Cloak: Zero-Shot Cross-Embodiment Manipulation by Masking the End-Effector from the VLA
Pith reviewed 2026-06-26 08:50 UTC · model grok-4.3
The pith
Masking the end-effector in wrist-camera images lets a VLA trained on one gripper control unseen robot bodies zero-shot.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
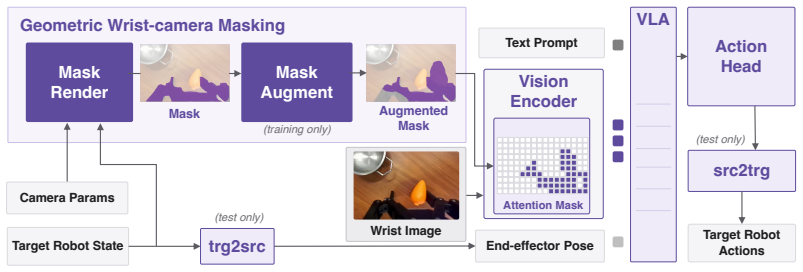
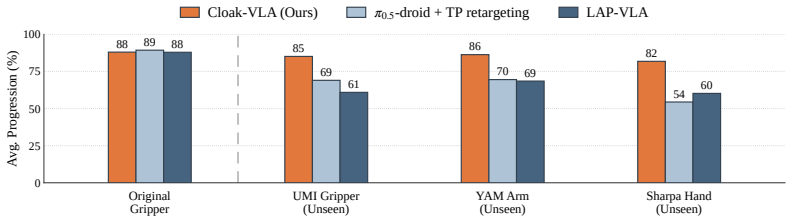
Cloak endows a VLA with zero-shot cross-embodiment transfer by cloaking the end-effector from its own wrist camera. The end-effector occupies a large and consistent region of the wrist view and masking it allows for embodiment-agnostic visual reasoning. Cloak renders a mask in simulation from the robot's known geometry, accurately and in real time, with no segmentation or generative models. During training the mask is augmented so the model generalizes to embodiments unseen at training time. Cloak-VLA trained on a single parallel-jaw gripper dataset transfers zero-shot to various unseen embodiments while preserving the source embodiment's performance.
What carries the argument
The Cloak mask: a real-time rendered silhouette of the end-effector generated from known robot geometry and augmented during training to force embodiment-agnostic reasoning.
If this is right
- The same model controls another gripper, another arm, and a five-fingered hand without any new data or fine-tuning.
- Performance on the source parallel-jaw gripper remains unchanged after the masking procedure.
- Robot datasets collected on one embodiment remain usable after the hardware is replaced or retired.
- No segmentation models or generative models are required to produce the masks.
Where Pith is reading between the lines
- The same masking idea could be applied to other visible robot parts such as the arm links if they appear in the wrist view.
- Large multi-embodiment datasets might be assembled more easily if each source is masked before mixing.
- The approach may reduce the need to retrain policies when only the end-effector changes on an existing robot.
- Testing the method on camera placements other than the wrist could reveal how much the benefit depends on the end-effector dominating the image.
Load-bearing premise
Rendering an accurate mask from the robot's known geometry and augmenting it during training is sufficient to make visual reasoning ignore embodiment details for bodies never seen in the training data.
What would settle it
A clear drop in success rate when the trained model is tested on the five-fingered hand or another unseen arm, relative to its performance on the original parallel-jaw gripper, would show the transfer has failed.
Figures







read the original abstract
We present Cloak, a training recipe that endows a Vision-Language-Action (VLA) model with zero-shot cross-embodiment transfer by cloaking the end-effector from its own wrist camera. The end-effector occupies a large and consistent region of the wrist view and masking it allows for embodiment-agnostic visual reasoning. Cloak renders a mask in simulation from the robot's known geometry, accurately and in real time, with no segmentation or generative models. During training, we augment the mask so the model generalizes to embodiments unseen at training time. We demonstrate the recipe with Cloak-VLA, a VLA trained with Cloak on a single parallel-jaw gripper dataset. No data of new embodiments is ever collected. Cloak-VLA transfers zero-shot to various unseen embodiments, including another gripper, another arm, and a five-fingered hand, while preserving the source embodiment's performance. By decoupling the wrist view from its own embodiment, Cloak allows data to outlive the hardware it was collected on.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Cloak, a training recipe for Vision-Language-Action (VLA) models that enables zero-shot cross-embodiment transfer by rendering and augmenting masks of the end-effector from known geometry in simulation. A model trained only on parallel-jaw gripper data is claimed to transfer without further data collection to unseen embodiments including another gripper, another arm, and a five-fingered hand, while preserving source-embodiment performance.
