Structured Hyperedge Adaptation for Parameter-Efficient Fine-Tuning of Vision Transformers
Pith reviewed 2026-06-26 10:41 UTC · model grok-4.3
The pith
Vision transformers adapt more effectively when updates are computed over groups of related tokens rather than each token alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
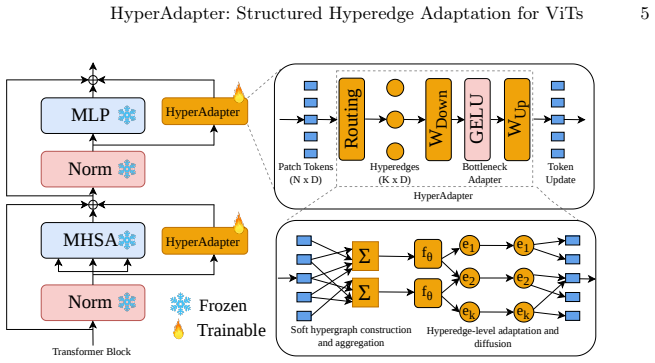
HyperAdapter constructs a soft hypergraph over ViT tokens with prototype-based assignments, aggregates token features into latent hyperedge representations, applies bottleneck adaptation at the hyperedge level, and diffuses the resulting updates back to tokens via the hypergraph incidence structure, thereby injecting an explicit structural inductive bias into parameter-efficient fine-tuning.
What carries the argument
Soft hypergraph constructed via prototype-based token assignments, which enables group-aware adaptation by routing updates through aggregated hyperedge representations rather than individual tokens.
If this is right
- Updates become spatially consistent because tokens assigned to the same hyperedge receive correlated refinements.
- Redundant parameter changes decrease when adaptation occurs on aggregated hyperedge features instead of every token separately.
- Gains are largest on tasks whose labels depend on relational structure among image regions.
- The module stays modular and can be inserted into existing ViT pipelines without altering the backbone weights.
Where Pith is reading between the lines
- The same hyperedge-level adaptation could be tested on language or multimodal transformers where token relations also matter.
- Alternative hypergraph construction rules, such as attention-derived or spatial-grid rules, might be compared directly against the prototype method.
- If the performance edge persists across many datasets, future PEFT designs may prioritize the choice of adaptation graph over further reductions in parameter count.
Load-bearing premise
Prototype-based soft hypergraph construction will produce meaningful hyperedges that reflect the actual structured relationships among tokens in visual scenes.
What would settle it
Replacing the learned prototype assignments with random token groupings of the same size and measuring whether accuracy falls back to standard adapter levels on the same benchmarks.
Figures



read the original abstract
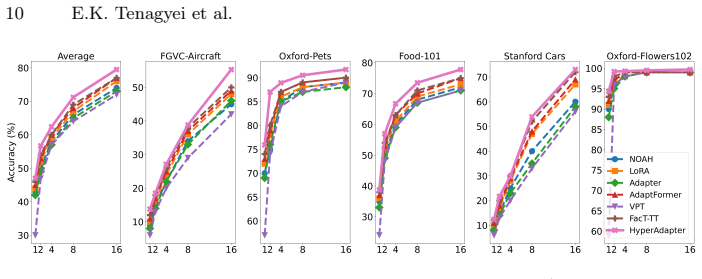
Parameter-efficient fine-tuning (PEFT) has become a practical solution for adapting large pretrained vision transformers (ViTs) to downstream tasks while updating only a small subset of parameters. However, existing adapter-based methods perform adaptation independently for each token, implicitly assuming that token refinements should be learned in isolation. This token-wise formulation overlooks the structured relationships among tokens that naturally arise in visual scenes, potentially leading to redundant updates and spatially inconsistent feature refinement. In this work, we revisit the design of parameter-efficient adapters and propose to perform adaptation in hyperedge space rather than token space. We introduce HyperAdapter, a hypergraph-based adapter architecture that enables structured, group-aware adaptation through soft token routing. HyperAdapter constructs a soft hypergraph over ViT tokens using prototype-based assignments, aggregates token features into latent hyperedge representations, applies lightweight bottleneck adaptation at the hyperedge level, and diffuses the resulting updates back to tokens via the hypergraph incidence structure. This design injects an explicit structural inductive bias into PEFT while preserving the modularity and efficiency of standard adapters. Extensive experiments across diverse visual benchmarks demonstrate that structured hyperedge adaptation consistently outperforms strong PEFT baselines under comparable parameter budgets, with particularly pronounced gains on tasks requiring structured reasoning. Our results suggest that the choice of adaptation space is a critical yet underexplored dimension in parameter-efficient transfer for ViTs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HyperAdapter, a hypergraph-based adapter for parameter-efficient fine-tuning of Vision Transformers. It constructs a soft hypergraph over ViT tokens via prototype-based assignments, aggregates features to hyperedge representations, performs bottleneck adaptation at the hyperedge level, and diffuses updates back to tokens via the incidence matrix. The central claim is that this structured adaptation in hyperedge space yields consistent outperformance over strong PEFT baselines (e.g., standard adapters) under comparable parameter budgets across visual benchmarks, with larger gains on tasks requiring structured reasoning.
