AgentMeter: Evaluating Model-CLI Matching for CLI-Based Local Task-Solving Agents
Pith reviewed 2026-06-26 14:00 UTC · model grok-4.3
The pith
Model-CLI pairs must be evaluated together because the same model yields different success, token, and cost results under different CLIs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
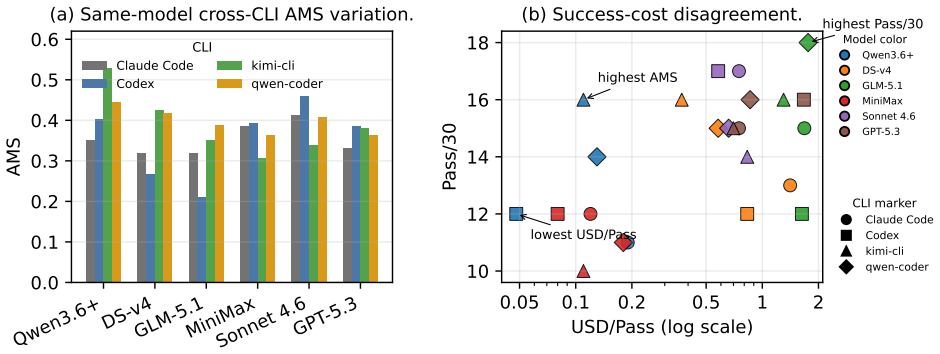
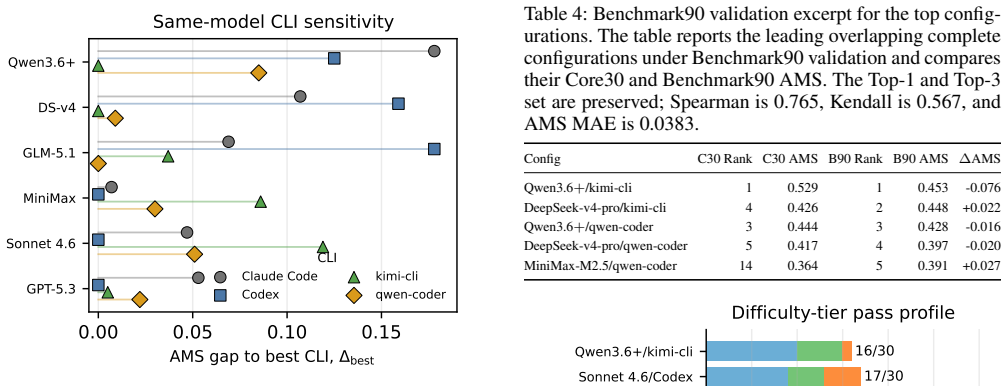
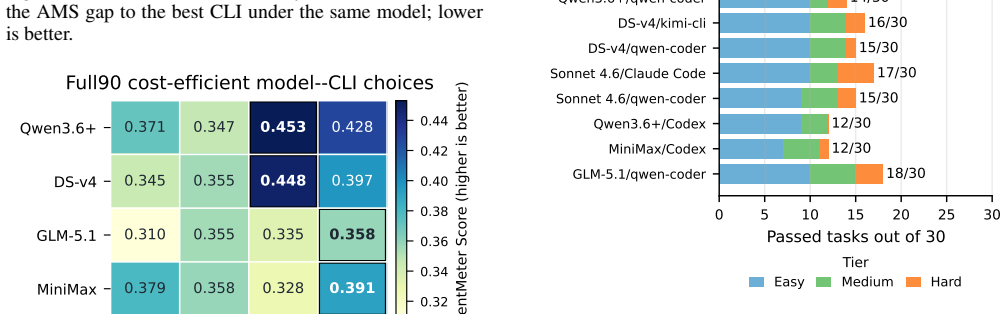
On Core30, highest Pass/30 selects GLM-5.1 with qwen-coder, lowest Tok./Pass selects GPT-5.3-Codex with kimi-cli, lowest billable USD/Pass selects Qwen3.6+ with Codex, while highest AMS selects Qwen3.6+ with kimi-cli. Benchmark90 validation preserves the Top-1 configuration and Top-3 set, with Spearman correlation 0.765, Kendall correlation 0.567, and AMS MAE 0.0383. These results show that model choice and CLI choice should not be decoupled, and that model-CLI configurations should be evaluated as the deployed unit.
