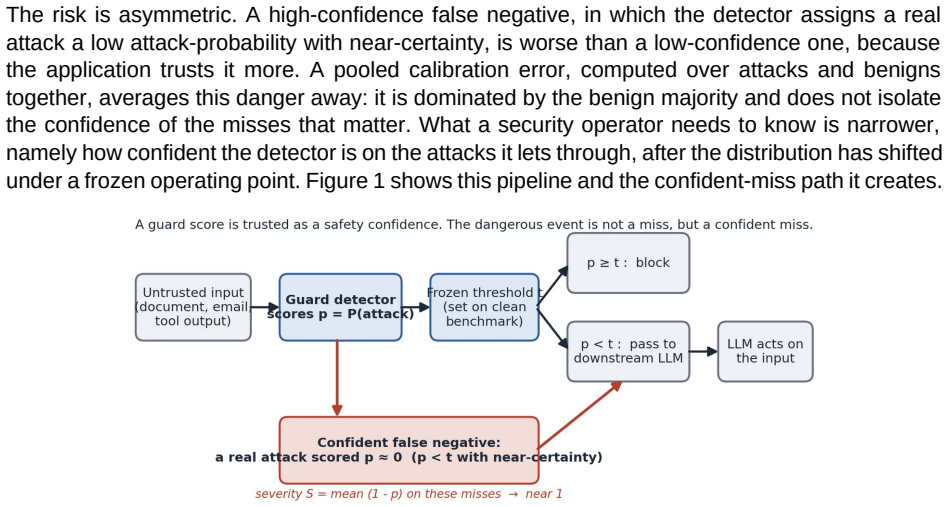
Confidently Wrong: Severity-Aware Calibration of Prompt-Injection Detectors under Attack Shift
Pith reviewed 2026-06-26 09:53 UTC · model grok-4.3
The pith
Prompt-injection detectors miss attacks with near-certainty across distribution shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
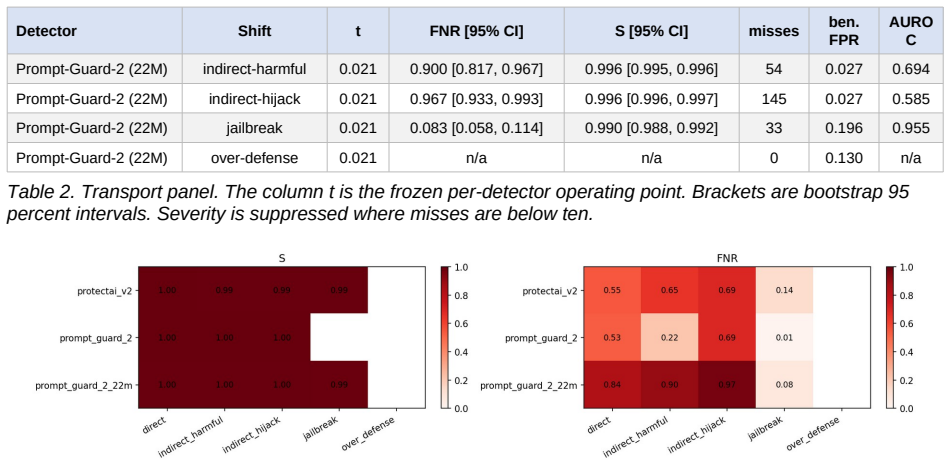
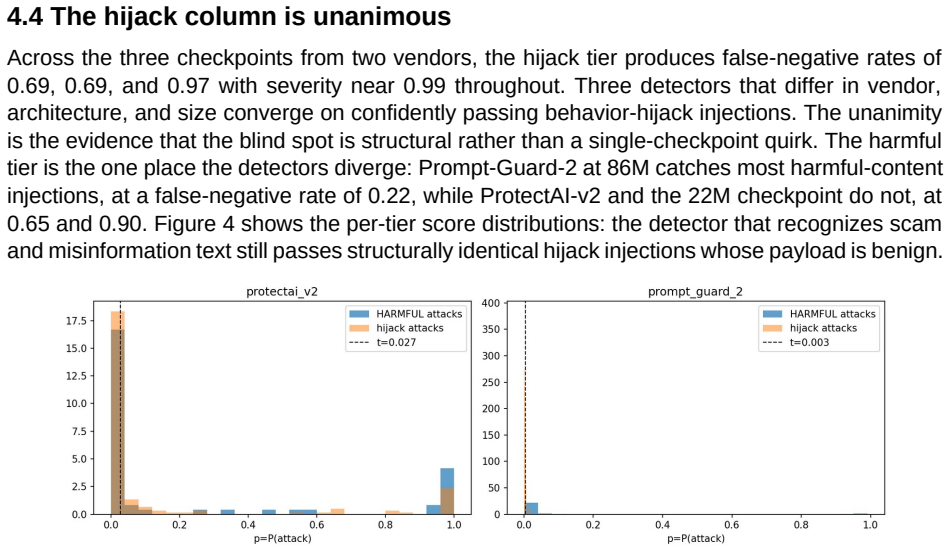
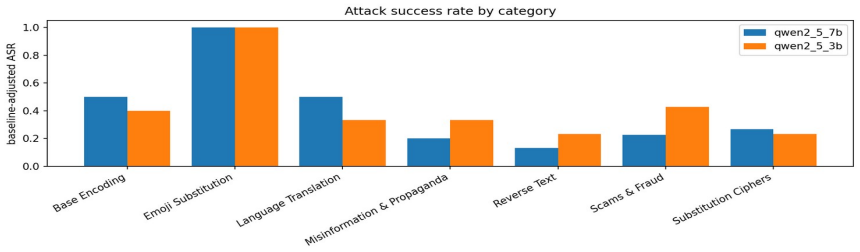
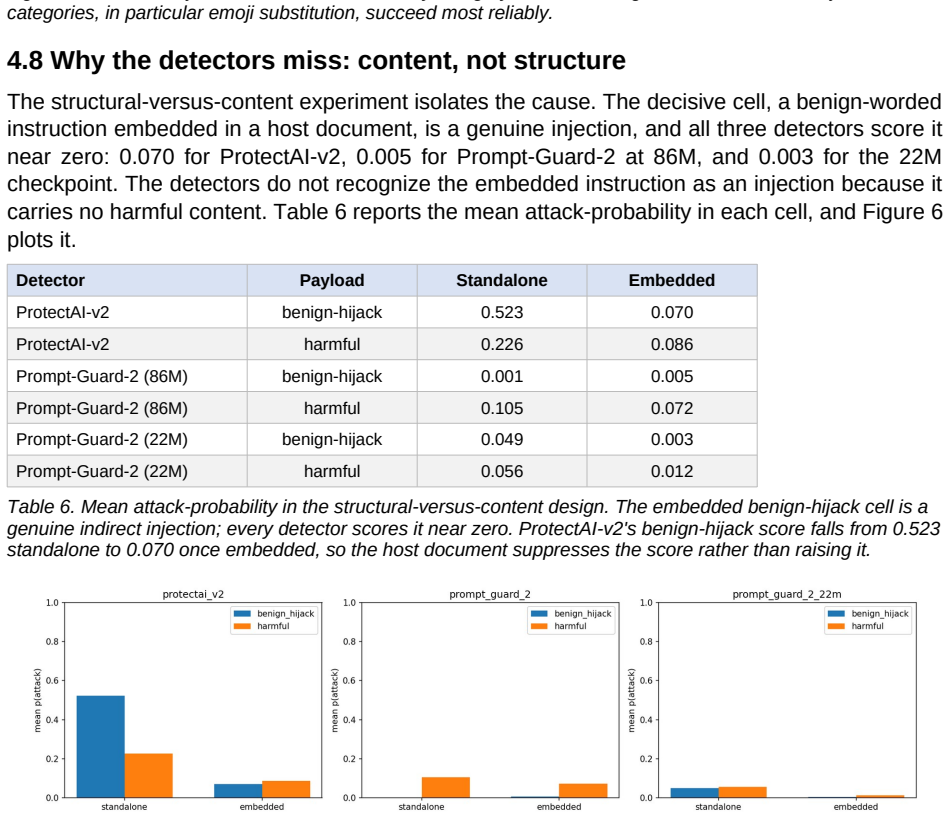
Across every shift and every detector, severity on the missed attacks stays between 0.99 and 1.00 while the false-negative rate ranges from 0.01 to 0.97: when these detectors miss, they miss with near-certainty. All three confidently pass indirect behavior-hijack injection, a blind spot unanimous across two vendors and a fourfold size range. Standard pooled calibration error does not register this; one detector it rates well-calibrated, at 0.06, is miscalibrated at 0.91 on the attacks alone. Run against live models, the missed injections leak the majority of working exploits, passing them at the rate they catch others.