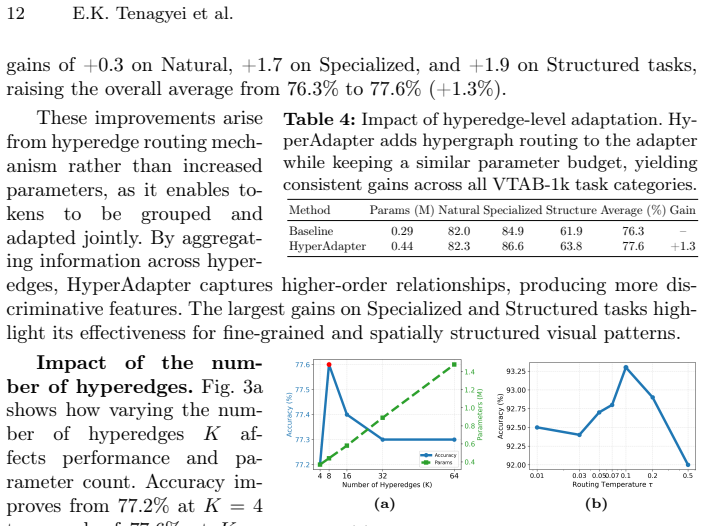
Significance. If the results hold and the hypergraph construction indeed captures meaningful visual structure, the work highlights adaptation space (hyperedge vs. token) as an underexplored axis for injecting inductive bias in PEFT. This could inform future adapter designs for relational or part-based vision tasks while retaining modularity and efficiency. The explicit structural mechanism is a conceptual contribution, though its empirical grounding requires further verification as noted below.
major comments (2)
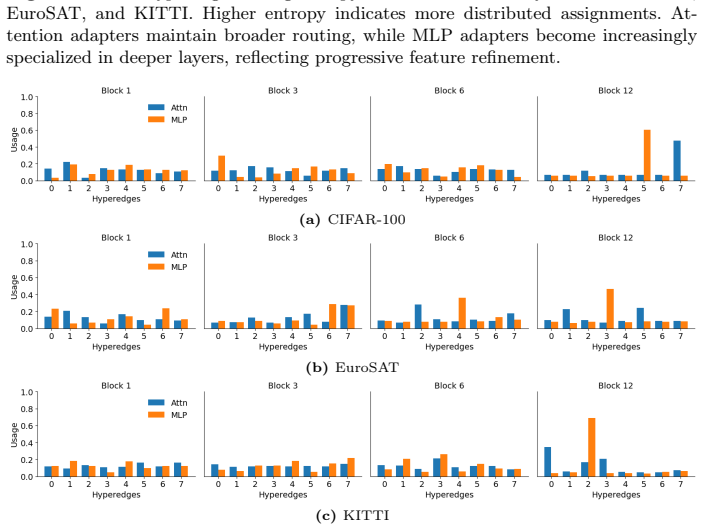
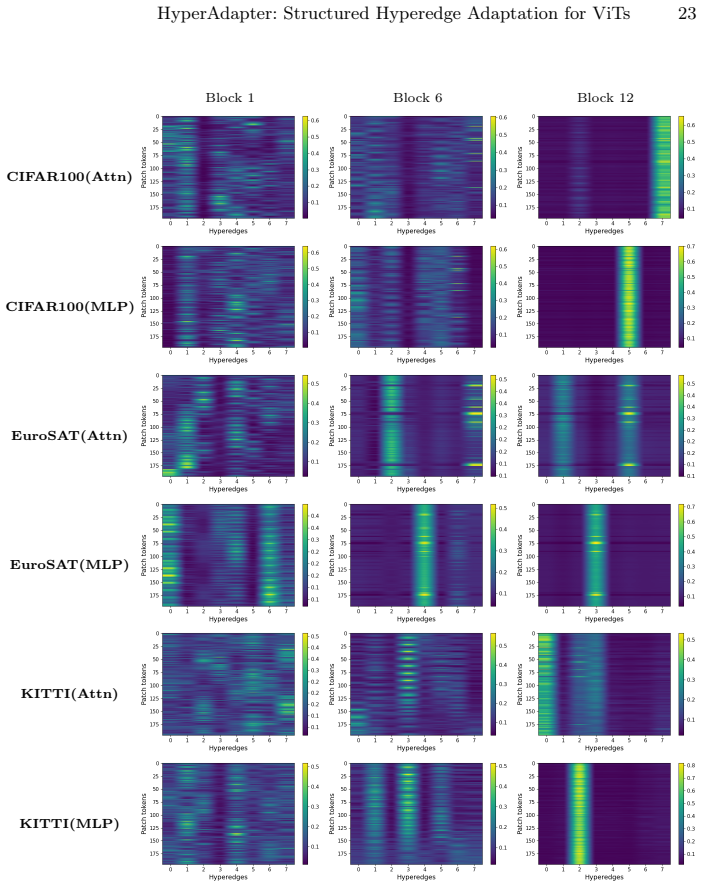
