Massive Activations Are Architecturally Robust: A Controlled Scratch/Commitment Residual Stream Test
Pith reviewed 2026-06-26 20:45 UTC · model grok-4.3
The pith
Massive activations re-emerge inside the protected decode-only stream even after splitting the residual stream.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
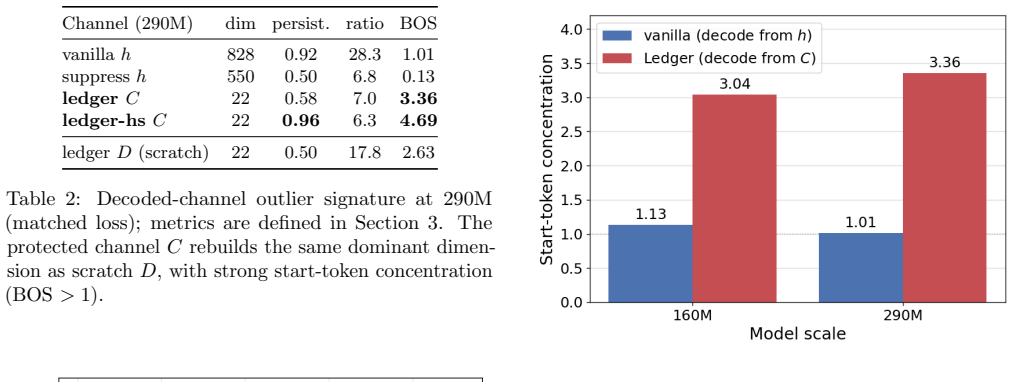
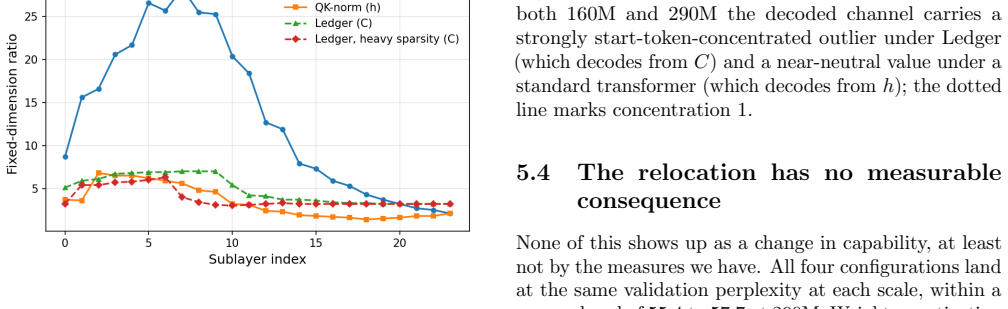
By introducing Ledger Residuals that split the residual stream into a mutable scratch stream (Deliberation) and a protected decode-only accumulator (Commitment), the model still develops the canonical massive activation in the commitment channel at 160M and 290M scales. The rebuilt feature is smaller in magnitude than in a standard transformer but more sharply concentrated on the start token, and a stronger sparsity penalty makes it more persistent and more concentrated still, rather than removing it.
What carries the argument
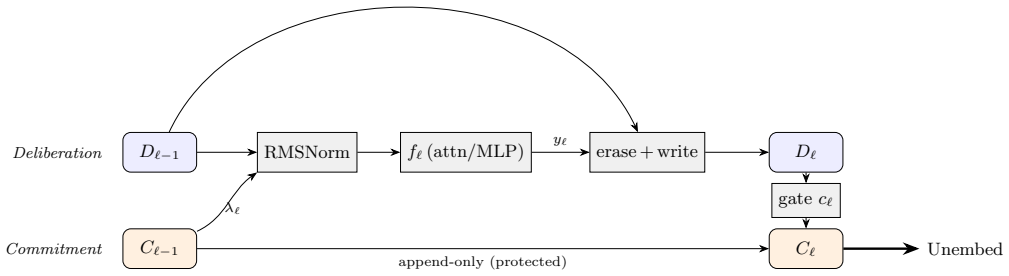
Ledger Residuals architecture, which splits the residual stream into a mutable scratch stream (Deliberation) and a protected, decode-only accumulator (Commitment) that holds the representation used for decoding.
If this is right
- Massive activations re-emerge in whichever representation the model decodes from.
- The rebuilt activation is smaller in magnitude but more sharply concentrated on the start token than in standard transformers.
- Increasing the strength of a sparsity penalty increases persistence and concentration of the activation rather than eliminating it.
Where Pith is reading between the lines
- The result implies that any successful removal of massive activations will likely require changes to training objectives or initialization rather than further isolation of the decode channel.
- The same split could be applied to test whether other known transformer outliers, such as those appearing in attention scores, also reappear when separated from mutable computation.
