BIT-Nav: Brain-Inspired Trajectory Memory for Embodied Navigation
Pith reviewed 2026-06-26 13:50 UTC · model grok-4.3
The pith
A Bi-GRU encoder compresses navigation trajectories into one memory token that VLMs use at every step without growing token cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
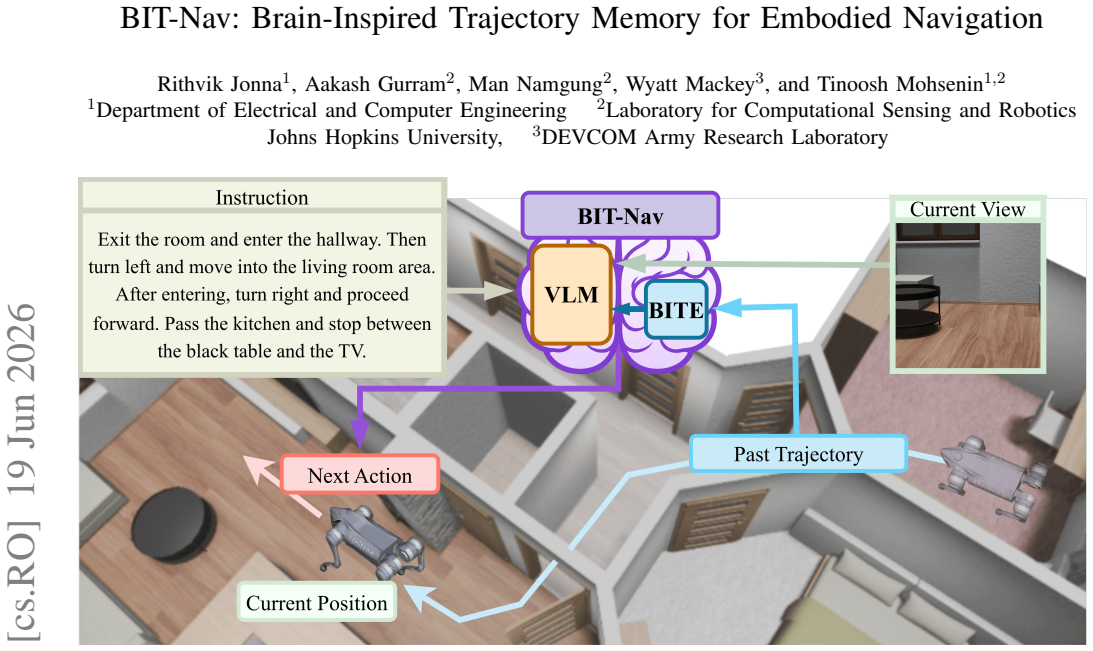
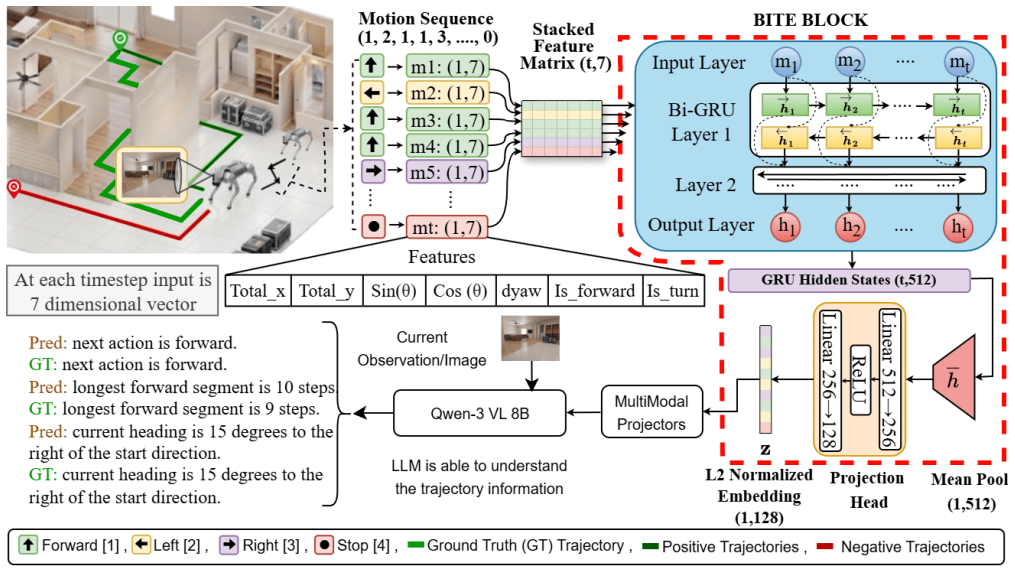
BIT-Nav augments frozen VLM navigation pipelines with a compact learned trajectory memory. Motivated by hippocampal path integration, it trains a Bi-GRU encoder over action and relative pose sequences via a multi-positive InfoNCE contrastive objective on trajectory prefixes sharing the same behavioral intent. The resulting embedding is projected into the VLM token space via a lightweight MLP and injected as a single memory token at each decision step, conditioning the model on structured motion history at constant token cost regardless of episode length.