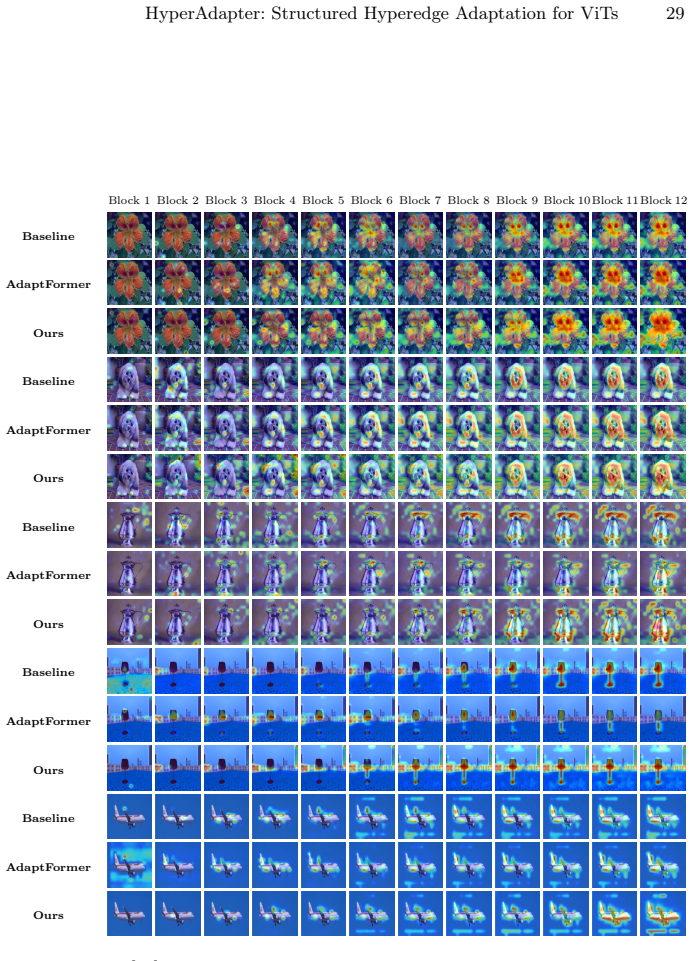
- [§4] §4 (HyperAdapter architecture), prototype-based soft hypergraph construction: the central claim that gains arise from 'structured' hyperedges reflecting visual relationships (objects, parts, spatial relations) is load-bearing, yet the manuscript provides no direct verification such as hyperedge visualizations, semantic coherence metrics on the learned prototypes, or ablations replacing prototype assignments with random soft assignments. Without these, it remains possible that performance improvements derive from the aggregation/diffusion routing or added parameters rather than genuine structural bias.
