Recognition: unknown
The Structural Origin of Attention Sink: Variance Discrepancy, Super Neurons, and Dimension Disparity
Pith reviewed 2026-05-08 12:07 UTC · model grok-4.3
The pith
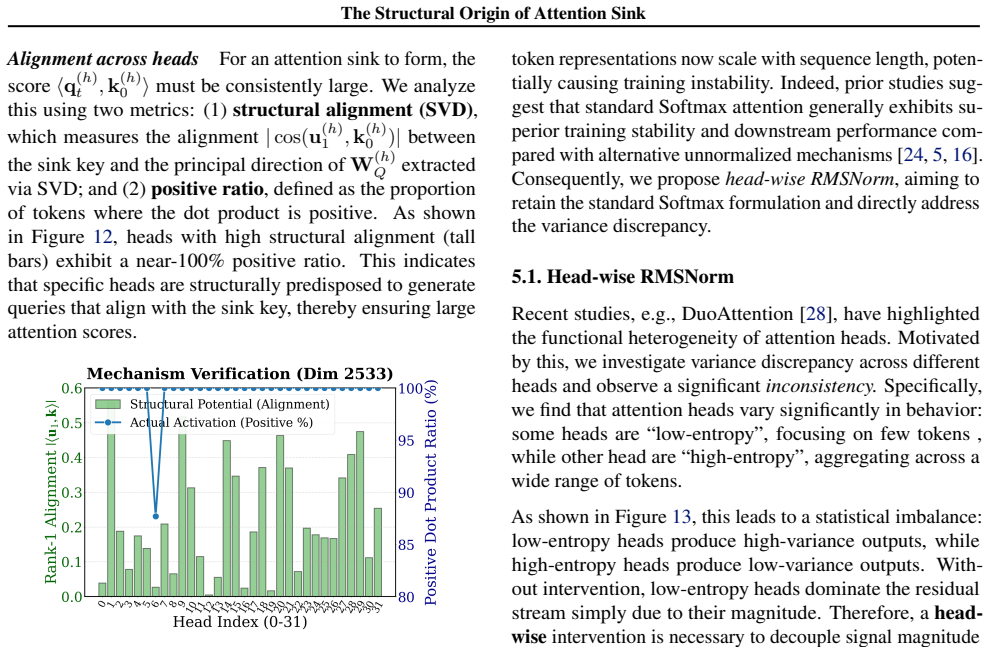
Attention sinks in LLMs arise because channel-sparse down-projections in feed-forward layers create a dimension disparity that forces the first token to serve as a structural anchor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Value aggregation in self-attention induces a systematic variance discrepancy that super neurons in FFN layers amplify through channel-sparse down-projections; these projections create a dimension disparity in the first-token representation, which necessitates attention sinks as a structural anchor.
What carries the argument
Channel-sparse down-projections inside super neurons that trigger dimension disparity in the first-token representation and thereby require attention sinks as a structural anchor.
If this is right
- Attention masks that isolate the aggregation effect can move sinks to any chosen position.
- Amplifying variance at targeted positions can induce sinks at those positions.