What carries the argument
Bi-GRU encoder trained via multi-positive InfoNCE contrastive objective on trajectory prefixes sharing behavioral intent, whose output is projected by MLP into VLM token space as one memory token.
If this is right
- VLMs receive structured motion history at every step while token usage stays fixed regardless of episode length.
- Behavioral signals such as turning patterns and path topology become available without selecting additional frames.
- The same frozen VLM backbone can be used across short and long episodes without retraining or changing context length.
- Navigation decisions are conditioned on compressed episodic traces rather than sparse raw sensory replay.
Where Pith is reading between the lines
- The same single-token compression could be tested on other long-horizon sequential tasks such as robotic manipulation.
- An ablation that trains the encoder without the contrastive grouping would show whether behavioral-intent alignment is required for the reported gains.
- The approach might extend to non-navigation domains if the encoder is retrained on domain-appropriate action sequences.
Load-bearing premise
Training the Bi-GRU with contrastive loss on prefixes that share behavioral intent will extract the turning patterns, displacement, and path topology signals needed for long-horizon reasoning.
What would settle it
An experiment that replaces the learned memory token with a random vector or removes it entirely and measures whether long-episode navigation accuracy remains unchanged compared with the full system.
Figures
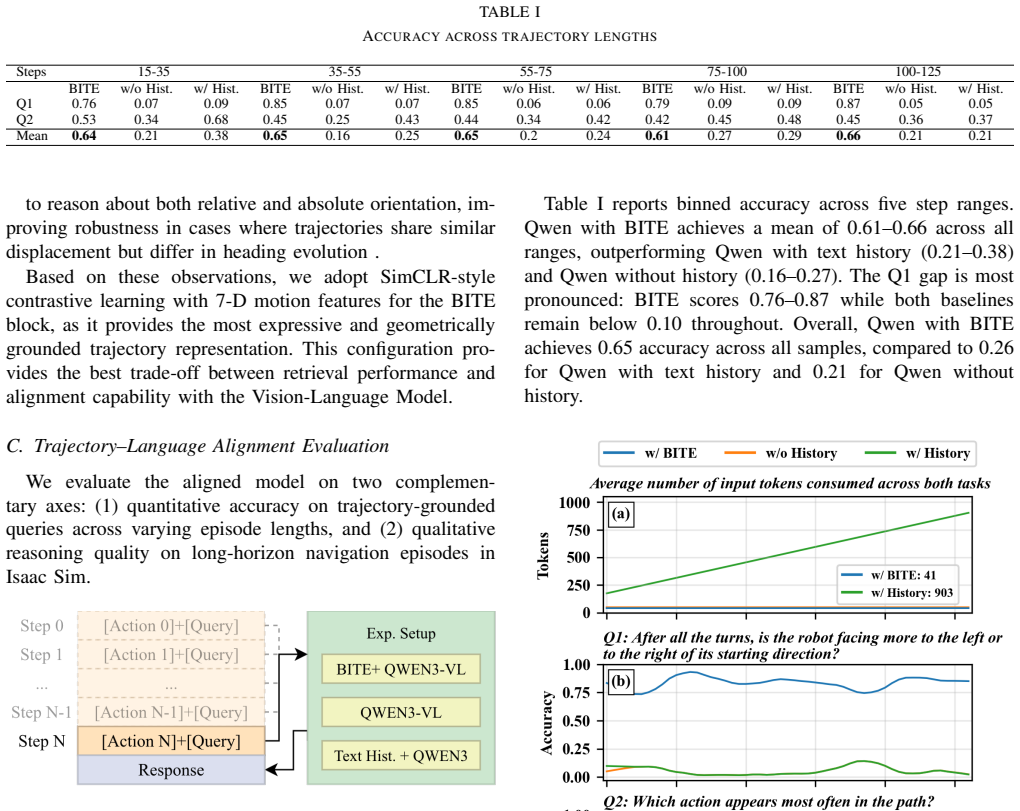

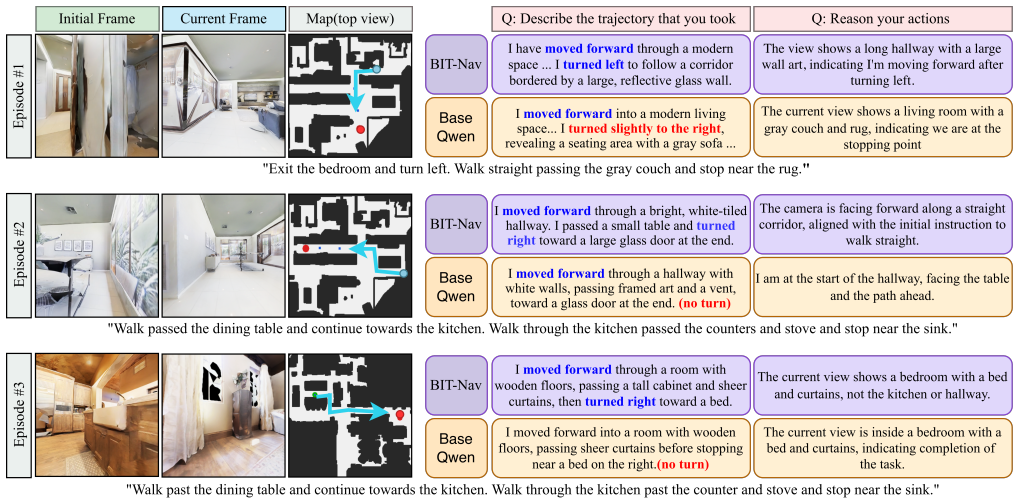
read the original abstract