- [§5] §5 (Experiments), results tables: while the abstract states 'consistent outperformance' and 'pronounced gains on structured-reasoning tasks,' the reported comparisons lack error bars, multiple random seeds, or statistical significance tests against baselines. This weakens the ability to assess whether the hyperedge mechanism reliably drives the claimed advantages under comparable parameter budgets.
minor comments (2)
- [§4] Notation for the incidence matrix and diffusion step should be clarified with an explicit equation showing how updates are propagated back to tokens; current description in §4 is high-level.
- The manuscript should include a reference to prior hypergraph neural network work in vision (e.g., hypergraph convolutions for scene understanding) to better situate the novelty of the soft prototype construction.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments point-by-point below and will revise the manuscript accordingly to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§4] §4 (HyperAdapter architecture), prototype-based soft hypergraph construction: the central claim that gains arise from 'structured' hyperedges reflecting visual relationships (objects, parts, spatial relations) is load-bearing, yet the manuscript provides no direct verification such as hyperedge visualizations, semantic coherence metrics on the learned prototypes, or ablations replacing prototype assignments with random soft assignments. Without these, it remains possible that performance improvements derive from the aggregation/diffusion routing or added parameters rather than genuine structural bias.
Authors: We agree that direct evidence isolating the contribution of the prototype-based structure is needed to support the central claim. In the revision we will add (i) qualitative visualizations of selected hyperedges overlaid on input images to show semantic coherence (e.g., grouping tokens belonging to the same object or spatial region), and (ii) a controlled ablation that replaces the learned prototype assignments with random soft assignments while preserving the aggregation, bottleneck, and diffusion stages. These additions will clarify whether the observed gains are attributable to the structured routing rather than the routing mechanism or parameter count alone. revision: yes
-
Referee: [§5] §5 (Experiments), results tables: while the abstract states 'consistent outperformance' and 'pronounced gains on structured-reasoning tasks,' the reported comparisons lack error bars, multiple random seeds, or statistical significance tests against baselines. This weakens the ability to assess whether the hyperedge mechanism reliably drives the claimed advantages under comparable parameter budgets.
Authors: We acknowledge the absence of statistical reporting. In the revised manuscript we will rerun all main experiments with at least three random seeds, report mean performance together with standard deviation, and include paired statistical significance tests (e.g., t-tests) against the strongest baselines under matched parameter budgets. Updated tables and a short discussion of variability will be added to §5. revision: yes
Circularity Check
No significant circularity; new architecture with independent empirical evaluation
full rationale
The paper introduces HyperAdapter as an explicit new architecture involving prototype-based soft hypergraph construction over ViT tokens, aggregation to hyperedges, bottleneck adaptation, and incidence-based diffusion. These are presented as design choices injecting structural bias, with performance claims resting on external benchmark comparisons rather than any equation or parameter reducing the gains to quantities defined by the method's own fitted inputs. No self-citations, self-definitional steps, or fitted-input predictions appear in the abstract or described method. The derivation chain is self-contained against external baselines.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of prototypes
- bottleneck dimension
axioms (1)
- domain assumption Tokens in visual scenes exhibit structured relationships that are better captured by hyperedges than by independent token updates.
invented entities (1)
-