What carries the argument
AgentMeter Score (AMS), a success-anchored, cost-aware metric over calibrated task-effort tiers that ranks complete model-CLI configurations.
Load-bearing premise
The Core30 and Benchmark90 tasks, together with their calibrated effort tiers, are representative of real-world CLI-mediated local task solving and produce unbiased comparisons across the 24 configurations.
What would settle it
Running the same 24 configurations on a fresh collection of real-world local tasks and finding that the AMS ranking or the identity of the top configuration changes substantially from the reported order.
Figures
read the original abstract
LLM agents increasingly solve local tasks through command-line and CLI-based harness interfaces, including code editing, repository inspection, data analysis, and file workflows. Existing evaluations often emphasize task success, but deployed local agents are not models alone: the CLI mediates prompts, context replay, tool outputs, file access, terminal observations, and stopping behavior. As a result, the same model can produce different success, token, and cost profiles under different CLIs. We introduce AGENTMETER, a benchmark for evaluating model-CLI matching in CLI-mediated local task-solving agents, together with AgentMeter Score (AMS), a success-anchored, cost-aware metric over calibrated task-effort tiers. AgentMeter uses Benchmark90 as the full validation set and Core30 as a lower-cost subset for expanded comparison across 24 complete model-CLI configurations. On Core30, common deployment criteria select different configurations: highest Pass/30 selects GLM-5.1 with qwen-coder, lowest Tok./Pass selects GPT-5.3-Codex with kimi-cli, lowest billable USD/Pass selects Qwen3.6+ with Codex, while highest AMS selects Qwen3.6+ with kimi-cli. Benchmark90 validation preserves the Top-1 configuration and Top-3 set, with Spearman correlation 0.765, Kendall correlation 0.567, and AMS MAE 0.0383. These results show that model choice and CLI choice should not be decoupled, and that model-CLI configurations should be evaluated as the deployed unit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AGENTMETER, a benchmark for evaluating model-CLI matching in CLI-mediated local task-solving agents. It defines the AgentMeter Score (AMS) as a success-anchored, cost-aware metric over calibrated task-effort tiers, evaluates 24 model-CLI configurations on Core30 (with Benchmark90 as validation), and reports that different deployment criteria select different top configurations (e.g., highest Pass/30 is GLM-5.1+qwen-coder while highest AMS is Qwen3.6+ with kimi-cli). Validation preserves the Top-1 and Top-3 sets with Spearman 0.765, Kendall 0.567, and AMS MAE 0.0383, supporting the claim that model and CLI choices should be evaluated jointly rather than decoupled.
Significance. If the Core30/Benchmark90 tasks and their effort-tier calibration are shown to be independent of the evaluated configurations and representative of real CLI-mediated tasks, the work would provide concrete evidence that joint model-CLI evaluation is necessary, with the preservation of top configurations across Core30 and Benchmark90 and the explicit reporting of multiple selection criteria as strengths. The empirical correlations and MAE offer a falsifiable basis for the joint-evaluation recommendation.
major comments (3)
- [Abstract] Abstract: The reported Spearman correlation 0.765, Kendall correlation 0.567, and AMS MAE 0.0383 are presented without error bars, confidence intervals, p-values, or details on the statistical procedure used to compute them; this directly weakens the claim that Benchmark90 validates the Core30 rankings and the central conclusion that model-CLI pairs must be evaluated jointly.
- [Abstract] Abstract (Core30/Benchmark90 description): The phrase 'calibrated effort tiers' is used without specifying the task sourcing criteria, selection process, or calibration procedure (e.g., whether tiers were set via independent pilots or derived from runs on the 24 model-CLI configurations under test); because the central claim rests on unbiased success/cost profiles across configurations, this omission is load-bearing for the reported divergences in winning configurations.
- [Abstract] Abstract: No information is given on exclusion rules, task difficulty balancing across the 24 configurations, or how the 30/90 task split was constructed; without these, the observation that common criteria select different winners (GLM-5.1+qwen-coder vs. Qwen3.6+ with kimi-cli) cannot be confidently attributed to genuine model-CLI interaction rather than benchmark artifacts.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that additional methodological details are needed to support the validation claims and will revise the abstract accordingly. The full manuscript contains expanded methods sections on task construction and calibration, but we will make the abstract self-contained on these points as requested.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported Spearman correlation 0.765, Kendall correlation 0.567, and AMS MAE 0.0383 are presented without error bars, confidence intervals, p-values, or details on the statistical procedure used to compute them; this directly weakens the claim that Benchmark90 validates the Core30 rankings and the central conclusion that model-CLI pairs must be evaluated jointly.