Vision-Language Models (VLMs) for embodied navigation rely on selecting a fixed number of frames from a growing trajectory history. As episodes extend, this selection grows increasingly sparse, yet prior work shows no accuracy gain when scaling from 8 to 64 frames, suggesting the bottleneck is not frame quantity but the representation itself. Sparse frame selection cannot capture the structured behavioral signal that long-horizon reasoning requires: turning patterns, cumulative displacement, and path topology. We introduce BIT-Nav (Brain-Inspired Trajectory Memory for Navigation), a framework that augments frozen VLM navigation pipelines with a compact learned trajectory memory. Motivated by hippocampal path integration, where spatial experience is compressed into structured episodic traces rather than stored as raw sensory replay, BIT-Nav trains a Bi-GRU encoder over action and relative pose sequences via a multi-positive InfoNCE contrastive objective on trajectory prefixes sharing the same behavioral intent. The resulting embedding is projected into the VLM token space via a lightweight MLP and injected as a single memory token at each decision step, conditioning the model on structured motion history at constant token cost regardless of episode length
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BIT-Nav, a framework augmenting frozen VLM navigation pipelines with compact trajectory memory. A Bi-GRU encoder is trained on action and relative pose sequences via multi-positive InfoNCE contrastive learning on trajectory prefixes sharing behavioral intent; the resulting embedding is projected by a lightweight MLP into VLM token space and injected as a single memory token per decision step to supply structured motion history (turning patterns, cumulative displacement, path topology) at constant token cost independent of episode length.
