The Geometry of Refusal: Linear Instability in Safety-Aligned LLMs
Pith reviewed 2026-06-26 09:50 UTC · model grok-4.3
The pith
Safety alignment in LLMs produces a linear refusal direction in output logits that can be isolated and steered to bypass or reinforce guardrails.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
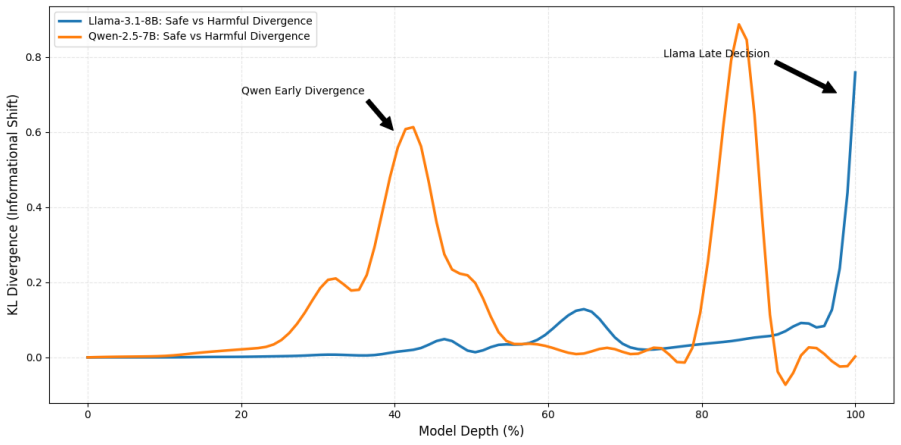
The refusal behavior in safety-aligned LLMs is not a deep semantic decision but a linear feature in the output logit space that can be isolated by contrasting safe and unrestricted prompts. Contrastive Logit Steering extracts this direction and uses it to steer the model, revealing that some models have a late decision point for safety that is easily overridden, while others integrate safety earlier in the computation. The method achieves higher success in bypassing safety than intervening on internal activations, and the direction can be reversed to make the model more resistant to jailbreaks without additional training.
What carries the argument
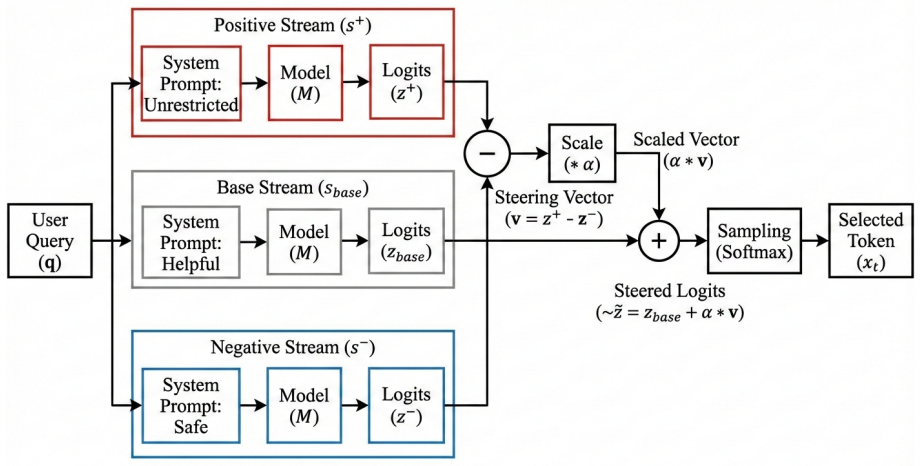
Contrastive Logit Steering (CLS), which computes the refusal direction as the difference in output distributions from safe and unrestricted system prompts and applies it to steer the logits during generation.