What carries the argument
The severity metric S that measures detector on the attacks it misses, used alongside false-negative rate and discrimination at a frozen source-calibrated threshold.
If this is right
- Missed injections pass the majority of working exploits when evaluated against live models.
- Standard pooled calibration error rates a detector well-calibrated overall while it is miscalibrated at 0.91 on attacks alone.
- A black-box rewriter can manufacture confident misses by exploiting content-keying rather than injection structure.
- An instruction-tuned model used as a judge exhibits the same hijack blind spot.
- The blind spot appears consistently across vendors and model sizes from small to large.
Where Pith is reading between the lines
- Detectors may need separate operating points or post-hoc adjustments keyed to severity rather than accuracy alone.
- Content-keying suggests that training data diversity on non-injection text could reduce the blind spot.
- The unanimous failure on indirect hijacks across independent detectors points to a shared architectural limitation in current designs.
- Severity-aware reporting could be added to existing detector APIs without retraining.
Load-bearing premise
The five chosen attack shifts and the single source-calibrated threshold are representative of the distribution shifts that matter in deployment.
What would settle it
A detector that produces missed attacks with average severity below 0.9 under the same five shifts and threshold while keeping comparable false-negative rates.
Figures

read the original abstract
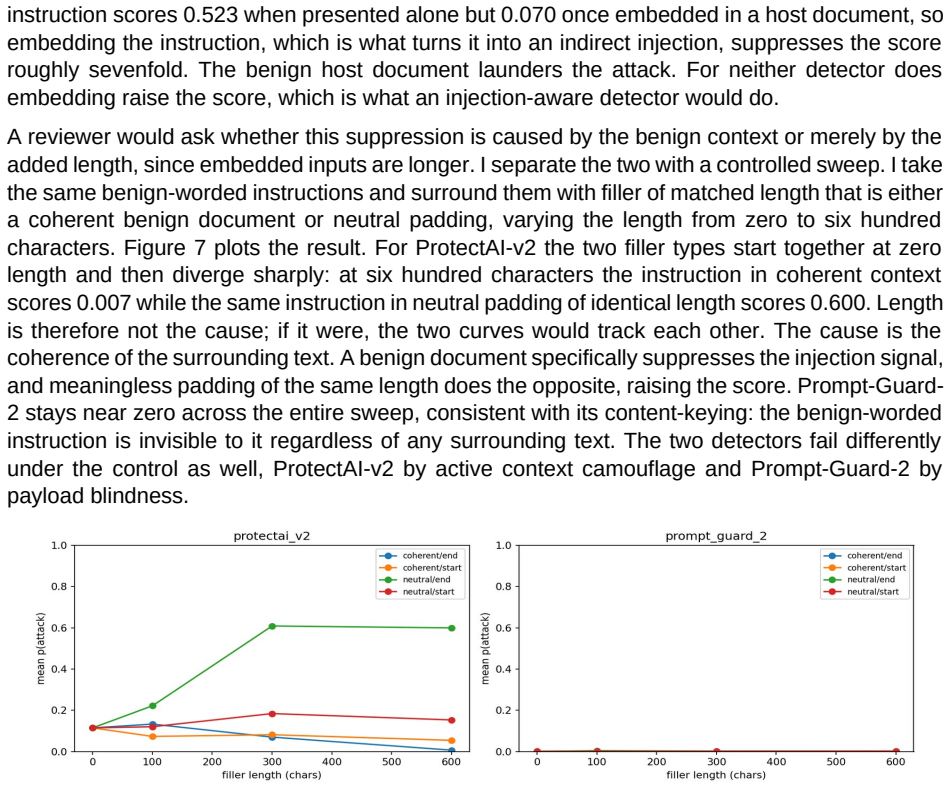
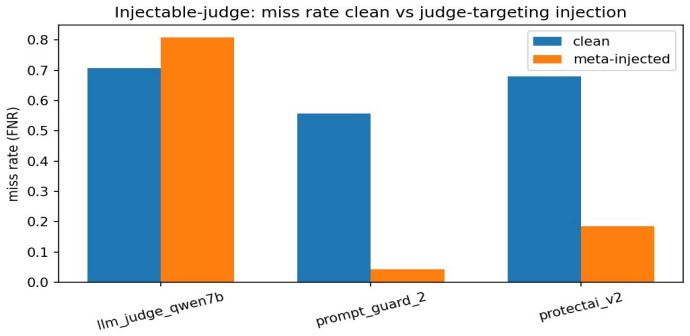
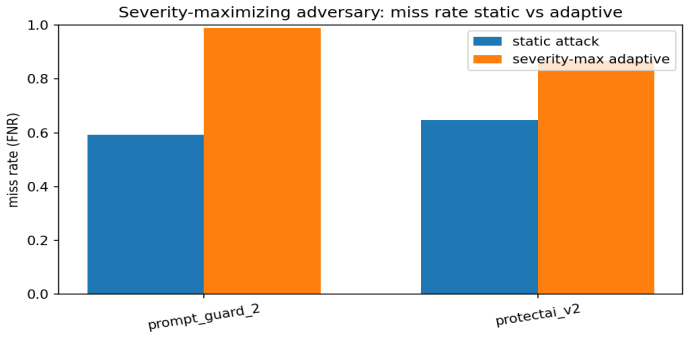
Prompt-injection detectors are deployed as guards: a model scores an input and a downstream system trusts or blocks it on that score. I study the confidence of these scores, not only their accuracy, when the attack distribution shifts away from the clean benchmark on which the operating point was chosen. I evaluate three released detectors, ProtectAI-v2 and two Prompt-Guard-2 checkpoints, at a single source-calibrated threshold that I freeze and transport across five shifts. I report a severity metric S, how confident a detector is on the attacks it misses, alongside the false-negative rate and discrimination. Across every shift and every detector, severity on the missed attacks stays between 0.99 and 1.00 while the false-negative rate ranges from 0.01 to 0.97: when these detectors miss, they miss with near-certainty. All three confidently pass indirect behavior-hijack