Authors: We agree the abstract should specify the statistical procedure. The correlations and MAE were computed directly on the per-configuration AMS values (n=24) using the standard definitions of Spearman's rho and Kendall's tau; the MAE is the mean absolute difference in AMS between Core30 and Benchmark90. With the modest sample size we omitted error bars in the initial version. We will add the computation details and bootstrap-derived 95% CIs to the revised abstract. revision: yes
-
Referee: [Abstract] Abstract (Core30/Benchmark90 description): The phrase 'calibrated effort tiers' is used without specifying the task sourcing criteria, selection process, or calibration procedure (e.g., whether tiers were set via independent pilots or derived from runs on the 24 model-CLI configurations under test); because the central claim rests on unbiased success/cost profiles across configurations, this omission is load-bearing for the reported divergences in winning configurations.
Authors: The effort tiers were assigned via independent pilot runs on a separate task pool before any of the 24 configurations were evaluated, using success-rate and token-consumption thresholds from those pilots. Task sourcing prioritized real CLI-mediated workflows (code editing, repo inspection, file operations) drawn from public issue trackers and tutorials. We will insert a concise description of the independent-pilot calibration into the abstract. revision: yes
-
Referee: [Abstract] Abstract: No information is given on exclusion rules, task difficulty balancing across the 24 configurations, or how the 30/90 task split was constructed; without these, the observation that common criteria select different winners (GLM-5.1+qwen-coder vs. Qwen3.6+ with kimi-cli) cannot be confidently attributed to genuine model-CLI interaction rather than benchmark artifacts.
Authors: Core30 was formed by stratified sampling from Benchmark90 to preserve the effort-tier distribution; exclusion rules removed tasks that were either solved by all pilots or unsolved by any pilot. Difficulty balancing was performed on the pilot data only. We will add these construction details to the abstract so readers can assess whether the observed winner divergence is attributable to model-CLI interaction. revision: yes
Circularity Check
No circularity detected in derivation or metric construction
full rationale
The manuscript contains no equations, derivations, fitted parameters, or self-citations. AMS is introduced as a direct combination of observed success rates and cost quantities over pre-defined task tiers; reported correlations (Spearman 0.765, Kendall 0.567) are computed from the empirical results on Core30 and Benchmark90 rather than being forced by construction. The central claim that model-CLI pairs must be evaluated jointly follows from the comparative measurements across the 24 configurations and does not reduce to any input by definition or self-reference.
Axiom & Free-Parameter Ledger
free parameters (1)
- task-effort tiers
Reference graph
Works this paper leans on
-
[1]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle =
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle =
-
[2]
2024 , note =
Terminal-Bench: A Benchmark for. 2024 , note =
2024
-
[3]
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and others , booktitle =
-
[4]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Li, Xiangyi and others , year =. doi:10.48550/arXiv.2602.12670 , url =. 2602.12670 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.12670
-
[5]
International Conference on Learning Representations (ICLR) , year =
Mialon, Gr. International Conference on Learning Representations (ICLR) , year =
-
[6]
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , booktitle =
-
[7]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =
-
[8]
2025 , howpublished =
2025