If this is right
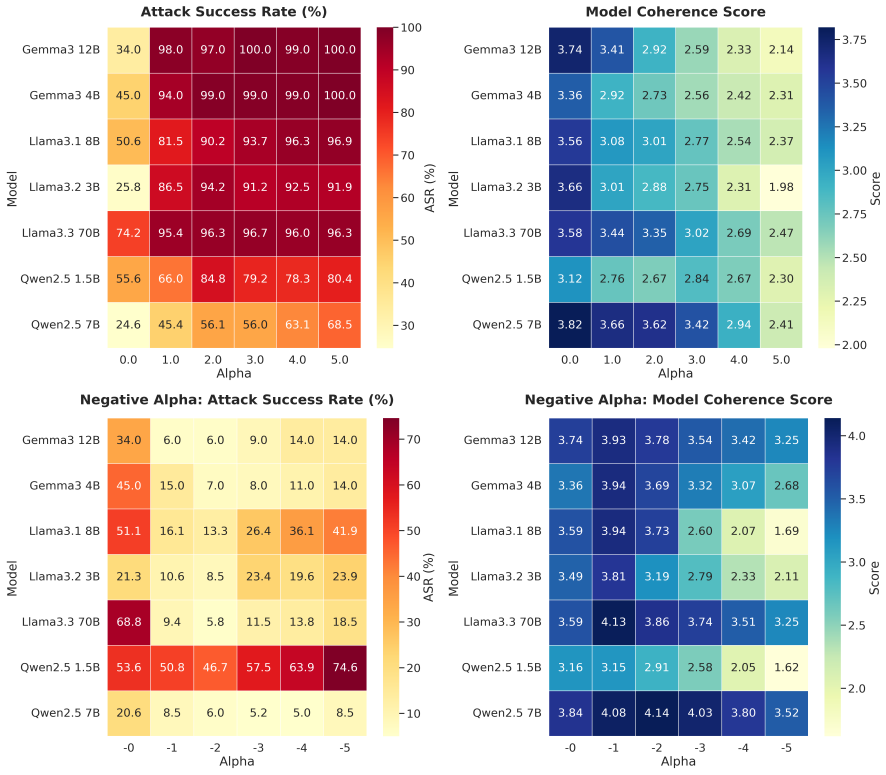
- Safety can be bypassed at rates up to 95 percent on models with late decision topologies using CLS and prefix injection.
- CLS produces substantially higher attack success rates than activation steering methods on multiple model families.
- Reversing the extracted direction hardens the model against jailbreaks without retraining.
- Safety mechanisms differ in their computational timing across architectures, with some showing early integration and others late divergence.
Where Pith is reading between the lines
- Alignment research could shift toward designing methods that avoid creating easily identifiable linear directions.
- The approach might be applied to test the robustness of new alignment techniques as they are developed.
- If the linearity holds, then monitoring or controlling this direction could become a standard part of model deployment.
- Similar contrastive methods might apply to other behavioral controls beyond safety, such as style or factuality.
Load-bearing premise
The difference in output distributions between safe and unrestricted system prompts isolates a causally relevant refusal direction rather than a correlated but non-causal feature of the model's response distribution.
What would settle it
Measuring whether steering with the extracted direction changes the rate of refusal on harmful queries while leaving performance on benign queries unchanged, or whether inverting it reduces success of known jailbreak prompts.
Figures


read the original abstract
Modern Large Language Models (LLMs) rely on extensive safety alignment, yet the mechanistic basis of refusal remains opaque. In this work, we investigate whether safety compliance is a deep semantic decision or a manipulable linear feature. We introduce Contrastive Logit Steering (CLS), a zero-optimization framework that isolates the "refusal direction" by contrasting hidden states derived from safe and unrestricted system prompts. Unlike representation engineering methods that intervene on internal activations, CLS operates directly on the output distribution, serving as a diagnostic probe for alignment fragility. When coupled with prefix injection to bypass initial refusal reflexes, this method induces a phase transition where guardrails collapse. Our experiments on 7 model families reveal that safety implementation is architecturally deterministic. While models like Llama-3.1 exhibit a "Late Decision" topology that is easily bypassed by CLS (reaching 95% ASR in approximately one second), others like Qwen-2.5 demonstrate "Early Divergence" by integrating safety mid-computation. Direct comparison with established activation-level steering methods shows that CLS achieves substantially higher attack success rates on Llama 2 (73% vs. 22.6%) and Qwen 7B (91% vs. 79.2%), demonstrating that logit-level intervention exposes alignment vulnerabilities that hidden-state methods underestimate. Beyond attacks, we show that this linearity enables bidirectional control: inverting the steering vector "hardens" models against jailbreaks without retraining. Our findings suggest that current alignment techniques create a steerable "safety axis" that serves as both a critical vulnerability and a precise primitive for defense.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Contrastive Logit Steering (CLS), a zero-optimization method that derives a 'refusal direction' from logit differences between safe and unrestricted system-prompt completions. It claims this direction reveals an architecturally deterministic linear safety axis in LLMs, enabling high attack success rates (e.g., 95% ASR on Llama-3.1 with prefix injection, 73% vs. 22.6% over activation steering on Llama 2) across 7 model families with differing topologies ('Late Decision' vs. 'Early Divergence'), and bidirectional control by vector inversion for defense without retraining.