Significance. If empirically validated, the approach could address a documented bottleneck in VLM embodied navigation by enabling constant-cost incorporation of long-horizon trajectory structure, motivated by hippocampal path integration. The use of contrastive training on intent-sharing prefixes and single-token injection is a clean architectural idea, but significance cannot be assessed without results.
major comments (1)
- [Abstract] Abstract: the central claim that the Bi-GRU embedding produced by multi-positive InfoNCE on intent-sharing prefixes encodes turning patterns, cumulative displacement, and path topology (rather than collapsing to coarser behavioral similarity) is load-bearing for the entire contribution, yet the manuscript supplies neither equations, derivations, nor any experimental results, baselines, or ablation data to support or refute this; the stress-test concern therefore stands unaddressed.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the recognition of the architectural idea. We address the single major comment below and commit to revisions that directly strengthen the evidential basis for the central claim.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the Bi-GRU embedding produced by multi-positive InfoNCE on intent-sharing prefixes encodes turning patterns, cumulative displacement, and path topology (rather than collapsing to coarser behavioral similarity) is load-bearing for the entire contribution, yet the manuscript supplies neither equations, derivations, nor any experimental results, baselines, or ablation data to support or refute this; the stress-test concern therefore stands unaddressed.
Authors: We agree that the current abstract states the intended representational properties of the embedding without accompanying equations or empirical support, leaving the claim unsubstantiated within the manuscript. The methods section describes the Bi-GRU architecture and multi-positive InfoNCE objective, but does not yet include derivations showing how the contrastive loss on intent-sharing prefixes encourages capture of turning patterns or topology, nor any ablation or baseline results. In the revised manuscript we will (1) add the explicit loss formulation and a short derivation linking the positive-pair construction to preservation of sequential structure, (2) insert a new experimental subsection with quantitative ablations (embedding reconstruction error on held-out trajectories, intent classification accuracy, and topology metrics) and baselines (random embeddings, single-positive InfoNCE, and non-contrastive GRU) demonstrating that the learned token encodes the claimed features rather than collapsing to coarse behavioral similarity, and (3) update the abstract to reference these results. These additions will directly address the stress-test concern. revision: yes
Circularity Check
No circularity; standard contrastive embedding is independent of target claims
full rationale
The paper's core construction trains a Bi-GRU via multi-positive InfoNCE on intent-sharing trajectory prefixes and projects the result as a single token. This is a conventional supervised embedding step whose loss and architecture are defined externally to the downstream VLM navigation accuracy; no equation equates the embedding to the geometric invariants it is later claimed to supply, and no self-citation or fitted-parameter renaming is present in the provided text. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Bi-GRU and MLP weights
axioms (2)
- domain assumption Hippocampal path integration compresses spatial experience into structured episodic traces rather than raw sensory replay
- domain assumption Multi-positive InfoNCE on prefixes sharing behavioral intent produces embeddings that capture turning patterns, displacement, and path topology
Reference graph
Works this paper leans on
-
[1]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu,et al., “Palm-e: An embodied multimodal language model,”arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
RT-2: Vision-language-action models transfer web knowledge to robotic control,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choro- manski,et al., “RT-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning (CoRL), 2023
2023
-
[3]
Vision-and-language nav- igation: Interpreting visually-grounded navigation instructions in real environments,
