Recognition: 2 theorem links
· Lean TheoremAttention Sinks Induce Gradient Sinks: Massive Activations as Gradient Regulators in Transformers
Pith reviewed 2026-05-15 09:30 UTC · model grok-4.3
The pith
Under causal masking, attention sinks induce gradient sinks that massive activations regulate via RMSNorm in Transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
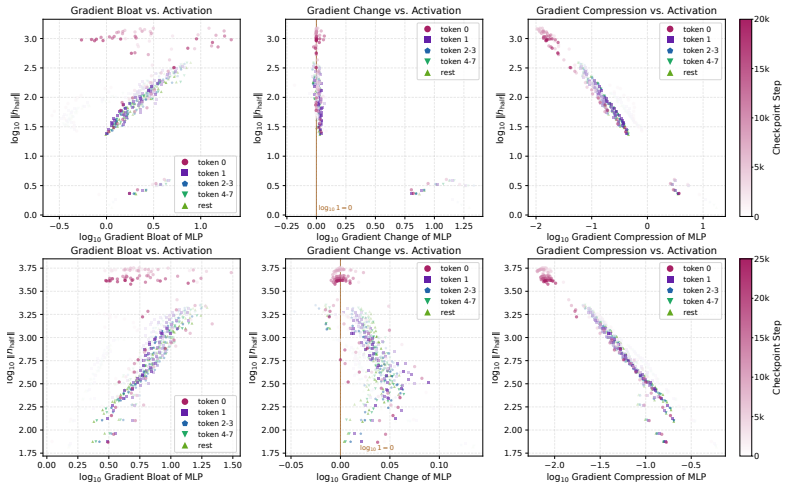
Attention sinks under causal masking induce gradient sinks. Massive activations serve as adaptive regulators of this localized gradient pressure because the RMSNorm Jacobian attenuates gradients roughly in inverse proportion to input norm. Modifying the value-path gradient with V-scale suppresses massive activations while preserving attention sinks, identifying massive activations as an RMSNorm-mediated response to gradient sinks.
What carries the argument
Gradient sinks induced by attention sinks under causal masking, with the RMSNorm Jacobian attenuating gradients inversely to input norm.
If this is right
- Attenuating sink-induced gradients on the value path suppresses massive activations.
- Attention sinks persist independently after massive activations are removed.
- Massive activations function as an adaptive response to localized gradient pressure during training.
- Gradient sinks are the backward-pass counterpart to attention sinks.
Where Pith is reading between the lines
- Direct interventions on gradient flow could control activation scales in other normalized sequence models.
- This dynamic may affect stability in long-context training where attention sinks commonly form.
- Similar gradient concentration could arise under other attention variants that concentrate scores on initial tokens.
Load-bearing premise
The RMSNorm Jacobian attenuates gradients roughly in inverse proportion to input norm, so that massive activations can regulate localized gradient pressure.
What would settle it
Training a model with V-scale and checking whether massive activations disappear while attention sinks remain intact; the opposite result would falsify the regulatory link.
Figures













read the original abstract
Attention sinks and massive activations are recurring and closely related phenomena in Transformer models. Existing explanations have largely focused on the forward pass, yet in pre-norm Transformers, large residual-stream norms play only an indirect forward role because sublayers operate on normalized inputs. We study this relationship from the perspective of backpropagation. Empirically and theoretically, we show that under causal masking, attention sinks can induce pronounced gradient concentration, which we term gradient sinks. Since the RMSNorm Jacobian attenuates gradients roughly in inverse proportion to input norm, massive activations can be understood as adaptive regulators of this localized gradient pressure during training. This interpretation predicts that attenuating sink-induced gradients should weaken massive activations. We test this prediction with V-scale, a modification that adjusts backpropagated gradients on the value path. In V-scale models, attention sinks are preserved, whereas massive activations are suppressed. These results identify gradient sinks as a backward-pass counterpart of attention sinks, and massive activations as an adaptive RMSNorm-mediated response that attenuates the resulting localized training pressure. Our code is available at https://anonymous.4open.science/r/GradientSinkCode-B309.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in pre-norm Transformers under causal masking, attention sinks induce gradient sinks during backpropagation. It argues that massive activations function as adaptive regulators of this localized gradient pressure via the RMSNorm Jacobian's attenuation of gradients roughly in inverse proportion to input norm. This is supported by theoretical arguments linking the phenomena and by empirical tests, including the V-scale intervention that adjusts value-path gradients to preserve attention sinks while suppressing massive activations.
