Mat-Pref: Verifiable-Reward Training Improves Compositional Reasoning in Inorganic Materials
Pith reviewed 2026-06-26 12:37 UTC · model grok-4.3
The pith
Verifiable-reward training on a materials benchmark lets an 8B model outperform 235B models on compositional reasoning about inorganic structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
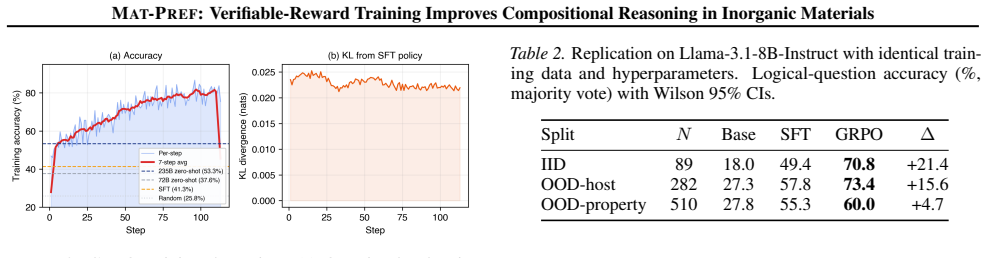
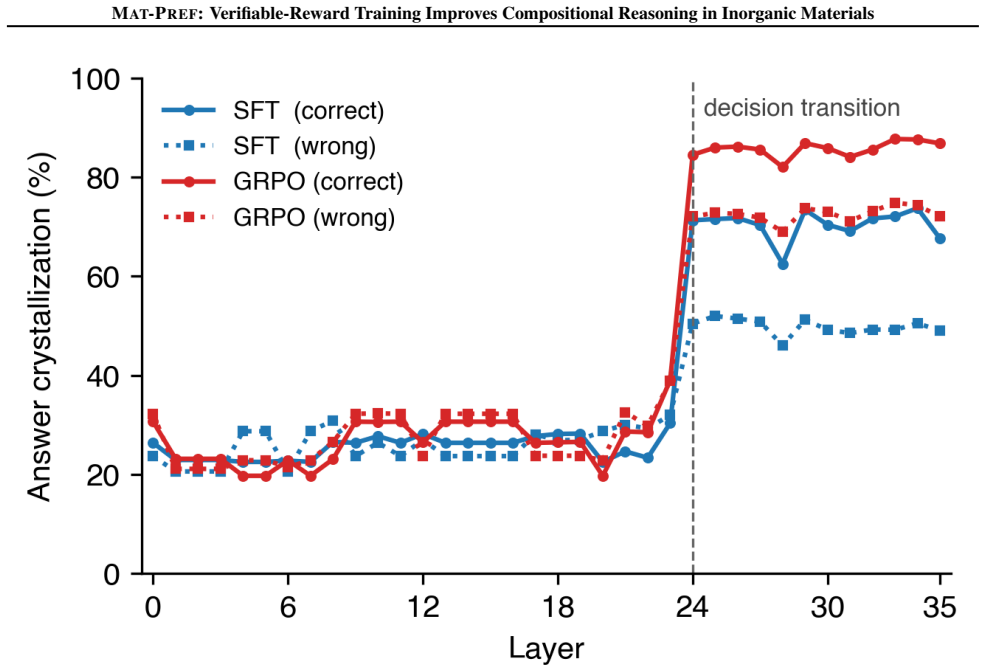
A two-stage pipeline of supervised fine-tuning followed by Group Relative Policy Optimization lifts Qwen3-8B to 65.2 percent in-distribution and 71.6 percent on held-out families, exceeding zero-shot Qwen3-235B by over 20 percentage points on both structural-generalization splits. Self-consistency sampling shows that the SFT policy can already produce correct answers but cannot reliably surface them as the modal response; GRPO reshapes the distribution so that correct answers become modal rather than merely reachable, and this sharper commitment is visible mechanistically through logit lens analysis revealing a ~20pp advantage in answer crystallization at the critical decision layer. The pap
What carries the argument
Group Relative Policy Optimization (GRPO) applied after supervised fine-tuning, which reshapes the output distribution so correct answers become the modal response.