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S ¨underhauf, I. Reid, S. Gould, and A. van den Hengel, “Vision-and-language nav- igation: Interpreting visually-grounded navigation instructions in real environments,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3674–3683, 2018
2018
-
[4]
Beyond the nav-graph: Vision-and-language navigation in continuous environ- ments,
J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee, “Beyond the nav-graph: Vision-and-language navigation in continuous environ- ments,” inProceedings of the European Conference on Computer Vision (ECCV), pp. 104–120, 2020
2020
-
[5]
arXiv preprint arXiv:2412.04453 (2024)
A.-C. Cheng, Y . Ji, Z. Yang, Z. Gongye, X. Zou, J. Kautz, E. Bıyık, H. Yin, S. Liu, and X. Wang, “Navila: Legged robot vision-language- action model for navigation,”arXiv preprint arXiv:2412.04453, 2024
-
[6]
Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action,
D. Shah, B. Osi ´nski, S. Levine,et al., “Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action,” in Conference on Robot Learning (CoRL), pp. 492–504, 2023
2023
-
[7]
Think global, act local: Dual-scale graph transformer for vision-and-language navigation,
S. Chen, P.-L. Guhur, M. Tapaswi, C. Schmid, and I. Laptev, “Think global, act local: Dual-scale graph transformer for vision-and-language navigation,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 16537–16547, 2022
2022
-
[8]
Place cells, grid cells, and the brain’s spatial representation system,
E. I. Moser, E. Kropff, and M.-B. Moser, “Place cells, grid cells, and the brain’s spatial representation system,”Annual Review of Neuroscience, vol. 31, pp. 69–89, 2008
2008
-
[9]
Vector-based navigation using grid-like representations in artificial agents,
A. Banino, C. Barry, B. Uria, C. Blundell, T. Lillicrap, P. Mirowski, et al., “Vector-based navigation using grid-like representations in artificial agents,”Nature, vol. 557, pp. 429–433, 2018
2018
-
[10]
A simple frame- work for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple frame- work for contrastive learning of visual representations,” inProceed- ings of the International Conference on Machine Learning (ICML), pp. 1597–1607, 2020
2020
-
[11]
S. Baiet al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
VILA: On pretraining for visual language models,
J. Lin, H. Tang, H. Tang, S. Yang, X. Dang, C. Gan, and S. Han, “VILA: On pretraining for visual language models,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[13]
Room- across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding,
A. Ku, P. Anderson, R. Patel, E. Ie, and J. Baldridge, “Room- across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding,” inProceedings of the Conference on Em- pirical Methods in Natural Language Processing (EMNLP), pp. 4392– 4407, 2020
2020
-
[14]
Deep recurrent Q-learning for partially observable MDPs,
M. Hausknecht and P. Stone, “Deep recurrent Q-learning for partially observable MDPs,” inAAAI Fall Symposium on Sequential Decision Making for Intelligent Agents, 2015
2015
-
[15]
Target-driven visual navigation in indoor scenes using deep reinforcement learning,
Y . Zhu, R. Mottaghi, E. Kolve, J. J. Lim, A. Gupta, L. Fei-Fei, and A. Farhadi, “Target-driven visual navigation in indoor scenes using deep reinforcement learning,” inIEEE International Conference on Robotics and Automation (ICRA), pp. 3357–3364, 2017
2017
-
[16]
CURL: Contrastive unsuper- vised representations for reinforcement learning,
M. Laskin, A. Srinivas, and P. Abbeel, “CURL: Contrastive unsuper- vised representations for reinforcement learning,” inProceedings of the International Conference on Machine Learning (ICML), pp. 5639– 5650, 2020
2020
-
[17]
Data-efficient reinforcement learning with self- predictive representations,
M. Schwarzer, A. Anand, R. Goel, R. D. Hjelm, A. Courville, and P. Bachman, “Data-efficient reinforcement learning with self- predictive representations,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[18]
Semi-parametric topolog- ical memory for navigation,
N. Savinov, A. Dosovitskiy, and V . Koltun, “Semi-parametric topolog- ical memory for navigation,” inInternational Conference on Learning Representations (ICLR), 2018
2018
-
[19]
ViKiNG: Long-range navigation with kilometer-scale environments,