Significance. If the central claims hold, the work provides a backward-pass mechanistic account connecting attention sinks to massive activations, interpreting the latter as an RMSNorm-mediated response to training pressure. The V-scale modification offers a targeted, falsifiable test of the prediction and could inform analyses of training dynamics and activation patterns in large models.
major comments (2)
- [Theoretical analysis of RMSNorm Jacobian] The assertion that the RMSNorm Jacobian attenuates gradients roughly in inverse proportion to input norm (allowing massive activations to regulate sink-induced gradient pressure) lacks an explicit derivation or bound. This is load-bearing for the causal regulator interpretation, as the manuscript does not show that this effect dominates other gradient paths such as residual connections or value-projection weights in the full backprop graph under causal masking.
- [V-scale experiments and results] The V-scale intervention is presented as confirming the prediction by attenuating sink-induced gradients and thereby suppressing massive activations. However, the manuscript provides insufficient detail on the exact implementation (e.g., the scaling factor applied to backpropagated value-path gradients and its interaction with the full computation graph), which is needed to evaluate whether the outcome cleanly isolates the hypothesized mechanism.
minor comments (2)
- [Abstract] The abstract states that code is available at an anonymous repository; the main text should include a reproducibility statement with more specifics on datasets, model configurations, and training hyperparameters to support the empirical claims.
- [Introduction and definitions] Ensure consistent terminology and notation for newly introduced concepts such as 'gradient sinks' when first defined and in subsequent sections.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comments point by point below and will revise the manuscript accordingly to strengthen both the theoretical exposition and the experimental documentation.
read point-by-point responses
-
Referee: The assertion that the RMSNorm Jacobian attenuates gradients roughly in inverse proportion to input norm (allowing massive activations to regulate sink-induced gradient pressure) lacks an explicit derivation or bound. This is load-bearing for the causal regulator interpretation, as the manuscript does not show that this effect dominates other gradient paths such as residual connections or value-projection weights in the full backprop graph under causal masking.
Authors: We acknowledge that the current manuscript presents the RMSNorm Jacobian attenuation primarily through its known form (gradient scaling ~1/||x||) and links it to the observed gradient sinks, but does not include a self-contained derivation or explicit bounds showing dominance over residual and value-projection paths. In the revised version we will add an appendix section deriving the relevant Jacobian entries under pre-norm causal masking, providing a bound on the attenuation factor, and including a short analysis (with supporting gradient-norm measurements) that isolates the RMSNorm contribution relative to the other paths at sink positions. revision: yes
-
Referee: The V-scale intervention is presented as confirming the prediction by attenuating sink-induced gradients and thereby suppressing massive activations. However, the manuscript provides insufficient detail on the exact implementation (e.g., the scaling factor applied to backpropagated value-path gradients and its interaction with the full computation graph), which is needed to evaluate whether the outcome cleanly isolates the hypothesized mechanism.
Authors: We agree that the implementation details of V-scale are currently underspecified. In the revision we will expand the methods section to state the precise scaling factor applied to the back-propagated value gradients (a constant multiplier of 0.1), describe its selective application only to the value-projection path during the backward pass, and include pseudocode plus a computation-graph diagram showing that attention-sink formation in the forward pass remains unaffected while the hypothesized gradient-sink pressure is reduced. revision: yes
Circularity Check
No significant circularity; core claims rest on standard RMSNorm properties and independent empirical test
full rationale
The paper derives gradient sinks from attention sinks under causal masking using backpropagation analysis, then invokes the standard RMSNorm Jacobian attenuation (gradients scale inversely with input norm) as an established property to interpret massive activations as regulators. This is not self-definitional or fitted by construction. The prediction that attenuating sink-induced gradients weakens massive activations is tested via the introduced V-scale modification on the value path, which is an independent intervention rather than a renaming or self-citation reduction. No load-bearing step reduces to the paper's own inputs, fitted parameters, or prior self-citations; the account is self-contained against external benchmarks and falsifiable via the reported V-scale experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The RMSNorm Jacobian attenuates gradients roughly in inverse proportion to input norm
invented entities (2)
-
gradient sinks
no independent evidence
-
V-scale
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Theorem 2 (Activation-dependent compression under RMSNorm). ... ||J_rms(x)||_op ≤ ||γ||_∞ / rms(x). ... large activations can act as gradient regulators
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
Attention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
The first survey on Attention Sink in Transformers structures the literature around fundamental utilization, mechanistic interpretation, and strategic mitigation.
-
The Structural Origin of Attention Sink: Variance Discrepancy, Super Neurons, and Dimension Disparity
Attention sinks arise from variance discrepancy in self-attention value aggregation, amplified by super neurons and first-token dimension disparity, and can be mitigated by head-wise RMSNorm to accelerate pre-training...
-
Irminsul: MLA-Native Position-Independent Caching for Agentic LLM Serving
Irminsul recovers up to 83% of prompt tokens above exact-prefix matching and delivers 63% prefill energy savings per cache hit on MLA-MoE models by content-hashing CDC chunks and applying closed-form kr correction.
