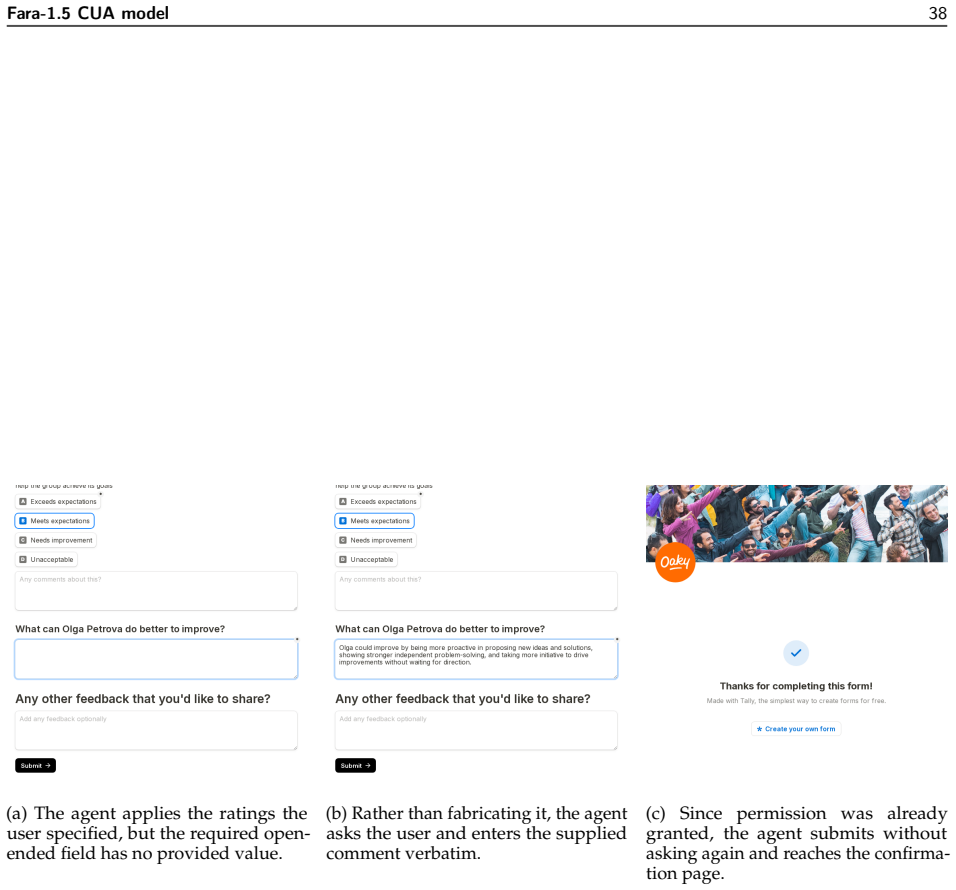
Fara-1.5: Scalable Learning Environments for Computer Use Agents
Pith reviewed 2026-06-26 17:23 UTC · model grok-4.3
The pith
A scalable pipeline of synthetic environments and triple verifiers generates training data that produces new state-of-the-art 9B and 27B computer-use agents on browser benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
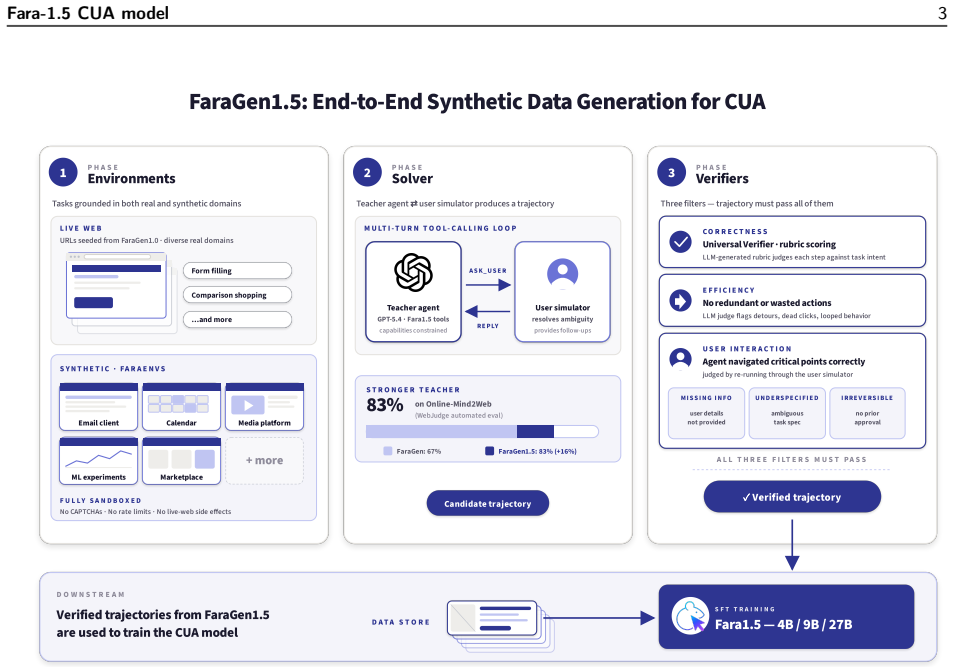
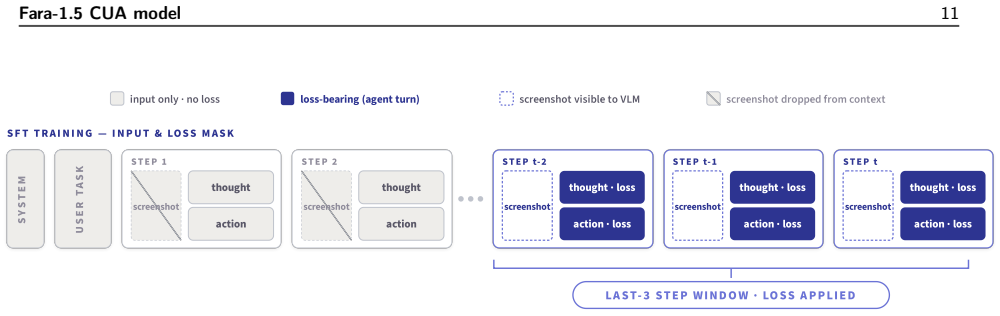
FaraGen1.5 is a data pipeline composed of environments, solvers, and verifiers that produces high-quality demonstration trajectories from both live and synthetic sites; when these trajectories are used in a balanced iterative supervised finetuning recipe, they yield Fara1.5 agents at three scales that set new state-of-the-art scores for their parameter classes on standard browser-use benchmarks.
