Is Agent Code Less Maintainable Than Human Code?
Pith reviewed 2026-06-26 13:15 UTC · model grok-4.3
The pith
Agents resolve up to 13.1% fewer tasks when extending prior agent code than when extending human code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
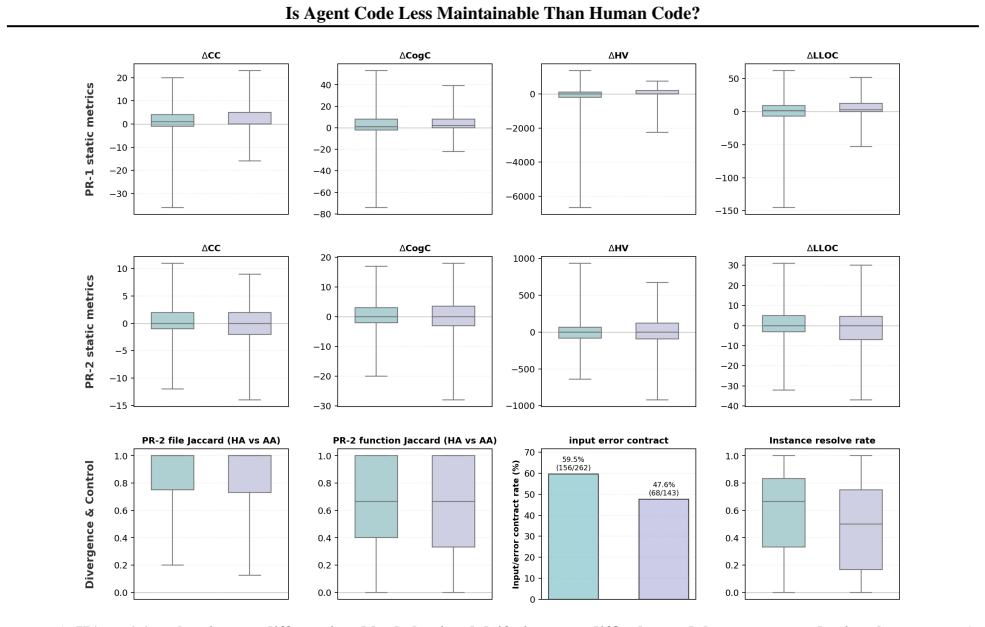
When subsequent coding agents attempt to resolve maintenance tasks on code previously written by agents, their success rate falls by as much as 13.1 percentage points relative to the same tasks on human-written code. Regression analysis indicates that many standard software maintainability metrics do not predict this performance difference. Instead, the gap correlates with subtler behavioral patterns in agent code, including alterations to input validation and error handling, together with measurable differences in the size of downstream code and the inherent difficulty of the tasks.
What carries the argument
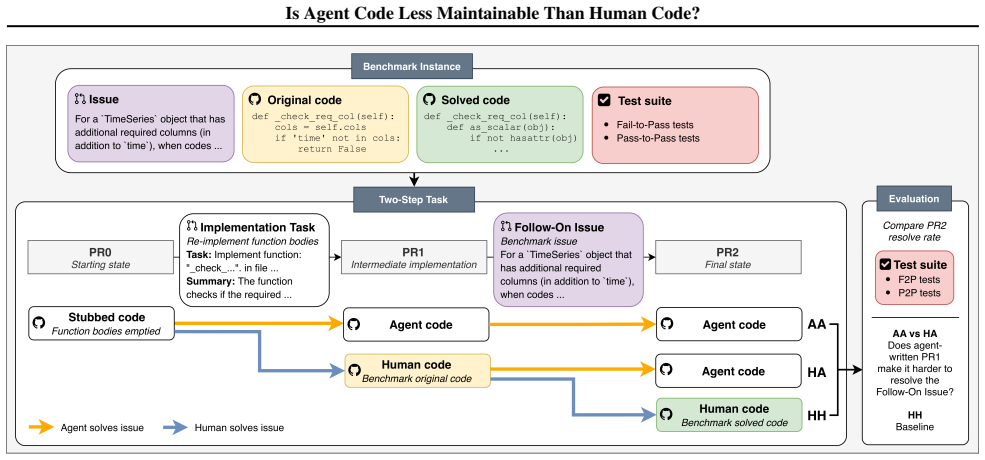
CodeThread, a framework that constructs controlled experiments from repository-level coding benchmarks to isolate the effect of prior code authorship on later agent task resolution.