-
The Cognitive Penalty: Ablating System 1 and System 2 Reasoning in Edge-Native SLMs for Decentralized Consensus
System 1 intuition in edge SLMs delivers 100% adversarial robustness and low latency for DAO consensus while System 2 reasoning causes 26.7% cognitive collapse and 17x slowdown.
Reference graph
Works this paper leans on
-
[1]
Gqa: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. InEmpirical Methods in Natural Language Processing, 2023
work page 2023
-
[2]
Systematic outliers in large language models
Yongqi An, Xu Zhao, Tao Yu, Ming Tang, and Jinqiao Wang. Systematic outliers in large language models. InInternational Conference on Learning Representations, 2025
work page 2025
-
[3]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [4]
-
[5]
Quantizable transformers: Removing outliers by helping attention heads do nothing
Yelysei Bondarenko, Markus Nagel, and Tijmen Blankevoort. Quantizable transformers: Removing outliers by helping attention heads do nothing. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[6]
Rui Bu, Haofeng Zhong, Wenzheng Chen, and Yangyan Li. Value-state gated attention for mitigating extreme-token phenomena in transformers.arXiv preprint arXiv:2510.09017, 2025
-
[7]
GPT3.int8(): 8-bit matrix multiplication for transformers at scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. GPT3.int8(): 8-bit matrix multiplication for transformers at scale. InAdvances in Neural Information Processing Systems, 2022
work page 2022
-
[8]
QLoRA: Efficient finetuning of quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized LLMs. InThirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[9]
OPTQ: Accurate quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. OPTQ: Accurate quantization for generative pre-trained transformers. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[10]
Attention Sink Forges Native MoE in Attention Layers: Sink-Aware Training to Address Head Collapse
Zizhuo Fu, Wenxuan Zeng, Runsheng Wang, and Meng Li. Attention sink forges native moe in attention layers: Sink-aware training to address head collapse.arXiv preprint arXiv:2602.01203, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Aaron McClendon, Juan Morinelli, Stavros Zervoudakis, and Antonios Saravanos
Jorge Gallego-Feliciano, S. Aaron McClendon, Juan Morinelli, Stavros Zervoudakis, and Antonios Saravanos. Hidden dynamics of massive activations in transformer training.arXiv preprint arXiv:2508.03616, 2025
-
[12]
Saeed Ghadimi and Guanghui Lan
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, et al. A framework for few-shot language model evaluation, 2023. URLhttps://zenodo.org/records/10256836
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
When attention sink emerges in language models: An empirical view
Xiangming Gu, Tianyu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Ye Wang, and Min Lin. When attention sink emerges in language models: An empirical view. InInternational Conference on Learning Representations, 2025
work page 2025
-
[15]
Tianyu Guo, Druv Pai, Yu Bai, Jiantao Jiao, Michael I. Jordan, and Song Mei. Active-dormant attention heads: Mechanistically demystifying extreme-token phenomena in llms. InConference on Parsimony and Learning, 2025
work page 2025
-
[16]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InIEEE Conference on Computer Vision and Pattern Recognition, 2016
work page 2016
-
[17]
From attention to activation: Unraveling the enigmas of large language models
Prannay Kaul, Chengcheng Ma, Ismail Elezi, and Jiankang Deng. From attention to activation: Unraveling the enigmas of large language models. InInternational Conference on Learning Representations, 2025. 10
work page 2025
-
[18]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration. InProceedings of Machine Learning and Systems, volume 6, pages 87–100, 2024
work page 2024
-
[19]
Guozhi Liu, Weiwei Lin, Tiansheng Huang, Ruichao Mo, Qi Mu, Xiumin Wang, and Li Shen. Surgery: Mitigating harmful fine-tuning for large language models via attention sink.arXiv preprint arXiv:2602:05228, 2026
work page 2026
-
[20]
Understanding the difficulty of training transformers
Liyuan Liu, Xiaodong Liu, Jianfeng Gao, Weizhu Chen, and Jiawei Han. Understanding the difficulty of training transformers. InEmpirical Methods in Natural Language Processing, pages 5747–5763. Association for Computational Linguistics, 2020
work page 2020
-
[21]
Sinktrack: Attention sink based context anchoring for large language models
Xu Liu, Guikun Chen, and Wenguan Wang. Sinktrack: Attention sink based context anchoring for large language models. InInternational Conference on Learning Representations, 2026
work page 2026
-
[22]
All you need is one: Capsule prompt tuning with a single vector
Yiyang Liu, James Chenhao Liang, Heng Fan, Wenhao Yang, Yiming Cui, Xiaotian Han, Lifu Huang, Dongfang Liu, Qifan Wang, and Cheng Han. All you need is one: Capsule prompt tuning with a single vector. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[23]
Stephan Mandt, Matthew D. Hoffman, and David M. Blei. Stochastic gradient descent as approximate bayesian inference.Journal of Machine Learning Research, 18:134:1–134:35, 2017