Significance. If the empirical results hold under rigorous validation, the work would be significant for robotics by providing a practical, simulation-only mechanism to decouple wrist-camera visual reasoning from specific hardware, allowing datasets to outlive the robots on which they were collected. The geometry-based real-time masking without segmentation or generative models is a concrete engineering strength that could be adopted in other VLA pipelines.
major comments (1)
- [Abstract] Abstract: the central claim that mask augmentation during training on a single parallel-jaw dataset produces embodiment-agnostic features for a never-seen five-fingered hand is load-bearing, yet no quantitative metrics, baselines, ablation isolating the augmentation schedule, or failure-case analysis are reported; without these it is impossible to verify whether the augmentation distribution actually covers the required appearance statistics of arbitrary new end-effector geometries.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying a point where the presentation of evidence for the core claim can be strengthened. We address the comment below and commit to revisions that will make the supporting metrics, ablations, and analysis explicit.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that mask augmentation during training on a single parallel-jaw dataset produces embodiment-agnostic features for a never-seen five-fingered hand is load-bearing, yet no quantitative metrics, baselines, ablation isolating the augmentation schedule, or failure-case analysis are reported; without these it is impossible to verify whether the augmentation distribution actually covers the required appearance statistics of arbitrary new end-effector geometries.
Authors: We agree that the abstract states the claim concisely without the supporting numbers and that an explicit ablation isolating the augmentation schedule together with failure-case analysis would allow readers to assess coverage of new end-effector appearance statistics. The experiments section already reports success rates on the five-fingered hand and comparisons against a no-masking baseline, but these elements are not summarized in the abstract and the augmentation ablation is not isolated as a single controlled study. We will therefore revise the abstract to include the key quantitative transfer metrics, add a dedicated ablation subsection that varies only the augmentation schedule, and include a failure-case analysis (with examples of when transfer succeeds or degrades) in the main text or supplementary material. revision: yes
Circularity Check
No significant circularity; method is data augmentation with external held-out evaluation
full rationale
The paper describes a masking-based data augmentation procedure applied during training on a single parallel-jaw gripper dataset, with zero-shot transfer evaluated on unseen embodiments (different grippers, arms, five-fingered hand). No equations, fitted parameters, or predictions are defined; success is measured by empirical performance on held-out hardware rather than any reduction to training inputs by construction. No self-citations or uniqueness theorems are invoked as load-bearing steps. The derivation chain consists of a rendering step from known geometry plus augmentation, both independent of the target result.
Axiom & Free-Parameter Ledger
free parameters (1)
- mask augmentation schedule
axioms (1)
- domain assumption The end-effector occupies a large and consistent region of the wrist view
Reference graph
Works this paper leans on
-
[1]
O. X.-E. Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Her- zog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Kolobov, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakr- ishna, A. W...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
2024
-
[3]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[4]
Bjorck, N
NVIDIA, J. Bjorck, N. C. Fernando Casta ˜neda, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Yu, ...
2025
-
[5]
M. Xu, H. Zhang, Y . Hou, Z. Xu, L. Fan, M. Veloso, and S. Song. Dexumi: Using human hand as the universal manipulation interface for dexterous manipulation. InConference on Robot Learning, pages 437–459. PMLR, 2025
2025
-
[6]
L. Y . Chen, C. Xu, K. Dharmarajan, M. Z. Irshad, R. Cheng, K. Keutzer, M. Tomizuka, Q. Vuong, and K. Goldberg. Rovi-aug: Robot and viewpoint augmentation for cross- embodiment robot learning. InConference on Robot Learning (CoRL), Munich, Germany, 2024
2024
-
[7]
