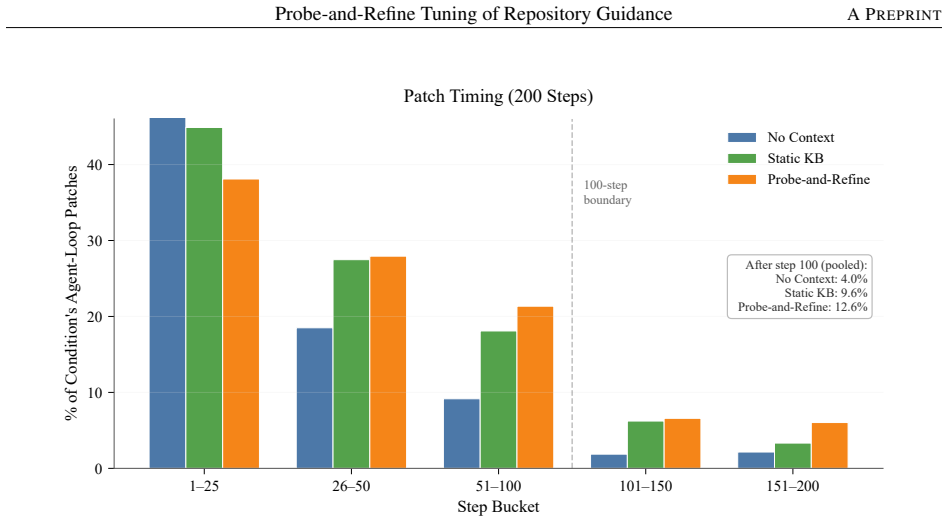
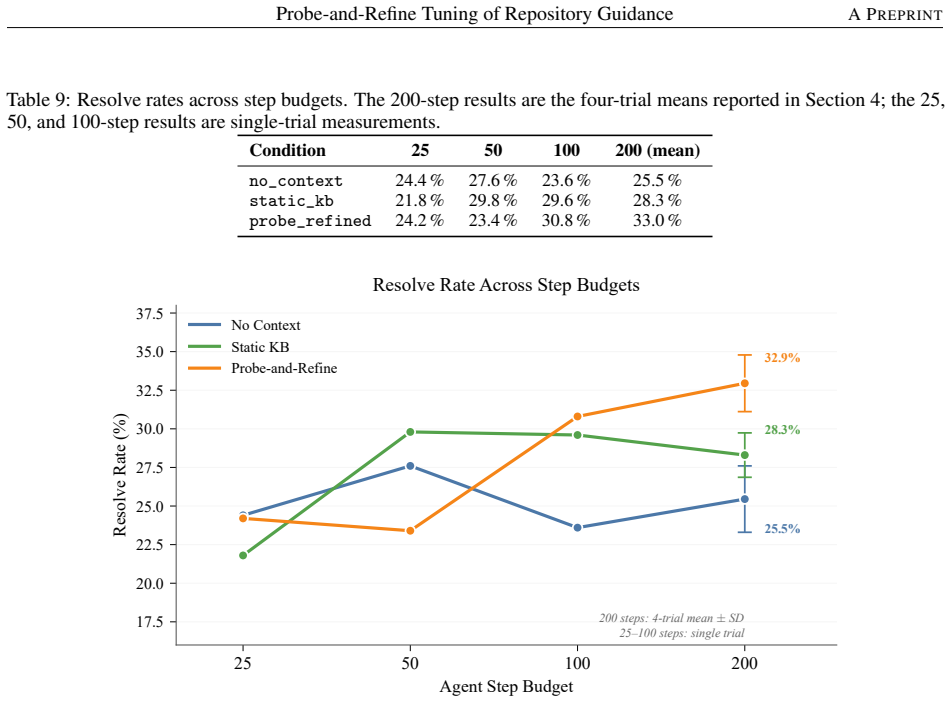
Probe-and-refine tuning uses synthetic bug-fix probes to iteratively diagnose and patch a repository's guidance file through single-shot LLM calls with no agent loop or tool use during tuning. On SWE-bench Verified across four independent trials with Qwen3.5-35B-A3B at 200 steps, it achieves 33.0 percent mean resolve rate versus 28.3 percent for the static knowledge base used to initialize it and 25.5 percent for an unguided baseline. The improvement comes from coverage rather than precision: refined guidance produces evaluable patches for 14.5 percentage points more instances while per-patch precision remains statistically constant at approximately 59 percent.