soft hypergraph over ViT tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Albert, P., Zhang, F.Z., Saratchandran, H., van den Hengel, A., Abbasnejad, E.: Towards higher effective rank in parameter-efficient fine-tuning using khatri-rao product. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1292–1302 (2025)
2025
-
[2]
In: European Conference on Computer Vision (2014)
Bossard, L., Guillaumin, M., Gool, L.V.: Food-101 - mining discriminative compo- nents with random forests. In: European Conference on Computer Vision (2014)
2014
-
[3]
Advances in Neural Information Processing Systems35, 16664–16678 (2022)
Chen, S., Ge, C., Tong, Z., Wang, J., Song, Y., Wang, J., Luo, P.: Adaptformer: Adapting vision transformers for scalable visual recognition. Advances in Neural Information Processing Systems35, 16664–16678 (2022)
2022
-
[4]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, T., Chen, J., Zhang, B., Yu, Z., Chen, S., Ye, R., Li, X., Ye, Y.: Sensitivity- aware efficient fine-tuning via compact dynamic-rank adaptation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 9655–9664 (2025)
2025
-
[5]
Advances in Neural Information Processing Systems 37, 102056–102077 (2024)
Dong, W., Sun, Y., Yang, Y., Zhang, X., Lin, Z., Yan, Q., Zhang, H., Wang, P., Yang, Y., Shen, H.: Efficient adaptation of pre-trained vision transformer via householder transformation. Advances in Neural Information Processing Systems 37, 102056–102077 (2024)
2024
-
[6]
Advances in Neural Information Processing Sys- tems36, 52548–52567 (2023)
Dong, W., Yan, D., Lin, Z., Wang, P.: Efficient adaptation of large vision trans- former via adapter re-composing. Advances in Neural Information Processing Sys- tems36, 52548–52567 (2023)
2023
-
[7]
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. ArXiv abs/2010.11929(2020)
Pith/arXiv arXiv 2010
-
[8]
In: Proceedings of the AAAI conference on artificial intelligence
Feng, Y., You, H., Zhang, Z., Ji, R., Gao, Y.: Hypergraph neural networks. In: Proceedings of the AAAI conference on artificial intelligence. vol. 33, pp. 3558– 3565 (2019)
2019
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Fixelle, J.: Hypergraph vision transformers: Images are more than nodes, more than edges. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9751–9761 (2025)
2025
-
[10]
Tenagyei et al
Gao, Y., Wang, M., Tao, D., Ji, R., Dai, Q.: 3-d object retrieval and recognition withhypergraphanalysis.IEEEtransactionsonimageprocessing21(9),4290–4303 (2012) 16 E.K. Tenagyei et al
2012
-
[11]
Advances in neural information processing systems30(2017)
Hamilton, W., Ying, Z., Leskovec, J.: Inductive representation learning on large graphs. Advances in neural information processing systems30(2017)
2017
-
[12]
arXiv preprint arXiv:2307.13770 (2023)
Han,C.,Wang,Q.,Cui,Y.,Cao,Z.,Wang,W.,Qi,S.,Liu,D.:Eˆ2vpt:Aneffective and efficient approach for visual prompt tuning. arXiv preprint arXiv:2307.13770 (2023)
arXiv 2023
-
[13]
Advances in neural information processing systems35, 8291–8303 (2022)
Han, K., Wang, Y., Guo, J., Tang, Y., Wu, E.: Vision gnn: An image is worth graph of nodes. Advances in neural information processing systems35, 8291–8303 (2022)
2022
-
[14]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Han, Y., Wang, P., Kundu, S., Ding, Y., Wang, Z.: Vision hgnn: An image is more than a graph of nodes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19878–19888 (2023)
2023
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022)
2022
-
[16]
In: Proceedings of the AAAI Conference on Artificial Intelligence
He, X., Li, C., Zhang, P., Yang, J., Wang, X.E.: Parameter-efficient model adapta- tion for vision transformers. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 817–825 (2023)
2023
-
[17]
In: International conference on machine learning
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Ges- mundo, A., Attariyan, M., Gelly, S.: Parameter-efficient transfer learning for nlp. In: International conference on machine learning. pp. 2790–2799. PMLR (2019)
2019
-
[18]
Iclr1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
2022
-
[19]
In: 2009 IEEE conference on computer vision and pattern recognition
Huang, Y., Liu, Q., Metaxas, D.: ] video object segmentation by hypergraph cut. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 1738–
2009
-
[20]
arXiv preprint arXiv:2403.19243 (2024)