-
[9]
Chhikara, Prateek and Khant, Dev and Aryan, Saket and Singh, Taranjeet and Yadav, Deshraj , journal =
-
[10]
and Stoica, Ion and Gonzalez, Joseph E
Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G. and Stoica, Ion and Gonzalez, Joseph E. , journal =
-
[11]
and Kadous, M
Ong, Isaac and Almahairi, Amjad and Wu, Vincent and Chiang, Wei-Lin and Wu, Tianhao and Gonzalez, Joseph E. and Kadous, M. Waleed and Stoica, Ion , booktitle =
-
[12]
Chen, Lingjiao and Zaharia, Matei and Zou, James , journal =
-
[13]
2026 , howpublished =
2026
-
[14]
2026 , howpublished =
Model Release and Update Log for. 2026 , howpublished =
2026
-
[15]
2026 , howpublished =
Model Invocation Pricing for. 2026 , howpublished =
2026
-
[16]
Huang, Yiming and Lin, Jianwen and Zhou, Yiming and Wang, Jiaqi and others , journal =
-
[17]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Schick, Timo and Dwivedi-Yu, Janvier and Dess. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[19]
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and others , booktitle =
-
[20]
2024 , howpublished =
Prompt Caching with. 2024 , howpublished =
2024
-
[21]
and Zhang, Hao and Stoica, Ion , booktitle =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with
-
[22]
Proceedings of Machine Learning and Systems (MLSys) , year =
Efficiently Scaling Transformer Inference , author =. Proceedings of Machine Learning and Systems (MLSys) , year =
-
[25]
2024 , howpublished =
Introducing the Next Generation of. 2024 , howpublished =
2024
-
[26]
and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , booktitle =
Yang, John and Jimenez, Carlos E. and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , booktitle =
-
[27]
2024 , howpublished =
2024
-
[28]
arXiv preprint arXiv:2203.15556 , year =
Training Compute-Optimal Large Language Models , author =. arXiv preprint arXiv:2203.15556 , year =
-
[29]
and Song, Yufan and Li, Boxin and Tang, Yuxiang and Jain, Kritanjali and Bao, Mengxue and Wang, Zora Z
Xu, Frank F. and Song, Yufan and Li, Boxin and Tang, Yuxiang and Jain, Kritanjali and Bao, Mengxue and Wang, Zora Z. and others , booktitle =. On the Cost-Effectiveness of
-
[30]
Alibaba Cloud . 2026 a . Model Invocation Pricing for Alibaba Cloud Bailian Model Studio . https://help.aliyun.com/zh/model-studio/model-pricing. Official documentation; accessed 2026-06-04
2026
-
[31]
Alibaba Cloud . 2026 b . Model Release and Update Log for Alibaba Cloud Bailian Model Studio . https://help.aliyun.com/zh/model-studio/newly-released-models. Official documentation; accessed 2026-06-04
2026
-
[32]
Anthropic . 2024 a . Claude Code : A Command-Line Tool for Agentic Coding. https://docs.claude.com/en/docs/claude-code
2024
-
[33]
Anthropic . 2024 b . Prompt Caching with Claude . Anthropic Documentation. https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching
2024
-
[34]
Anthropic . 2026. Claude Models. https://docs.anthropic.com/en/docs/about-claude/models. Official documentation; accessed 2026-06-16
2026
-
[35]
Chen, L.; Zaharia, M.; and Zou, J. 2024. FrugalGPT : How to Use Large Language Models While Reducing Cost and Improving Performance. Transactions on Machine Learning Research (TMLR)
2024
-
[36]
Chhikara, P.; Khant, D.; Aryan, S.; Singh, T.; and Yadav, D. 2025. Mem0 : Building Production-Ready AI Agents with Scalable Long-Term Memory. arXiv preprint arXiv:2504.19413
Pith/arXiv arXiv 2025
-
[37]
GLM Team . 2024. ChatGLM : A Family of Large Language Models from GLM-130B to GLM-4 All Tools. arXiv preprint arXiv:2406.12793
Pith/arXiv arXiv 2024
-
[38]
Huang, Y.; Lin, J.; Zhou, Y.; Wang, J.; et al. 2024. DA-Code : Agent Data Science Code Generation Benchmark for Large Language Models. arXiv preprint arXiv:2410.07331
arXiv 2024
-
[39]
E.; Yang, J.; Wettig, A.; Yao, S.; Pei, K.; Press, O.; and Narasimhan, K