What carries the argument
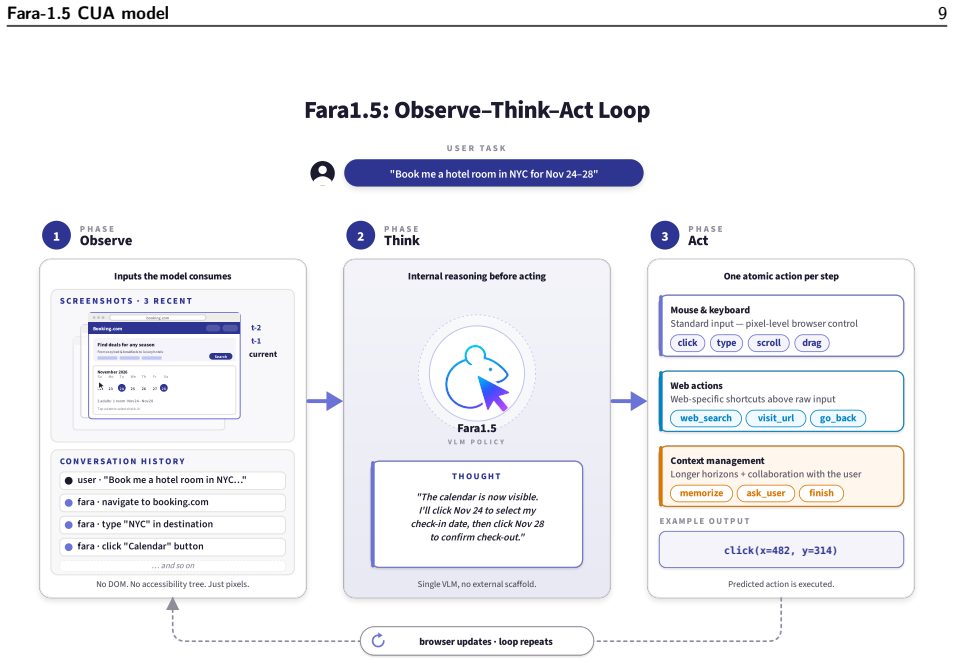
FaraGen1.5 pipeline, consisting of live and synthetic environments, a solver harness that supports multiple models and a user simulator, and three verifiers that evaluate task correctness, efficiency, and critical-point adherence.