If this is right
- The post-GRPO model makes correct answers the modal response rather than merely reachable through sampling.
- Structural generalization to entirely held-out crystal structure families improves substantially.
- Cross-property transfer, such as applying band-gap reasoning to hosts seen only through formation-energy supervision, becomes viable.
- Logit lens analysis shows a roughly 20 percentage point advantage in answer crystallization at the critical decision layer.
- The distractor-permutation consistency metric narrows the gap between lenient and strict scoring from 24.0 to 14.3 percentage points.
Where Pith is reading between the lines
- The verifiable-reward pipeline could be tested on other scientific domains that supply simulation or database ground truth, such as molecular property prediction.
- The held-out-family split design offers a template for diagnosing memorization versus generalization in other language-model reasoning benchmarks.
- Logit lens diagnostics might help identify which post-training methods reliably produce modal correct answers across tasks.
- If the gains persist under stricter leakage controls, the result would favor investing in targeted post-training over further scale alone for scientific applications.
Load-bearing premise
The three evaluation splits isolate true structural generalization and cross-property transfer without the model having memorized specific compound-property pairs or benefited from leakage in question generation.
What would settle it
If the same two-stage training is repeated on a version of the benchmark in which structure-family labels are randomly scrambled and the performance advantage over zero-shot baselines disappears, the claim that the model learned compositional reasoning would be falsified.
Figures



read the original abstract
Reinforcement learning from verifiable rewards (RLVR) has driven rapid progress in mathematical and code reasoning, but when extended to science, existing benchmarks do not decompose what generalizes: do gains reflect structural transfer, property transfer, or memorization? We introduce Mat-Pref, a benchmark of 10,837 ionic-substitution questions across 11 inorganic structure families, grounded in density functional theory calculations from the Materials Project, with three evaluation splits that isolate in-distribution performance, generalization to entirely held-out structure families, and cross-property transfer: applying band-gap reasoning to hosts seen during training only through formation-energy supervision. Four zero-shot frontier models (70-671B parameters) remain in the 33-54% range on every split, confirming that scale alone does not resolve the compositional chemical reasoning this task demands. A two-stage pipeline of supervised fine-tuning followed by Group Relative Policy Optimization (GRPO) lifts Qwen3-8B to 65.2% in-distribution and 71.6% on held-out families, exceeding zero-shot Qwen3-235B by over 20 percentage points on both structural-generalization splits. Self-consistency sampling shows that the SFT policy can already produce correct answers but cannot reliably surface them as the modal response; GRPO reshapes the distribution so that correct answers become modal rather than merely reachable, and this sharper commitment is visible mechanistically: logit lens analysis reveals a ${\sim}$20pp advantage in answer crystallization at the critical decision layer. We formalize this observation as a distractor-permutation consistency metric under which GRPO narrows the gap between lenient scoring (at least one permutation correct) and strict scoring (all permutations correct) from 24.0 to 14.3 percentage points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Mat-Pref, a benchmark of 10,837 ionic-substitution questions derived from Materials Project DFT data across 11 inorganic structure families. It defines three evaluation splits to separately measure in-distribution performance, generalization to held-out structure families, and cross-property transfer (e.g., band-gap reasoning on hosts seen only via formation-energy training). The central empirical claim is that supervised fine-tuning followed by Group Relative Policy Optimization (GRPO) on Qwen3-8B yields 65.2% accuracy in-distribution and 71.6% on held-out families, outperforming zero-shot Qwen3-235B by more than 20 points on the generalization splits. The paper further analyzes the effect of GRPO using self-consistency sampling and logit-lens techniques, introducing a distractor-permutation consistency metric that quantifies improved answer crystallization.