What carries the argument
The probe-and-refine tuning procedure that diagnoses gaps in a repository guidance file using synthetic bug-fix probes and updates the file through single-shot LLM calls.
If this is right
- Guidance produced by the method lets agents make productive use of larger step budgets.
- The tuning loop degrades when the model cannot generate sufficiently diagnostic output about guidance gaps.
- Per-patch precision remains constant even when the tuning process itself degrades.
- Refined guidance primarily increases the number of problems for which the agent reaches the correct file.
Where Pith is reading between the lines
- The method could start from minimal or empty guidance files on repositories that lack any AGENTS.md.
- It may scale to larger or private codebases because tuning avoids running full agent trajectories.
- Cross-model results suggest that the diagnostic quality of the tuning model is the main limit on further gains.
Load-bearing premise
Synthetic bug-fix probes generated by the same LLM family are representative enough of real repository issues for the tuning model to diagnose and correct guidance gaps.
What would settle it
Applying probe-and-refine to SWE-bench Verified and finding no statistically significant rise in the fraction of instances that receive evaluable patches.
Figures

read the original abstract
LLM-based coding agents need higher-level operational knowledge about a repository (which files house which subsystems, how to run the test suite, which workflows have historically led to wrong fixes) that does not exist in the code itself. Engineers typically maintain AGENTS.md files to supply this context as instructions for coding agents, but whether they help is contested: recent studies disagree on whether LLM-generated guidance improves or harms agent performance. In this paper we show that how the guidance is produced is the decisive variable, and introduce probe-and-refine tuning: a procedure that uses synthetic bug-fix probes to iteratively diagnose and patch a repository's guidance file through single-shot LLM calls, with no agent loop or tool use during tuning. On SWE-bench Verified across four independent trials with Qwen3.5-35B-A3B at 200 steps, probe-and-refine achieves 33.0% mean resolve rate vs. 28.3% for the static knowledge base used to initialize it and 25.5% for an unguided baseline (p < 0.001 for both probe-and-refine contrasts). The improvement comes from coverage rather than precision: refined guidance produces evaluable patches for 14.5 percentage points (pp) more instances while per-patch precision remains statistically constant (~59%, p = 0.119), showing that improved guidance helps agents reach the correct file rather than improving the quality of the changes they make. Further, a step-budget experiment shows that guidance is what lets the agent use a larger step budget productively, and a cross-model experiment with NVIDIA-Nemotron-3-Nano-30B-A3B finds that the tuning loop degrades when the model cannot generate sufficiently diagnostic output, though per-patch precision remains constant even then.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces probe-and-refine tuning, a procedure that iteratively diagnoses and patches repository guidance files (e.g., AGENTS.md) using synthetic bug-fix probes via single-shot LLM calls, without any agent loop or tool use during tuning. On SWE-bench Verified across four independent trials with Qwen3.5-35B-A3B at 200 steps, it reports a mean resolve rate of 33.0% versus 28.3% for the static knowledge base initializer and 25.5% for an unguided baseline (p < 0.001 for both contrasts). The lift is attributed to improved coverage (14.5pp more evaluable patches) while per-patch precision remains statistically unchanged (~59%, p = 0.119). Additional experiments examine step-budget utilization and cross-model behavior with NVIDIA-Nemotron-3-Nano-30B-A3B.