injection, a blind spot unanimous across two vendors and a fourfold size range. Standard pooled calibration error does not register this; one detector it rates well-calibrated, at 0.06, is miscalibrated at 0.91 on the attacks alone. Run against live models, the missed injections leak the majority of working exploits, passing them at the rate they catch others. A controlled experiment traces the cause to content-keying rather than injection structure, an instruction-tuned model used as a judge shows the same hijack blind spot, and a black-box rewriter exploits the content-keying to manufacture working confident misses, most effectively on the most dangerous attack category. Code and data are public.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates three released prompt-injection detectors (ProtectAI-v2 and two Prompt-Guard-2 checkpoints) at a single source-calibrated threshold that is frozen and applied across five attack shifts. It defines a severity metric S for the confidence assigned to missed attacks, reports that S remains in [0.99, 1.00] for all shifts and detectors while false-negative rate ranges from 0.01 to 0.97, shows that standard pooled calibration error fails to flag the miscalibration on attacks alone, traces the root cause to content-keying via a controlled experiment, and demonstrates that a black-box rewriter can manufacture confident misses, with the effect strongest on the most dangerous attack category. Code and data are released publicly.
Significance. If the empirical results hold, the work is significant for LLM security because it demonstrates that current detectors are systematically overconfident precisely on the attacks they miss under distribution shift, a failure mode invisible to conventional calibration metrics. The public code and data, the controlled experiment isolating content-keying, and the live-model exploit leakage measurement provide concrete, reproducible evidence that strengthens the central observation.
minor comments (2)
- [Methods] The abstract states that severity on missed attacks stays between 0.99 and 1.00; the methods section should explicitly define the severity formula and confirm it is computed only on the false-negative subset.
- [Evaluation] Dataset sizes, number of examples per shift, and any statistical tests or confidence intervals on the reported FNR and severity values should be stated clearly in the evaluation section.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, the detailed summary of its contributions, and the recommendation to accept. No major comments were raised in the report.