Load-bearing premise
The Ledger Residuals split cleanly separates mutable computation from the decode-only representation without introducing confounding changes to training dynamics or loss landscape that could independently drive the re-emergence of outliers.
What would settle it
Training a Ledger Residuals model to matched loss while observing no massive activation inside the Commitment channel would falsify the claim of architectural robustness.
Figures
read the original abstract
Trained transformers reliably develop massive activations, a small number of hidden dimensions whose magnitude is far above the median and which concentrate on the sequence-start token. Whether these outliers are a removable artifact of the residual stream's overloaded read and write role, or instead a functional necessity, is actively debated. We test the artifact hypothesis directly, with an architectural intervention. Our architecture, Ledger Residuals, splits the residual stream into a mutable scratch stream (Deliberation) that intermediate computation may freely overwrite and a protected, decode-only accumulator (Commitment) that holds the representation the model reads out. If massive activations exist only because one stream is forced to be both scratchpad and answer, then a dedicated answer channel should remove the need for them. We find that it does not. In matched-loss language models at the 160M and 290M scales, the model rebuilds the canonical fixed-dimension, start-token outlier inside the protected channel. The rebuilt feature is smaller in magnitude than in a standard transformer but more sharply concentrated on the start token, and a stronger sparsity penalty makes it more persistent and more concentrated still, rather than removing it. Massive activations therefore look architecturally robust: they re-emerge in whichever representation the model decodes from, which is what we would expect if they are functional rather than incidental. We release our architecture and measurement code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Ledger Residuals, an architecture that splits the residual stream into a mutable Deliberation scratch stream and a protected Commitment accumulator used only for decoding. In loss-matched transformer language models trained at 160M and 290M scales (plus a sparsity ablation), massive activations re-emerge inside the Commitment stream; the re-emerged feature is smaller in magnitude than in a baseline transformer but more sharply concentrated on the start token, and stronger sparsity makes the feature more persistent rather than eliminating it. The authors conclude that massive activations are architecturally robust and therefore likely functional rather than an artifact of an overloaded residual stream.
Significance. If the central empirical result survives tighter controls on training dynamics, the work would supply direct architectural evidence against the artifact hypothesis for massive activations and would support the view that they play a necessary role in the model's computation. The public release of the architecture implementation and measurement code is a clear strength that enables direct replication and extension.
major comments (2)
- [Methods / Experimental Setup] Methods / Experimental Setup: the claim that loss-matching at 160M/290M scales isolates the effect of the Deliberation/Commitment split is under-supported. The architectural change necessarily alters residual addition, layer inputs/outputs, and gradient pathways; reporting only final loss equivalence does not demonstrate that optimization landscapes or capacity utilization remain comparable. This is load-bearing for the central claim that re-emergence in Commitment demonstrates functional necessity rather than an artifact of the intervention itself.
- [Results] Results (sparsity ablation): the statement that a stronger sparsity penalty makes the start-token outlier 'more persistent and more concentrated still' requires quantitative support (effect sizes, concentration metrics, and statistical tests across runs) to be load-bearing; without these, the ablation cannot reliably distinguish functional necessity from a side-effect of the modified training dynamics.
minor comments (2)
- The manuscript should include an explicit repository link or citation for the released code and measurement scripts in the main text rather than only in the abstract.
- Notation for the two streams (Deliberation vs. Commitment) and the precise definition of 'massive activation' (threshold, dimension count, start-token focus) should be introduced with a single equation or table early in the paper for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on experimental controls and the need for quantitative rigor in the sparsity ablation. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Methods / Experimental Setup] Methods / Experimental Setup: the claim that loss-matching at 160M/290M scales isolates the effect of the Deliberation/Commitment split is under-supported. The architectural change necessarily alters residual addition, layer inputs/outputs, and gradient pathways; reporting only final loss equivalence does not demonstrate that optimization landscapes or capacity utilization remain comparable. This is load-bearing for the central claim that re-emergence in Commitment demonstrates functional necessity rather than an artifact of the intervention itself.
Authors: We agree that equivalence of final validation loss alone does not fully establish that optimization landscapes or capacity utilization are comparable, given the changes to residual addition and gradient pathways introduced by the split. Our control consists of tuning hyperparameters at each scale until the models reach matched loss; the consistent re-emergence of the start-token outlier inside the protected Commitment stream (which cannot serve as a mutable scratchpad) nevertheless provides evidence against a pure overload artifact. To strengthen the isolation claim, we will add training curves, per-layer gradient norm statistics, and activation magnitude trajectories during training to the revised Methods and Appendix. revision: partial
-
Referee: [Results] Results (sparsity ablation): the statement that a stronger sparsity penalty makes the start-token outlier 'more persistent and more concentrated still' requires quantitative support (effect sizes, concentration metrics, and statistical tests across runs) to be load-bearing; without these, the ablation cannot reliably distinguish functional necessity from a side-effect of the modified training dynamics.