Significance. If the empirical result holds, the work supplies a low-overhead method for improving repository guidance that demonstrably increases coverage without altering per-patch precision, and shows that better guidance enables productive use of larger step budgets. Credit is due for the multi-trial design with reported p-values, the explicit coverage-vs-precision breakdown, and the boundary-condition experiment on model diagnostic capability. These elements make the central performance claim more falsifiable than typical single-run agent evaluations.
major comments (2)
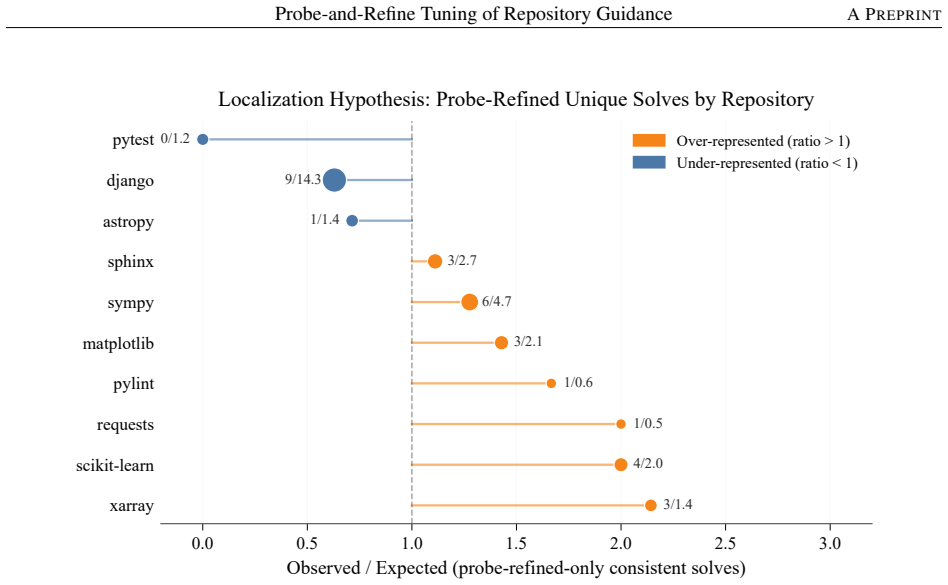
- [Probe generation and results paragraphs] The claim that the 4.7pp resolve-rate improvement (33.0% vs 28.3%) arises from refined guidance that generalizes to real SWE-bench Verified tasks depends on synthetic probes being representative of actual bug distributions. No quantitative comparison is provided of probe file locations, multi-file complexity, or error categories against the test distribution (see the probe-generation description and the results paragraph reporting the coverage gain).
- [Methods and experimental setup] The reported mean rates, p-values, and coverage-vs-precision breakdown cannot be fully verified because the text omits full methods details: exact prompts and sampling parameters for probe generation, how the four trials were made independent, dataset splits between tuning probes and evaluation, and any error analysis of failed probes.
minor comments (2)
- [Abstract and model descriptions] The abstract and results text use 'A3B' in model names without defining the suffix or its relation to model architecture.
- [Step-budget experiment paragraph] The step-budget experiment is mentioned but lacks a figure or table reference in the provided text, making it difficult to assess how guidance interacts with step count.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the manuscript's claims and reproducibility. We address each major comment below and will revise accordingly.
read point-by-point responses
-
Referee: [Probe generation and results paragraphs] The claim that the 4.7pp resolve-rate improvement (33.0% vs 28.3%) arises from refined guidance that generalizes to real SWE-bench Verified tasks depends on synthetic probes being representative of actual bug distributions. No quantitative comparison is provided of probe file locations, multi-file complexity, or error categories against the test distribution (see the probe-generation description and the results paragraph reporting the coverage gain).