Load-bearing premise
The CodeThread framework and chosen benchmarks separate the effects of code authorship from confounding factors such as task difficulty and downstream code size.
What would settle it
An experiment that shows equal task resolution rates for agent and human base code after matching on task difficulty and code size, or that finds conventional maintainability metrics strongly predicting the observed performance drop.
Figures

read the original abstract
Maintainability is a core dimension of software engineering, shaping how code is written, reviewed, and developed over time. While coding agents have demonstrated strong performance on single-issue tasks, it remains unclear how maintainable their code is when future agents build on top of it, potentially leading to compounding downstream effects. We investigate how agent code compares to human code in these maintenance settings, presenting CodeThread, a framework to construct controlled experiments from repository-level coding benchmarks. Applying CodeThread to four frontier coding agents and four benchmarks, we find that agents are less effective at resolving tasks when building on agent code compared to human code, with task resolve rate drops of up to 13.1%. Regression analysis reveals that many traditional software engineering maintainability metrics do not explain this difference. Instead, the clearest signals are subtler behavioral differences in agent code, such as changes to input validation and error handling, along with differences in downstream code size and task difficulty. These findings highlight the need to evaluate these systems not only by immediate task resolution but also by code maintainability, and point to potential sources of downstream errors introduced by agent code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the CodeThread framework to construct paired human- and agent-generated code threads from repository-level benchmarks, enabling controlled comparison of maintainability. Applying the framework to four frontier agents and four benchmarks, the authors report that agents resolve subsequent tasks at lower rates (drops of up to 13.1%) when building on prior agent code versus human code. Regression analysis finds that conventional maintainability metrics fail to explain the gap; instead, behavioral differences (e.g., input validation and error handling), downstream code size, and task difficulty emerge as stronger signals. The work concludes that coding-agent evaluation must incorporate long-term maintainability considerations.
Significance. If the CodeThread construction successfully isolates maintainability effects, the result would provide concrete empirical evidence that agent-generated code introduces downstream resolution penalties not captured by standard metrics. The use of multiple agents and benchmarks, together with regression to surface alternative explanatory factors, supplies a falsifiable, data-driven basis for rethinking single-task agent benchmarks. The framework itself could become a reusable tool for the community.
major comments (3)
- [§3, §4.2] §3 (CodeThread construction) and §4.2 (pairing procedure): the description of how human/agent thread pairs are formed does not report explicit matching, stratification, or pre-regression balancing on task difficulty or downstream code size. Because the abstract and §5.3 identify these two variables as the clearest signals, the absence of documented controls leaves the maintainability interpretation vulnerable to the alternative that observed resolve-rate drops reflect correlated task or size differences rather than maintainability per se.
- [§5.3] §5.3 (regression results): while the text states that traditional metrics do not explain the difference, the reported models do not appear to include interaction terms or controls that would test whether the 13.1% drop persists after conditioning on the very signals (code size, task difficulty) the authors flag as dominant. Without these, the claim that maintainability is the operative factor rests on an untested isolation assumption.
- [Table 2, Figure 4] Table 2 / Figure 4 (resolve-rate deltas): the reported maximum drop of 13.1% is presented without per-benchmark sample sizes, confidence intervals, or exclusion criteria. Given that the central quantitative claim is a specific percentage difference, the lack of these details prevents assessment of whether the effect is robust or driven by a small number of threads.
minor comments (2)
- [Abstract, §4] The abstract lists sample sizes, statistical controls, and error bars as absent; the full text should supply these in §4 and §5 even if they were omitted from the abstract.
- [§3] Notation for the CodeThread threading process (e.g., how “downstream” tasks are selected) is introduced without a formal definition or pseudocode; a small diagram or algorithm box would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for these constructive comments. We address each major point below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [§3, §4.2] §3 (CodeThread construction) and §4.2 (pairing procedure): the description of how human/agent thread pairs are formed does not report explicit matching, stratification, or pre-regression balancing on task difficulty or downstream code size. Because the abstract and §5.3 identify these two variables as the clearest signals, the absence of documented controls leaves the maintainability interpretation vulnerable to the alternative that observed resolve-rate drops reflect correlated task or size differences rather than maintainability per se.