C. Yuan, S. Joshi, S. Zhu, H. Su, H. Zhao, and Y . Gao. Roboengine: Plug-and-play robot data augmentation with semantic robot segmentation and background generation. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7622–
-
[8]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, et al.\π {0.5}: a vision-language-action model with open-world generalization. In9th Annual Conference on Robot Learning, 2025
2025
-
[9]
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, et al. X- vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Ghosh, H
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y . Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
- [13]
-
[14]
L. Wang, X. Chen, J. Zhao, and K. He. Scaling proprioceptive-visual learning with heteroge- neous pre-trained transformers. InNeurips, 2024
2024
-
[15]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffu- sion foundation model for bimanual manipulation. InInternational Conference on Learning Representations, volume 2025, pages 29982–30009, 2025
2025
- [16]
- [17]
-
[18]
L. Y . Chen, K. Hari, K. Dharmarajan, C. Xu, Q. Vuong, and K. Goldberg. Mirage: Cross- embodiment zero-shot policy transfer with cross-painting. InProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[19]
S. Bahl, A. Gupta, and D. Pathak. Human-to-robot imitation in the wild. 2022
2022
-
[20]
E. Dessalene, P. Mantripragada, M. Maynord, and Y . Aloimonos. Embodiswap for zero-shot robot imitation learning.arXiv preprint arXiv:2510.03706, 2025
-
[21]
Lepert, J
M. Lepert, J. Fang, and J. Bohg. Phantom: Training robots without robots using only human videos. InConference on Robot Learning, pages 4545–4565. PMLR, 2025
2025
-
[22]
Lepert, J
M. Lepert, J. Fang, and J. Bohg. Masquerade: Learning from in-the-wild human videos using data-editing. In2026 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2026
2026
-
[23]
G. Li, Y . Lyu, Z. Liu, C. Hou, Y . Xu, J. Zhang, and S. Zhang. H2r: A human-to-robot data augmentation for robot pre-training from videos. InSynthetic Data for Computer Vision Work- shop@ CVPR 2025
2025
- [24]
-
[25]
P. Dan, K. Kedia, A. Chao, E. Duan, M. A. Pace, W.-C. Ma, and S. Choudhury. X-sim: Cross-embodiment learning via real-to-sim-to-real. InConference on Robot Learning, pages 816–833. PMLR, 2025. 11
2025
-
[26]
Lepert, R
M. Lepert, R. Doshi, and J. Bohg. Shadow: Leveraging segmentation masks for zero-shot cross-embodiment policy transfer. InConference on Robot Learning (CoRL), Munich, Ger- many, 2024
2024
-
[27]
R. Mirjalili, T. J ¨ulg, F. Walter, and W. Burgard. Augmented Reality for RObots (ARRO): Pointing visuomotor policies towards visual robustness.arXiv preprint arXiv:2505.08627, 2025
-
[28]
Handa, K
A. Handa, K. Van Wyk, W. Yang, J. Liang, Y .-W. Chao, Q. Wan, S. Birchfield, N. Ratliff, and D. Fox. Dexpilot: Vision-based teleoperation of dexterous robotic hand-arm system. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 9164–9170. IEEE, 2020
2020
-
[29]
Y . Qin, W. Yang, B. Huang, K. Van Wyk, H. Su, X. Wang, Y .-W. Chao, and D. Fox. Anyteleop: A general vision-based dexterous robot arm-hand teleoperation system. InRobotics: Science and Systems, 2023
2023
-
[30]
H. Yuan, B. Zhou, Y . Fu, and Z. Lu. Cross-embodiment dexterous grasping with reinforce- ment learning. InInternational Conference on Learning Representations, volume 2025, pages 81413–81434, 2025
2025
-
[31]
Z. Wei, Y . Yao, and M. Ding. One hand to rule them all: Canonical representations for unified dexterous manipulation.arXiv preprint arXiv:2602.16712, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Bauer, E
E. Bauer, E. Nava, and R. K. Katzschmann. Latent action diffusion for cross-embodiment manipulation. InDexterous Manipulation: Learning and Control with Diverse Modalities, 2025
2025
-
[33]
Zhang, L
K. Zhang, L. Xu, C. Song, J. Xu, X. Lin, Z. Jiang, and R. Xu. Dexformer: Cross-embodied dexterous manipulation via history-conditioned transformer.preprint, 2026
2026
- [34]
-
[35]
K. Zakka. mink: Python inverse kinematics based on MuJoCo, jul 2025. URLhttps:// github.com/kevinzakka/mink
2025
-
[36]
openpi.https://github.com/Physical-Intelligence/openpi,
Physical Intelligence. openpi.https://github.com/Physical-Intelligence/openpi,
-
[37]
Accessed: 2026-06-04
2026
-
[38]
Front-Left
K. Pertsch. DROID with filled-in language annotations.https://huggingface.co/KarlP/ droid, 2024. 12 Appendix A Data Processing A.1 Camera Extrinsics Estimation The wrist-camera extrinsics shipped with DROID are noisy and not suitable for the pixel-level mask alignment needed byCloak. We therefore re-estimate the 6-DoF camera pose in the end-effector frame...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.