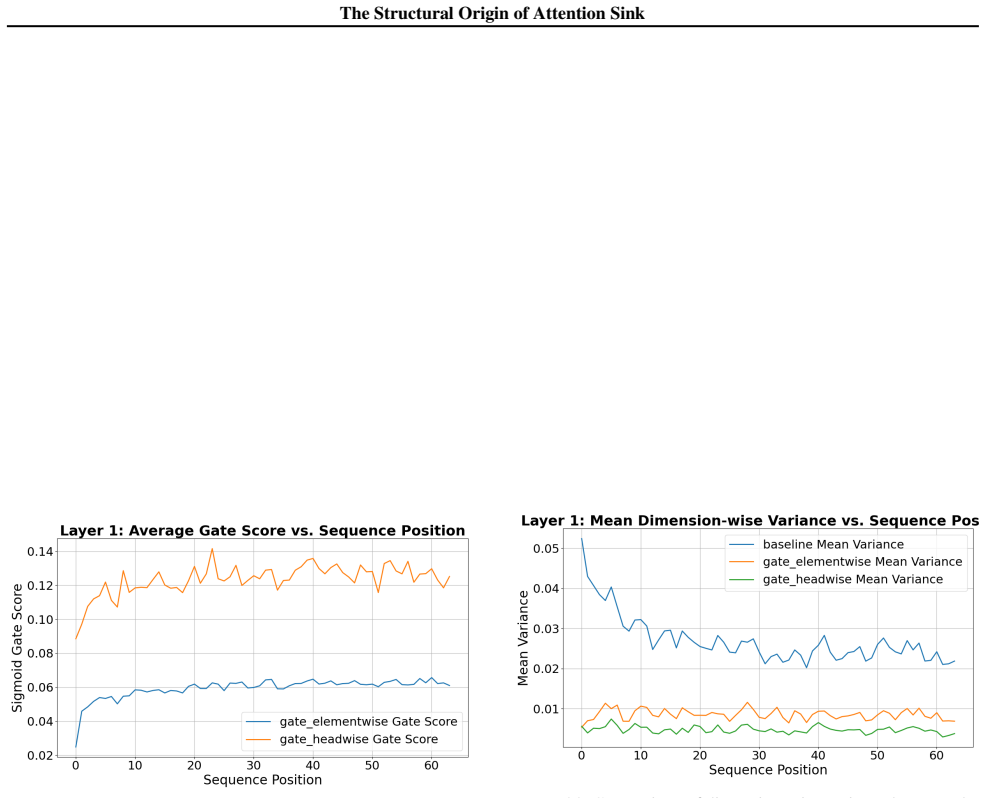
- Head-wise RMSNorm applied during pre-training restores parity across positions and accelerates convergence.
Where Pith is reading between the lines
- Architectures that avoid channel sparsity in down-projections might eliminate the need for sinks without losing representational power.
- The same variance-discrepancy analysis could be applied to other positional biases observed in transformer training.
- Early detection of super-neuron activation patterns could predict sink locations before full training completes.
Load-bearing premise
Super neurons and the dimension disparity they produce are the primary cause of attention sinks rather than secondary effects of training or architecture.
What would settle it
Remove or densify the down-projections of the identified super neurons while keeping all other weights and training dynamics fixed, then measure whether attention sinks disappear or shift.
Figures


















read the original abstract
Despite the prevalence of the attention sink phenomenon in Large Language Models (LLMs), where initial tokens disproportionately monopolize attention scores, its structural origins remain elusive. This work provides a \textit{mechanistic explanation} for this phenomenon. First, we trace its root to the value aggregation process inherent in self-attention, which induces a systematic variance discrepancy. We further demonstrate that this discrepancy is drastically amplified by the activation of super neurons within Feed-Forward Network (FFN) layers. Specifically, the channel-sparse down-projections trigger a dimension disparity of the first-token representation, necessitating the formation of attention sinks as a structural anchor. Then, we validate this causal chain through two controlled interventions: (i) isolating the aggregation effect via attention mask modifications and (ii) amplifying the variance of targeted token representations. Both interventions can replicate attention sinks at arbitrary positions. Our mechanistic understanding offers a foundation for the systematic control of sink formation. Finally, as a proof of concept, we propose \textit{head-wise RMSNorm}, an architectural modification that stabilizes value aggregation outputs during pre-training. Our experiments demonstrate that restoring statistical parity across positions significantly accelerates convergence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a mechanistic explanation for the attention sink phenomenon in LLMs. It traces the root to variance discrepancy induced by value aggregation in self-attention, which is amplified by super neurons in FFN layers via channel-sparse down-projections leading to dimension disparity in the first-token representation. This disparity necessitates attention sinks as a structural anchor. The authors validate the causal chain with two interventions—attention mask modifications to isolate aggregation effects and targeted variance amplification—that replicate sinks at arbitrary positions. They also propose head-wise RMSNorm as an architectural change to stabilize value aggregation and accelerate convergence during pre-training.