Authors: CodeThread pairs are formed by running both human and agent workflows on identical task sequences drawn from the same repository benchmarks, which matches on task identity by construction. We did not apply explicit pre-regression stratification or balancing on downstream code size or task difficulty because these variables surfaced as post-hoc explanatory factors rather than a priori confounders. We acknowledge that documenting their distributions and any sensitivity checks would strengthen the isolation claim. In revision we will add descriptive statistics, balance tables, and, where feasible, propensity-score or stratification checks on these variables. revision: yes
-
Referee: [§5.3] §5.3 (regression results): while the text states that traditional metrics do not explain the difference, the reported models do not appear to include interaction terms or controls that would test whether the 13.1% drop persists after conditioning on the very signals (code size, task difficulty) the authors flag as dominant. Without these, the claim that maintainability is the operative factor rests on an untested isolation assumption.
Authors: The regressions in §5.3 were constructed to test the explanatory power of conventional maintainability metrics; code size and task difficulty were examined separately as dominant signals. To directly address the isolation concern we will add supplementary regressions that include code size and task difficulty as covariates and report the agent-code coefficient after conditioning on them. Interaction terms will be included if they improve fit or are theoretically motivated. revision: yes
-
Referee: [Table 2, Figure 4] Table 2 / Figure 4 (resolve-rate deltas): the reported maximum drop of 13.1% is presented without per-benchmark sample sizes, confidence intervals, or exclusion criteria. Given that the central quantitative claim is a specific percentage difference, the lack of these details prevents assessment of whether the effect is robust or driven by a small number of threads.
Authors: We agree that sample sizes, confidence intervals, and exclusion criteria are required to evaluate the 13.1% figure. In the revised manuscript we will expand Table 2 and Figure 4 to report per-benchmark thread counts, 95% bootstrap or binomial confidence intervals, and the explicit exclusion rules applied during CodeThread construction. revision: yes
Circularity Check
No circularity: purely empirical measurements and regressions
full rationale
The paper constructs CodeThread to generate paired code threads from existing benchmarks, then measures task resolve rates and runs standard regression analysis on maintainability metrics. No equations, derivations, or self-citations appear in the provided text that reduce any reported difference (e.g., the 13.1% resolve-rate drop) to a fitted parameter or prior result by construction. The central findings rest on direct observation of agent vs. human code performance and post-hoc regression coefficients, which are falsifiable against the benchmarks and do not invoke uniqueness theorems or ansatzes from the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four selected frontier coding agents and four benchmarks are representative of broader agent behavior and real maintenance tasks.
invented entities (1)
-
CodeThread framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2026 , howpublished =
2026
-
[2]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[3]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[4]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[5]
2024 , url=
John Yang and Carlos E Jimenez and Alexander Wettig and Kilian Lieret and Shunyu Yao and Karthik R Narasimhan and Ofir Press , booktitle=. 2024 , url=
2024
-
[6]
2024 , url=
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=. 2024 , url=
2024
-
[7]
Ann , booktitle=
Campbell, G. Ann , booktitle=. Cognitive Complexity — An Overview and Evaluation , year=
-
[8]
Cyclomatic Complexity , year=
Ebert, Christof and Cain, James and Antoniol, Giuliano and Counsell, Steve and Laplante, Phillip , journal=. Cyclomatic Complexity , year=
-
[9]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[10]
2026 , eprint=
SWE-EVO: Benchmarking Coding Agents in Long-Horizon Software Evolution Scenarios , author=. 2026 , eprint=
2026
-
[11]
2024 , url =
SWE-bench Verified , author =. 2024 , url =