Significance. Should the evaluation protocol prove robust against memorization and leakage, the results would indicate that verifiable-reward RL methods can drive substantial gains in compositional scientific reasoning where model scale alone is insufficient. The mechanistic evidence from logit lens and the distractor-permutation consistency metric provide concrete, falsifiable insights into how GRPO reshapes the output distribution. The benchmark construction from verifiable DFT data is a strength that supports reproducible evaluation in the materials domain.
major comments (2)
- [Benchmark construction and evaluation splits section] The isolation of the held-out structure families split from training data is central to the generalization claim, yet the manuscript provides no quantitative statistics on compound overlap, ionic substitution template overlap, or potential leakage from pretraining corpora containing Materials Project entries. Without these controls, the 71.6% held-out accuracy cannot be unambiguously attributed to compositional reasoning rather than exploitation of statistical regularities in the question generation process.
- [Results and experimental details] The reported accuracies (65.2% in-distribution, 71.6% held-out) are presented as point estimates without statistical error bars, variance across random seeds, or explicit description of data exclusion rules and question-generation hyperparameters, which are required to establish that the gains over zero-shot baselines are reliable.
minor comments (2)
- [Abstract] The abstract omits the number of questions per split and any concrete description of how the cross-property transfer split is generated.
- [Analysis of GRPO effects] The distractor-permutation consistency metric would benefit from an explicit mathematical definition or worked example in the main text rather than relying solely on the reported 24.0-to-14.3 pp narrowing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for stronger controls on leakage and statistical reliability. We respond to each major comment below.
read point-by-point responses
-
Referee: [Benchmark construction and evaluation splits section] The isolation of the held-out structure families split from training data is central to the generalization claim, yet the manuscript provides no quantitative statistics on compound overlap, ionic substitution template overlap, or potential leakage from pretraining corpora containing Materials Project entries. Without these controls, the 71.6% held-out accuracy cannot be unambiguously attributed to compositional reasoning rather than exploitation of statistical regularities in the question generation process.
Authors: We agree that quantitative overlap statistics are required to support the generalization claims. In the revised manuscript we will add tables reporting compound overlap percentages and ionic substitution template overlap between training and held-out structure families. We will also include a discussion of Materials Project entry overlap with likely pretraining sources. Complete verification against proprietary pretraining corpora remains limited. revision: partial
-
Referee: [Results and experimental details] The reported accuracies (65.2% in-distribution, 71.6% held-out) are presented as point estimates without statistical error bars, variance across random seeds, or explicit description of data exclusion rules and question-generation hyperparameters, which are required to establish that the gains over zero-shot baselines are reliable.
Authors: We agree that variance estimates and hyperparameter details are necessary. The revised version will report accuracies with error bars over multiple random seeds, state the data exclusion rules explicitly, and provide the full set of question-generation hyperparameters. revision: yes
- Exhaustive checks for leakage from all pretraining corpora of closed models are not feasible without access to their training data.
Circularity Check
No significant circularity; claims rest on new benchmark and empirical runs
full rationale
The paper introduces a new benchmark (Mat-Pref) with explicitly constructed splits from Materials Project data and reports empirical accuracies from SFT+GRPO training on Qwen3-8B versus baselines. No derivation chain reduces a claimed result to a fitted parameter, self-citation, or ansatz by construction; the distractor-permutation consistency metric is presented as a post-hoc formalization of observed logit-lens behavior rather than a load-bearing prediction. The central performance numbers (65.2%, 71.6%) are direct experimental outputs, not quantities defined in terms of themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The benchmark questions and splits isolate structural generalization and cross-property transfer without confounding memorization or leakage.