If this is right
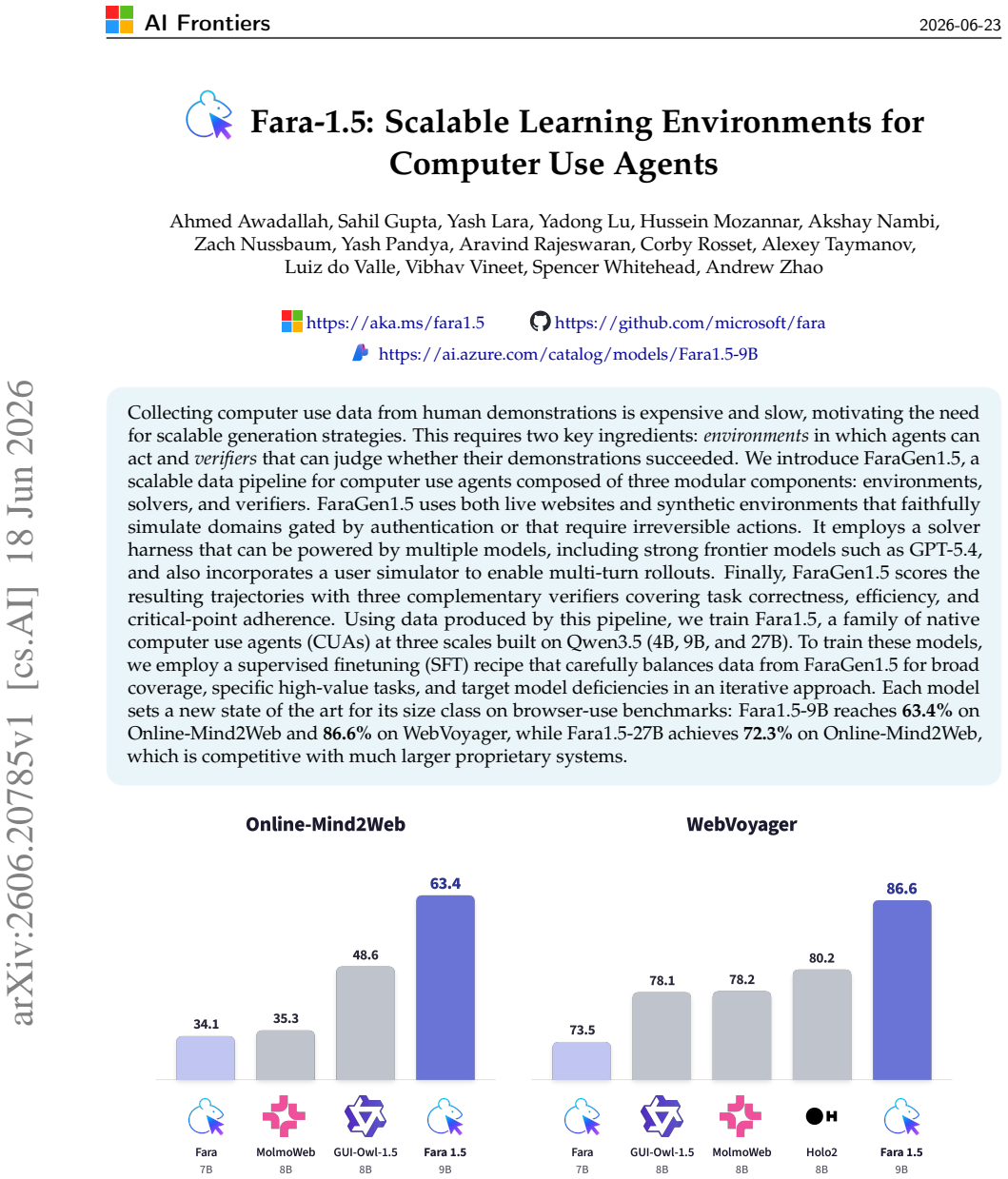
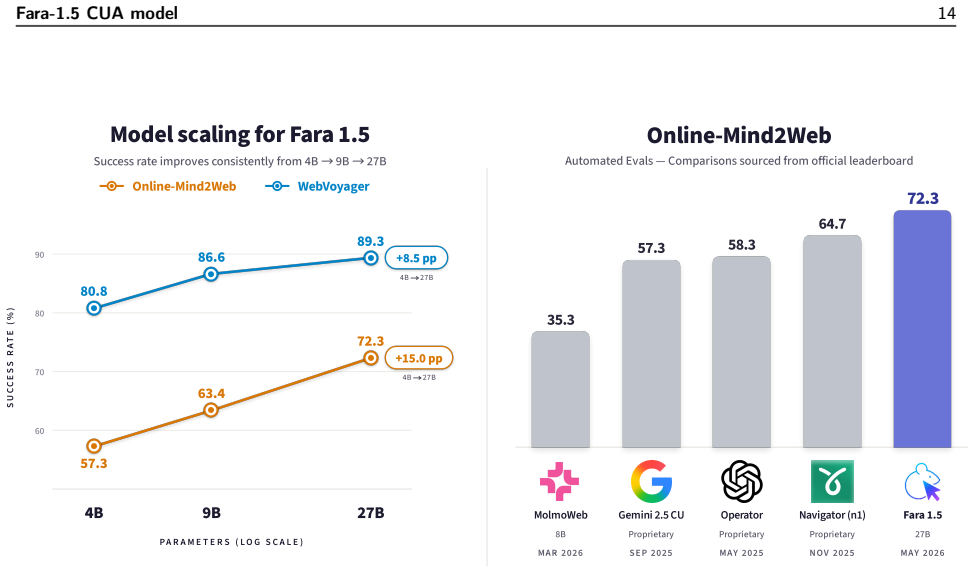
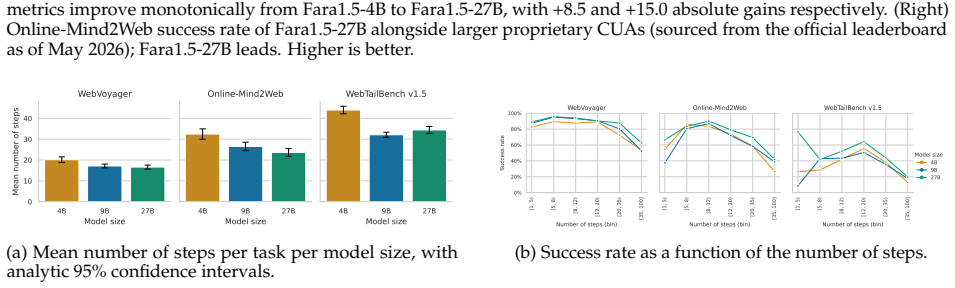
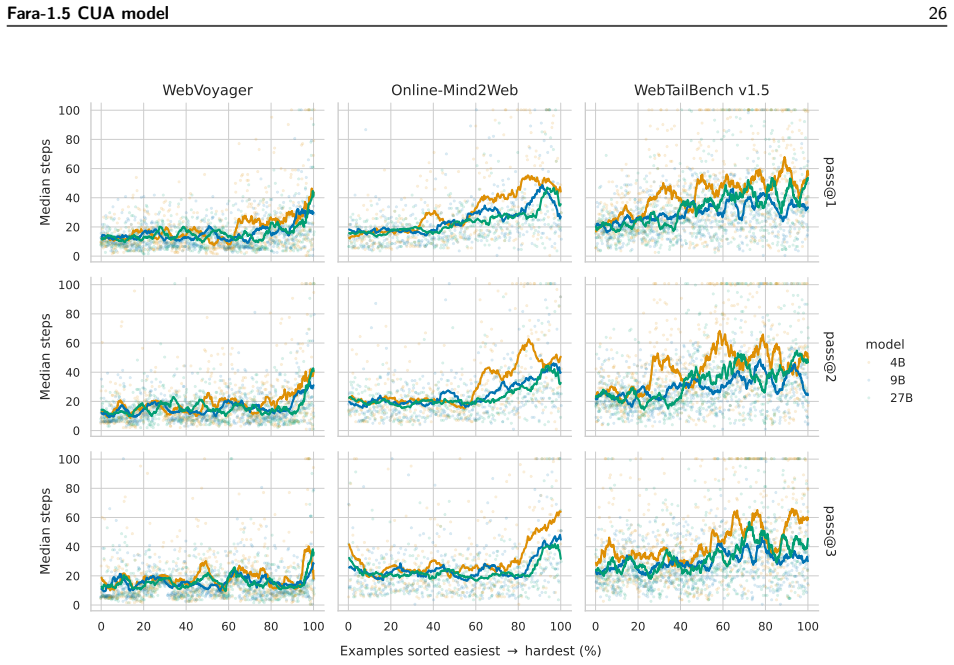
- Fara1.5-9B reaches 63.4% on Online-Mind2Web and 86.6% on WebVoyager.