2024
-
[12]
2025 , url=
SWE-bench Multilingual , author=. 2025 , url=
2025
-
[13]
2025 , eprint=
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving , author=. 2025 , eprint=
2025
-
[14]
2025 , eprint=
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks? , author=. 2025 , eprint=
2025
-
[15]
2025 , eprint=
SWE-smith: Scaling Data for Software Engineering Agents , author=. 2025 , eprint=
2025
-
[16]
2025 , eprint=
SWE-PolyBench: A multi-language benchmark for repository level evaluation of coding agents , author=. 2025 , eprint=
2025
-
[17]
2026 , eprint=
SWE-rebench V2: Language-Agnostic SWE Task Collection at Scale , author=. 2026 , eprint=
2026
-
[18]
arXiv preprint arXiv:2509.22237 , year=
FeatBench: Evaluating Coding Agents on Feature Implementation for Vibe Coding , author=. arXiv preprint arXiv:2509.22237 , year=
-
[19]
2025 , eprint=
RefactorBench: Evaluating Stateful Reasoning in Language Agents Through Code , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint=
SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models , author=. 2025 , eprint=
2025
-
[21]
arXiv preprint arXiv:2603.24755 , year=
SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks , author=. arXiv preprint arXiv:2603.24755 , year=
-
[22]
2026 , eprint=
CodeFlowBench: A Multi-turn, Iterative Benchmark for Complex Code Generation , author=. 2026 , eprint=
2026
-
[23]
2025 , eprint=
SWE-Bench-CL: Continual Learning for Coding Agents , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
MaintainCoder: Maintainable Code Generation Under Dynamic Requirements , author=. 2025 , eprint=
2025
-
[25]
2026 , eprint=
daVinci-Agency: Unlocking Long-Horizon Agency Data-Efficiently , author=. 2026 , eprint=
2026
-
[26]
2026 , eprint=
SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration , author=. 2026 , eprint=
2026
-
[27]
arXiv preprint arXiv:2508.06471 , year=
Glm-4.5: Agentic, reasoning, and coding (arc) foundation models , author=. arXiv preprint arXiv:2508.06471 , year=
-
[28]
Claude Sonnet 4.5 , author=
-
[29]
MiniMax M2.5 , author=
-
[30]
1977 , publisher =
Elements of Software Science , author =. 1977 , publisher =
1977
-
[31]
Proceedings of the IEEE/ACM 46th International Conference on Software Engineering , articleno =
Zhang, Zejun and Xing, Zhenchang and Zhao, Dehai and Lu, Qinghua and Xu, Xiwei and Zhu, Liming , title =. Proceedings of the IEEE/ACM 46th International Conference on Software Engineering , articleno =. 2024 , isbn =. doi:10.1145/3597503.3639101 , abstract =
-
[32]
2025 , eprint=
The Rise of AI Teammates in Software Engineering (SE) 3.0: How Autonomous Coding Agents Are Reshaping Software Engineering , author=. 2025 , eprint=
2025
-
[33]
2025 , eprint=
Training Language Models to Generate Quality Code with Program Analysis Feedback , author=. 2025 , eprint=
2025
-
[34]
and Kemerer, C.F
Chidamber, S.R. and Kemerer, C.F. , journal=. A metrics suite for object oriented design , year=
-
[35]
and Ash, D
Coleman, D. and Ash, D. and Lowther, B. and Oman, P. , journal=. Using metrics to evaluate software system maintainability , year=
-
[36]
2014 , month = aug, howpublished =
van Deursen, Arie , title =. 2014 , month = aug, howpublished =
2014
-
[37]
and Weimer, Westley R
Buse, Raymond P.L. and Weimer, Westley R. , journal=. Learning a Metric for Code Readability , year=
-
[38]
Riaz, Mehwish and Mendes, Emilia and Tempero, Ewan , title =. Proceedings of the 2009 3rd International Symposium on Empirical Software Engineering and Measurement , pages =. 2009 , isbn =. doi:10.1109/ESEM.2009.5314233 , abstract =
-
[39]
Scientific Programming , volume =
Ardito, Luca and Coppola, Riccardo and Barbato, Luca and Verga, Diego , title =. Scientific Programming , volume =. doi:https://doi.org/10.1155/2020/8840389 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1155/2020/8840389 , abstract =
-
[40]
2025 , eprint=
Investigating The Smells of LLM Generated Code , author=. 2025 , eprint=
2025
-
[41]
2025 , type =
Harding, William and Kloster, Matthew , title =. 2025 , type =
2025
-
[42]
Journal of Systems and Software , volume=
Comprehension strategies and difficulties in maintaining object-oriented systems: An explorative study , author=. Journal of Systems and Software , volume=. 2007 , publisher=
2007
-
[43]
Computer , volume=