Ji, Y., Saratchandran, H., Gordon, C., Zhang, Z., Lucey, S.: Efficient learning with sine-activated low-rank matrices. arXiv preprint arXiv:2403.19243 (2024)
arXiv 2024
-
[21]
In: European conference on computer vision
Jia, M., Tang, L., Chen, B.C., Cardie, C., Belongie, S., Hariharan, B., Lim, S.N.: Visual prompt tuning. In: European conference on computer vision. pp. 709–727. Springer (2022)
2022
-
[22]
arXiv preprint arXiv:2207.07039 (2022)
Jie, S., Deng, Z.H.: Convolutional bypasses are better vision transformer adapters. arXiv preprint arXiv:2207.07039 (2022)
arXiv 2022
-
[23]
In: Proceedings of the AAAI conference on artificial intelligence
Jie, S., Deng, Z.H.: Fact: Factor-tuning for lightweight adaptation on vision trans- former. In: Proceedings of the AAAI conference on artificial intelligence. vol. 37, pp. 1060–1068 (2023)
2023
-
[24]
Advances in neural information processing systems 34, 1022–1035 (2021)
Karimi Mahabadi, R., Henderson, J., Ruder, S.: Compacter: Efficient low-rank hypercomplex adapter layers. Advances in neural information processing systems 34, 1022–1035 (2021)
2021
-
[25]
2013 IEEE International Conference on Computer Vision Workshops pp
Krause, J., Stark, M., Deng, J., Fei-Fei, L.: 3d object representations for fine- grained categorization. 2013 IEEE International Conference on Computer Vision Workshops pp. 554–561 (2013)
2013
-
[26]
Advances in Neural Information Processing Systems35, 109–123 (2022)
Lian, D., Zhou, D., Feng, J., Wang, X.: Scaling & shifting your features: A new baseline for efficient model tuning. Advances in Neural Information Processing Systems35, 109–123 (2022)
2022
-
[27]
Pattern Recognit.165, 111607 (2025)
Liao, Y., Gao, Y., Zhang, W.: Dynamic accumulated attention map for interpreting evolution of decision-making in vision transformer. Pattern Recognit.165, 111607 (2025)
2025
-
[28]
arXiv preprint arXiv:2311.06243 (2023) HyperAdapter: Structured Hyperedge Adaptation for ViTs 17
Liu, W., Qiu, Z., Feng, Y., Xiu, Y., Xue, Y., Yu, L., Feng, H., Liu, Z., Heo, J., Peng, S., et al.: Parameter-efficient orthogonal finetuning via butterfly factoriza- tion. arXiv preprint arXiv:2311.06243 (2023) HyperAdapter: Structured Hyperedge Adaptation for ViTs 17
arXiv 2023
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu,Z.,Hu,H.,Lin,Y.,Yao,Z.,Xie,Z.,Wei,Y.,Ning,J.,Cao,Y.,Zhang,Z.,Dong, L., et al.: Swin transformer v2: Scaling up capacity and resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12009–12019 (2022)
2022
-
[30]
2021 IEEE/CVF International Conference on Computer Vision (ICCV) pp
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin trans- former: Hierarchical vision transformer using shifted windows. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 9992–10002 (2021)
2021
-
[31]
arXiv preprint arXiv:2302.08106 (2023)
Luo, G., Huang, M., Zhou, Y., Sun, X., Jiang, G., Wang, Z., Ji, R.: To- wards efficient visual adaption via structural re-parameterization. arXiv preprint arXiv:2302.08106 (2023)
arXiv 2023
-
[32]
In: 2018 25th IEEE Interna- tional Conference on Image Processing (ICIP)
Lv, X., Wang, L., Zhang, Q., Zheng, N., Hua, G.: Video object co-segmentation from noisy videos by a multi-level hypergraph model. In: 2018 25th IEEE Interna- tional Conference on Image Processing (ICIP). pp. 2207–2211. IEEE (2018)
2018
-
[33]
arXiv preprint arXiv:2404.04316 (2024)
Ma, X., Chu, X., Yang, Z., Lin, Y., Gao, X., Zhao, J.: Parameter efficient quasi- orthogonal fine-tuning via givens rotation. arXiv preprint arXiv:2404.04316 (2024)
arXiv 2024
-
[34]
Maji, S., Rahtu, E., Kannala, J., Blaschko, M.B., Vedaldi, A.: Fine-grained visual classification of aircraft. ArXivabs/1306.5151(2013)
Pith/arXiv arXiv 2013
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Munir, M., Avery, W., Marculescu, R.: Mobilevig: Graph-based sparse attention for mobile vision applications. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2211–2219 (2023)
2023
-
[36]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Munir, M., Avery, W., Rahman, M.M., Marculescu, R.: Greedyvig: Dynamic axial graph construction for efficient vision gnns. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6118–6127 (2024)
2024
-
[37]
2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06)2, 1447–1454 (2006)
Nilsback, M.E., Zisserman, A.: A visual vocabulary for flower classification. 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06)2, 1447–1454 (2006)