Reference graph
Works this paper leans on
-
[1]
, title =
Jain, Anubhav and Ong, Shyue Ping and Hautier, Geoffroy and Chen, Wei and Richards, William Davidson and Dacek, Stephen and Cholia, Shreyas and Gunter, Dan and Skinner, David and Ceder, Gerbrand and Persson, Kristin A. , title =. APL Materials , volume =
-
[2]
and Rignanese, Gian-Marco and Gonze, Xavier and Hautier, Geoffroy , title =
Waroquiers, David and George, Julie and Horton, Matthew and Schenk, Stephan and Persson, Kristin A. and Rignanese, Gian-Marco and Gonze, Xavier and Hautier, Geoffroy , title =. Acta Crystallographica Section B , volume =
-
[4]
and Li, Y
Guo, Daya and Zhu, Qihao and Yang, Dejian and Xie, Zhenda and Dong, Kai and Zhang, Wentao and Chen, Guanting and Bi, Xiao and Wu, Y. and Li, Y. K. and Luo, Fuli and Xiong, Yingfei and Liang, Wenfeng , journal=
-
[5]
and Persson, Kristin A
Ong, Shyue Ping and Richards, William Davidson and Jain, Anubhav and Hautier, Geoffroy and Kocher, Michael and Cholia, Shreyas and Gunter, Dan and Chevrier, Vincent L. and Persson, Kristin A. and Ceder, Gerbrand , title =. Computational Materials Science , volume =
-
[6]
and Ong, Shyue Ping and Hautier, Geoffroy and Jain, Anubhav and Richards, William Davidson and Gamst, Alex C
Sun, Wenhao and Dacek, Stephen T. and Ong, Shyue Ping and Hautier, Geoffroy and Jain, Anubhav and Richards, William Davidson and Gamst, Alex C. and Persson, Kristin A. and Ceder, Gerbrand , title =. Science Advances , volume =
-
[7]
Humanity's last exam , author=. arXiv preprint arXiv:2501.14249 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
2025 , month = jul, howpublished =
Skarlinski, Michael and Laurent, Jon and Bou, Albert and White, Andrew , title =. 2025 , month = jul, howpublished =
2025
-
[9]
Humanity's Last Exam (HLE) Bio/Chem Gold , year =
-
[10]
Benchmarking materials property prediction methods: the
Dunn, Alexander and Wang, Qi and Ganose, Alex and Dopp, Daniel and Jain, Anubhav , journal=. Benchmarking materials property prediction methods: the. 2020 , publisher=
2020
-
[11]
2023 , publisher=
Song, Yu and Miret, Santiago and Liu, Bang , booktitle=. 2023 , publisher=
2023
-
[12]
Advances in Neural Information Processing Systems , volume=
Training a Scientific Reasoning Model for Chemistry , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
and Torkar, Michaela and Li, Donghui and Karaletsos, Theofanis , booktitle=
Istrate, Ana-Maria and Milletari, Fausto and Castrotorres, Fabrizio and Tomczak, Jakub M. and Torkar, Michaela and Li, Donghui and Karaletsos, Theofanis , booktitle=. rbio1 -- Training Scientific Reasoning
-
[14]
2025 , month = jul, howpublished =
About 30\. 2025 , month = jul, howpublished =
2025
-
[15]
NeurIPS 2025 Workshop on AI for Science , year=
Towards Generating Stable Materials via Large Language Models with Reinforcement Learning Finetuning , author=. NeurIPS 2025 Workshop on AI for Science , year=
2025
-
[17]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=. 2022 , url=
2022
-
[20]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , journal=. The
-
[21]
DeepSeek-AI , journal=
-
[22]
Advances in Neural Information Processing Systems , year=
Eliciting Latent Predictions from Transformers with the Tuned Lens , author=. Advances in Neural Information Processing Systems , year=
-
[23]
Eliciting latent predictions from transformers with the tuned lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens. In Advances in Neural Information Processing Systems, 2023
2023
-
[24]
DeepSeek-AI. DeepSeek-V3 technical report. arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1 : Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Alexander Dunn, Qi Wang, Alex Ganose, Daniel Dopp, and Anubhav Jain. Benchmarking materials property prediction methods: the Matbench test set and Automatminer reference algorithm. npj Computational Materials, 6 0 (1): 0 138, 2020. doi:10.1038/s41524-020-00406-3
-
[27]
Humanity's last exam (hle) bio/chem gold