Program comprehension during software maintenance and evolution , author=. Computer , volume=. 2002 , publisher=
2002
-
[44]
Proceedings of the 5th International Workshop on Requirements Engineering and Testing , pages=
Ambiguous software requirement specification detection: An automated approach , author=. Proceedings of the 5th International Workshop on Requirements Engineering and Testing , pages=
-
[45]
2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE) , pages=
Improving fault localization by integrating value and predicate based causal inference techniques , author=. 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE) , pages=. 2021 , organization=
2021
-
[46]
Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering , pages=
Techniques for improving regression testing in continuous integration development environments , author=. Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering , pages=
-
[47]
Empirical Software Engineering , volume=
Automated patch assessment for program repair at scale , author=. Empirical Software Engineering , volume=. 2021 , publisher=
2021
-
[48]
FSE’11 , year=
How do fixes become bugs?--a comprehensive characteristic study on incorrect fixes in commercial and open source operating systems , author=. FSE’11 , year=
-
[49]
2012 34th international conference on software engineering (icse) , pages=
Improving early detection of software merge conflicts , author=. 2012 34th international conference on software engineering (icse) , pages=. 2012 , organization=
2012
-
[50]
2017 IEEE/ACM 14th International Conference on Mining Software Repositories (MSR) , pages=
Insights into continuous integration build failures , author=. 2017 IEEE/ACM 14th International Conference on Mining Software Repositories (MSR) , pages=. 2017 , organization=
2017
-
[51]
IEEE access , volume=
Continuous integration, delivery and deployment: a systematic review on approaches, tools, challenges and practices , author=. IEEE access , volume=. 2017 , publisher=
2017
-
[52]
ISO/IEC quality standards for AI engineering , year =
Oviedo, Jes\'. ISO/IEC quality standards for AI engineering , year =. doi:10.1016/j.cosrev.2024.100681 , journal =
-
[53]
2026 , eprint=
Debt Behind the AI Boom: A Large-Scale Empirical Study of AI-Generated Code in the Wild , author=. 2026 , eprint=
2026
-
[54]
Journal of Systems and Software , pages=
Quality assurance of LLM-generated code: Addressing non-functional quality characteristics , author=. Journal of Systems and Software , pages=. 2026 , publisher=
2026
-
[55]
2026 , eprint=
Does Pass Rate Tell the Whole Story? Evaluating Design Constraint Compliance in LLM-based Issue Resolution , author=. 2026 , eprint=
2026
-
[56]
arXiv preprint arXiv:2601.20109 , year=
Beyond Bug Fixes: An Empirical Investigation of Post-Merge Code Quality Issues in Agent-Generated Pull Requests , author=. arXiv preprint arXiv:2601.20109 , year=
-
[57]
2026 , eprint=
More Code, Less Reuse: Investigating Code Quality and Reviewer Sentiment towards AI-generated Pull Requests , author=. 2026 , eprint=
2026
-
[58]
2026 , eprint=
AI IDEs or Autonomous Agents? Measuring the Impact of Coding Agents on Software Development , author=. 2026 , eprint=
2026
-
[59]
Mu\. An Empirical Validation of Cognitive Complexity as a Measure of Source Code Understandability , year =. Proceedings of the 14th ACM / IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM) , articleno =. doi:10.1145/3382494.3410636 , abstract =
-
[60]
Ehsan Mashhadi and Shaiful Chowdhury and Somayeh Modaberi and Hadi Hemmati and Gias Uddin , keywords =. An empirical study on bug severity estimation using source code metrics and static analysis , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.jss.2024.112179 , url =
-
[61]
2026 , eprint=
SWE-Adept: An LLM-Based Agentic Framework for Deep Codebase Analysis and Structured Issue Resolution , author=. 2026 , eprint=
2026
-
[62]
CodeSkelGen-A program skeleton generator , author=
-
[63]
2008 21st Conference on Software Engineering Education and Training , pages=
Teaching object-oriented software engineering through problem-based learning in the context of game design , author=. 2008 21st Conference on Software Engineering Education and Training , pages=. 2008 , organization=
2008
-
[64]
2025 , eprint=
An Empirical Study on Failures in Automated Issue Solving , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.