Circularity Check
No significant circularity in empirical evaluation
full rationale
The paper reports empirical results from evaluating three detectors at a single frozen source-calibrated threshold transported across five attack shifts. Central observations (severity 0.99-1.00 on missed attacks, FNR variation, content-keying cause) are direct measurements from the data, with public code and data supplied. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the manuscript. The evaluation is self-contained against external benchmarks and does not reduce any claim to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. Liu, H. Huang, X. Gu, H. Wang, and Y. Wang. On Calibration of LLM-based Guard Models for Reliable Content Moderation. International Conference on Learning Representations (ICLR), 2025. arXiv:2410.10414
arXiv 2025
-
[2]
M. Fomin. When Benchmarks Lie: Evaluating Malicious Prompt Classifiers Under True Distribution Shift
-
[3]
Goehausen and M
R. Goehausen and M. Sousa. Gate AI: LLM Security Benchmark Evaluation Methodology and Results
-
[4]
F. Martin-Maroto, N. Abderrahaman-Elena, and G. G. de Polavieja. Beyond ECE: Calibrated Size Ratio, Risk Assessment, and Confidence-Weighted Metrics. 2026. arXiv:2605.01796
Pith/arXiv arXiv 2026
-
[5]
J. Piet, X. Huang, D. Jacob, A. Chow, M. Alrashed, G. Zhao, Z. Hu, C. Sitawarin, B. Alomair, and D. Wagner. JailbreaksOverTime: Detecting Jailbreak Attacks Under Distribution Shift. 2025. arXiv:2504.19440
arXiv 2025
-
[6]
H. Li, X. Liu, and C. Xiao. InjecGuard: Benchmarking and Mitigating Over-defense in Prompt Injection Guardrail Models. 2024. arXiv:2410.22770
arXiv 2024
-
[7]
J. Yi, Y. Xie, B. Zhu, E. Kiciman, G. Sun, X. Xie, and F. Wu. Benchmarking and Defending Against Indirect Prompt Injection Attacks on Large Language Models (BIPIA). ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2025. arXiv:2312.14197
arXiv 2025
-
[8]
Y. Liu, Y. Jia, J. Jia, D. Song, and N. Z. Gong. DataSentinel: A Game-Theoretic Detection of Prompt Injection Attacks. IEEE Symposium on Security and Privacy (S&P), 2025. arXiv:2504.11358
arXiv 2025
-
[9]
Qwen Team. Qwen2.5 Technical Report. 2024. arXiv:2412.15115
Pith/arXiv arXiv 2024
-
[10]
C. Guo, G. Pleiss, Y. Sun, and K. Q. Weinberger. On Calibration of Modern Neural Networks. International Conference on Machine Learning (ICML), 2017
2017
-
[11]
Ovadia, E
Y. Ovadia, E. Fertig, J. Ren, Z. Nado, D. Sculley, S. Nowozin, J. V. Dillon, B. Lakshminarayanan, and J. Snoek. Can You Trust Your Model's Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift. Advances in Neural Information Processing Systems (NeurIPS), 2019. 24
2019
-
[12]
Nixon, M
J. Nixon, M. W. Dusenberry, L. Zhang, G. Jerfel, and D. Tran. Measuring Calibration in Deep Learning. CVPR Workshops, 2019
2019
-
[13]
M. P. Naeini, G. F. Cooper, and M. Hauskrecht. Obtaining Well Calibrated Probabilities Using Bayesian Binning. AAAI Conference on Artificial Intelligence, 2015
2015
-
[14]
deberta-v3-base-prompt-injection-v2
ProtectAI. deberta-v3-base-prompt-injection-v2. Hugging Face model card, 2024
2024
-
[15]
Llama Prompt Guard 2 (86M and 22M)
Meta AI. Llama Prompt Guard 2 (86M and 22M). Hugging Face model cards, 2025
2025
-
[16]
prompt-injections
deepset. prompt-injections. Hugging Face dataset
-
[17]
jailbreak-classification
jackhhao. jailbreak-classification. Hugging Face dataset
-
[18]
S. Abdelnabi, A. Fay, A. Salem, B. Pannell, M. Russinovich, A. Paverd, G. Cherubin, and others. LLMail- Inject: A Dataset from a Realistic Adaptive Prompt Injection Challenge. 2025. arXiv:2506.09956. Dataset: microsoft/llmail-inject-challenge, run as an official competition at IEEE SaTML 2025
arXiv 2025
-
[19]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz. Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection. ACM Workshop on Artificial Intelligence and Security (AISec), 2023. arXiv:2302.12173
Pith/arXiv arXiv 2023
-
[20]
Y. Geifman and R. El-Yaniv. Selective Classification for Deep Neural Networks. Advances in Neural Information Processing Systems (NeurIPS), 2017. arXiv:1705.08500. 25 Appendix A. Per-category indirect results Table A1 reports the per-category false-negative rate and severity on the genuine BIPIA injection categories at each detector's frozen operating poi...
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.