Significance. If the proposed causal mechanism holds, this work offers a significant advance in understanding a common but poorly explained behavior in transformer-based LLMs. The controlled interventions provide direct support by demonstrating inducibility of sinks at new positions, and the head-wise RMSNorm modification demonstrates a practical application that improves training dynamics. This could lead to better architectural designs and training strategies for large models.
major comments (2)
- [Validation experiments (abstract and §4)] The two interventions are presented as validating the dimension-disparity-to-sink causal chain, but attention mask modifications can alter global attention entropy and position-wise value mixing independently of the first-token dimension disparity. The paper should provide quantitative comparisons of attention statistics before and after the mask change to confirm isolation.
- [Validation experiments (abstract and §4)] Similarly, the variance amplification intervention may affect super-neuron activations or downstream normalization in ways unrelated to the original mechanism. Additional ablations or controls are needed to show that the replicated sinks are driven specifically by the induced dimension disparity rather than side effects.
minor comments (2)
- The definition of 'super neurons' and 'head-wise RMSNorm' should be made more precise with equations in the main text for reproducibility.
- The manuscript would benefit from including full experimental details, such as model sizes, datasets, and exact quantitative results for the interventions, which are currently summarized at a high level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments on the validation experiments are well-taken and point to opportunities for strengthening the isolation of causal effects. We address each major comment below and have revised the paper to include the requested quantitative analyses and controls.
read point-by-point responses
-
Referee: [Validation experiments (abstract and §4)] The two interventions are presented as validating the dimension-disparity-to-sink causal chain, but attention mask modifications can alter global attention entropy and position-wise value mixing independently of the first-token dimension disparity. The paper should provide quantitative comparisons of attention statistics before and after the mask change to confirm isolation.
Authors: We agree that explicit quantification is necessary to rule out confounding changes in attention entropy or value mixing. Our mask modifications were constructed to selectively block non-first-token aggregation while leaving the first-token representation and its dimension disparity intact. In the revised manuscript we now include direct pre/post comparisons of global attention entropy, per-position value mixing distributions, and variance statistics (new Figure 4 and accompanying table in §4). These metrics show that entropy shifts are small and uncorrelated with the replicated sink positions, which instead track the preserved dimension disparity. This addition confirms the intended isolation without altering the original experimental design. revision: yes
-
Referee: [Validation experiments (abstract and §4)] Similarly, the variance amplification intervention may affect super-neuron activations or downstream normalization in ways unrelated to the original mechanism. Additional ablations or controls are needed to show that the replicated sinks are driven specifically by the induced dimension disparity rather than side effects.