D. Shah, A. Sridhar, A. Bhorkar, N. Hirose, and S. Levine, “ViKiNG: Long-range navigation with kilometer-scale environments,” inRobotics: Science and Systems (RSS), 2022
2022
-
[20]
Speaker- follower models for vision-and-language navigation,
D. Fried, R. Hu, V . Cirik, A. Rohrbach, J. Andreas, L.-P. Morency, T. Berg-Kirkpatrick, K. Saenko, D. Klein, and T. Darrell, “Speaker- follower models for vision-and-language navigation,” inAdvances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[21]
History aware multimodal transformer for vision-and- language navigation,
S. Chenet al., “History aware multimodal transformer for vision-and- language navigation,” inNeurIPS, 2021
2021
-
[22]
VLN- BERT: A recurrent vision-and-language BERT for navigation,
Y . Hong, Q. Wu, Y . Qi, C. Rodriguez-Opazo, and I. Reid, “VLN- BERT: A recurrent vision-and-language BERT for navigation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1643–1653, 2021
2021
-
[23]
NavGPT: Explicit reasoning in vision- and-language navigation with large language models,
G. Zhou, Y . Hong, and Q. Wu, “NavGPT: Explicit reasoning in vision- and-language navigation with large language models,”arXiv preprint arXiv:2305.16986, 2024
-
[24]
EmbodiedGPT: Vision-language pre-training via embodied chain of thought,
Y . Mu, Q. Zhang, M. Hu, W. Wang, M. Ding, J. Jin, B. Wang, J. Dai, Y . Qiao, and P. Luo, “EmbodiedGPT: Vision-language pre-training via embodied chain of thought,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[25]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Mower, A. Balakrishna, S. Buc ¸ak,et al., “OpenVLA: An open-source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
A. Graves, G. Wayne, and I. Danihelka, “Neural turing machines,” arXiv preprint arXiv:1410.5401, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[27]
Hybrid computing using a neural network with dynamic external memory,
A. Graves, G. Wayne, M. Reynolds, T. Harley, I. Danihelka, A. Grabska-Barwinska,et al., “Hybrid computing using a neural network with dynamic external memory,”Nature, vol. 538, pp. 471– 476, 2016
2016
-
[28]
Recurrent memory trans- former,
A. Bulatov, Y . Kuratov, and M. Burtsev, “Recurrent memory trans- former,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[29]
Mem- former: A memory-augmented transformer for sequence modeling,
Q. Wu, Z. Lan, K. Qian, J. Gu, A. Geramifard, and Z. Yu, “Mem- former: A memory-augmented transformer for sequence modeling,” in Findings of the Association for Computational Linguistics (EMNLP), 2022
2022
-
[30]
Etpnav: Evolving topological planning for vision-language navigation in continuous environments,
D. An, H. Wang, W. Wang,et al., “Etpnav: Evolving topological planning for vision-language navigation in continuous environments,” arXiv preprint arXiv:2304.03047, 2023
-
[31]
Learning transferable visual models from natural language su- pervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, et al., “Learning transferable visual models from natural language su- pervision,” inProceedings of the International Conference on Machine Learning (ICML), pp. 8748–8763, 2021
2021
-
[32]
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,”arXiv preprint arXiv:2304.08485, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Flamingo: A visual language model for few-shot learning,
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Hasson, et al., “Flamingo: A visual language model for few-shot learning,” in Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[34]
InstructBLIP: Towards general-purpose vision-language models with instruction tuning,
W. Dai, J. Li, D. Li, A. M. H. Tiong, J. Zhao, W. Wang, B. Li, P. Fung, and S. Hoi, “InstructBLIP: Towards general-purpose vision-language models with instruction tuning,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[35]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, “Gaussian error linear units (gelus),” arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[36]
Short and long-term renewable electricity demand forecasting based on cnn- bi-gru model,
S. Zhao, Z. Xu, Z. Zhu, X. Liang, Z. Zhang, and R. Jiang, “Short and long-term renewable electricity demand forecasting based on cnn- bi-gru model,”ICCK Transactions on Emerging Topics in Artificial Intelligence, vol. 2, no. 1, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.