- Fara1.5-27B reaches 72.3% on Online-Mind2Web, competitive with much larger proprietary systems.
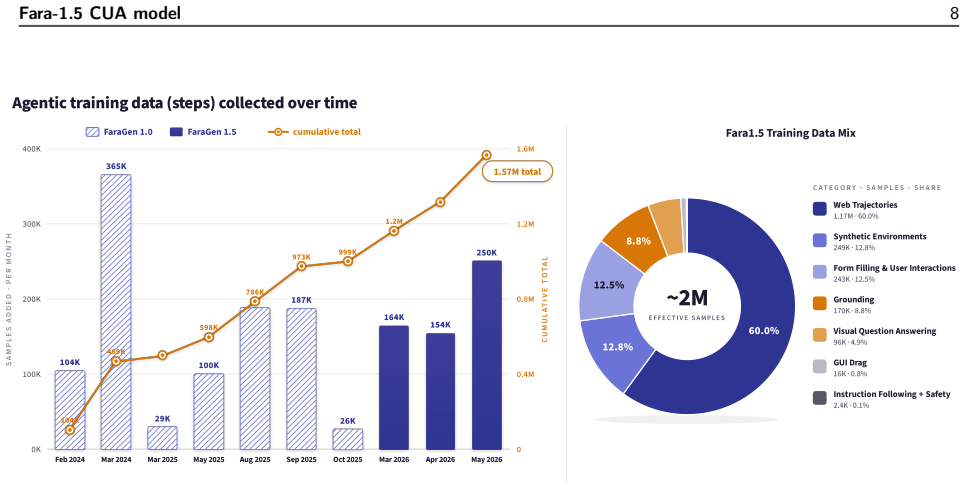
- The supervised finetuning recipe balances broad coverage, specific high-value tasks, and iterative correction of target model deficiencies.
- Each Fara1.5 model sets a new state of the art for its size class on browser-use benchmarks.
Where Pith is reading between the lines
- If the pipeline generalizes, it could supply training data for computer-use agents operating outside browsers once additional synthetic environments are built.
- The inclusion of efficiency and critical-point verifiers may encourage agents to prefer shorter, lower-risk action sequences even when task success is the main objective.
- Using frontier models inside the solver harness could let smaller target models learn from higher-quality demonstrations than they could generate themselves.
- Faithful synthetic environments would allow safe rehearsal of actions that cannot be tested directly on live systems.
Load-bearing premise
The synthetic environments must faithfully simulate domains gated by authentication or irreversible actions, and the three verifiers must accurately judge demonstration success without introducing bias or false positives.
What would settle it
Retraining the same base models on an equivalent amount of human-collected trajectories and measuring whether benchmark scores match or exceed those of the Fara1.5 models would directly test whether the pipeline's data is responsible for the gains.
Figures
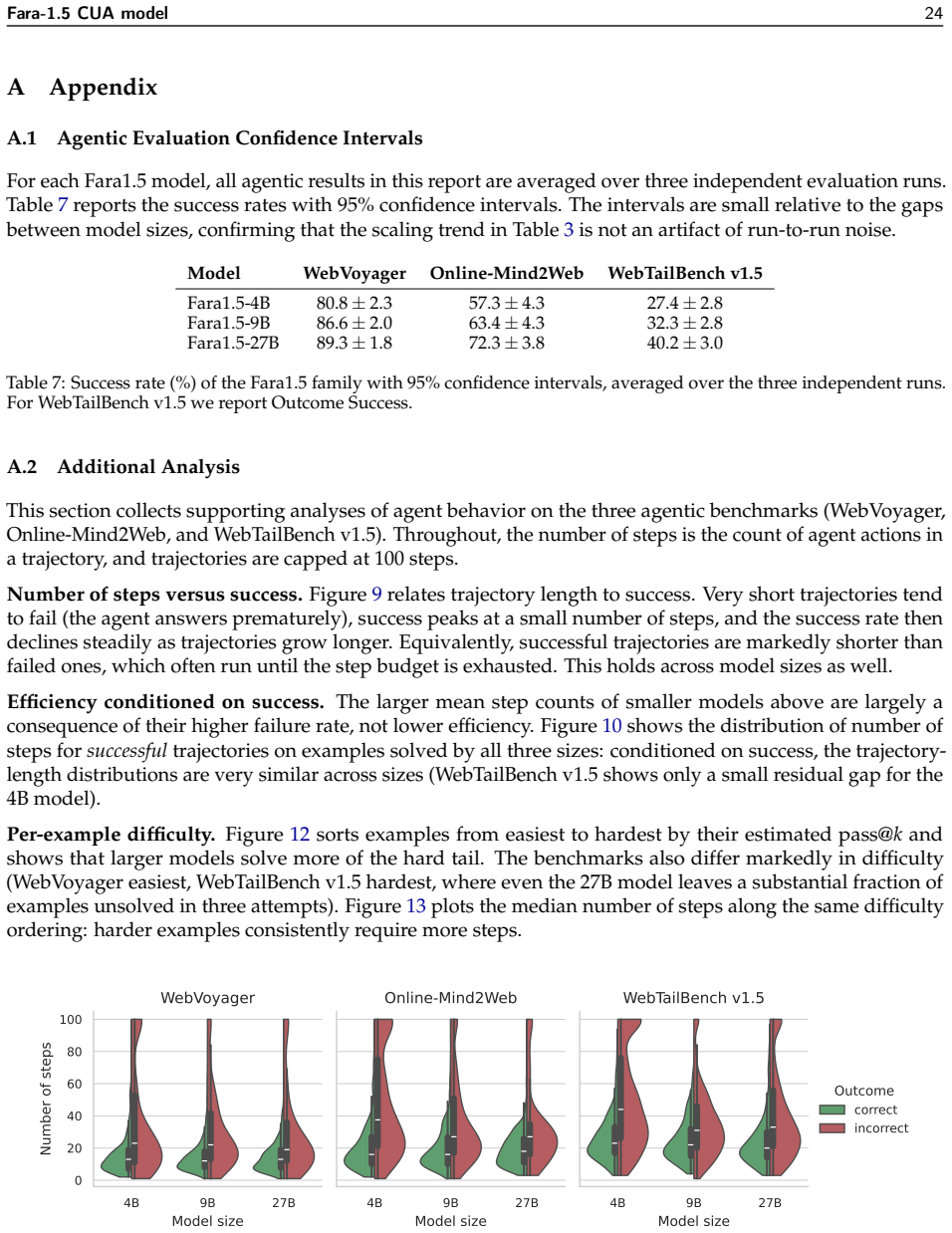
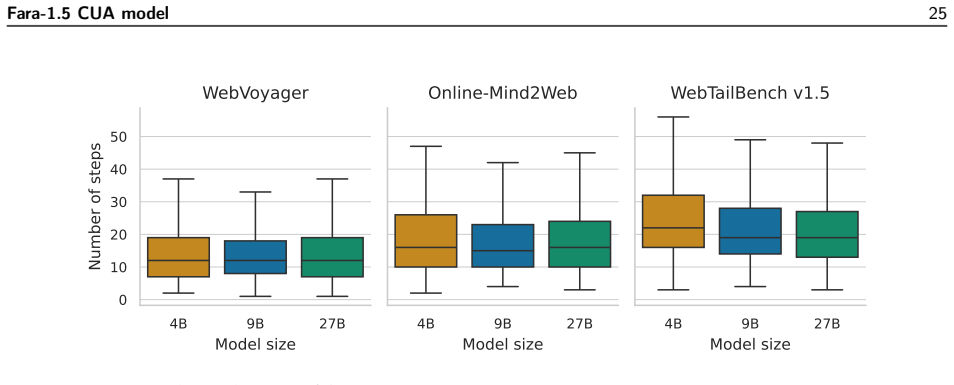
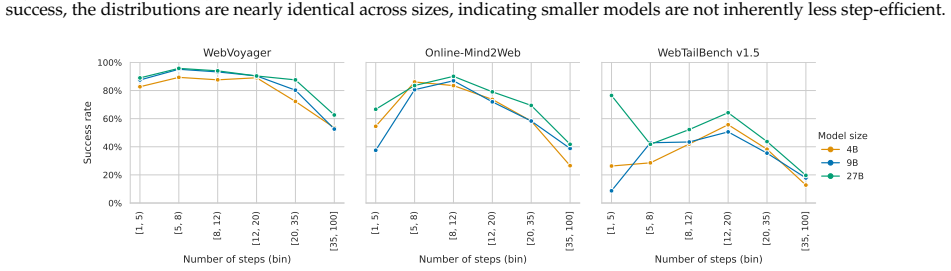
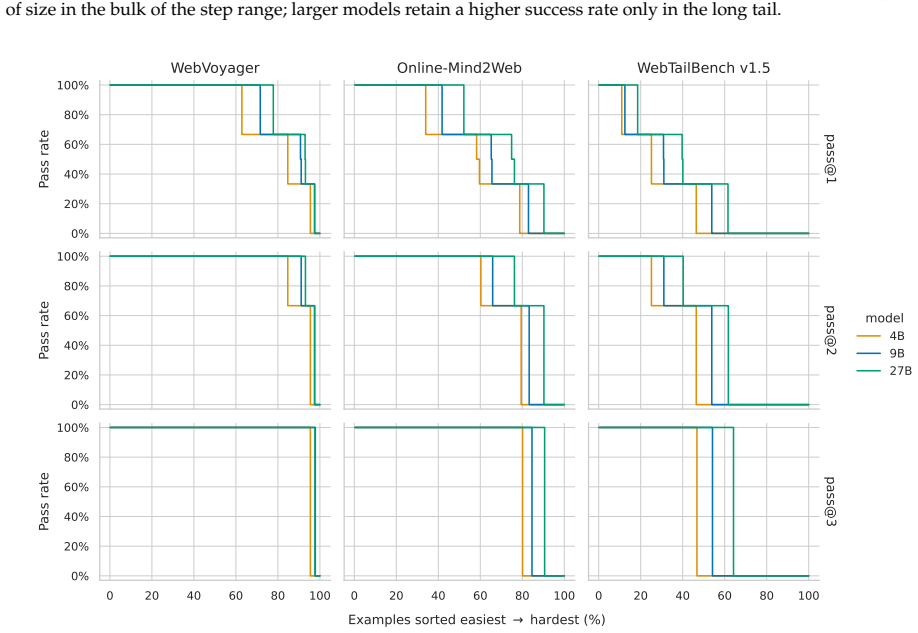
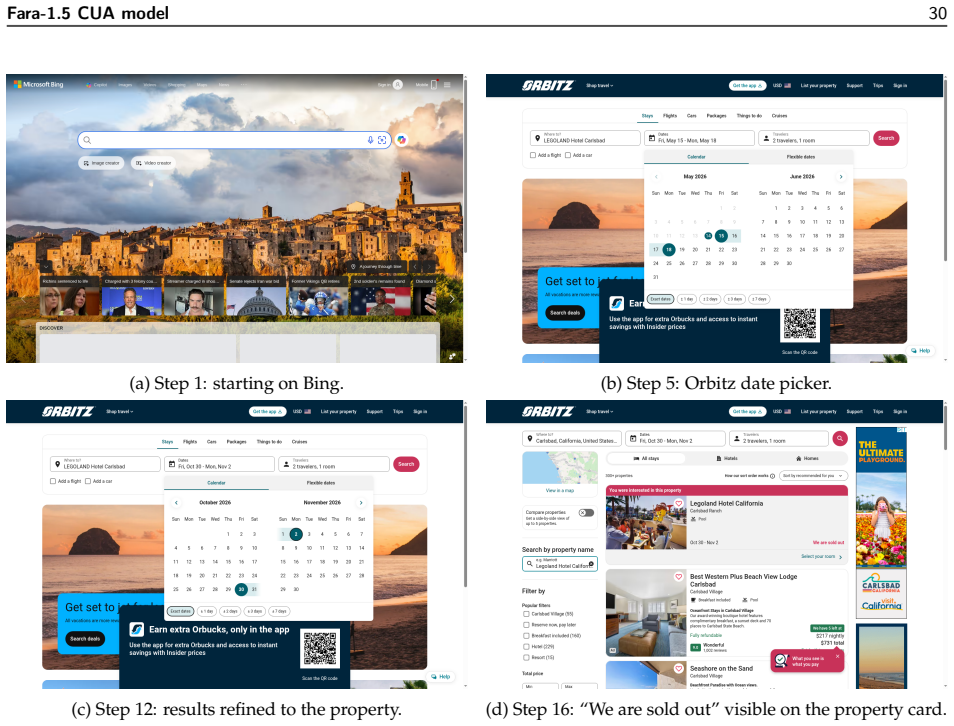
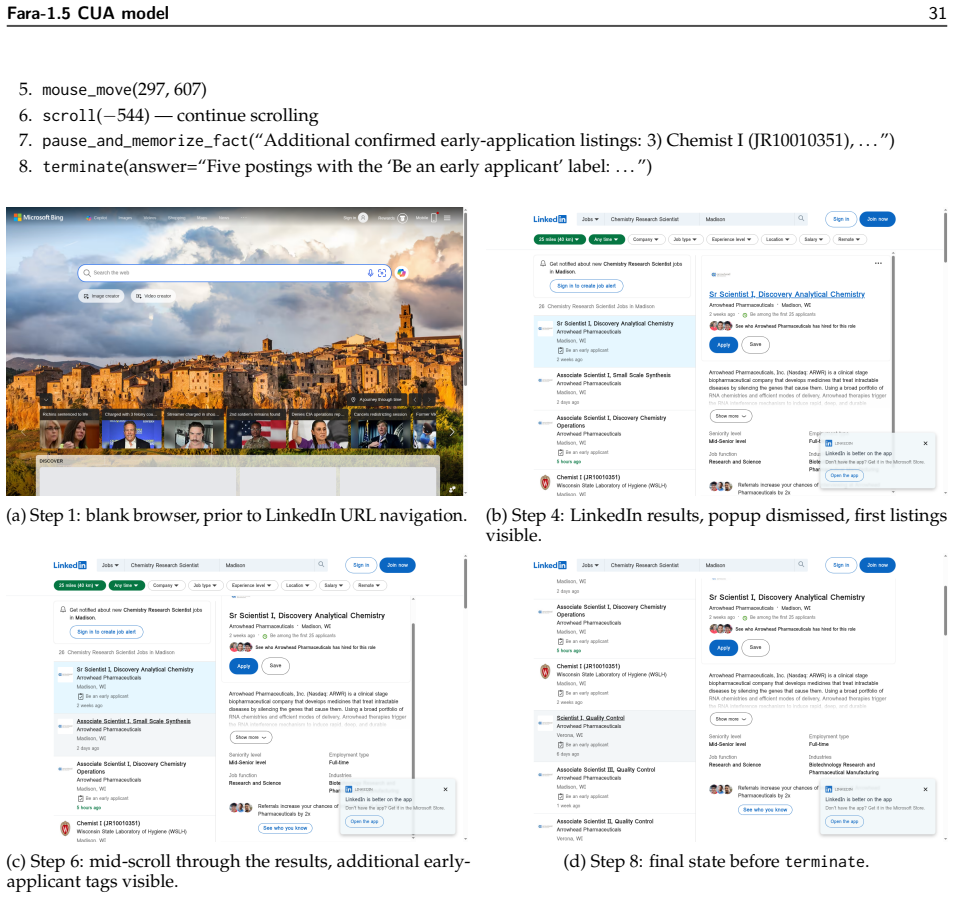
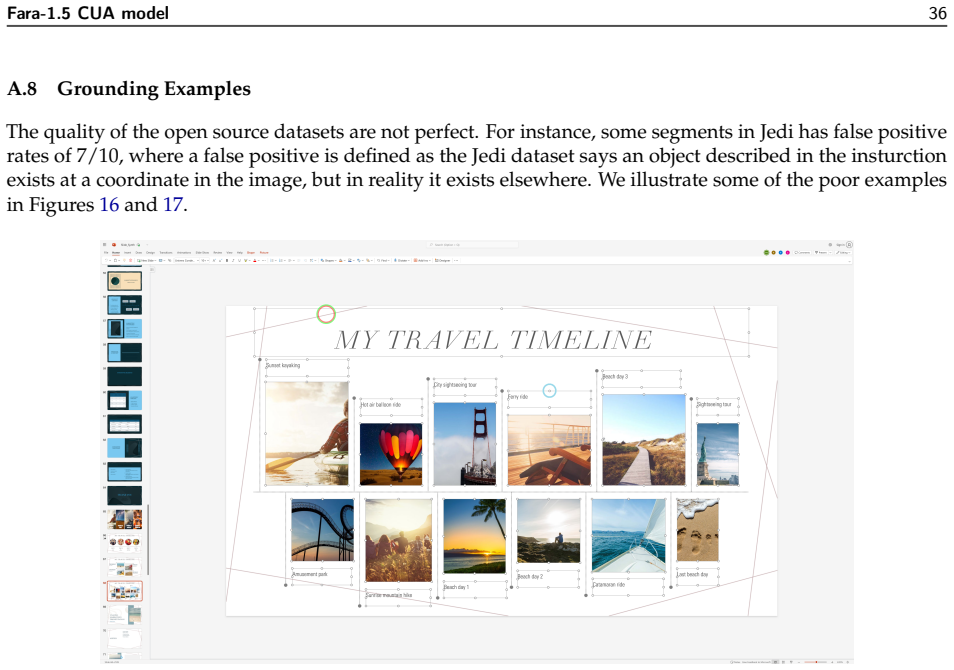

read the original abstract