Significance. If the central claims hold with proper causal validation, the work would be significant for mechanistic interpretability of alignment: it positions logit-level intervention as a stronger diagnostic than activation steering and supplies a simple primitive for both attacking and hardening safety. The topology distinctions and specific cross-model comparisons add concrete empirical content to debates on whether refusal is a deep semantic decision or a steerable linear feature.
major comments (3)
- [§3] §3 (Method): The claim that the logit-difference vector isolates a causally relevant refusal direction rests on the assumption that safe vs. unrestricted system-prompt contrasts separate the decision mechanism from correlated response features (verbosity, hedging, topic shift). No ablation is described that zeros or inverts the vector while measuring selective impact on refusal versus unrelated generation statistics, leaving open the possibility that CLS captures a downstream symptom rather than the refusal axis itself.
- [§4] §4 (Experiments): The reported superiority (73% vs. 22.6% on Llama 2; 91% vs. 79.2% on Qwen 7B) and 95% ASR on Llama-3.1 are presented without error bars, prompt-variation controls, or statistical tests; the abstract supplies only point estimates, so it is impossible to assess whether the gap over activation steering is robust or sensitive to implementation details of either method.
- [§4.3] §4.3 (Topology claims): The distinction between 'Late Decision' (Llama-3.1) and 'Early Divergence' (Qwen-2.5) topologies is load-bearing for the architectural-determinism conclusion, yet the manuscript provides no quantitative metric or figure that operationalizes these topologies or shows they predict CLS success rates independently of the steering vector construction.
minor comments (2)
- [Abstract / §3] The abstract states CLS 'operates directly on the output distribution' yet later refers to 'hidden states derived from safe and unrestricted system prompts'; this notation inconsistency should be clarified in the method section.
- [§3] No mention of the exact number of prompts, temperature settings, or decoding parameters used to compute the logit contrast; these details are required for reproducibility even if the method is zero-optimization.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major point below with clarifications and planned revisions where appropriate.
read point-by-point responses
-
Referee: §3 (Method): The claim that the logit-difference vector isolates a causally relevant refusal direction rests on the assumption that safe vs. unrestricted system-prompt contrasts separate the decision mechanism from correlated response features (verbosity, hedging, topic shift). No ablation is described that zeros or inverts the vector while measuring selective impact on refusal versus unrelated generation statistics, leaving open the possibility that CLS captures a downstream symptom rather than the refusal axis itself.
Authors: We agree that explicit causal validation strengthens the claim. The system-prompt contrast is intended to isolate refusal by holding all other instructions fixed, but we will add an ablation in the revision: zeroing and inverting the vector while tracking refusal rate alongside secondary statistics (response length, hedging markers, topic shift). This will quantify selective impact on the refusal decision. revision: yes
-
Referee: §4 (Experiments): The reported superiority (73% vs. 22.6% on Llama 2; 91% vs. 79.2% on Qwen 7B) and 95% ASR on Llama-3.1 are presented without error bars, prompt-variation controls, or statistical tests; the abstract supplies only point estimates, so it is impossible to assess whether the gap over activation steering is robust or sensitive to implementation details of either method.