work page 2017
-
[24]
An Empirical Model of Large-Batch Training
Sam McCandlish, Jared Kaplan, Dario Amodei, and OpenAI Dota Team. An empirical model of large-batch training.arXiv preprint arXiv:1812.06162, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Evan Miller. Attention is off by one, 2023. URL https://www.evanmiller.org/ attention-is-off-by-one.html
work page 2023
-
[26]
Toan Q. Nguyen and Julian Salazar. Transformers without tears: Improving the normalization of self-attention. InProceedings of the 16th International Conference on Spoken Language Translation. Association for Computational Linguistics, 2019
work page 2019
-
[27]
A refined analysis of massive activations in llms.arXiv preprint arXiv:2503.22329, 2025
Louis Owen, Nilabhra Roy Chowdhury, Abhay Kumar, and Fabian Gura. A refined analysis of massive activations in llms.arXiv preprint arXiv:2503.22329, 2025
-
[28]
YaRN: Efficient con- text window extension of large language models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. YaRN: Efficient con- text window extension of large language models. InInternational Conference on Learning Representations, 2024
work page 2024
-
[29]
Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, et al. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[30]
Zihan Qiu, Zeyu Huang, Kaiyue Wen, Peng Jin, Bo Zheng, Yuxin Zhou, Haofeng Huang, Zekun Wang, Xiao Li, Huaqing Zhang, et al. A unified view of attention and residual sinks: Outlier-driven rescaling is essential for transformer training.arXiv preprint arXiv:2601.22966, 2026
-
[31]
Bronstein, Yann LeCun, and Ravid Shwartz-Ziv
Enrique Queipo-de Llano, Alvaro Arroyo, Federico Barbero, Xiaowen Dong, Michael M. Bronstein, Yann LeCun, and Ravid Shwartz-Ziv. Attention sinks and compression valleys in llms are two sides of the same coin. InInternational Conference on Learning Representations, 2026
work page 2026
-
[32]
Language models are unsupervised multitask learners
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019
work page 2019
-
[33]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21:140:1–140:67, 2020
work page 2020
-
[34]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202, 2020. 11
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[35]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[36]
Zunhai Su and Kehong Yuan. Kvsink: Understanding and enhancing the preservation of attention sinks in kv cache quantization for llms. InConference on Language Modeling, 2025
work page 2025
-
[37]
Unveiling super experts in mixture-of-experts large language models
Zunhai Su, Qingyuan Li, Hao Zhang, Weihao Ye, Qibo Xue, Yulei Qian, Ngai Wong, and Kehong Yuan. Unveiling super experts in mixture-of-experts large language models. In International Conference on Learning Representations, 2026
work page 2026
-
[38]
Mingjie Sun, Xinlei Chen, J. Zico Kolter, and Zhuang Liu. Massive activations in large language models. InConference on Language Modeling, 2024
work page 2024
-
[39]
Shangwen Sun, Alfredo Canziani, Yann LeCun, and Jiachen Zhu. The spike, the sparse and the sink: Anatomy of massive activations and attention sinks.arXiv preprint arXiv:2603.05498, 2026
-
[40]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems, 2017
work page 2017
-
[42]
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Dongdong Zhang, and Furu Wei. Deepnet: Scaling transformers to 1,000 layers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(10):6761–6774, 2024
work page 2024
-
[43]
SmoothQuant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and efficient post-training quantization for large language models. InProceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 38087–38099. PMLR, 23–29 Jul 2023
work page 2023
-
[44]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InInternational Conference on Learning Representations, 2024
work page 2024
-
[45]
On layer normalization in the transformer architecture
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu. On layer normalization in the transformer architecture. InInternational Conference on Machine Learning, 2020
work page 2020
-
[46]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. Root mean square layer normalization. InAdvances in Neural Information Processing Systems, 2019
work page 2019
-
[50]
Zayd M. K. Zuhri, Erland Hilman Fuadi, and Alham Fikri Aji. Softpick: No attention sink, no massive activations with rectified softmax.arXiv preprint arXiv:2504.20966, 2025. 12 A Related work Phenomena and utilizationAttention sinks (AS) refer to the tendency of Transformer-based LLMs to route disproportionate attention mass to a small set of early or oth...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Moreover,max r≥0 λ∥(r) = 9/8, attained atr= 3C
Then the Jacobian in (5) has eigenvalue λ⊥(r) = r r+C on the (dhead −1) -dimensional subspace orthogonal to v, and eigenvalue λ∥(r) = r2+3Cr (r+C) 2 along the radial directionvitself. Moreover,max r≥0 λ∥(r) = 9/8, attained atr= 3C. Proof. Because vv ⊤ is rank one, for any u⊥v we have vv ⊤u= 0 , so Proposition 7 gives Jϕ(v)u=ϕ(r)u. Along the radial directi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.