Collecting computer use data from human demonstrations is expensive and slow, motivating the need for scalable generation strategies. This requires two key ingredients: environments in which agents can act and verifiers that can judge whether their demonstrations succeeded. We introduce FaraGen1.5, a scalable data pipeline for computer use agents composed of three modular components: environments, solvers, and verifiers. FaraGen1.5 uses both live websites and synthetic environments that faithfully simulate domains gated by authentication or that require irreversible actions. It employs a solver harness that can be powered by multiple models, including strong frontier models such as GPT-5.4, and also incorporates a user simulator to enable multi-turn rollouts. Finally, FaraGen1.5 scores the resulting trajectories with three complementary verifiers covering task correctness, efficiency, and critical-point adherence. Using data produced by this pipeline, we train Fara1.5, a family of native computer use agents (CUAs) at three scales built on Qwen3.5 (4B, 9B, and 27B). To train these models, we employ a supervised finetuning (SFT) recipe that carefully balances data from FaraGen1.5 for broad coverage, specific high-value tasks, and target model deficiencies in an iterative approach. Each model sets a new state of the art for its size class on browser-use benchmarks: Fara1.5-9B reaches 63.4% on Online-Mind2Web and 86.6% on WebVoyager, while Fara1.5-27B achieves 72.3% on Online-Mind2Web, which is competitive with much larger proprietary systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FaraGen1.5, a modular pipeline for scalable generation of computer-use agent training data. The pipeline combines live and synthetic environments, a solver harness (supporting frontier models such as GPT-5.4 and a user simulator for multi-turn rollouts), and three verifiers that score trajectories on task correctness, efficiency, and critical-point adherence. Data produced by the pipeline is used to train the Fara1.5 family (4B, 9B, 27B) via iterative, balanced supervised fine-tuning on Qwen3.5 backbones. The resulting models are reported to set new state-of-the-art results for their size classes on Online-Mind2Web (63.4 % for 9B, 72.3 % for 27B) and WebVoyager (86.6 % for 9B).