Authors: The reported figures are point estimates from a fixed prompt set. In revision we will add standard deviations across multiple random seeds and prompt variations, include error bars, and report paired statistical tests (e.g., t-tests) between CLS and activation steering to establish robustness of the observed gaps. revision: yes
-
Referee: §4.3 (Topology claims): The distinction between 'Late Decision' (Llama-3.1) and 'Early Divergence' (Qwen-2.5) topologies is load-bearing for the architectural-determinism conclusion, yet the manuscript provides no quantitative metric or figure that operationalizes these topologies or shows they predict CLS success rates independently of the steering vector construction.
Authors: The topologies are currently described qualitatively from layer-wise steering efficacy. We will introduce a quantitative operationalization (earliest layer at which refusal-direction norm exceeds a threshold or steering ASR surpasses baseline) and add a figure showing its correlation with per-model ASR. This will make the architectural-determinism argument more precise while remaining grounded in the existing experimental data. revision: partial
Circularity Check
No circularity: empirical contrast defines intervention without self-referential reduction
full rationale
The paper presents CLS as an empirical procedure that computes a direction by contrasting output distributions (or hidden states) under safe versus unrestricted system prompts, then measures the resulting attack success rates across models. This construction is a direct measurement and steering intervention rather than a derivation in which a claimed result is forced by the inputs or by self-citation; the reported ASR figures (e.g., 95% on Llama-3.1) are experimental outcomes, not algebraic identities. No equations, uniqueness theorems, or prior self-citations are invoked that would collapse the safety-axis claim back into the prompt contrast itself. The method therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[2]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[3]
2023 , eprint=
Jailbroken: How Does LLM Safety Training Fail? , author=. 2023 , eprint=
2023
-
[4]
2024 , eprint=
Jailbreaking Black Box Large Language Models in Twenty Queries , author=. 2024 , eprint=
2024
-
[5]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[6]
2024 , eprint=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
2024
-
[7]
2023 , eprint=
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. 2023 , eprint=
2023
-
[8]
2024 , eprint=
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal , author=. 2024 , eprint=
2024
-
[9]
2024 , eprint=
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models , author=. 2024 , eprint=
2024
-
[10]
2025 , eprint=
Representation Engineering: A Top-Down Approach to AI Transparency , author=. 2025 , eprint=
2025
-
[11]
2025 , eprint=
Logit-Gap Steering: Efficient Short-Suffix Jailbreaks for Aligned Large Language Models , author=. 2025 , eprint=
2025
-
[12]
2024 , eprint=
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models , author=. 2024 , eprint=
2024
-
[13]
2024 , eprint=
ROSE Doesn't Do That: Boosting the Safety of Instruction-Tuned Large Language Models with Reverse Prompt Contrastive Decoding , author=. 2024 , eprint=
2024
-
[14]
2025 , eprint=
Weak-to-Strong Jailbreaking on Large Language Models , author=. 2025 , eprint=
2025
-
[15]
2023 , eprint=
Self-Detoxifying Language Models via Toxification Reversal , author=. 2023 , eprint=
2023
-
[16]
2025 , eprint=
Programming Refusal with Conditional Activation Steering , author=. 2025 , eprint=
2025
-
[17]
2024 , eprint=
Tree of Attacks: Jailbreaking Black-Box LLMs Automatically , author=. 2024 , eprint=
2024
-
[18]
2025 , eprint=
In-Context Representation Hijacking , author=. 2025 , eprint=
2025
-
[19]
Vazquez and Ulisse Mini and Monte MacDiarmid , Title =
Alexander Matt Turner and Lisa Thiergart and Gavin Leech and David Udell and Juan J. Vazquez and Ulisse Mini and Monte MacDiarmid , Title =. 2023 , Eprint =
2023
-
[20]
2024 , eprint=
Refusal in Language Models Is Mediated by a Single Direction , author=. 2024 , eprint=
2024