Authors: We acknowledge the possibility of unintended effects on super-neuron firing or normalization. The variance amplification was applied only to targeted token hidden states chosen to mimic the observed dimension disparity. In the revised §4 we now report additional ablation controls that (i) monitor super-neuron activation histograms before and during amplification and (ii) track downstream LayerNorm/RMSNorm statistics. When these side-effect variables are held constant across conditions, the attention-sink replication remains tied to the induced dimension disparity and disappears when the disparity is removed. These controls are presented alongside the original intervention results. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper traces attention sinks to value aggregation in self-attention (inducing variance discrepancy), amplified by observed super-neuron activation in FFN down-projections that create first-token dimension disparity. This is presented as a mechanistic explanation rather than a definitional equivalence. Validation relies on two independent interventions (attention-mask modifications and targeted variance amplification) that replicate sinks at arbitrary positions, plus a proposed architectural change (head-wise RMSNorm). No load-bearing step reduces by construction to fitted parameters, self-citations, or renamed inputs; the central claim rests on empirical tracing and controlled experiments that are falsifiable outside the paper's own equations. This is the expected non-finding for a paper whose core argument is experimentally grounded rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard mathematical properties of self-attention value aggregation and FFN down-projections in transformers
invented entities (2)
-
super neurons
no independent evidence
-
head-wise RMSNorm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer normal- ization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review arXiv 2016
-
[2]
Bronstein and Petar Velickovic and Razvan Pascanu , title =
Barbero, F., Arroyo, A., Gu, X., Perivolaropoulos, C., Bronstein, M., Veli ˇckovi´c, P., and Pascanu, R. Why do llms attend to the first token?arXiv preprint arXiv:2504.02732, 2025
-
[3]
Quan- tizable transformers: Removing outliers by helping attention heads do nothing.Advances in Neural Infor- mation Processing Systems, 36:75067–75096, 2023
Bondarenko, Y ., Nagel, M., and Blankevoort, T. Quan- tizable transformers: Removing outliers by helping attention heads do nothing.Advances in Neural Infor- mation Processing Systems, 36:75067–75096, 2023
2023
-
[4]
Cancedda, N. Spectral filters, dark signals, and atten- tion sinks.arXiv preprint arXiv:2402.09221, 2024
-
[5]
Conversa- tional agents in therapeutic interventions for neurode- velopmental disorders: a survey.ACM Computing Surveys, 55(10):1–34, 2023
Catania, F., Spitale, M., and Garzotto, F. Conversa- tional agents in therapeutic interventions for neurode- velopmental disorders: a survey.ACM Computing Surveys, 55(10):1–34, 2023
2023
-
[6]
Attention Sinks Induce Gradient Sinks: Massive Activations as Gradient Regulators in Transformers
Chen, Y . and Yao, Q. Attention sinks induce gradient sinks.arXiv preprint arXiv:2603.17771, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Clark, K., Khandelwal, U., Levy, O., and Manning, C. D. What does bert look at? an analysis of bert’s attention.arXiv preprint arXiv:1906.04341, 2019
work page Pith review arXiv 1906
-
[8]
Openwebtext corpus
Gokaslan, A., Cohen, V ., Pavlick, E., and Tellex, S. Openwebtext corpus. http://Skylion007. github.io/OpenWebTextCorpus, 2019
2019
-
[9]
When attention sink emerges in language models: An empirical view.arXiv preprint arXiv:2410.10781,
Gu, X., Pang, T., Du, C., Liu, Q., Zhang, F., Du, C., Wang, Y ., and Lin, M. When attention sink emerges in language models: An empirical view.arXiv preprint arXiv:2410.10781, 2024
-
[10]
Lm-infinite: Simple on-the-fly length generalization for large language models
Han, C., Wang, Q., Peng, H., Xiong, W., Chen, Y ., Ji, H., and Wang, S. Lm-infinite: Zero-shot extreme length generalization for large language models.arXiv preprint arXiv:2308.16137, 2023
-
[11]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016
2016
-
[12]
KENDALL, M. G. A new measure of rank correla- tion.Biometrika, 30(1-2):81–93, 06 1938. ISSN 0006-
1938
-
[13]
Biometrika30(1-2), 81–93 (1938) https://doi.org/10.1093/biomet/30.1-2.81
doi: 10.1093/biomet/30.1-2.81. URL https: //doi.org/10.1093/biomet/30.1-2.81
-
[14]
Li, S., Tong, Y ., Wang, H., and Hu, T. Transformers are born biased: Structural inductive biases at random initialization and their practical consequences.arXiv preprint arXiv:2602.05927, 2026
-
[15]