Significance. If the verifiers and synthetic environments produce high-quality, unbiased trajectories, the work supplies a concrete, scalable alternative to human demonstration collection and demonstrates that the resulting data can yield measurable gains on established browser-use benchmarks. The modular design and the iterative balancing procedure for covering model deficiencies constitute methodological contributions that could be reused by others.
major comments (2)
- [Pipeline description / verifiers paragraph] The headline SOTA claims rest on the assumption that the three verifiers (task correctness, efficiency, critical-point adherence) produce low false-positive rates and do not systematically favor particular solution styles. The manuscript provides no quantitative validation of this assumption (human agreement rates, ablation removing one verifier, or error analysis of accepted vs. rejected trajectories).
- [Environments component] The assertion that synthetic environments 'faithfully simulate' domains gated by authentication or requiring irreversible actions is stated without supporting evidence such as side-by-side comparisons, failure-mode analysis, or human validation of simulation fidelity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Pipeline description / verifiers paragraph] The headline SOTA claims rest on the assumption that the three verifiers (task correctness, efficiency, critical-point adherence) produce low false-positive rates and do not systematically favor particular solution styles. The manuscript provides no quantitative validation of this assumption (human agreement rates, ablation removing one verifier, or error analysis of accepted vs. rejected trajectories).
Authors: We agree that the current manuscript does not include quantitative validation of the verifiers. While the reported SOTA results offer indirect support for trajectory quality, direct evidence is needed. In the revised manuscript we will add (1) human agreement rates on a sampled subset of trajectories, (2) an ablation that removes each verifier in turn and reports the resulting change in accepted data volume and downstream model performance, and (3) an error analysis comparing characteristics of accepted versus rejected trajectories. revision: yes
-
Referee: [Environments component] The assertion that synthetic environments 'faithfully simulate' domains gated by authentication or requiring irreversible actions is stated without supporting evidence such as side-by-side comparisons, failure-mode analysis, or human validation of simulation fidelity.
Authors: We acknowledge that the manuscript asserts faithful simulation without accompanying evidence. We will add the requested supporting material: side-by-side comparisons (where live equivalents exist), a failure-mode analysis of the synthetic environments, and human validation results on simulation fidelity for the gated and irreversible-action domains. revision: yes
Circularity Check
No circularity: empirical pipeline and benchmark results with no derivation chain
full rationale
The paper presents a data-generation pipeline (environments, solvers, verifiers) and reports empirical SOTA benchmark scores on independent external tasks (Online-Mind2Web, WebVoyager). No equations, fitted parameters, predictions, or self-referential definitions appear. Central claims rest on measured performance rather than any reduction to inputs by construction, self-citation chains, or ansatz smuggling. The result is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AgentTrek: Agent Trajectory Synthesis via Guiding Replay with Web Tutorials. InThe Thirteenth International Conference on Learning Representations.https://openreview.net/forum?id=EEgYUccwsV Fara-1.5 CUA model 23 Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. 2024. Aguvis: Unified Pure Vision...