-
[21]
Stanford Center for Research on Foundation Models
Alpaca: A strong, replicable instruction-following model , author=. Stanford Center for Research on Foundation Models. https://crfm. stanford. edu/2023/03/13/alpaca. html , volume=
2023
-
[22]
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. 2024. https://arxiv.org/abs/2406.11717 Refusal in language models is mediated by a single direction . Preprint, arXiv:2406.11717
Pith/arXiv arXiv 2024
-
[23]
Pappas, Florian Tramer, Hamed Hassani, and Eric Wong
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramer, Hamed Hassani, and Eric Wong. 2024 a . https://arxiv.org/abs/2404.01318 Jailbreakbench: An open robustness benchmark for jailbreaking large language models . Preprint, arXiv:2404.01318
Pith/arXiv arXiv 2024
-
[24]
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. 2024 b . https://arxiv.org/abs/2310.08419 Jailbreaking black box large language models in twenty queries . Preprint, arXiv:2310.08419
Pith/arXiv arXiv 2024
-
[25]
Bruce W. Lee, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Erik Miehling, Pierre Dognin, Manish Nagireddy, and Amit Dhurandhar. 2025. https://arxiv.org/abs/2409.05907 Programming refusal with conditional activation steering . Preprint, arXiv:2409.05907
arXiv 2025
-
[26]
Chak Tou Leong, Yi Cheng, Jiashuo Wang, Jian Wang, and Wenjie Li. 2023. https://arxiv.org/abs/2310.09573 Self-detoxifying language models via toxification reversal . Preprint, arXiv:2310.09573
arXiv 2023
-
[27]
Tung-Ling Li and Hongliang Liu. 2025. https://arxiv.org/abs/2506.24056 Logit-gap steering: Efficient short-suffix jailbreaks for aligned large language models . Preprint, arXiv:2506.24056
Pith/arXiv arXiv 2025
-
[28]
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2024. https://arxiv.org/abs/2310.04451 Autodan: Generating stealthy jailbreak prompts on aligned large language models . Preprint, arXiv:2310.04451
Pith/arXiv arXiv 2024
-
[29]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. 2024. https://arxiv.org/abs/2402.04249 Harmbench: A standardized evaluation framework for automated red teaming and robust refusal . Preprint, arXiv:2402.04249
Pith/arXiv arXiv 2024
-
[30]
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. 2024. https://arxiv.org/abs/2312.02119 Tree of attacks: Jailbreaking black-box llms automatically . Preprint, arXiv:2312.02119
arXiv 2024
-
[31]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. https://arxiv.org/abs/2203.02155 Training language models to f...
Pith/arXiv arXiv 2022
-
[32]
Vazquez, Ulisse Mini, and Monte MacDiarmid
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. 2023. https://arxiv.org/abs/arXiv:2308.10248 Steering language models with activation engineering
Pith/arXiv arXiv 2023
-
[33]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. https://arxiv.org/abs/2307.02483 Jailbroken: How does llm safety training fail? Preprint, arXiv:2307.02483
Pith/arXiv arXiv 2023
-
[34]
Itay Yona, Amir Sarid, Michael Karasik, and Yossi Gandelsman. 2025. https://arxiv.org/abs/2512.03771 In-context representation hijacking . Preprint, arXiv:2512.03771
arXiv 2025
-
[35]
Xuandong Zhao, Xianjun Yang, Tianyu Pang, Chao Du, Lei Li, Yu-Xiang Wang, and William Yang Wang. 2025. https://arxiv.org/abs/2401.17256 Weak-to-strong jailbreaking on large language models . Preprint, arXiv:2401.17256
arXiv 2025
-
[36]
Qihuang Zhong, Liang Ding, Juhua Liu, Bo Du, and Dacheng Tao. 2024. https://arxiv.org/abs/2402.11889 Rose doesn't do that: Boosting the safety of instruction-tuned large language models with reverse prompt contrastive decoding . Preprint, arXiv:2402.11889
arXiv 2024
-
[37]
Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, and 2 others
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, and 2 others. 2025. https://arxiv.org/abs/2310.01405 Representation engineering: A top-...
Pith/arXiv arXiv 2025
-
[38]
Zico Kolter, and Matt Fredrikson
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. 2023. https://arxiv.org/abs/2307.15043 Universal and transferable adversarial attacks on aligned language models . Preprint, arXiv:2307.15043
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.