FutureHouse . Humanity's last exam (hle) bio/chem gold. https://huggingface.co/datasets/futurehouse/hle-gold-bio-chem, 2025 a . Hugging Face dataset card, accessed April 18, 2026
2025
-
[28]
About 30\ are likely wrong
FutureHouse . About 30\ are likely wrong. https://www.futurehouse.org/research-announcements/hle-exam, July 2025 b . Blog post, accessed April 19, 2026
2025
-
[29]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. DeepSeek-Coder : When the large language model meets programming -- the rise of code intelligence. arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Towards generating stable materials via large language models with reinforcement learning finetuning
Zhang-Wei Hong, Nofit Segal, Aviv Netanyahu, Hoje Chun, Rafael Gomez-Bombarelli, and Pulkit Agrawal. Towards generating stable materials via large language models with reinforcement learning finetuning. In NeurIPS 2025 Workshop on AI for Science, 2025
2025
-
[32]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA : Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[33]
Tomczak, Michaela Torkar, Donghui Li, and Theofanis Karaletsos
Ana-Maria Istrate, Fausto Milletari, Fabrizio Castrotorres, Jakub M. Tomczak, Michaela Torkar, Donghui Li, and Theofanis Karaletsos. rbio1 -- training scientific reasoning LLMs with biological world models as soft verifiers. In NeurIPS 2025 Workshop on AI Virtual Cells and Instruments: A New Era in Drug Discovery and Development, 2025
2025
-
[34]
Anubhav Jain, Shyue Ping Ong, Geoffroy Hautier, Wei Chen, William Davidson Richards, Stephen Dacek, Shreyas Cholia, Dan Gunter, David Skinner, Gerbrand Ceder, and Kristin A. Persson. Commentary: The materials project: A materials genome approach to accelerating materials innovation. APL Materials, 1 0 (1): 0 011002, 2013
2013
-
[35]
Taoyuze Lv, Alexander Chen, Fengyu Xie, Chu Wu, Jeffrey Meng, Dongzhan Zhou, Bram Hoex, Zhicheng Zhong, and Tong Xie. Atomworld: A benchmark for evaluating spatial reasoning in large language models on crystalline materials. arXiv preprint arXiv:2510.04704, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Narayanan, James D
Siddharth M. Narayanan, James D. Braza, Ryan-Rhys Griffiths, Albert Bou, Geemi P. Wellawatte, Mayk Caldas Ramos, Ludovico Mitchener, Samuel G. Rodriques, and Andrew D. White. Training a scientific reasoning model for chemistry. In Advances in Neural Information Processing Systems, volume 38, 2025
2025
-
[37]
Chevrier, Kristin A
Shyue Ping Ong, William Davidson Richards, Anubhav Jain, Geoffroy Hautier, Michael Kocher, Shreyas Cholia, Dan Gunter, Vincent L. Chevrier, Kristin A. Persson, and Gerbrand Ceder. Python materials genomics (pymatgen): A robust, open-source python library for materials analysis. Computational Materials Science, 68: 0 314--319, 2013
2013
-
[38]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath : Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Yu Song, Santiago Miret, and Bang Liu. MatSci-NLP : Evaluating scientific language models on materials science language tasks using text-to-schema modeling. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3621--3639, Toronto, Canada, 2023. Association for Computational Linguistics. ...
-
[40]
Dacek, Shyue Ping Ong, Geoffroy Hautier, Anubhav Jain, William Davidson Richards, Alex C
Wenhao Sun, Stephen T. Dacek, Shyue Ping Ong, Geoffroy Hautier, Anubhav Jain, William Davidson Richards, Alex C. Gamst, Kristin A. Persson, and Gerbrand Ceder. The thermodynamic scale of inorganic crystalline metastability. Science Advances, 2 0 (11): 0 e1600225, 2016
2016
-
[41]
Persson, Gian-Marco Rignanese, Xavier Gonze, and Geoffroy Hautier
David Waroquiers, Julie George, Matthew Horton, Stephan Schenk, Kristin A. Persson, Gian-Marco Rignanese, Xavier Gonze, and Geoffroy Hautier. Chemenv: a fast and robust coordination environment identification tool. Acta Crystallographica Section B, 76 0 (4): 0 683--695, 2020
2020
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2025 b
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.