Authors: We acknowledge that the current text describes the sparsity effect qualitatively from the reported figures without accompanying effect sizes, concentration metrics, or multi-run statistics. In the revision we will supply explicit metrics (maximum-to-median activation ratio, fraction of activation mass on the start token), report results from at least three independent runs per condition, and include statistical comparisons to support the claim that stronger sparsity increases persistence and concentration rather than eliminating the feature. revision: yes
Circularity Check
No circularity: empirical architecture intervention with no derivations or self-referential fits
full rationale
The paper presents an empirical test via a new architecture (Ledger Residuals) that splits residual streams, trains matched-loss models at fixed scales, and measures re-emergence of outliers. No equations, parameter fits, or predictions are defined in terms of the target outcome. The central claim rests on observed behavior under controlled intervention rather than any reduction to fitted inputs or self-cited uniqueness theorems. Self-citations, if present, are not load-bearing for the result. This matches the default non-circular case for empirical architecture papers.
Axiom & Free-Parameter Ledger
free parameters (2)
- model scale
- sparsity penalty strength
axioms (2)
- domain assumption Massive activations concentrate on the sequence-start token in standard transformers
- domain assumption Loss-matched training produces comparable models across architectures
invented entities (1)
-
Ledger Residuals (Deliberation scratch stream + Commitment accumulator)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
M. Sun, X. Chen, J. Z. Kolter, Z. Liu. 2024. Mas- sive Activations in Large Language Models.COLM. arXiv:2402.17762
Pith/arXiv arXiv 2024
-
[2]
G. Xiao, Y. Tian, B. Chen, S. Han, M. Lewis. 2024. Efficient Streaming Language Models with Attention Sinks.ICLR. arXiv:2309.17453
Pith/arXiv arXiv 2024
-
[3]
S. Sun, A. Canziani, Y. LeCun, J. Zhu. 2026. The Spike, the Sparse and the Sink: Anatomy of Massive Activations and Attention Sinks. arXiv:2603.05498
arXiv 2026
- [4]
-
[5]
Elhage et al
N. Elhage et al. 2021. A Mathematical Framework for Transformer Circuits.Transformer Circuits Thread
2021
- [6]
-
[7]
Y. Zhang, Y. Liu, M. Wang, Q. Gu. 2026. Deep Delta Learning. arXiv:2601.00417
Pith/arXiv arXiv 2026
-
[8]
F. Barbero et al. 2025. Why Do LLMs Attend to the First Token?COLM. arXiv:2504.02732
arXiv 2025
-
[9]
Y. Bondarenko, M. Nagel, T. Blankevoort. 2023. Quan- tizable Transformers: Removing Outliers by Helping At- tention Heads Do Nothing.NeurIPS. arXiv:2306.12929
arXiv 2023
-
[10]
Y. Chen, Z. Lin, Q. Yao. 2026. Attention Sinks Induce Gradient Sinks: Massive Activations as Gradient Regu- lators in Transformers. arXiv:2603.17771
Pith/arXiv arXiv 2026
-
[11]
X. Gu et al. 2025. When Attention Sink Emerges in Language Models: An Empirical View.ICLR. arXiv:2410.10781
Pith/arXiv arXiv 2025
-
[12]
J. C. Kerce, A. Fox. 2026. The Dual-Stream Transformer: Channelized Architecture for Interpretable Language Modeling. arXiv:2603.07461
arXiv 2026
-
[13]
P. Kaul, C. Ma, I. Elezi, J. Deng. 2024. From Attention to Activation. arXiv:2410.17174
arXiv 2024
-
[14]
Y. Ran-Milo. 2026. Attention Sinks Are Provably Neces- sary in Softmax Transformers: Evidence from Trigger- Conditional Tasks. arXiv:2603.11487
Pith/arXiv arXiv 2026
-
[15]
Darcet, M
T. Darcet, M. Oquab, J. Mairal, P. Bojanowski
- [16]
-
[17]
Kovaleva, S
O. Kovaleva, S. Kulshreshtha, A. Rogers, A. Rumshisky
-
[18]
BERT Busters: Outlier Dimensions that Disrupt Transformers.Findings of ACL-IJCNLP. arXiv:2105.06990
- [19]
-
[20]
Puccetti, A
G. Puccetti, A. Rogers, A. Drozd, F. Dell’Orletta
-
[21]
Outlier Dimensions that Disrupt Transform- ers Are Driven by Frequency.Findings of EMNLP. arXiv:2205.11380. 6
-
[22]
T. Dettmers, M. Lewis, Y. Belkada, L. Zettlemoyer. 2022. LLM.int8(): 8-bit Matrix Multiplication for Transform- ers at Scale.NeurIPS. arXiv:2208.07339. 7
Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.