Authors: We agree that a quantitative comparison of probe characteristics to the test distribution would make the generalization argument more robust. The current manuscript relies on the empirical lift observed on held-out real tasks as evidence of utility, but does not include such a distributional analysis. In the revised manuscript we will add a dedicated subsection (with accompanying table) that reports file-location overlap, multi-file complexity statistics, and error-category distributions for the synthetic probes versus the SWE-bench Verified test set, using appropriate overlap metrics and statistical tests. revision: yes
-
Referee: [Methods and experimental setup] The reported mean rates, p-values, and coverage-vs-precision breakdown cannot be fully verified because the text omits full methods details: exact prompts and sampling parameters for probe generation, how the four trials were made independent, dataset splits between tuning probes and evaluation, and any error analysis of failed probes.
Authors: We acknowledge that the submitted manuscript does not supply the level of methodological detail required for full verification. The four trials used distinct random seeds for both probe generation and downstream evaluation; probes were generated from the repository without using any evaluation-task instances. In the revision we will expand the Methods section and add an appendix containing the exact prompts, sampling parameters (temperature, top-p, max tokens), a precise description of trial independence and dataset splits, and a brief error analysis of any probes that failed to produce usable diagnostic output. revision: yes
Circularity Check
No circularity: empirical benchmark results independent of internal definitions
full rationale
The paper reports direct empirical measurements of resolve rates on the external SWE-bench Verified benchmark across multiple trials and models. The 33.0% vs 28.3% contrast is a measured outcome of running the tuned guidance on real tasks, not a quantity derived by construction from fitted parameters, self-citations, or renamed inputs. No equations, uniqueness theorems, or ansatzes are present that reduce the central claim to the tuning procedure itself. The method uses synthetic probes for tuning but evaluates on held-out real tasks, keeping the reported lift falsifiable and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SWE-bench Verified
SWE-bench. SWE-bench Verified. 2024.https://www.swebench.com/verified.html. Carlos E. Jimenez et al. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?ICLR,
2024
-
[2]
Qwen3.5-35B-A3B
Qwen Team. Qwen3.5-35B-A3B. 2026.https://huggingface.co/Qwen/Qwen3.5-35B-A3B. Jai Lal Lulla et al. On the Impact of AGENTS.md Files on the Efficiency of AI Coding Agents.ICSE JAWs,
2026
-
[3]
arXiv:2601.20404. Thibaud Gloaguen et al. Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents? arXiv:2602.11988,
-
[4]
Agentless: Demystifying LLM-based Software Engineering Agents
Chunqiu Steven Xia et al. Agentless: Demystifying LLM-based Software Engineering Agents.arXiv:2407.01489,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv:2410.14684. Yuntong Zhang et al. AutoCodeRover: Autonomous Program Improvement.ISSTA,
-
[6]
Worawalan Chatlatanagulchai et al. Agent READMEs: An Empirical Study of Context Files for Agentic Coding. arXiv:2511.12884,
-
[7]
Codified Context: Infrastructure for AI Agents in a Complex Codebase.arXiv:2602.20478,
Aristidis Vasilopoulos. Codified Context: Infrastructure for AI Agents in a Complex Codebase.arXiv:2602.20478,
-
[8]
SWE Context Bench: A Benchmark for Context Learning in Coding
Jared Zhu et al. SWE Context Bench: A Benchmark for Context Learning in Coding.arXiv:2602.08316,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Meta Context Engineering via Agentic Skill Evolution.arXiv:2601.21557,
Haoran Ye et al. Meta Context Engineering via Agentic Skill Evolution.arXiv:2601.21557,
-
[10]
arXiv preprint arXiv:2502.17424 , year =
Jan Betley et al. Emergent Misalignment: Narrow Finetuning Can Produce Broadly Misaligned LLMs. arXiv:2502.17424,
-
[11]
Jan Betley et al. Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs.arXiv:2512.09742,
- [12]
-
[13]
Dietterich
Thomas G. Dietterich. Approximate Statistical Tests for Comparing Supervised Classification Learning Algorithms. Neural Computation, 10(7):1895–1923,
1923
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.