Pith/arXiv arXiv 2024
-
[2]
An Illusion of Progress? Assessing the Current State of Web Agents. arXiv:2504.01382 [cs.AI] https://arxiv.org/abs/2504.01382 An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang,...
arXiv 2025
-
[3]
Feel free to create mock user information and make assumptions freely
-
[4]
Make sure to answer all questions and provide all necessary details
-
[5]
Make sure any assumptions you make are reasonable and consistent with the conversation history
-
[6]
If the agent asks for preferences, make a clear choice
-
[7]
If the agent needs personal details (name, email, address, etc.), provide realistic fake information Guidelines for approval requests:
-
[8]
If the agent is requesting approval to proceed with an action (e.g., making a purchase, submitting a form), make sure it aligns with the original task
-
[9]
If the action seems reasonable and safe, approve it
-
[10]
Table 8: Task-proposal dimensions for online environments
If the action seems risky, unnecessary, or misaligned with the original task, deny it Fara-1.5 CUA model 27 Dimension # values Who decides Values Site 100s sampled popularity-weighted across 18 domain categories (e-commerce, travel, search-info, forms, food-delivery, social-media, government, finance, healthcare, news, education, real-estate, automotive, ...
-
[11]
Is naturally related to the conversation history and previous tasks/outputs
-
[12]
Could reasonably be asked by a user in this context
-
[13]
Leverages the current page state or information visible in the screenshot, but requires navigation beyond the current page
-
[14]
tell me more
Is specific and actionable (not vague like "tell me more")
-
[15]
Requires actions (clicking, navigating to new page), beyond just reading the page
-
[16]
The follow-up task should be slightly simpler than the original task but within similar complexity
-
[17]
What is the best pair of noise canceling headphones
Do not ever refer to https:// URLs directly in your feedback to the agent. Instead, refer to the general domain name (i.e, Google Flights) instead of an https URL. Examples of good follow-up tasks: - If the previous task was "What is the best pair of noise canceling headphones", a good follow-up: "can you see if this headphone is available on Amazon", a s...
2026
-
[18]
Selection 1.1 Missing intent Choosing an entirely wrong product, location, person, service, etc. 1.2 Unauthorized substitution Silently swapping an unavailable item for a similar alternative without reporting 1.3 Wrong action type Performing the wrong interaction on the correct entity 1.4 Wrong values / constraint violation Incorrect parameters, unsatisfi...
-
[19]
Hallucination 2.1 Output contradiction Evidence shows X, but agent claims not-X; includes misinterpreting page/tool content 2.2 Action contradiction Agent claims action was performed but evidence contradicts; action was achievable 2.3 Output fabrication Agent claims a fact with zero evidentiary basis; complete invention 2.4 Action fabrication Agent claims...
-
[20]
Execution & Strategy 3.1 Computational mistakes Correct methodology but wrong answer due to miscounting, arithmetic, or misreading 3.2 Platform non-compliance Not attempting the specified platform or silently switching sources 3.2.1 API-Sniffing Agent navigates to a site’s underlying JSON/REST API instead of the GUI URL the task implied, when the task / p...
-
[21]
Critical Point 4.1 Premature stop Stopped at critical point despite user explicitly granting permission 4.2 Violation Crossed transactional boundary without permission 4.3 Other Critical point error not covered above
-
[22]
Side-Effect 5.1 Unsolicited Any lasting modification, enrollment, or addition not requested 5.2 Other Side-effect error not covered above
-
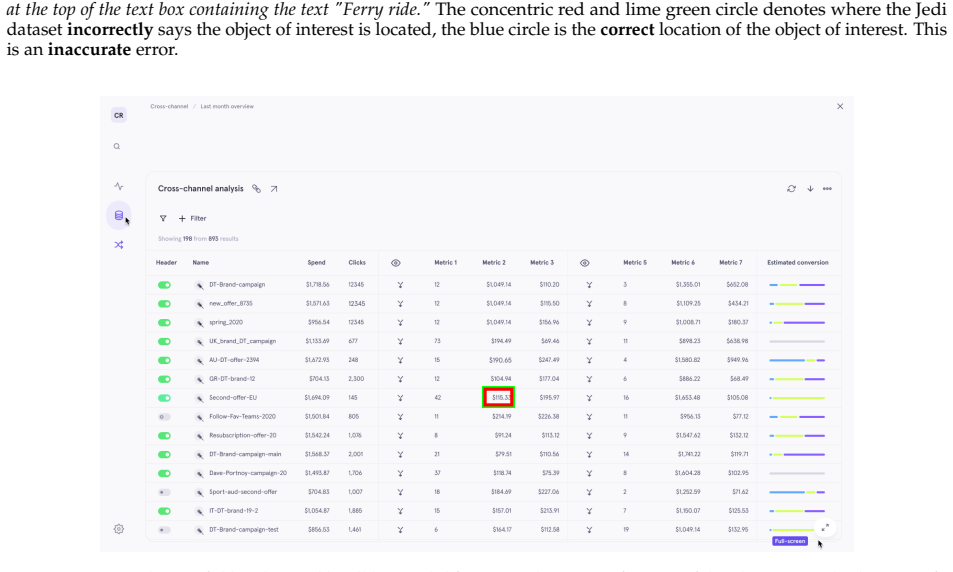
[23]
Ferry ride
Tool Interaction 6.1 Invalid invocation Tool call with wrong arguments (action exists but args are incorrect) 6.2 Hallucinated action Agent invokes a tool/action that does not exist in the action space 6.3 Intent-action mismatch Agent’s stated intent differs from actual tool call issued 6.4 Grounding error Correct target identified but (x, y) coordinates ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.