Liu, R., Bai, H., Lin, H., Li, Y ., Gao, H., Xu, Z., Hou, L., Yao, J., and Yuan, C. Intactkv: Improving large language model quantization by keeping pivot tokens intact.arXiv preprint arXiv:2403.01241, 2024
-
[16]
Loshchilov, I., Hsieh, C.-P., Sun, S., and Ginsburg, B. ngpt: Normalized transformer with representa- tion learning on the hypersphere.arXiv preprint arXiv:2410.01131, 2024
-
[17]
The devil in linear transformer
Qin, Z., Han, X., Sun, W., Li, D., Kong, L., Barnes, N., and Zhong, Y . The devil in linear transformer.arXiv preprint arXiv:2210.10340, 2022
-
[18]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Qiu, Z., Wang, Z., Zheng, B., Huang, Z., Wen, K., Yang, S., Men, R., Yu, L., Huang, F., Huang, S., et al. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free.arXiv preprint arXiv:2505.06708, 2025
work page internal anchor Pith review arXiv 2025
-
[19]
Theory, analysis, and best practices for sigmoid self-attention.arXiv preprint arXiv:2409.04431,
Ramapuram, J., Danieli, F., Dhekane, E., Weers, F., Busbridge, D., Ablin, P., Likhomanenko, T., Digani, J., Gu, Z., Shidani, A., et al. Theory, analysis, and best practices for sigmoid self-attention.arXiv preprint arXiv:2409.04431, 2024
-
[20]
and Vetterli, M
Roy, O. and Vetterli, M. The effective rank: A measure of effective dimensionality. In2007 15th European Signal Processing Conference, pp. 606–610, 2007
2007
-
[21]
GLU Variants Improve Transformer
Shazeer, N. Glu variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review arXiv 2002
-
[22]
Prefix- ing attention sinks can mitigate activation outliers for large language model quantization
Son, S., Park, W., Han, W., Kim, K., and Lee, J. Prefix- ing attention sinks can mitigate activation outliers for large language model quantization. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 2242–2252, 2024
2024
-
[23]
SeedPrints: Fingerprints Can Even Tell Which Seed Your Large Language Model Was Trained From
Tong, Y ., Wang, H., Li, S., Kawaguchi, K., and Hu, T. Seedprints: Fingerprints can even tell which seed your large language model was trained from.arXiv preprint arXiv:2509.26404, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Alma- hairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhar- gava, P., Bhosale, S., et al. Llama 2: Open foun- dation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 10 The Structural Origin of Attention Sink
work page internal anchor Pith review arXiv 2023
-
[25]
N., Kaiser, Ł., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. Attention is all you need.Advances in neural informa- tion processing systems, 30, 2017
2017
-
[26]
Analyzing the Structure of Attention in a Transformer Language Model
Vig, J. and Belinkov, Y . Analyzing the structure of attention in a transformer language model.arXiv preprint arXiv:1906.04284, 2019
work page Pith review arXiv 1906
-
[27]
Wan, Z., Wu, Z., Liu, C., Huang, J., Zhu, Z., Jin, P., Wang, L., and Yuan, L. Look-m: Look-once optimiza- tion in kv cache for efficient multimodal long-context inference.arXiv preprint arXiv:2406.18139, 2024
-
[28]
Efficient Streaming Language Models with Attention Sinks
Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review arXiv 2023
-
[29]
Duoattention: Efficient long-context LLM inference with retrieval and streaming heads
Xiao, G., Tang, J., Zuo, J., Guo, J., Yang, S., Tang, H., Fu, Y ., and Han, S. Duoattention: Efficient long- context llm inference with retrieval and streaming heads.arXiv preprint arXiv:2410.10819, 2024
-
[30]
Yan, R., Du, X., Deng, H., Zheng, L., Sun, Q., Hu, J., Shao, Y ., Jiang, P., Jiang, J., and Zhao, L. Unveiling and controlling anomalous attention distribution in transformers.arXiv preprint arXiv:2407.01601, 2024
-
[31]
Interpretingtherepeated token phenomenon in large language models.arXiv preprint arXiv:2503.08908,
Yona, I., Shumailov, I., Hayes, J., Barbero, F., and Gandelsman, Y . Interpreting the repeated token phe- nomenon in large language models.arXiv preprint arXiv:2503.08908, 2025. 11 The Structural Origin of Attention Sink A. Extended LLMs Analysis In this section, we provide additional empirical evidence supporting the mechanistic origin of attention sinks...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.