Jimenez, C. E.; Yang, J.; Wettig, A.; Yao, S.; Pei, K.; Press, O.; and Narasimhan, K. 2024. SWE-bench : Can Language Models Resolve Real-World GitHub Issues? In International Conference on Learning Representations (ICLR)
2024
-
[40]
H.; Gonzalez, J
Kwon, W.; Li, Z.; Zhuang, S.; Sheng, Y.; Zheng, L.; Yu, C. H.; Gonzalez, J. E.; Zhang, H.; and Stoica, I. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention . In Proceedings of the 29th Symposium on Operating Systems Principles (SOSP)
2023
-
[41]
Li, X.; et al. 2026. SkillsBench : Benchmarking How Well Agent Skills Work Across Diverse Tasks. arXiv:2602.12670
Pith/arXiv arXiv 2026
-
[42]
Liu, X.; Yu, H.; Zhang, H.; Xu, Y.; Lei, X.; Lai, H.; Gu, Y.; Ding, H.; Men, K.; Yang, K.; et al. 2024. AgentBench : Evaluating LLM s as Agents. In International Conference on Learning Representations (ICLR)
2024
-
[43]
Mialon, G.; Fourrier, C.; Swift, C.; Wolf, T.; LeCun, Y.; and Scialom, T. 2024. GAIA : A Benchmark for General AI Assistants. In International Conference on Learning Representations (ICLR)
2024
-
[44]
MiniMax Team . 2025. MiniMax-M2 : A Mixture-of-Experts Foundation Model. Technical Report
2025
-
[45]
Moonshot AI . 2026. Kimi Code CLI Quick Start. https://www.kimi.com/code/docs/en/kimi-code-cli/getting-started.html. Official documentation; accessed 2026-06-04
2026
-
[46]
E.; Kadous, M
Ong, I.; Almahairi, A.; Wu, V.; Chiang, W.-L.; Wu, T.; Gonzalez, J. E.; Kadous, M. W.; and Stoica, I. 2025. RouteLLM : Learning to Route LLM s with Preference Data. In International Conference on Learning Representations (ICLR)
2025
-
[47]
OpenAI . 2025. Codex CLI : Lightweight Coding Agent for the Terminal. https://github.com/openai/codex
2025
-
[48]
OpenAI . 2026. OpenAI Models. https://platform.openai.com/docs/models. Official documentation; accessed 2026-06-16
2026
-
[49]
G.; Stoica, I.; and Gonzalez, J
Packer, C.; Wooders, S.; Lin, K.; Fang, V.; Patil, S. G.; Stoica, I.; and Gonzalez, J. E. 2024. MemGPT : Towards LLM s as Operating Systems. arXiv preprint arXiv:2310.08560
Pith/arXiv arXiv 2024
-
[50]
Pope, R.; Douglas, S.; Chowdhery, A.; Devlin, J.; Bradbury, J.; Heek, J.; Xiao, K.; Agrawal, S.; and Dean, J. 2023. Efficiently Scaling Transformer Inference. Proceedings of Machine Learning and Systems (MLSys)
2023
-
[51]
Qin, Y.; Liang, S.; Ye, Y.; Zhu, K.; Yan, L.; Lu, Y.; Lin, Y.; Cong, X.; et al. 2024. ToolLLM : Facilitating Large Language Models to Master 16000+ Real-world APIs . In International Conference on Learning Representations (ICLR)
2024
-
[52]
Qwen Team . 2024. Qwen2.5 Technical Report. arXiv preprint arXiv:2412.15115
Pith/arXiv arXiv 2024
-
[53]
Qwen Team . 2025. Qwen-Coder : A Family of Code-Centric Large Language Models. https://github.com/QwenLM/qwen-coder
2025
-
[54]
Schick, T.; Dwivedi-Yu, J.; Dess \` , R.; Raileanu, R.; Lomeli, M.; Zettlemoyer, L.; Cancedda, N.; and Scialom, T. 2023. Toolformer : Language Models Can Teach Themselves to Use Tools. In Advances in Neural Information Processing Systems (NeurIPS)
2023
-
[55]
Stanford CRFM and Laude Institute . 2024. Terminal-Bench: A Benchmark for AI Agents in Terminal Environments. https://www.tbench.ai/
2024
-
[56]
E.; Wettig, A.; Lieret, K.; Yao, S.; Narasimhan, K.; and Press, O
Yang, J.; Jimenez, C. E.; Wettig, A.; Lieret, K.; Yao, S.; Narasimhan, K.; and Press, O. 2024. SWE-agent : Agent-Computer Interfaces Enable Automated Software Engineering. In Advances in Neural Information Processing Systems (NeurIPS)
2024
-
[57]
F.; Zhu, H.; Zhou, X.; Lo, R.; Sridhar, A.; Cheng, X.; Ou, T.; Bisk, Y.; Fried, D.; Alon, U.; and Neubig, G
Zhou, S.; Xu, F. F.; Zhu, H.; Zhou, X.; Lo, R.; Sridhar, A.; Cheng, X.; Ou, T.; Bisk, Y.; Fried, D.; Alon, U.; and Neubig, G. 2024. WebArena : A Realistic Web Environment for Building Autonomous Agents. In International Conference on Learning Representations (ICLR)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.