2006
-
[38]
In: 2012 IEEE conference on computer vision and pattern recognition
Parkhi, O.M., Vedaldi, A., Zisserman, A., Jawahar, C.: Cats and dogs. In: 2012 IEEE conference on computer vision and pattern recognition. pp. 3498–3505. IEEE (2012)
2012
-
[39]
In: Proceedings of the AAAI conference on artificial intel- ligence
Pei, W., Xia, T., Chen, F., Li, J., Tian, J., Lu, G.: Sa2vp: Spatially aligned-and- adapted visual prompt. In: Proceedings of the AAAI conference on artificial intel- ligence. vol. 38, pp. 4450–4458 (2024)
2024
-
[40]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ren, L., Chen, C., Wang, L., Hua, K.: Da-vpt: Semantic-guided visual prompt tuning for vision transformers. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 4353–4363 (2025)
2025
-
[41]
International Journal of Computer Vision115, 211 – 252 (2014)
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M.S., Berg, A.C., Fei-Fei, L.: Imagenet large scale visual recognition challenge. International Journal of Computer Vision115, 211 – 252 (2014)
2014
-
[42]
AI magazine29(3), 93–93 (2008)
Sen, P., Namata, G., Bilgic, M., Getoor, L., Galligher, B., Eliassi-Rad, T.: Collec- tive classification in network data. AI magazine29(3), 93–93 (2008)
2008
-
[43]
arXiv preprint arXiv:2408.11351 (2024)
Srinivas, S.S., Sarkar, R.K., Gangasani, S., Runkana, V.: Vision hgnn: An electron- micrograph is worth hypergraph of hypernodes. arXiv preprint arXiv:2408.11351 (2024)
arXiv 2024
-
[44]
In: International conference on machine learning
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jégou, H.: Training data-efficient image transformers & distillation through attention. In: International conference on machine learning. pp. 10347–10357. PMLR (2021)
2021
-
[45]
Knowledge and Information Systems14(3), 347–375 (2008) 18 E.K
Wale, N., Watson, I.A., Karypis, G.: Comparison of descriptor spaces for chemical compound retrieval and classification. Knowledge and Information Systems14(3), 347–375 (2008) 18 E.K. Tenagyei et al
2008
-
[46]
In: Proceedings of the AAAI conference on artificial intelli- gence
Wang, H., Chang, J., Zhai, Y., Luo, X., Sun, J., Lin, Z., Tian, Q.: Lion: Implicit vision prompt tuning. In: Proceedings of the AAAI conference on artificial intelli- gence. vol. 38, pp. 5372–5380 (2024)
2024
-
[47]
arXiv preprint arXiv:2505.11235 (2025)
Wu, F., Hu, J., Min, G., Wang, S.: Efficient orthogonal fine-tuning with principal subspace adaptation. arXiv preprint arXiv:2505.11235 (2025)
arXiv 2025
-
[48]
In: International Conference on Machine Learning
Yoo, S., Kim, E., Jung, D., Lee, J., Yoon, S.: Improving visual prompt tuning for self-supervised vision transformers. In: International Conference on Machine Learning. pp. 40075–40092. PMLR (2023)
2023
-
[49]
arXiv preprint arXiv:2210.00788 (2022)
Yu,B.X.,Chang,J.,Liu,L.,Tian,Q.,Chen,C.W.:Towardsaunifiedviewonvisual parameter-efficient transfer learning. arXiv preprint arXiv:2210.00788 (2022)
arXiv 2022
-
[50]
In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
Zaken, E.B., Goldberg, Y., Ravfogel, S.: Bitfit: Simple parameter-efficient fine- tuning for transformer-based masked language-models. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). pp. 1–9 (2022)
2022
-
[51]
arXiv preprint arXiv:1910.04867 (2019)
Zhai, X., Puigcerver, J., Kolesnikov, A., Ruyssen, P., Riquelme, C., Lucic, M., Djo- longa, J., Pinto, A.S., Neumann, M., Dosovitskiy, A., et al.: A large-scale study of representation learning with the visual task adaptation benchmark. arXiv preprint arXiv:1910.04867 (2019)
Pith/arXiv arXiv 1910
-
[52]
IEEE Transactions on Pattern Analysis and Machine Intelligence47(7), 5268–5280 (2024)
Zhang, Y., Zhou, K., Liu, Z.: Neural prompt search. IEEE Transactions on Pattern Analysis and Machine Intelligence47(7), 5268–5280 (2024)
2024
-
[53]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, Z., Zhang, Q., Gao, Z., Zhang, R., Shutova, E., Zhou, S., Zhang, S.: Gradient-based parameter selection for efficient fine-tuning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 28566– 28577 (2024) HyperAdapter: Structured Hyperedge Adaptation for ViTs 19 T able 6:VTAB-1k datasets [51] categorized into Na...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.